Edited, memorised or added to reading queue
on 07-Mar-2017 (Tue)
Do you want BuboFlash to help you learning these things? Click here to log in or create user.
Flashcard 1429070548236
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itValuable goods are those which are not only desired for their own sake but which increase the intrinsic worth of their possessor. For instance, knowledge, virtue, and health are valuable goods.
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1442931412236
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itPara establecer la estructura interna de las palabras, la morfología se ocupa de: a . identificar los formantes morfológicos; b . determinar las posibles variaciones que éstos presenten; c . describir los procesos involucrados; d . reconocer la organización de las palabras
Original toplevel document
La estructura interna de la palabra1. Los formantes morfológicos Una palabra tiene estructura interna cuando contiene más de un formante morfológico. Un formante morfológico o morfema es una unidad mínima que consta de una forma fonética y de un significado. Comparemos las siguientes palabras: gota, gotas, gotita, gotera, cuentagotas. Gota es la única de estas palabras que consta de un solo formante. Carece, entonces, de estructura interna. Es una palabra simple. Todas las otras palabras tienen estructura interna. [31] Los formantes que pueden aparecer como palabras independientes son formas libres. Los otros, los que necesariamente van adosados a otros morfe- mas, son formas ligadas. Cuentagotas contiene dos formantes que pueden aparecer cada uno como palabra independiente. Es una palabra compuesta. Gotas, gotita y gotera también contienen dos formantes, pero uno de ellos (-s, -ita, -era) nunca puede ser una palabra independiente. Son formas ligadas que se denominan afijos. Algunos afijos van pospuestos a la base (gota), como los de nuestros ejemplos: son los s u f i j o s . Otros afijos la preceden: in-útil, des-contento, a-político: Son los prefijos. Las palabras que contienen un afijo se denominan palabras complejas. Del inventario de formantes reconocidos, reconoceremos dos clases: a. Algunos son formantes léxicos: tienen un significado léxico, que se define en el diccionario: gota, cuenta. Se agrupan en clases abiertas. Pertenecen a una clase particular de palabras: sustantivos (gota), adjetivos (útil), adverbios (ayer), verbos (cuenta). Pueden ser: - palabras simples (gota, útil, ayer); - base a la que se adosan los afijos en palabras complejas (got-, politic-); - parte de una palabra, compuesta (cuenta, gotas). b. Otros son formantes gramaticales: tienen significado gramatical, no léxico. Se agrupan en clases cerradas. Pueden ser: - palabras independientes: preposiciones (a, de, por), conjunciones (que, si); - afijos en palabras derivadas (-s, -ero, in-, des-); - menos frecuentemente, formantes de compuestos (aun-que, por-que, si-no). Entre las palabras no simples consideradas hasta aquí, cada una contenía sólo dos formantes. En otras un mismo tipo de formantes se repite: - sufijos: region-al-izar, util-iza-ble; - prefijos: des-com-poner. ex-pro-soviético, o también formantes de diferentes tipos pueden combinarse entre sí: - prefijo y sufijo: des-leal-tad, em-pobr-ecer; - palabra compuesta y sufijo: rionegr-ino, narcotrafic-ante. En la combinación de prefijación y sufijación, se distinguen dos casos, ilustrados en nuestros ejemplos. En deslealtad, la aplicación de cada uno de los afijos da como resultado una palabra bien formada: si aplicamos sólo el prefijo se obtiene el adjetivo desleal; si aplicamos sólo el sufijo el resultado será el sustantivo lealtad. En cambio, en empobrecer, si se aplica sólo un afijo [32] el resultado no será una palabra existente: *empobre, *pobrecer. Prefijo y sufijo se aplican simultáneamente, constituyendo un único formante morfológico – discontinuo– que se añade a ambos lados de la base léxica. Este segundo caso se denomina parasíntesis. Para establecer la estructura interna de las palabras, la morfología se ocupa de: a. identificar los formantes morfológicos; b. determinar las posibles variaciones que éstos presenten; c. describir los procesos involucrados; d. reconocer la organización de las palabras. 2. Identificación de los formantes morfológicos Comparemos ahora las siguientes palabras: sol, sol-ar; sol-azo, quita- sol, gira-sol, solter-o, solaz. En las
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Flashcard 1484231150860
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itdy>most proteins are composed of a series of protein domains, in which different regions of the polypeptide chain fold independently to form compact structures. Such multidomain proteins are believed to have originated from the accidental joining of the DNA sequences that encode each domain, cre- ating a new gene.<body><html>
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1484315036940
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itA vector x and a vector y are orthogonal to each other if x y = 0 .
