Edited, memorised or added to reading queue
on 27-Jan-2020 (Mon)
Do you want BuboFlash to help you learning these things? Click here to log in or create user.
Flashcard 1602824572172

| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4881260612876
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4881262447884
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4883816254732
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4884405292300
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4884407127308
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4884410535180
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4884412370188
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4884414205196
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4884416040204
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4884417875212
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4884419710220
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4884421545228
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4884423380236
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4884425215244
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4884427836684
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4884430195980
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4884432030988
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4884433865996
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4884435701004
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4884437536012
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4884439371020
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4884501761292
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4884507790604
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4884510412044
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4884512771340
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4884514868492
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4884516965644
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4884518800652
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Article 4884520635660
Toner and Nuzzo (2011): Acting on the Lessons of SARS: What Remains To Be Done? Eric S. Toner
Acting on the Lessons of SARS: What Remains To Be Done? Eric S. Toner and Jennifer B. Nuzzo Eric S. Toner Search for more papers by this author and Jennifer B. Nuzzo Search for more papers by this author Published Online:25 May 2011 About Figures References Related Details View PDF View PDF Plus Sections Diseases Jump the Species Barrier More Interconnected and Urbanized Hospitals Can Amplify Disease Hospital Infection Control Measures International Scientific Collaboration Disease Doesn't Stop at the Border Preparing to Respond Can Save Lives Superspreading and Respiratory Transmission What Remains To Be Done View Article View PDF View PDF Plus Tools Add to favorites Download Citations Track Citations Permissions Back To Publication Share Share on Facebook Twitter Lin
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Toner and Nuzzo (2011): Acting on the Lessons of SARS: What Remains To Be Done? Eric S. Toner
ier The risk of infectious diseases jumping the species barrier remains a clear and present danger. People have been catching diseases from animals (zoonoses) as long as there have been people. <span>In recent years, most emerging infectious disease events have been the result of mutations in wildlife pathogens that have allowed infection of human hosts.4 In the past, such events contributed to some of history's great pandemics, including influenza, plague, smallpox, and HIV. SARS was caused by a coronavirus that was endemic among fruit bats in China; it adapted to a human host after establishing itself in the captive animals in the wild animal markets of Gu
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Toner and Nuzzo (2011): Acting on the Lessons of SARS: What Remains To Be Done? Eric S. Toner
ons in wildlife pathogens that have allowed infection of human hosts.4 In the past, such events contributed to some of history's great pandemics, including influenza, plague, smallpox, and HIV. <span>SARS was caused by a coronavirus that was endemic among fruit bats in China; it adapted to a human host after establishing itself in the captive animals in the wild animal markets of Guangdong Province. As humans encroach ever more deeply into previously wild areas, the incidence of zoonotic infections will likely increase. In recent years we have seen zoonotic outbreaks of ebola, Marb
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Toner and Nuzzo (2011): Acting on the Lessons of SARS: What Remains To Be Done? Eric S. Toner
ict the emergence of a novel human coronavirus years before SARS appeared.5 More Interconnected and Urbanized The risk of pandemics grows as the world becomes more interconnected and urbanized. <span>Modern urban environments have conditions, such as high population density, poor sanitation, and many poor, malnourished people, that may accelerate the spread of emerging infections. For instance, the large outbreak of SARS at the Amoy Gardens apartment complex in Honk Kong (329 patients) is at least partially related to its enormous size and density—19,000 residents in 0.04 km2.6 Because of their great population density, the burgeoning megacities around the world may contribute to the spread of novel contagious diseases.7,8 The introduction of a highly contagio
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Toner and Nuzzo (2011): Acting on the Lessons of SARS: What Remains To Be Done? Eric S. Toner
pandemic, modern hospitals and the sophisticated care they provided were double-edged swords. It is certainly true that many victims of SARS were saved in intensive care units around the world. <span>It is reasonable to estimate that the case fatality rate for SARS was cut in half by sophisticated modern health care. (If all patients who required intensive care would have died without it, then the case fatality rate would have been approximately 20% rather than the actual 10%.) On the other hand, it is likely that SARS would not have become a major epidemic had it not been for the many superspreading events that occurred in hospitals.11 These superspreading ev
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Toner and Nuzzo (2011): Acting on the Lessons of SARS: What Remains To Be Done? Eric S. Toner
alth care. (If all patients who required intensive care would have died without it, then the case fatality rate would have been approximately 20% rather than the actual 10%.) On the other hand, <span>it is likely that SARS would not have become a major epidemic had it not been for the many superspreading events that occurred in hospitals.11 These superspreading events were very often related to certain medical procedures—such as endotracheal intubation, airway suctioning, and noninvasive ventilation—that turn respiratory d
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Toner and Nuzzo (2011): Acting on the Lessons of SARS: What Remains To Be Done? Eric S. Toner
g events were very often related to certain medical procedures—such as endotracheal intubation, airway suctioning, and noninvasive ventilation—that turn respiratory droplets into aerosols.12,13 <span>Most SARS infections probably occurred in hospitals, and nearly all cases of SARS can be traced back to one or more nosocomial superspreading events starting with relatively small hospital outbreaks in rural Guangdong, then large nosocomial outbreaks in Guangzhou, Hong Kong, Hanoi, Beijing, Singapore, and Toronto.2 That hospitals can function as disease amplifiers is not entirely new: Outbreaks of influenza occur in healthcare facilities every year, and many hospital-related outbreaks of TB have b
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Toner and Nuzzo (2011): Acting on the Lessons of SARS: What Remains To Be Done? Eric S. Toner
red with other infectious diseases as well, including smallpox14,15 and ebola.16,17 Hospital Infection Control Measures Hospital infection control measures work to stop the spread of pandemics. <span>SARS was brought under control within a matter of months largely due to the fact that the disease was most transmissible when the patients were most sick—that is, when they were in a hospital.2 There was relatively little community transmission of SARS compared to other respiratory infections like influenza.18 For this reason, controlling the transmission in hospitals was key in controlling the outbreak.19 This also explains the large percentage of healthcare workers who became infected and the large percentage of victims who acquired their infections in hospitals. For the most part (with
Flashcard 4884535053580
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Toner and Nuzzo (2011): Acting on the Lessons of SARS: What Remains To Be Done? Eric S. Toner
rkers who became infected and the large percentage of victims who acquired their infections in hospitals. For the most part (with the very important exception of aerosol-generating procedures), <span>transmission in hospitals was brought under control by the use of standard infection control practices, such as isolation of sick patients and wearing of masks, gowns, and gloves by hospital staff.20,21 For those high-risk aerosol-generating procedures, more stringent measures, such as the use of negative pressure isolation and high-efficiency respirators, were effective in reducing tr
Flashcard 4884539247884
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Toner and Nuzzo (2011): Acting on the Lessons of SARS: What Remains To Be Done? Eric S. Toner
to contain diseases at national borders provide limited value at great cost. Public health authorities in many locations imposed various forms of quarantine in attempts to quash the outbreaks. <span>Quarantine is the sequestration from the general public of individuals who have potentially been exposed to an infectious disease in an attempt to prevent them from spreading the disease if they turn out to be carriers. It is different from isolation, which is the sequestration of individuals known to have the infection. Isolation was clearly effective in SARS and, in fact, was the key to its control.
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Toner and Nuzzo (2011): Acting on the Lessons of SARS: What Remains To Be Done? Eric S. Toner
l public of individuals who have potentially been exposed to an infectious disease in an attempt to prevent them from spreading the disease if they turn out to be carriers. It is different from <span>isolation, which is the sequestration of individuals known to have the infection. Isolation was clearly effective in SARS and, in fact, was the key to its control. Quarantine, although widely employed, was not so clearly effective. In many cases, a large number of people subject to quarantine orders refused to comply. In fact, in some cases the i
Flashcard 4884543704332
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itQuarantine is the sequestration from the general public of individuals who have potentially been exposed to an infectious disease in an attempt to prevent them from spreading the disease if they t
Original toplevel document
Toner and Nuzzo (2011): Acting on the Lessons of SARS: What Remains To Be Done? Eric S. Tonerto contain diseases at national borders provide limited value at great cost. Public health authorities in many locations imposed various forms of quarantine in attempts to quash the outbreaks. <span>Quarantine is the sequestration from the general public of individuals who have potentially been exposed to an infectious disease in an attempt to prevent them from spreading the disease if they turn out to be carriers. It is different from isolation, which is the sequestration of individuals known to have the infection. Isolation was clearly effective in SARS and, in fact, was the key to its control.