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1484402593036
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itIn other words, the normalizer for the beta distribution is the beta function \(B(a,b) = \int d\theta \space \theta^{a-1}(1-\theta)^{b-1}\)
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1484429856012
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itThe standard deviation of the beta distribution is μ(1−μ)/(a+b+1)−−−−−−−−−−−−−−−−√μ(1−μ)/(a+b+1). Notice that the standard deviation gets smaller when the concentration κ = a + b gets larger.
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
How to Make Your Own Smart Drugs
tion. Research has also determined that this supplement can provide significant memory improvements in Alzheimer’s and vascular dementia patients. There are also generous amounts in the adaptogenic herb complex TianChi. 2. Bacopa Monnieri <span>Bacopa Monnieri is an extract from the Brahmi plant. According to WebMD, Bacopa is used for a wide variety of purposes, including as a supplemental Alzheimer’s treatment and way to reduce anxiety. Evidence suggests that this natural nootropic is effective at improving memory and hand-eye coordination. There have also been some studies that link Bacopa with a reduction in anxiety,
Flashcard 1486207978764
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itBacopa Monnieri is an extract from the Brahmi plant. According to WebMD, Bacopa is used for a wide variety of purposes, including as a supplemental Alzheimer’s treatment and way to reduce anxiety.
Original toplevel document
How to Make Your Own Smart Drugstion. Research has also determined that this supplement can provide significant memory improvements in Alzheimer’s and vascular dementia patients. There are also generous amounts in the adaptogenic herb complex TianChi. 2. Bacopa Monnieri <span>Bacopa Monnieri is an extract from the Brahmi plant. According to WebMD, Bacopa is used for a wide variety of purposes, including as a supplemental Alzheimer’s treatment and way to reduce anxiety. Evidence suggests that this natural nootropic is effective at improving memory and hand-eye coordination. There have also been some studies that link Bacopa with a reduction in anxiety,
Flashcard 1486210600204
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
How to Make Your Own Smart Drugs
ts together to achieve some pretty cool results. Happy blendin'. ————————- Synthetic vs. Natural Nootropics There are numerous synthetic smart drugs that are utilized nowadays by people from all walks of life, from CEO's to soccer moms. <span>For example, Piracetam was one of the first lab created compounds specifically designed to enhance cognitive performance, and although it is a synthesized chemical (with chemical name 2-oxo-1-pyrrolidine acetamide) it is generally regarded as being safe. The vast majority of people can take this supplement without needing to worry about suffering from any major side effects. However, there are also many notable natural and herbal nootro
ts together to achieve some pretty cool results. Happy blendin'. ————————- Synthetic vs. Natural Nootropics There are numerous synthetic smart drugs that are utilized nowadays by people from all walks of life, from CEO's to soccer moms. <span>For example, Piracetam was one of the first lab created compounds specifically designed to enhance cognitive performance, and although it is a synthesized chemical (with chemical name 2-oxo-1-pyrrolidine acetamide) it is generally regarded as being safe. The vast majority of people can take this supplement without needing to worry about suffering from any major side effects. However, there are also many notable natural and herbal nootro
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
How to Make Your Own Smart Drugs
nent that you would take individually is not typically a wise choice due to the way that each supplement blends together. For this stack, most folks use the following daily combination, and you can find most of this stuff in bulk on Amazon. <span>Lion’s Mane – 500 mg, once per day Gingko Biloba – 240 mg, once per day Bacopa Monnieri – 100 mg, twice per day After 12 weeks, if you are not experiencing positive results, you may need to adjust the dosages in your stack. Start with small increments such as increasing each dose of the Bacopa