Flashcard 4884545277196
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itQuarantine is the sequestration from the general public of individuals who have potentially been exposed to an infectious disease in an attempt to prevent them from spreading the disease if they turn out to be carriers.
Original toplevel document
Toner and Nuzzo (2011): Acting on the Lessons of SARS: What Remains To Be Done? Eric S. Tonerto contain diseases at national borders provide limited value at great cost. Public health authorities in many locations imposed various forms of quarantine in attempts to quash the outbreaks. <span>Quarantine is the sequestration from the general public of individuals who have potentially been exposed to an infectious disease in an attempt to prevent them from spreading the disease if they turn out to be carriers. It is different from isolation, which is the sequestration of individuals known to have the infection. Isolation was clearly effective in SARS and, in fact, was the key to its control.
Flashcard 4884547374348
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4884548685068
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itIsolation is the sequestration of individuals known to have the infection.
Original toplevel document
Toner and Nuzzo (2011): Acting on the Lessons of SARS: What Remains To Be Done? Eric S. Tonerl public of individuals who have potentially been exposed to an infectious disease in an attempt to prevent them from spreading the disease if they turn out to be carriers. It is different from <span>isolation, which is the sequestration of individuals known to have the infection. Isolation was clearly effective in SARS and, in fact, was the key to its control. Quarantine, although widely employed, was not so clearly effective. In many cases, a large number of people subject to quarantine orders refused to comply. In fact, in some cases the i
Flashcard 4884549733644
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itIsolation is the sequestration of individuals known to have the infection.
Original toplevel document
Toner and Nuzzo (2011): Acting on the Lessons of SARS: What Remains To Be Done? Eric S. Tonerl public of individuals who have potentially been exposed to an infectious disease in an attempt to prevent them from spreading the disease if they turn out to be carriers. It is different from <span>isolation, which is the sequestration of individuals known to have the infection. Isolation was clearly effective in SARS and, in fact, was the key to its control. Quarantine, although widely employed, was not so clearly effective. In many cases, a large number of people subject to quarantine orders refused to comply. In fact, in some cases the i
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Toner and Nuzzo (2011): Acting on the Lessons of SARS: What Remains To Be Done? Eric S. Toner
d to comply. In fact, in some cases the imposition of quarantine orders produced a paradoxical result—people escaped. This may have contributed to the spread of SARS to remote parts of China.24 <span>Various types of travel screening were employed by a number of countries. Despite screening of millions of travelers, only a very few individuals with SARS were discovered. This was especially true of thermal screening. More than 35 million international travelers entering China, Canada, and Singapore had their temperatures measured, but no cases of SARS were found.18 Although the public health benefits of such measures are not clear, the resources required to implement them have been shown to be significant. Canada spent nearly $8 million (Canadian
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Toner and Nuzzo (2011): Acting on the Lessons of SARS: What Remains To Be Done? Eric S. Toner
on the fly. After losing patients and staff to nosocomial transmission of SARS, affected hospitals were forced to figure out which infection control measures would halt the spread of infection. <span>In Canada, where 45% of SARS cases occurred among healthcare workers, a government-sponsored review found that, had the respiratory precautions and isolation policies that were eventually employed in the hospitals been in place at the beginning of the outbreak, many fewer people would have been infected.27 In both hospitals and health departments, advance planning, creation of information and communication systems, education and training, and stockpiling of supplies are necessary to enabl
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Toner and Nuzzo (2011): Acting on the Lessons of SARS: What Remains To Be Done? Eric S. Toner
RS was estimated to be 2 to 4, this number only represents the average number of secondary cases caused by an infected person.28 The reality is that a huge range of transmission rates occurred. <span>While most people with SARS did not infect anyone else, the majority of SARS infections can be traced to a relatively small number of superspreading events in which 1 individual infected many other people.2 Superspreading is not a new phenomenon, having been described with tuberculosis, measles, and smallpox.29 It may well occur more frequently than is recognized in other contagious diseas
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Toner and Nuzzo (2011): Acting on the Lessons of SARS: What Remains To Be Done? Eric S. Toner
disease, diabetes, advanced age, and perhaps corticosteroid therapy. In addition to these host factors, high-risk aerosol-generating procedures were clearly associated with superspreading. But <span>3 superspreading events stand out as particularly puzzling: those that occurred at the Metropole Hotel and Amoy Gardens in Hong Kong, and the event in the emergency department (ED) of Scarborough Grace Hospital in Toronto. The event at the Metropole Hotel was the proximate cause of the SARS pandemic, as nearly all cases outside of China can be traced back to it.31 One infected individual stayed 1 night on
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Toner and Nuzzo (2011): Acting on the Lessons of SARS: What Remains To Be Done? Eric S. Toner
out as particularly puzzling: those that occurred at the Metropole Hotel and Amoy Gardens in Hong Kong, and the event in the emergency department (ED) of Scarborough Grace Hospital in Toronto. <span>The event at the Metropole Hotel was the proximate cause of the SARS pandemic, as nearly all cases outside of China can be traced back to it.31 One infected individual stayed 1 night on the ninth floor of the hotel and infected 16 other people on the same floor who then traveled across the globe before becoming ill. Although several possible explanations have been proposed, there is still no entirely satisfactory explanation for this event. The ED of Scarborough Grace Hospital was the site of a chain of SARS transmission that led to most of the cases in Toronto. In particular, one event there stands out as unusual. The wif
Flashcard 4884561792268
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Toner and Nuzzo (2011): Acting on the Lessons of SARS: What Remains To Be Done? Eric S. Toner
same floor who then traveled across the globe before becoming ill. Although several possible explanations have been proposed, there is still no entirely satisfactory explanation for this event. <span>The ED of Scarborough Grace Hospital was the site of a chain of SARS transmission that led to most of the cases in Toronto. In particular, one event there stands out as unusual. The wife of one of the SARS patients sat in the ED waiting room while her husband was being treated. Unbeknownst to the ED staff, she also had SARS, but her symptoms were mild. Despite having mild symptoms, she apparently infected a number of other people in the waiting room and possibly a number of the staff as well. This event contrasts with most other incidents of SARS transmission, which required close contact and occurred only when the patient had severe symptoms. Like the event in the Metropole Hotel, it would be useful to understand what factors contributed to this anomalous event. The Amoy Gardens event is even more disconcerting. Amoy Gardens is a high-rise apartment complex with 19,000 residents. One infected individual staying there infected 329 others. The be
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Toner and Nuzzo (2011): Acting on the Lessons of SARS: What Remains To Be Done? Eric S. Toner
d close contact and occurred only when the patient had severe symptoms. Like the event in the Metropole Hotel, it would be useful to understand what factors contributed to this anomalous event. <span>The Amoy Gardens event is even more disconcerting. Amoy Gardens is a high-rise apartment complex with 19,000 residents. One infected individual staying there infected 329 others. The best explanation is that a malfunctioning plumbing system allowed the creation of a virus-laden aerosol plume that was blown outdoors, wafted hundreds of yards downwind, and infected people in other buildings through open windows.32 If this hypothesis is true, it undermines many assumptions about the transmission of infectious diseases. This leads to the consideration of how SARS was transmitted—that is, whether it involved droplets or aerosols. Much has been written on this topic, and there are strong opinions on both
Flashcard 4884567821580
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Toner and Nuzzo (2011): Acting on the Lessons of SARS: What Remains To Be Done? Eric S. Toner
h sides. The distinction is important, because the answer determines the appropriate infection control measures to be used. In fact, there is convincing evidence for both forms of transmission. <span>In most cases SARS transmission was blocked by simple droplet precautions, but in others it seems clear that aerosol transmission was the only logical explanation; this was especially true in certain hospital outbreaks (eg, Ward 8a of the Prince of Wales Hospital in Hong Kong33). Probably both droplets and aerosols were produced as patients coughed, and various host and environmental factors determined which mechanism was predominant at a particular time and place. Better understanding of this phenomenon is important, because if this is also true for other diseases, then the role of aerosol transmission in respiratory infections more generally mus
Flashcard 4884569918732
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itThe goal of research at Google is to bring significant, practical benefits to our users, and to do so rapidly, within a few years at most.
Original toplevel document (pdf)
cannot see any pdfsFlashcard 4884570967308
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itThe goal of research at Google is to bring significant, practical benefits to our users, and to do so rapidly, within a few years at most.
Original toplevel document (pdf)
cannot see any pdfsFlashcard 4884572015884
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itThe goal of research at Google is to bring significant, practical benefits to our users, and to do so rapidly, within a few years at most.