Flashcard 1486213483788
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itLion’s Mane – 500 mg, once per dayGingko Biloba – 240 mg, once per dayBacopa Monnieri – 100 mg, twice per day
Original toplevel document
How to Make Your Own Smart Drugsnent that you would take individually is not typically a wise choice due to the way that each supplement blends together. For this stack, most folks use the following daily combination, and you can find most of this stuff in bulk on Amazon. <span>Lion’s Mane – 500 mg, once per day Gingko Biloba – 240 mg, once per day Bacopa Monnieri – 100 mg, twice per day After 12 weeks, if you are not experiencing positive results, you may need to adjust the dosages in your stack. Start with small increments such as increasing each dose of the Bacopa
Flashcard 1486214532364
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
How to Make Your Own Smart Drugs
each component that you would take individually is not typically a wise choice due to the way that each supplement blends together. For this stack, most folks use the following daily combination, and you can find most of this stuff in bulk on <span>Amazon. Lion’s Mane – 500 mg, once per day Gingko Biloba – 240 mg, once per day Bacopa Monnieri – 100 mg, twice per day After 12 weeks, if you are not experiencing positive results, you may
each component that you would take individually is not typically a wise choice due to the way that each supplement blends together. For this stack, most folks use the following daily combination, and you can find most of this stuff in bulk on <span>Amazon. Lion’s Mane – 500 mg, once per day Gingko Biloba – 240 mg, once per day Bacopa Monnieri – 100 mg, twice per day After 12 weeks, if you are not experiencing positive results, you may
Flashcard 1486217415948
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itOther measures such as correlation normalize the con tribution of each v ariable in order to measure only how m uc h the v ariables are related, rather than also b eing affected b y the scale of the separate v ariables</s
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486218988812
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itOther measures such as correlation normalize the con tribution of each v ariable in order to measure only how m uc h the v ariables are related, rather than also b eing affected b y the scale of the separate v ariables
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486220561676
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itOther measures such as correlation normalize the con tribution of each v ariable in order to measure only how m uc h the v ariables are related, rather than also b eing affected b y the scale of the separate v ariables
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Flashcard 1486269844748
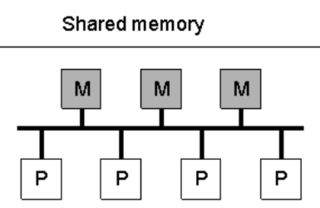
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 1486273252620
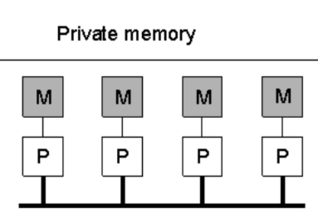
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 1486276660492
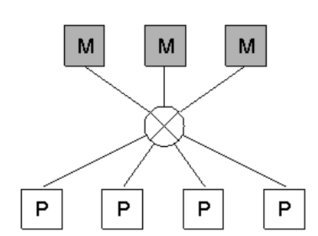
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 1486280068364
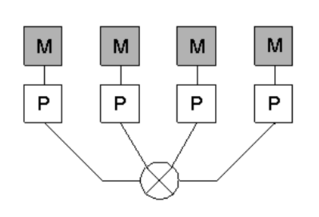
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 1486283476236
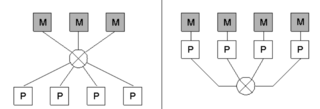
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 1486285311244
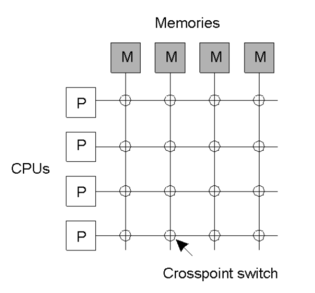
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 1486291078412
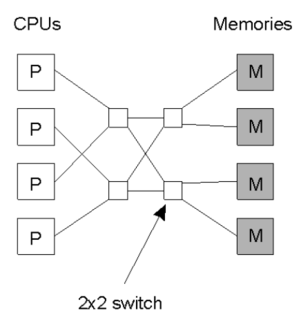
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 1486292389132
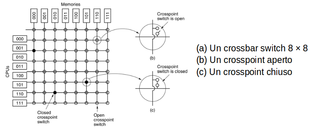
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 1486303137036
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 1486306544908
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 1486383090956
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 1486384925964
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 1486390955276
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itThe co v ariance matrix of a random vector x ∈ R n is an n n × matrix, suc h that Co v( ) x i,j = Co v( x i , x j ) . (3.14) The diagonal elemen ts of the co v ariance give the v ariance: Co v( x i , x