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Softmax function - Wikipedia
ts will correspond to larger probabilities. Softmax is often used in neural networks , to map the non-normalized output of a network to a probability distribution over predicted output classes. <span>The standard (unit) softmax function σ : R K → R K {\displaystyle \sigma :\mathbb {R} ^{K}\to \mathbb {R} ^{K}} is defined by the formula σ ( z ) i = e z i ∑ j = 1 K e z j for i = 1 , … , K and z = ( z 1 , … , z K ) ∈ R K {\displaystyle \sigma (\mathbf {z} )_{i}={\frac {e^{z_{i}}}{\sum _{j=1}^{K}e^{z_{j}}}}{\text{ for }}i=1,\dotsc ,K{\text{ and }}\mathbf {z} =(z_{1},\dotsc ,z_{K})\in \mathbb {R} ^{K}} In words: we apply the standard exponential function to each element z i {\displaystyle z_{i}} of the input vector z {\displaystyle \mathbf {z} } and normalize these values by dividing
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Toner and Nuzzo (2011): Acting on the Lessons of SARS: What Remains To Be Done? Eric S. Toner
health. Important lessons were also learned in the area of emergency management at the municipal, provincial/state, and national levels34 and in the realm of international treaties.35 Hospitals <span>In the first few years following the SARS pandemic, “respiratory etiquette” became the “new normal” in hospitals—anyone with a cough had a surgical mask placed on them at the ED door, and aerosol-generating procedures were done only in closed rooms with staff wearing PPE—and it was said that things would never be the same again. But now when we walk the halls of hospitals, this “new normal” for infection control is hard to detect. If SARS were transmitt
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Flashcard 4884591414540
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Alammar-2018-The_Illustrated_Transformer-jalammar,github,io
e animal didn’t cross the street because it was too tired”, we would want to know which word “it” refers to. It gives the attention layer multiple “representation subspaces”. As we’ll see next, <span>with multi-headed attention we have not only one, but multiple sets of Query/Key/Value weight matrices (the Transformer uses eight attention heads, so we end up with eight sets for each encoder/decoder). Each of these sets is randomly initialized. Then, after training, each set is used to project the input embeddings (or vectors from lower encoders/decoders) into a different representation subspace. With multi-headed attention, we maintain separate Q/K/V weight matrices for each head resulting in different Q/K/V matrices. As we did before, we multiply X by the WQ/WK/WV matrices to
Flashcard 4884594298124

| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Alammar-2018-The_Illustrated_Transformer-jalammar,github,io
same self-attention calculation we outlined above, just eight different times with different weight matrices, we end up with eight different Z matrices This leaves us with a bit of a challenge. <span>The feed-forward layer is not expecting eight matrices – it’s expecting a single matrix (a vector for each word). So we need a way to condense these eight down into a single matrix. How do we do that? We concat the matrices then multiple them by an additional weights matrix WO. That’s pretty much all there is to multi-headed self-attention. It’s quite a handful of matrices, I realize. Let me try to put them all in one visual so we can look at them in one place
same self-attention calculation we outlined above, just eight different times with different weight matrices, we end up with eight different Z matrices This leaves us with a bit of a challenge. <span>The feed-forward layer is not expecting eight matrices – it’s expecting a single matrix (a vector for each word). So we need a way to condense these eight down into a single matrix. How do we do that? We concat the matrices then multiple them by an additional weights matrix WO. That’s pretty much all there is to multi-headed self-attention. It’s quite a handful of matrices, I realize. Let me try to put them all in one visual so we can look at them in one place
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Alammar-2018-The_Illustrated_Transformer-jalammar,github,io
Now that we have touched upon attention heads, let’s revisit our example from before to see where the different attention heads are focusing as we encode the word “it” in our example sentence: <span>As we encode the word "it", one attention head is focusing most on "the animal", while another is focusing on "tired" -- in a sense, the model's representation of the word "it" bakes in some of the representation of both "animal" and "tired". If we add all the attention heads to the picture, however, things can be harder to interpret: Representing The Order of The Sequence Using Positional Encoding One thing that’s missing from the model as we have described it so far is a way to account for the order of the words in
Flashcard 4884597443852
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
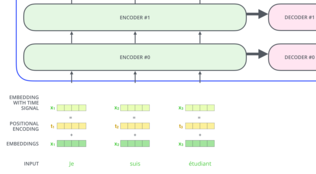
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Alammar-2018-The_Illustrated_Transformer-jalammar,github,io
Sequence Using Positional Encoding One thing that’s missing from the model as we have described it so far is a way to account for the order of the words in the input sequence. To address this, <span>the transformer adds a vector to each input embedding. These vectors follow a specific pattern that the model learns, which helps it determine the position of each word, or the distance between different words in the sequence. The intuition here is that adding these values to the embeddings provides meaningful distances between the embedding vectors once they’re projected into Q/K/V vectors and during dot-product attention. To give the model a sense of the order of the words, we add positional encoding vectors -- the values of which follow a specific pattern. If we assumed the embedding has a dimensionalit
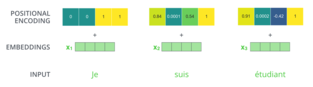
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Alammar-2018-The_Illustrated_Transformer-jalammar,github,io
uition here is that adding these values to the embeddings provides meaningful distances between the embedding vectors once they’re projected into Q/K/V vectors and during dot-product attention. <span>To give the model a sense of the order of the words, we add positional encoding vectors -- the values of which follow a specific pattern. If we assumed the embedding has a dimensionality of 4, the actual positional encodings would look like this: A real example of positional encoding with a toy embedding size of 4 What might this pattern look like? In the following figure, each row corresponds the a positional encoding of a vect
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Alammar-2018-The_Illustrated_Transformer-jalammar,github,io
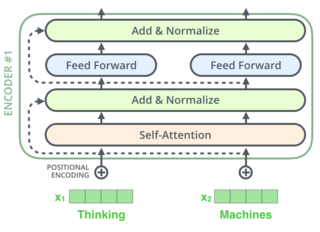
generated by one function (which uses sine), and the right half is generated by another function (which uses cosine). They're then concatenated to form each of the positional encoding vectors. <span>The formula for positional encoding is described in the paper (section 3.5). You can see the code for generating positional encodings in get_timing_signal_1d() . This is not the only possible method for positional encoding. It, however, gives the advantage of being able to scale to unseen lengths of sequences (e.g. if our trained model is asked to translate a sentence longer than any of those in our training set). The Residuals One detail in the architecture of the encoder that we need to mention before moving on, is that each sub-layer (self-attention, ffnn) in each encoder has a residual connec
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Alammar-2018-The_Illustrated_Transformer-jalammar,github,io
ives the advantage of being able to scale to unseen lengths of sequences (e.g. if our trained model is asked to translate a sentence longer than any of those in our training set). The Residuals <span>One detail in the architecture of the encoder that we need to mention before moving on, is that each sub-layer (self-attention, ffnn) in each encoder has a residual connection around it, and is followed by a layer-normalization step. If we’re to visualize the vectors and the layer-norm operation associated with self attention, it would look like this: This goes for the sub-layers of the decoder as well. If we’re to
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Alammar-2018-The_Illustrated_Transformer-jalammar,github,io
into a set of attention vectors K and V. These are to be used by each decoder in its “encoder-decoder attention” layer which helps the decoder focus on appropriate places in the input sequence: <span>After finishing the encoding phase, we begin the decoding phase. Each step in the decoding phase outputs an element from the output sequence (the English translation sentence in this case). The following steps repeat the process until a special symbol is reached indicating the transformer decoder has completed its output. The output of each step is fed to the bottom decode
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Alammar-2018-The_Illustrated_Transformer-jalammar,github,io
t sequence (the English translation sentence in this case). The following steps repeat the process until a special symbol is reached indicating the transformer decoder has completed its output. <span>The output of each step is fed to the bottom decoder in the next time step, and the decoders bubble up their decoding results just like the encoders did. And just like we did with the encoder inputs, we embed and add positional encoding to those decoder inputs to indicate the position of each word. The self attention layers in the decoder operate in a slightly different way than the one in the encoder: In the decoder, the self-attention layer is only allowed to attend to earlier p
Flashcard 4884610288908
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Alammar-2018-The_Illustrated_Transformer-jalammar,github,io
ir decoding results just like the encoders did. And just like we did with the encoder inputs, we embed and add positional encoding to those decoder inputs to indicate the position of each word. <span>The self attention layers in the decoder operate in a slightly different way than the one in the encoder: In the decoder, the self-attention layer is only allowed to attend to earlier positions in the output sequence. This is done by masking future positions (setting them to -inf) before the softmax step in the self-attention calculation. The “Encoder-Decoder Attention” layer works just like multiheaded self-attention, except it creates its Queries matrix from the layer below it, and takes the Keys and Values matrix from the output of the encoder stack. The Final Linear and Softmax Layer The decoder stack outputs a vector of floats. How do we turn that into a word? That’s the job of the final Linear layer which is followed by a Softmax
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Pasteur's quadrant - Wikipedia
Pasteur's quadrant - Wikipedia Pasteur's quadrant From Wikipedia, the free encyclopedia Jump to navigation Jump to search Pasteur's quadrant is a classification of scientific research projects that seek fundamental understanding of scientific problems, while also having immediate use for society. Louis Pasteur 's research is thought to exemplify this type of method, which bridges the gap between "basic " and "applied " research.[1] The term was introduced by Donald E. Stokes in his book, Pasteur's Quadrant.[2] Applied and basic research[edit ] As shown in the following table, scientific research can be classified by whether it advances human knowledge by seeking a fundamental understanding



| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Flashcard 4884626017548
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itwe note that in the terminology of Pasteur’s Quadrant, 11 we do “use-inspired basic” and “pure ap- plied” (CS) research.