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486393314572
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itThe co v ariance matrix of a random vector x ∈ R n is an n n × matrix, suc h that Cov(x) i,j = Cov( x i , x j ) . (3.14) The diagonal elements of the covariance give the variance: Cov( x i , x i ) = Var( x i )
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486394887436
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itThe co v ariance matrix of a random vector x ∈ R n is an n n × matrix, suc h that Cov(x) i,j = Cov( x i , x j ) . (3.14) The diagonal elements of the covariance give the variance: Cov( x i , x i ) = Var( x i )
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486396460300
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itThe Bernoulli distribution is a distribution ov er a single binary random v ariable. It is controlled by a single parameter φ ∈ [0 , 1] , whic h gives the probability of the random v ariable b eing equal to 1. It has the following prop erties: P φ ( = 1) = x (3.16) P
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486398033164
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itThe Bernoulli distribution is a distribution ov er a single binary random v ariable. It is controlled by a single parameter φ ∈ [0 , 1] , whic h gives the probability of the random v ariable b eing equal to 1. It has the following prop erties: P φ ( = 1) = x (3.16) P φ ( = 0) = 1 x − (3.17) P x φ ( = x ) = x (1 ) − φ 1 − x (3.18) E x [ ] = x φ (3.19) V ar x ( ) = (1 ) x φ − φ</spa
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486400392460
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itis controlled by a single parameter φ ∈ [0 , 1] , whic h gives the probability of the random v ariable b eing equal to 1. It has the following prop erties: P (x = 1) = φ P (x = 0) = 1-φ P (x = x ) = φ x (1 − φ) 1 − x <span>E x [x] = φ V ar (x) = φ (1− φ)<span><body><html>
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486402227468
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itingle parameter φ ∈ [0 , 1] , whic h gives the probability of the random v ariable b eing equal to 1. It has the following prop erties: P (x = 1) = φ P (x = 0) = 1-φ P (x = x ) = φ x (1 − φ) 1 − x E x [x] = φ <span>V ar (x) = φ (1− φ)<span><body><html>
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486404062476
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itIn some cases, we wish to sp ecify that all of the mass in a probabilit y distribution clusters around a single p oin t. This can b e accomplished b y defining a PDF using the Dirac delta function, : δ x ( ) p x δ x µ . ( ) = ( − ) (3.27) The Dirac delta function is defined such that it is zero-v alued eve
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486405635340
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itIn some cases, we wish to sp ecify that all of the mass in a probabilit y distribution clusters around a single p oin t. This can b e accomplished b y defining a PDF using the Dirac delta function, : δ x ( ) p x δ x µ . ( ) = ( − ) (3.27) The Dirac delta function is defined such that it is zero-v alued everywhere except 0, y et integrates to 1.
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486407208204
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itll of the mass in a probabilit y distribution clusters around a single p oin t. This can b e accomplished b y defining a PDF using the Dirac delta function, : δ x ( ) p x δ x µ . ( ) = ( − ) (3.27) The Dirac delta function is defined such that <span>it is zero-v alued everywhere except 0, y et integrates to 1.<span><body><html>
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486409567500
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itIn some cases, we wish to sp ecify that all of the mass in a probabilit y distribution clusters around a single p oin t. This can b e accomplished b y defining a PDF using the Dirac delta function, : δ(x) = δ(x-µ) The Dirac delta function is defined such that it is zero-v alued everywhere except 0, y et integrates to 1.
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486412713228
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itmathematical ob ject called a generalized function that is defined in terms of its prop erties when integrated
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486414286092
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itAnother imp ortant p ersp ective on the empirical distribution is that it is the probabilit y density that maximizes the likelihoo d of the training data
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486415858956
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itAnother imp ortant p ersp ective on the empirical distribution is that it is the probabilit y density that maximizes the likelihoo d of the training data
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486417431820
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itA latent v ariable is a random v ariable that w e cannot observe directly .
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486419004684
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itA latent v ariable is a random v ariable that w e cannot observe directly .
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486421363980
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itCertain functions arise often while working with probability distributions, especially the probabilit y distributions used in deep learning models. One of these functions is the : logistic sigmoid σ(x) = 1/(1 + exp(− x))
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486422936844
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itCertain functions arise often while working with probability distributions, especially the probabilit y distributions used in deep learning models. One of these functions is the : logistic sigmoid σ(x) = 1/(1 + exp(− x))
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486424509708
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itdiagonal co v ariance matrix, meaning it can control the v ariance separately along each axis-aligned direction.
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486426082572
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itdiagonal co v ariance matrix, meaning it can control the v ariance separately along each axis-aligned direction.
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486428441868
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itAnother commonly encountered function is the softplus function ( , Dugas et al. 2001 ): ζ(x) = log (1 + exp(x)) The softplus function can be useful for pro ducing the β or σ parameter of a normal distribution b ecause its range is (0 , ∞ )
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486430014732
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itAnother commonly encountered function is the softplus function ( , Dugas et al. 2001 ): ζ(x) = log (1 + exp(x)) The softplus function can be useful for pro ducing the β or σ parameter of a normal distribution b ecause its range is (0 , ∞ )</
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486431587596
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itAnother commonly encountered function is the softplus function ( , Dugas et al. 2001 ): ζ(x) = log (1 + exp(x)) The softplus function can be useful for pro ducing the β or σ parameter of a normal distribution b ecause its range is (0 , ∞ )
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486433160460
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open it<head>Another commonly encountered function is the softplus function ( , Dugas et al. 2001 ): ζ(x) = log (1 + exp(x)) The softplus function can be useful for pro ducing the β or σ parameter of a normal distribution b ecause its range is (0 , ∞ )<html>
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486435519756
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itJust as x can b e recov ered from its p ositive part and negativ e part via the iden tit y x + − x − = x , it is also p ossible to reco v er x using the same relationship b et w een and ζ (x), ζ ( −x)
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486437092620
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itJust as x can b e recov ered from its p ositive part and negativ e part via the iden tit y x + − x − = x , it is also p ossible to reco v er x using the same relationship b et w een and ζ (x), ζ ( −x)
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486439451916
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itSupp ose we ha v e t w o random v ariables, x and y , suc h that y = g ( x ) , where g is an inv ertible, con- tin uous, differen tiable transformation. One migh t exp ect that p y ( y ) = p x ( g − 1 ( y )) . This is actually not the case.
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486441024780
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itd>Supp ose we ha v e t w o random v ariables, x and y , suc h that y = g ( x ) , where g is an inv ertible, con- tin uous, differen tiable transformation. One migh t exp ect that p y ( y ) = p x ( g − 1 ( y )) . This is actually not the case.<html>
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486442597644
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itThe basic intuition b ehind information theory is that learning that an unlik ely ev en t has occurred is more informative than learning that a lik ely ev ent has o ccurred
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486444956940
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itIn order to satisfy all three of these prop erties, w e define the self-information of an event x = x to be I x = −log P(x)
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1486446529804
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itIn order to satisfy all three of these prop erties, w e define the self-information of an event x = x to be I x = −log P(x)