Original toplevel document (pdf)
cannot see any pdfsFlashcard 4884627590412
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itNot only do we have to manage the software code artifacts but also the data sets, the machine learning models, and the parameters and hyperparameters used by such models. All these artifacts have to be managed, versioned and promoted through different stages until they’re deployed to production.
Original toplevel document
Sato,Wider,Windheuser_2019_Continuous-delivery_thoughtworksicient collaboration and alignment. However, this integration also brings new challenges when compared to traditional software development. These include: A higher number of changing artifacts. <span>Not only do we have to manage the software code artifacts but also the data sets, the machine learning models, and the parameters and hyperparameters used by such models. All these artifacts have to be managed, versioned and promoted through different stages until they’re deployed to production. It’s harder to achieve versioning, quality control, reliability, repeatability and audibility in that process. Size and portability: Training data and machine learning models usually co
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Flashcard 4885281901836
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4885282950412
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4885284785420
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Flashcard 4885296581900
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Flashcard 4885299989772
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Flashcard 4885309689100
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4885311524108
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Flashcard 4885316504844
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4885318339852
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4885320174860
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4885322009868
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4885323844876
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4885325679884
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4885327514892
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4885329349900
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4885331184908
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4885333019916
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4885334854924
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4885336689932
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4885338524940
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4885340359948
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4885342194956
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4885344029964
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Flashcard 4886700625164
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itconjunto completo das demonstrações contábeis”. A seguir transcrevemos referido item: Conjunto completo de demonstrações contábeis 10. O conjunto completo de demonstrações contábeis inclui: (a) <span>balanço patrimonial ao final do período; (b) demonstração do resultado do período; (ba) demonstração do resultado abrangente do período; (c) demonstração das mutações do patrimônio líquido do período; (d)
Original toplevel document (pdf)
cannot see any pdfsFlashcard 4886702198028
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itreferido item: Conjunto completo de demonstrações contábeis 10. O conjunto completo de demonstrações contábeis inclui: (a) balanço patrimonial ao final do período; (b) demonstração do resultado <span>do período; (ba) demonstração do resultado abrangente do período; (c) demonstração das mutações do patrimônio líquido do período; (d) demonstração dos fluxos de caixa do período; (da) demonstração
Original toplevel document (pdf)
cannot see any pdfsFlashcard 4886703770892
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itrações contábeis 10. O conjunto completo de demonstrações contábeis inclui: (a) balanço patrimonial ao final do período; (b) demonstração do resultado do período; (ba) demonstração do resultado <span>abrangente do período; (c) demonstração das mutações do patrimônio líquido do período; (d) demonstração dos fluxos de caixa do período; (da) demonstração do valor adicionado do período, conforme N
Original toplevel document (pdf)
cannot see any pdfsFlashcard 4886705343756
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itdemonstrações contábeis inclui: (a) balanço patrimonial ao final do período; (b) demonstração do resultado do período; (ba) demonstração do resultado abrangente do período; (c) demonstração das <span>mutações do patrimônio líquido do período; (d) demonstração dos fluxos de caixa do período; (da) demonstração do valor adicionado do período, conforme NBC TG 09 – Demonstração do Valor Adicionad
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Flashcard 4886852406540

| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |