Edited, memorised or added to reading queue
on 19-Jun-2024 (Wed)
Do you want BuboFlash to help you learning these things? Click here to log in or create user.

| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Grundprinzipien der Rechnerarchitektur
und das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! <span>Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. Da das Ziel eines Sprungbefehles oft erst festgestellt werden muss, liegt diese Adresse erst ab der MEM ACCESS Phase bereit. Somit kann das erneute Laden des Programmcounters auch erst in dieser Phase geschehen. So verzögert sich das Holen des nächsten Befehles um einige Takte. Durch eine Optimierung der Pipeline kann zwar die stall-Phase verkleinert, aber nicht ausgeschlossen werden. (durch Verlegung des Sprungbedingungstests in die Decode-Phase) Welche Methoden gibt es zur Reduzierung von Sprungverlusten? Predict Not Taken / Predict-Taken (fixed prediction) Objektcode basiert (statisch) dynamisch Brach-Prediction mit History Buffern (correlating / non-correlating) Delayed-Branch Wie funktioniert die Predict-Not-Taken bzw. Predict-Taken Methodik? Hier wird nichts weiter gemacht als entweder alle Sprünge voreingestellt abzulehnen oder alle Sprünge ersteinmal ohne Gewähr duchzuführen. Allgemeine Programmstatistiken sagen aus, dass mehr bedingte Sprünge ausgeführt als abgewiesen werden. Wie funktioniert die Delayed-Branch Methode? Hier wird ein sprungunabhängiger Befehl in den Delay Slot eingeschleust. Dies muss somit schon von den Compilerbauern berücksichtigt werden. Um diese Bedingung zu Umgehen wird die "Cancelling Branches"-Technik eingesetzt. Im Mittel werden dann trotzdem die Branch-Verluste verringert. Durch ein zusätzliches Bit im Befehlscode gibt der Compiler die wahrscheinlichste Sprungrichtung an. Nun kann entsprechend dieser Annahme ein Befehl in den Delay Slot eingefügt werden, der nur gültig ist, wenn der Sprung richtig vorhergesagt war. Falls nicht wird der Delay-Slot-Befehl abgebrochen (gecancelt). Dynamische Branch-Prediction Um Wartezeiten durch bedingte Sprünge zu vermeiden, sollte das Sprungziel schon mit dem Ende der Fetch-Phase zur Verfügung stehen. Es gibt zwei Ansätze Sprungzielspeicher (branch-target-buffer = BTB) Sprungvorhersage-Puffer (Branch History Table = BHT) Wie arbeitet eine Branch History Table? In dieser Tabelle wird im Grunde nur durch ein Bit (oder mehr) vermerkt, ob ein Sprung durchgeführt wurde oder nicht. Als Index der Tabelle dient der niederwertige Teil der Adresse des dazugehörigen Sprungbefehls. Nun kann die Pipeline in der Fetchphase nach einem eventuell vorhandenen Eintrag schauen und diesen als Entscheidungsgrundlage nehmen. Welchen Nachteil hat die 1-Bit Sprungvorhersage? Es wird nicht nur bei einem Schleifenaustritt der Sprung falsch vorhergesagt, sondern auch die erste Vorhersage bei erneuter Verwendung der Schleife. Wie arbeitet die 2-Bit-Sprungvorhersage mit BHT? Durch einen einfachen Zähler kann man den Nachteil der 1-Bit-Vorhersage minimieren. Hier wird die Vorhersage erst geändert, wenn sie zweimal falsch war. Es hat sich gezeigt, daß durch Zähler mit mehr als 2 Bit sich die Performance nicht weiter signifikant erhöhen läßt. Abb.: 2-Bit-Sprungvorhersagenautomat Wie arbeitet der Branch-Target-Buffer? Hier wird die Zieladresse eines gemachten Sprungs direkt gespeichert, um diese gegebenfalls ohne Verzögerung wiederzuverwenden. So kann bei einem Hit (Index stimmt mit Befehlsadresse überein) sofort der Instruction Counter mit der dazugehörigen Sprungadresse geladen werden). Exeptions Exeptions unterbrechen den Programmablauf Aufgrund verschiedenster Fehler oder Anforderungen, wie Softwareinterrupts, Page Faults oder anderen Verletzungen. Bei synchronen Exeptions treten die Fehler stehts an der gleichen Programmstelle auf. Asynchrone werden durch externe Geräte ausgelöst und können nach dem laufenden Befehl ausgeführt werden. Was sind Precice Exeptions? Sind Exeptions, welche garantieren, dass die Exeptions direkt nach oder während des Befehles ausgeführt werden und kein Folgebefehl vorher abgearbeitet wird. Zusammenfassung der Sprungvorhersage Sprungvorhersage ist extrem wichtig für Pipelining und Superskalarität, um stalls und Verzögerungen zu minimieren. Bei statischer Vorhersage werden Rückwärtssprünge meist erst durchgeführt und Vorwärtssprünge nicht. Wurde ein Sprung falsch vorhergesagt, muss die angefangene Instruktion rückgängig gemacht werden, was aufwendig ist. Deshalb gibt es ausgeklügelte Verfahren für die Branch Prediction. Statische Sprungvorhersage Es werden Compiler benutzt, die spezielle Sprungbefehle mitführen, welche ein Bit für die Sprungvorhersage enthalten. Da der Compiler ja weiß, wie oft eine Schleife durchlaufen wird, ist das sehr effizient. Dies muss aber architektonisch von der Hardware unterstützt werden. Des Weiteren ist kein Speicher für die History Table notwendig, was es kostengünstiger macht. Statische Verfahren erreichen eine Trefferrate von 65 bis 85%, was für moderne CPU's mit Superpipelines zu wenig ist. Dynamische Verfahren erreichen Trefferraten bei der Vorhersage von 98% und mehr! Dynamische Sprungvorhersage Es gibt zwei grundlegende Methoden. BHT und BTB. Die Branch History Table (Branch Predicion Buffer) ist ein Cache, in der alle bedingten Sprünge protokolliert werden. ( bis zu mehereren Tausend) Einfachste Version enthält ein Valid-Bit (Branch taken oder nicht), welches durch den niederwertigen Teil der Sprungadresse adressiert wird. Kompliziere Implementationen arbeiten nach dem n-Wege Prinzip. Durch Second Chance kann dieses Verfahren noch verbessert werden. Der Branch Target Buffer speichert nicht nur die taken-Bits, sondern auch die Sprungzieladresse, um null Verluste bei wiederholtem Aufruf zu haben. Das setzt voraus, dass nur taken branches aufgenommen werden. Bei einem Hit in der BTB kann somit während der Fetch Phase der Program Counter überschrieben werden. Werden keine History Bits mitgeführt spricht man vom BTAB. Wie arbeitet Second Chance? Nach Beenden einer Schleife wird ein Sprung logischerweise falsch vorhergesagt. Um zu vermeiden, dass nun fälschlicherweise das Sprungbit falsch gesetzt wird (da ja die gleiche Schleife noch mal durchlaufen werden kann), ändert man dieses erst nach der zweiten falschen Vorhersage. Leicht zu implementieren als Finite State Machine mit vier Zuständen. Nachteil der dynamischen Vorhersage ist die notwendige teuere und komplexere Hardware. Was ist der Vorteil von BHT gegenüber BTB? Branch Target Buffer loggen nur, ob ein Sprung genommen wurde oder nicht. Daher gibt es bei MIPS-Architekturen die BTB verwenden immernoch die sogenannten Branch Delay Slots, da die Sprungadresse trotzdem neu ermittelt werden muss. BHT beseitigen diesen Nachteil, da sie die Sprungadresse mit abspeichern und diese dann sofort in den IP geladen werden kann. Was sind Correlating Predictors? Betrachten wir folgendes Codefragment, fällt uns auf, daß ein Branch Predictor, der nur einen Sprung als Entscheidungsgrundlage einbezieht, den Zusammenhang der drei Sprünge nicht erkennen kann. if (a==10) //1. Sprung a=0; if (b=0) //2. Sprung b=0; if (a!=b){ //3. Sprung ... //abhängig von 1. und 2. Sprung } Um diese Abhängigkeiten in eine Sprungvorhersage einbeziehen zu können, sind Correlating Predictors notwendig. Solche Einheiten werden oft als (m,n)-Predictors bezeichnet. protokolliert wird das Verhalten der letzten m Sprünge je mit einem n-Bit Predictor (z.B. 2-Bit Second Chance) somit wird aus 2^m*n-Bit Preticors ausgewählt, um Vorhersage für den jeweiligen Sprung zu treffen Wie werden Correlating Predictors hardwaremäßig implementiert? Das Implementieren dieser Predictors ist weitaus einfacher, als man es annehmen würde. Es wird einfach für die History-Bits ein m-Bit-Shift Register verwendet, um die letzten m Sprünge zu speichern. Welche Performancesteigerung ist durch Correlating Predictors erreichbar? Eqntott ist ein Benchmark, welches speziell mehrere voneinander abhängige Sprünge simuliert. Hier sinkt die Fehlvorhersage von 20% auf unter 8%! Beim GCC-Compiler sind dagegen keine Unterschiede zwischen Correlating Predictors und normaler 2-Bit Sprungvorhersage erkennbar. Kapitel 8 - Superskalarität Was bedeutet superskalar? Mit normalen Pipelines (Überlappen von Instruktionen) ist nur eine maximale Performance von einem Befehl / Takt technisch und theor
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open ite Eigenschaft Lokalität? Aus programmtechnischer Sicht wiederholen sich oft Befehle und ganze Programmteile. Somit werden Daten oft wiederholt angefordert. Es gibt nun zwei Arten von Lokalität: <span>Was ist Zeitliche Lokalität? Auf ein gerade zugegriffenes Datum wird sicher bald wieder zugegriffen. Was ist Räumliche Lokalität? Auf Daten, deren Adressen benachbart sind, wird mit hoher Wahrscheinlichkeit auch zugegriffen. Anzumerken ist, daß Datenzugriffe eine geringere Lokalität ze
Original toplevel document
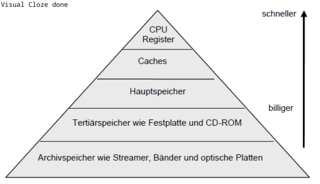
Grundprinzipien der Rechnerarchitekturaubt : ) Preemptives Multitasking ist echtes Multitasking. Ein externer Timer steuert die Umschaltung der Tasks. Die Tasks können somit keinen Einfluss auf die Betriebsmittelumschaltung nehmen. <span>Kapitel 4 - Speicherhierarchie und Caches Was bedeutet die Eigenschaft Lokalität? Aus programmtechnischer Sicht wiederholen sich oft Befehle und ganze Programmteile. Somit werden Daten oft wiederholt angefordert. Es gibt nun zwei Arten von Lokalität: Was ist Zeitliche Lokalität? Auf ein gerade zugegriffenes Datum wird sicher bald wieder zugegriffen. Was ist Räumliche Lokalität? Auf Daten, deren Adressen benachbart sind, wird mit hoher Wahrscheinlichkeit auch zugegriffen. Anzumerken ist, daß Datenzugriffe eine geringere Lokalität zeigen als Befehlszugriffe. Nach welchen Merkmalen lassen sich Caches klassifizieren? Cache-Größe (damit verbundener Hardware-Aufwand) Größe einer Cachezeile (Verschmutzungseffekt) Cache-Organisation (Vollassoziativ/Direct Mapped/Satz-Assoziativ) Schreibstrategie (Write-Through /-Allocate oder -Back) Split-Cache-Design (Transfer-Bandbreiten) Multi-level Cache-Hierarchien (Workingssetgrößen) Effective Working Set (Overflow-, Victim-, Trace Cache) Innere Cache-Parallelität (Streaming) Kohärenz-Verfahren (Snooping, MESI) Wie ist ein Cache aufgebaut? Zeile 1 Adress-Tag Datenblock Control(Bits) Zeile 2 Adress-Tag Datenblock Control(Bits) Zeile 3 Adress-Tag Datenblock Control(Bits) ... Adress-Tag Datenblock Control(Bits) Zeile n Adress-Tag Datenblock Control(Bits) Control-Bits sind z.B. Valid-Bits, Dirty-Bits und Prozess-ID. Das Adress-Tag ist nichts weiter als ein Teil der Adresse, welche bei einem Zugriff als Index gilt. Ein Datenblock ist in der Praxis meistens zwischen 16 und 64 KByte groß. Welche Cache-Arten kennen Sie? Ein Cache-Eintrag besteht aus einem Tag (Identifikator) und den Daten. Die Implementierung unterscheidet sich. Es gibt voll-, einfach assoziative und Satzassoziative Caches . Wie arbeitet ein vollassoziativer Cache? Das Tag Feld ist hier die assoziierende Adresse des Datums im Speicher. Die Hardware ist bei vollassoziativen Caches aufwendig, da diese bei einem Cache Zugriff alle Tags gleichzeitig mit der anliegenden Adresse vergleicht. Dies ist zwar extrem schnell, aber sehr teuer. Außerdem wird er sehr langsam wenn die Anzahl der Cachezeilen hinreichend groß wird. Da bei vollassoziativen Cachen ein Datum an jede Stelle des Caches platziert werden kann, muss eine Logik her, welche eine Entscheidung trifft. Als Plazierungsstrategie wird oft LRU verwendet. Dies ist seht aufwendig! Wie arbeitet ein Direct-Mapped-Cache (einfach assoziativer Cache)? Beim Direct-Mapped-Cache entscheidet eine Map-Funktion, welche Zeile im Cache mit der anliegenden Adresse referenziert wird (somit ist kein LRU o.ä. notwendig). Dabei wird einem Hauptspeicherblock genau ein Cache-Block zugeordnet (n:1 Beziehung). Oft wird eine Funktion wie (A mod Cachesize / Zeilengröße) zur Berechnung der Cachezeile aus der anliegenden Adresse benutzt, da bei diesem Verfahren dann nur (A / Cachesize) als Tag in jeder Cachezeile gespeichert werden muss. Vorteil dieser Variante ist die einfache, kostengünstige Integration (nur Komperator notwendig) und die hohe Geschwindigkeit. Leider neigt ein Direct-Mapped-Cache zu vielen Konflikten (ähnlich den Kollisionen bei Hash-Tables), welche zusätzliche Cache-Misses bildet, da mehrere Adressen auf die gleiche Cachezeile verweisen. Wie arbeitet ein n-Wege-Satz Cache (Satzassoziativer Cache)? Diese Variante ist nichts anderes als eine Implementation mehrerer parallel verknüpfter Direct-Mapped-Caches. Sie stellt quasi einen Kompromiss zwischen Cache-Effizienz und Aufwand dar. Die Arbeitsweise ist die gleiche, nur das die Map-Funktion nicht nur auf eine Zeile im Speicher zeigt, sondern auf n. Die Hardware des Caches vergleicht alle n Tags gleichzeitig, mit dem anliegenden Index. Ist eine der Tags gleich dem Index, ist dies ein Cache-Hit. Diese Technik reduziert die hohe Anfälligkeit von Direct-Mapped-Caches für Konflikte, benötigt aber mehr Chipfläche. Welche Schreibstrategien für Caches gibt es? Write-Back,Write-Throug und Write-Allocate. Write-Back-Strategie? Ein zu lesendes Datum wird entweder bei einem Hit aus dem Cache gelesen oder im Falle eines Misses, aus dem Hauptspeicher geholt und parallel in den Cache eingetragen. Im Falle der Aktualisierung, muss erst das Dirty-Bit der zu überschreibenden Cache-Line geprüft werden, um diese gegebenenfalls in den Hauptspeicher zurückzuschreiben. (Write-Back) Vorteil dieser Strategie ist das bei Hits kein Hauptspeicherverkehr oder Busbelastung auftritt. Alle Operationen können schnell innerhalb der Working-Sets mit Cache-Speed erfolgen. Somit arbeitet die CPU ungebremst. Problematisch wird dies, wenn mehrere Bus-Master am Bus hängen. Um Inkonsistenzen zu vermeiden sind dann spezielle Synchronisationsprotololle wie MESI notwendig. Concurrent Write-Back? Bei einfachen Write-Back-Caches muss die CPU im Falle eines Cache-Misses warten, bis die neue Cache-Line aus dem Speicher geholt wurde. Um diese Wartezeit im Mittel zu eliminieren, wird die alte Zeile zunächst in einen Writebuffer zwischengespeichert und später, parallel zu nachfolgenden Cache-Referenzen in den Hauptspeicher übernommen. (Sonderform: Buffered Line Refill) Wenn auch beim Lesen ein Line-(Read)-Buffer verwendet wird, spricht man von einem Streaming Cache. Write-Through-Strategie? Write-Through schreibt immer in den Hauptspeicher und falls sich eine Kopie auch im Cache befindet, so wird diese aktualisiert. Genau aus diesem Grund ist kein Rückschreiben eines Dirty-Datums notwendig, da es zu keinen Inkonsistenzen zwischen RAM und Cache kommen kann. Nachteil ist aber, dass nur bei Leseoperationen ein Geschwindigkeitsvorteil erzielt werden kann Buffered Write-Through Im Mittel erfolgen nach jeder Write-Operation zwei Read-Operationen. Deshalb kann ein Geschwindigkeitsgewinn erzielt werden, wenn ein schneller Zwischenbuffer (FiFo) vor dem Speicher plaziert wird, welcher einige Write-Operationen aufnehmen kann. Wird nun eine Leseoperation ausgeführt, so kann das Datum falls es noch in dem schnellen Buffer steht, direkt aus diesem gelesen werden. Write Allocate Hier wird immer in den Hauptspeicher und in den Cache geschrieben - auch wenn das Datum sich noch nicht im Cache befand. Zusammenspiel bei Cache-Misses Write-Allocate wird meistens mit Write-Back Strategie gemeinsam verwendet. Write-Allocate bedeutet dabei nichts weiter, als das der Hauptspeicher-Block in den Cache geladen wird. Beim No-write-Allocate (Write-Around) wird das Datum direkt im Hauptspeicher modifiziert, weshalb Write Around meist mit Write-Through verbunden wird. Zusammenfassung Caches Write-Back wird üblicherweise mit Write-Allocate kombiniert. Beim Write Allocate (fetch-on-write) wird ein Block gelesen und in Cache gespeichert. Beim No-write-allocate (write-around) wird der Block in der unteren Ebene der Speicherhierarchie modifiziert und nicht nicht im Cache geladen. No-write-allocate wird deshalb meist bei Write-through verwendet. Was ist der Unterschied zwischen einen logischen und einen physischen Cache? Physische Caches liegen vor der MMU und speichern somit nur physikalische Adressen. Ein logischer Cache liegt zwischen CPU und MMU und speichert logische Adressen. Vorteil von logischen Caches ist daher, dass die Adressumrechnung bei einem Hit entfällt. Ein großer Nachteil sind aber die Synonym-Probleme bei Multiprozessorsystemen. Des weiteren wird bei Taskwechsel ein Cache-Flush notwendig. Multi-Level-Caches und Split-Caches Durch Hintereinanderlegen von verschiedenen Caches kann ein gleitender Übergang zu immer größeren und langsameren Speichern erreicht werden. First Level Caches sind meist n-Wege-Satzassoziativ und folgende Direct-Mapped. Split-Caches trennen Code und Daten und sind somit viel flexibler und besser an das Zugriffsverhalten in Bezug auf Strategie oder Assoziativität zu optimieren. Dabei unterscheidet man eine Havard-Architektur von der multiplexed Havard-Architektur (von Neumann Prinzip). Die reine Harvard trennt nicht nur Cache sondern auch den Hauptspeicher in Daten und Codebereich. Bei von Neumann liegen Daten und Code zusammen im Hauptspeicher und werden nur im Cache getrennt. Durch Trennung von Code und Daten verdoppelt sich die Bandbreite, da zeitgleich zugegriffen werden kann. Was geschieht wenn kein Platz mehr im Cache vorhanden ist? Es muss eine Cache-Line ausgewählt werden, die mit den neuen benötigten Daten überschrieben werden kann. Die Auswahl erfolgt meistens mit LRU - Last Recently Used. D.h. die am längsten nicht genutzte Cache-Line fliegt raus. Was ist ein Burst-Cache? Burst Caches schreiben nicht nur eine Zeile in den Speicher zurück, sondern gleich mehrere, um die Bandbreite auszunutzen und somit Zeit zu sparen. Zusammenhänge zwischen Caches, TLB's und Page Tables Folgende vier Fragen stellen sich bei Caches, TLB's und auch bei Page Tables: Wo kann ein Block eingelagert werden? (Direct Mapped also nur an einem Ort, Set Assoziativ an mehreren Orten oder Voll Assoziativ, also überall) Wie kann ein Block gefunden werden? (indexiert, limitierte Suche, komplette Suche oder lookup table wie Page Tables) Wie wird ein Block bei einem Miss aktualisiert? (normalerweise über LRU oder random Methoden) Wie wird mit Schreiboperationen umgegangen? (Write Through oder Write Back) Ein TLB ist ein Translation Lookaside Buffer und ist ein kleiner Cache für die Page Table, um Seitenzugriffe zu beschleunigen. Was ist ein Trace-Cache Ein Trace Cache ist ein spezieller Befehlscache, der "Traces" des aktuellen Programmlauf protokolliert. Dabei speichert jede Zeile einen Trace, welcher typisch mehrere taken branches enthalten kann. Befehlsfolgen, die aufgrund von taken branches (weit) auseinander liegen, werden in kontinuierlicher Folge abgespeichert. Gepaart mit multiple branch prediction können mehrere zusammenhängende Basisblöcke parallel gefetched werden. (ergibt hohe issue rate) Kapitel 5 - Risc Wie berechnet sich die Prozessorleistung? Die Prozessorleistung ist umgekehrt proportional zur Ausführungszeit eines Algorithmus und wird aus folgenden drei Parametern
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itmteile. Somit werden Daten oft wiederholt angefordert. Es gibt nun zwei Arten von Lokalität: Was ist Zeitliche Lokalität? Auf ein gerade zugegriffenes Datum wird sicher bald wieder zugegriffen. <span>Was ist Räumliche Lokalität? Auf Daten, deren Adressen benachbart sind, wird mit hoher Wahrscheinlichkeit auch zugegriffen. Anzumerken ist, daß Datenzugriffe eine geringere Lokalität zeigen als Befehlszugriffe. Nach welchen Merkmalen lassen sich Caches klassifizieren? Cache-Größe (damit verbundener Hardware-Aufwand) Größe einer Cachezeile (Verschmutzungseffekt) Cache-Organisation (Vollassoziat
Original toplevel document
Grundprinzipien der Rechnerarchitekturaubt : ) Preemptives Multitasking ist echtes Multitasking. Ein externer Timer steuert die Umschaltung der Tasks. Die Tasks können somit keinen Einfluss auf die Betriebsmittelumschaltung nehmen. <span>Kapitel 4 - Speicherhierarchie und Caches Was bedeutet die Eigenschaft Lokalität? Aus programmtechnischer Sicht wiederholen sich oft Befehle und ganze Programmteile. Somit werden Daten oft wiederholt angefordert. Es gibt nun zwei Arten von Lokalität: Was ist Zeitliche Lokalität? Auf ein gerade zugegriffenes Datum wird sicher bald wieder zugegriffen. Was ist Räumliche Lokalität? Auf Daten, deren Adressen benachbart sind, wird mit hoher Wahrscheinlichkeit auch zugegriffen. Anzumerken ist, daß Datenzugriffe eine geringere Lokalität zeigen als Befehlszugriffe. Nach welchen Merkmalen lassen sich Caches klassifizieren? Cache-Größe (damit verbundener Hardware-Aufwand) Größe einer Cachezeile (Verschmutzungseffekt) Cache-Organisation (Vollassoziativ/Direct Mapped/Satz-Assoziativ) Schreibstrategie (Write-Through /-Allocate oder -Back) Split-Cache-Design (Transfer-Bandbreiten) Multi-level Cache-Hierarchien (Workingssetgrößen) Effective Working Set (Overflow-, Victim-, Trace Cache) Innere Cache-Parallelität (Streaming) Kohärenz-Verfahren (Snooping, MESI) Wie ist ein Cache aufgebaut? Zeile 1 Adress-Tag Datenblock Control(Bits) Zeile 2 Adress-Tag Datenblock Control(Bits) Zeile 3 Adress-Tag Datenblock Control(Bits) ... Adress-Tag Datenblock Control(Bits) Zeile n Adress-Tag Datenblock Control(Bits) Control-Bits sind z.B. Valid-Bits, Dirty-Bits und Prozess-ID. Das Adress-Tag ist nichts weiter als ein Teil der Adresse, welche bei einem Zugriff als Index gilt. Ein Datenblock ist in der Praxis meistens zwischen 16 und 64 KByte groß. Welche Cache-Arten kennen Sie? Ein Cache-Eintrag besteht aus einem Tag (Identifikator) und den Daten. Die Implementierung unterscheidet sich. Es gibt voll-, einfach assoziative und Satzassoziative Caches . Wie arbeitet ein vollassoziativer Cache? Das Tag Feld ist hier die assoziierende Adresse des Datums im Speicher. Die Hardware ist bei vollassoziativen Caches aufwendig, da diese bei einem Cache Zugriff alle Tags gleichzeitig mit der anliegenden Adresse vergleicht. Dies ist zwar extrem schnell, aber sehr teuer. Außerdem wird er sehr langsam wenn die Anzahl der Cachezeilen hinreichend groß wird. Da bei vollassoziativen Cachen ein Datum an jede Stelle des Caches platziert werden kann, muss eine Logik her, welche eine Entscheidung trifft. Als Plazierungsstrategie wird oft LRU verwendet. Dies ist seht aufwendig! Wie arbeitet ein Direct-Mapped-Cache (einfach assoziativer Cache)? Beim Direct-Mapped-Cache entscheidet eine Map-Funktion, welche Zeile im Cache mit der anliegenden Adresse referenziert wird (somit ist kein LRU o.ä. notwendig). Dabei wird einem Hauptspeicherblock genau ein Cache-Block zugeordnet (n:1 Beziehung). Oft wird eine Funktion wie (A mod Cachesize / Zeilengröße) zur Berechnung der Cachezeile aus der anliegenden Adresse benutzt, da bei diesem Verfahren dann nur (A / Cachesize) als Tag in jeder Cachezeile gespeichert werden muss. Vorteil dieser Variante ist die einfache, kostengünstige Integration (nur Komperator notwendig) und die hohe Geschwindigkeit. Leider neigt ein Direct-Mapped-Cache zu vielen Konflikten (ähnlich den Kollisionen bei Hash-Tables), welche zusätzliche Cache-Misses bildet, da mehrere Adressen auf die gleiche Cachezeile verweisen. Wie arbeitet ein n-Wege-Satz Cache (Satzassoziativer Cache)? Diese Variante ist nichts anderes als eine Implementation mehrerer parallel verknüpfter Direct-Mapped-Caches. Sie stellt quasi einen Kompromiss zwischen Cache-Effizienz und Aufwand dar. Die Arbeitsweise ist die gleiche, nur das die Map-Funktion nicht nur auf eine Zeile im Speicher zeigt, sondern auf n. Die Hardware des Caches vergleicht alle n Tags gleichzeitig, mit dem anliegenden Index. Ist eine der Tags gleich dem Index, ist dies ein Cache-Hit. Diese Technik reduziert die hohe Anfälligkeit von Direct-Mapped-Caches für Konflikte, benötigt aber mehr Chipfläche. Welche Schreibstrategien für Caches gibt es? Write-Back,Write-Throug und Write-Allocate. Write-Back-Strategie? Ein zu lesendes Datum wird entweder bei einem Hit aus dem Cache gelesen oder im Falle eines Misses, aus dem Hauptspeicher geholt und parallel in den Cache eingetragen. Im Falle der Aktualisierung, muss erst das Dirty-Bit der zu überschreibenden Cache-Line geprüft werden, um diese gegebenenfalls in den Hauptspeicher zurückzuschreiben. (Write-Back) Vorteil dieser Strategie ist das bei Hits kein Hauptspeicherverkehr oder Busbelastung auftritt. Alle Operationen können schnell innerhalb der Working-Sets mit Cache-Speed erfolgen. Somit arbeitet die CPU ungebremst. Problematisch wird dies, wenn mehrere Bus-Master am Bus hängen. Um Inkonsistenzen zu vermeiden sind dann spezielle Synchronisationsprotololle wie MESI notwendig. Concurrent Write-Back? Bei einfachen Write-Back-Caches muss die CPU im Falle eines Cache-Misses warten, bis die neue Cache-Line aus dem Speicher geholt wurde. Um diese Wartezeit im Mittel zu eliminieren, wird die alte Zeile zunächst in einen Writebuffer zwischengespeichert und später, parallel zu nachfolgenden Cache-Referenzen in den Hauptspeicher übernommen. (Sonderform: Buffered Line Refill) Wenn auch beim Lesen ein Line-(Read)-Buffer verwendet wird, spricht man von einem Streaming Cache. Write-Through-Strategie? Write-Through schreibt immer in den Hauptspeicher und falls sich eine Kopie auch im Cache befindet, so wird diese aktualisiert. Genau aus diesem Grund ist kein Rückschreiben eines Dirty-Datums notwendig, da es zu keinen Inkonsistenzen zwischen RAM und Cache kommen kann. Nachteil ist aber, dass nur bei Leseoperationen ein Geschwindigkeitsvorteil erzielt werden kann Buffered Write-Through Im Mittel erfolgen nach jeder Write-Operation zwei Read-Operationen. Deshalb kann ein Geschwindigkeitsgewinn erzielt werden, wenn ein schneller Zwischenbuffer (FiFo) vor dem Speicher plaziert wird, welcher einige Write-Operationen aufnehmen kann. Wird nun eine Leseoperation ausgeführt, so kann das Datum falls es noch in dem schnellen Buffer steht, direkt aus diesem gelesen werden. Write Allocate Hier wird immer in den Hauptspeicher und in den Cache geschrieben - auch wenn das Datum sich noch nicht im Cache befand. Zusammenspiel bei Cache-Misses Write-Allocate wird meistens mit Write-Back Strategie gemeinsam verwendet. Write-Allocate bedeutet dabei nichts weiter, als das der Hauptspeicher-Block in den Cache geladen wird. Beim No-write-Allocate (Write-Around) wird das Datum direkt im Hauptspeicher modifiziert, weshalb Write Around meist mit Write-Through verbunden wird. Zusammenfassung Caches Write-Back wird üblicherweise mit Write-Allocate kombiniert. Beim Write Allocate (fetch-on-write) wird ein Block gelesen und in Cache gespeichert. Beim No-write-allocate (write-around) wird der Block in der unteren Ebene der Speicherhierarchie modifiziert und nicht nicht im Cache geladen. No-write-allocate wird deshalb meist bei Write-through verwendet. Was ist der Unterschied zwischen einen logischen und einen physischen Cache? Physische Caches liegen vor der MMU und speichern somit nur physikalische Adressen. Ein logischer Cache liegt zwischen CPU und MMU und speichert logische Adressen. Vorteil von logischen Caches ist daher, dass die Adressumrechnung bei einem Hit entfällt. Ein großer Nachteil sind aber die Synonym-Probleme bei Multiprozessorsystemen. Des weiteren wird bei Taskwechsel ein Cache-Flush notwendig. Multi-Level-Caches und Split-Caches Durch Hintereinanderlegen von verschiedenen Caches kann ein gleitender Übergang zu immer größeren und langsameren Speichern erreicht werden. First Level Caches sind meist n-Wege-Satzassoziativ und folgende Direct-Mapped. Split-Caches trennen Code und Daten und sind somit viel flexibler und besser an das Zugriffsverhalten in Bezug auf Strategie oder Assoziativität zu optimieren. Dabei unterscheidet man eine Havard-Architektur von der multiplexed Havard-Architektur (von Neumann Prinzip). Die reine Harvard trennt nicht nur Cache sondern auch den Hauptspeicher in Daten und Codebereich. Bei von Neumann liegen Daten und Code zusammen im Hauptspeicher und werden nur im Cache getrennt. Durch Trennung von Code und Daten verdoppelt sich die Bandbreite, da zeitgleich zugegriffen werden kann. Was geschieht wenn kein Platz mehr im Cache vorhanden ist? Es muss eine Cache-Line ausgewählt werden, die mit den neuen benötigten Daten überschrieben werden kann. Die Auswahl erfolgt meistens mit LRU - Last Recently Used. D.h. die am längsten nicht genutzte Cache-Line fliegt raus. Was ist ein Burst-Cache? Burst Caches schreiben nicht nur eine Zeile in den Speicher zurück, sondern gleich mehrere, um die Bandbreite auszunutzen und somit Zeit zu sparen. Zusammenhänge zwischen Caches, TLB's und Page Tables Folgende vier Fragen stellen sich bei Caches, TLB's und auch bei Page Tables: Wo kann ein Block eingelagert werden? (Direct Mapped also nur an einem Ort, Set Assoziativ an mehreren Orten oder Voll Assoziativ, also überall) Wie kann ein Block gefunden werden? (indexiert, limitierte Suche, komplette Suche oder lookup table wie Page Tables) Wie wird ein Block bei einem Miss aktualisiert? (normalerweise über LRU oder random Methoden) Wie wird mit Schreiboperationen umgegangen? (Write Through oder Write Back) Ein TLB ist ein Translation Lookaside Buffer und ist ein kleiner Cache für die Page Table, um Seitenzugriffe zu beschleunigen. Was ist ein Trace-Cache Ein Trace Cache ist ein spezieller Befehlscache, der "Traces" des aktuellen Programmlauf protokolliert. Dabei speichert jede Zeile einen Trace, welcher typisch mehrere taken branches enthalten kann. Befehlsfolgen, die aufgrund von taken branches (weit) auseinander liegen, werden in kontinuierlicher Folge abgespeichert. Gepaart mit multiple branch prediction können mehrere zusammenhängende Basisblöcke parallel gefetched werden. (ergibt hohe issue rate) Kapitel 5 - Risc Wie berechnet sich die Prozessorleistung? Die Prozessorleistung ist umgekehrt proportional zur Ausführungszeit eines Algorithmus und wird aus folgenden drei Parametern
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itLokalität? Auf Daten, deren Adressen benachbart sind, wird mit hoher Wahrscheinlichkeit auch zugegriffen. Anzumerken ist, daß Datenzugriffe eine geringere Lokalität zeigen als Befehlszugriffe. <span>Nach welchen Merkmalen lassen sich Caches klassifizieren? Cache-Größe (damit verbundener Hardware-Aufwand) Größe einer Cachezeile (Verschmutzungseffekt) Cache-Organisation (Vollassoziativ/Direct Mapped/Satz-Assoziativ) Schreibstrategie (Write-Through /-Allocate oder -Back) Split-Cache-Design (Transfer-Bandbreiten) Multi-level Cache-Hierarchien (Workingssetgrößen) Effective Working Set (Overflow-, Victim-, Trace Cache) Innere Cache-Parallelität (Streaming) Kohärenz-Verfahren (Snooping, MESI) Wie ist ein Cache aufgebaut? Zeile 1 Adress-Tag Datenblock Control(Bits) Zeile 2 Adress-Tag Datenblock Control(Bits) Zeile 3 Adress-Tag Datenblock Control(Bits) ... Adress-Tag Datenblock Control(Bits) Zeile n Adress-Tag Datenblock Control(Bits) Control-Bits sind z.B. Valid-Bits, Dirty-Bits und Prozess-ID. Das Adress-Tag ist nichts weiter als ein Teil der Adresse, welche bei einem Zugriff als Index gilt. Ein Datenblock ist in der Praxis meistens zwischen 16 und 64 KByte groß. Welche Cache-Arten kennen Sie? Ein Cache-Eintrag besteht aus einem Tag (Identifikator) und den Daten. Die Implementierung unterscheidet sich. Es gibt voll-, einfach assoziative und Satz
Original toplevel document
Grundprinzipien der Rechnerarchitekturaubt : ) Preemptives Multitasking ist echtes Multitasking. Ein externer Timer steuert die Umschaltung der Tasks. Die Tasks können somit keinen Einfluss auf die Betriebsmittelumschaltung nehmen. <span>Kapitel 4 - Speicherhierarchie und Caches Was bedeutet die Eigenschaft Lokalität? Aus programmtechnischer Sicht wiederholen sich oft Befehle und ganze Programmteile. Somit werden Daten oft wiederholt angefordert. Es gibt nun zwei Arten von Lokalität: Was ist Zeitliche Lokalität? Auf ein gerade zugegriffenes Datum wird sicher bald wieder zugegriffen. Was ist Räumliche Lokalität? Auf Daten, deren Adressen benachbart sind, wird mit hoher Wahrscheinlichkeit auch zugegriffen. Anzumerken ist, daß Datenzugriffe eine geringere Lokalität zeigen als Befehlszugriffe. Nach welchen Merkmalen lassen sich Caches klassifizieren? Cache-Größe (damit verbundener Hardware-Aufwand) Größe einer Cachezeile (Verschmutzungseffekt) Cache-Organisation (Vollassoziativ/Direct Mapped/Satz-Assoziativ) Schreibstrategie (Write-Through /-Allocate oder -Back) Split-Cache-Design (Transfer-Bandbreiten) Multi-level Cache-Hierarchien (Workingssetgrößen) Effective Working Set (Overflow-, Victim-, Trace Cache) Innere Cache-Parallelität (Streaming) Kohärenz-Verfahren (Snooping, MESI) Wie ist ein Cache aufgebaut? Zeile 1 Adress-Tag Datenblock Control(Bits) Zeile 2 Adress-Tag Datenblock Control(Bits) Zeile 3 Adress-Tag Datenblock Control(Bits) ... Adress-Tag Datenblock Control(Bits) Zeile n Adress-Tag Datenblock Control(Bits) Control-Bits sind z.B. Valid-Bits, Dirty-Bits und Prozess-ID. Das Adress-Tag ist nichts weiter als ein Teil der Adresse, welche bei einem Zugriff als Index gilt. Ein Datenblock ist in der Praxis meistens zwischen 16 und 64 KByte groß. Welche Cache-Arten kennen Sie? Ein Cache-Eintrag besteht aus einem Tag (Identifikator) und den Daten. Die Implementierung unterscheidet sich. Es gibt voll-, einfach assoziative und Satzassoziative Caches . Wie arbeitet ein vollassoziativer Cache? Das Tag Feld ist hier die assoziierende Adresse des Datums im Speicher. Die Hardware ist bei vollassoziativen Caches aufwendig, da diese bei einem Cache Zugriff alle Tags gleichzeitig mit der anliegenden Adresse vergleicht. Dies ist zwar extrem schnell, aber sehr teuer. Außerdem wird er sehr langsam wenn die Anzahl der Cachezeilen hinreichend groß wird. Da bei vollassoziativen Cachen ein Datum an jede Stelle des Caches platziert werden kann, muss eine Logik her, welche eine Entscheidung trifft. Als Plazierungsstrategie wird oft LRU verwendet. Dies ist seht aufwendig! Wie arbeitet ein Direct-Mapped-Cache (einfach assoziativer Cache)? Beim Direct-Mapped-Cache entscheidet eine Map-Funktion, welche Zeile im Cache mit der anliegenden Adresse referenziert wird (somit ist kein LRU o.ä. notwendig). Dabei wird einem Hauptspeicherblock genau ein Cache-Block zugeordnet (n:1 Beziehung). Oft wird eine Funktion wie (A mod Cachesize / Zeilengröße) zur Berechnung der Cachezeile aus der anliegenden Adresse benutzt, da bei diesem Verfahren dann nur (A / Cachesize) als Tag in jeder Cachezeile gespeichert werden muss. Vorteil dieser Variante ist die einfache, kostengünstige Integration (nur Komperator notwendig) und die hohe Geschwindigkeit. Leider neigt ein Direct-Mapped-Cache zu vielen Konflikten (ähnlich den Kollisionen bei Hash-Tables), welche zusätzliche Cache-Misses bildet, da mehrere Adressen auf die gleiche Cachezeile verweisen. Wie arbeitet ein n-Wege-Satz Cache (Satzassoziativer Cache)? Diese Variante ist nichts anderes als eine Implementation mehrerer parallel verknüpfter Direct-Mapped-Caches. Sie stellt quasi einen Kompromiss zwischen Cache-Effizienz und Aufwand dar. Die Arbeitsweise ist die gleiche, nur das die Map-Funktion nicht nur auf eine Zeile im Speicher zeigt, sondern auf n. Die Hardware des Caches vergleicht alle n Tags gleichzeitig, mit dem anliegenden Index. Ist eine der Tags gleich dem Index, ist dies ein Cache-Hit. Diese Technik reduziert die hohe Anfälligkeit von Direct-Mapped-Caches für Konflikte, benötigt aber mehr Chipfläche. Welche Schreibstrategien für Caches gibt es? Write-Back,Write-Throug und Write-Allocate. Write-Back-Strategie? Ein zu lesendes Datum wird entweder bei einem Hit aus dem Cache gelesen oder im Falle eines Misses, aus dem Hauptspeicher geholt und parallel in den Cache eingetragen. Im Falle der Aktualisierung, muss erst das Dirty-Bit der zu überschreibenden Cache-Line geprüft werden, um diese gegebenenfalls in den Hauptspeicher zurückzuschreiben. (Write-Back) Vorteil dieser Strategie ist das bei Hits kein Hauptspeicherverkehr oder Busbelastung auftritt. Alle Operationen können schnell innerhalb der Working-Sets mit Cache-Speed erfolgen. Somit arbeitet die CPU ungebremst. Problematisch wird dies, wenn mehrere Bus-Master am Bus hängen. Um Inkonsistenzen zu vermeiden sind dann spezielle Synchronisationsprotololle wie MESI notwendig. Concurrent Write-Back? Bei einfachen Write-Back-Caches muss die CPU im Falle eines Cache-Misses warten, bis die neue Cache-Line aus dem Speicher geholt wurde. Um diese Wartezeit im Mittel zu eliminieren, wird die alte Zeile zunächst in einen Writebuffer zwischengespeichert und später, parallel zu nachfolgenden Cache-Referenzen in den Hauptspeicher übernommen. (Sonderform: Buffered Line Refill) Wenn auch beim Lesen ein Line-(Read)-Buffer verwendet wird, spricht man von einem Streaming Cache. Write-Through-Strategie? Write-Through schreibt immer in den Hauptspeicher und falls sich eine Kopie auch im Cache befindet, so wird diese aktualisiert. Genau aus diesem Grund ist kein Rückschreiben eines Dirty-Datums notwendig, da es zu keinen Inkonsistenzen zwischen RAM und Cache kommen kann. Nachteil ist aber, dass nur bei Leseoperationen ein Geschwindigkeitsvorteil erzielt werden kann Buffered Write-Through Im Mittel erfolgen nach jeder Write-Operation zwei Read-Operationen. Deshalb kann ein Geschwindigkeitsgewinn erzielt werden, wenn ein schneller Zwischenbuffer (FiFo) vor dem Speicher plaziert wird, welcher einige Write-Operationen aufnehmen kann. Wird nun eine Leseoperation ausgeführt, so kann das Datum falls es noch in dem schnellen Buffer steht, direkt aus diesem gelesen werden. Write Allocate Hier wird immer in den Hauptspeicher und in den Cache geschrieben - auch wenn das Datum sich noch nicht im Cache befand. Zusammenspiel bei Cache-Misses Write-Allocate wird meistens mit Write-Back Strategie gemeinsam verwendet. Write-Allocate bedeutet dabei nichts weiter, als das der Hauptspeicher-Block in den Cache geladen wird. Beim No-write-Allocate (Write-Around) wird das Datum direkt im Hauptspeicher modifiziert, weshalb Write Around meist mit Write-Through verbunden wird. Zusammenfassung Caches Write-Back wird üblicherweise mit Write-Allocate kombiniert. Beim Write Allocate (fetch-on-write) wird ein Block gelesen und in Cache gespeichert. Beim No-write-allocate (write-around) wird der Block in der unteren Ebene der Speicherhierarchie modifiziert und nicht nicht im Cache geladen. No-write-allocate wird deshalb meist bei Write-through verwendet. Was ist der Unterschied zwischen einen logischen und einen physischen Cache? Physische Caches liegen vor der MMU und speichern somit nur physikalische Adressen. Ein logischer Cache liegt zwischen CPU und MMU und speichert logische Adressen. Vorteil von logischen Caches ist daher, dass die Adressumrechnung bei einem Hit entfällt. Ein großer Nachteil sind aber die Synonym-Probleme bei Multiprozessorsystemen. Des weiteren wird bei Taskwechsel ein Cache-Flush notwendig. Multi-Level-Caches und Split-Caches Durch Hintereinanderlegen von verschiedenen Caches kann ein gleitender Übergang zu immer größeren und langsameren Speichern erreicht werden. First Level Caches sind meist n-Wege-Satzassoziativ und folgende Direct-Mapped. Split-Caches trennen Code und Daten und sind somit viel flexibler und besser an das Zugriffsverhalten in Bezug auf Strategie oder Assoziativität zu optimieren. Dabei unterscheidet man eine Havard-Architektur von der multiplexed Havard-Architektur (von Neumann Prinzip). Die reine Harvard trennt nicht nur Cache sondern auch den Hauptspeicher in Daten und Codebereich. Bei von Neumann liegen Daten und Code zusammen im Hauptspeicher und werden nur im Cache getrennt. Durch Trennung von Code und Daten verdoppelt sich die Bandbreite, da zeitgleich zugegriffen werden kann. Was geschieht wenn kein Platz mehr im Cache vorhanden ist? Es muss eine Cache-Line ausgewählt werden, die mit den neuen benötigten Daten überschrieben werden kann. Die Auswahl erfolgt meistens mit LRU - Last Recently Used. D.h. die am längsten nicht genutzte Cache-Line fliegt raus. Was ist ein Burst-Cache? Burst Caches schreiben nicht nur eine Zeile in den Speicher zurück, sondern gleich mehrere, um die Bandbreite auszunutzen und somit Zeit zu sparen. Zusammenhänge zwischen Caches, TLB's und Page Tables Folgende vier Fragen stellen sich bei Caches, TLB's und auch bei Page Tables: Wo kann ein Block eingelagert werden? (Direct Mapped also nur an einem Ort, Set Assoziativ an mehreren Orten oder Voll Assoziativ, also überall) Wie kann ein Block gefunden werden? (indexiert, limitierte Suche, komplette Suche oder lookup table wie Page Tables) Wie wird ein Block bei einem Miss aktualisiert? (normalerweise über LRU oder random Methoden) Wie wird mit Schreiboperationen umgegangen? (Write Through oder Write Back) Ein TLB ist ein Translation Lookaside Buffer und ist ein kleiner Cache für die Page Table, um Seitenzugriffe zu beschleunigen. Was ist ein Trace-Cache Ein Trace Cache ist ein spezieller Befehlscache, der "Traces" des aktuellen Programmlauf protokolliert. Dabei speichert jede Zeile einen Trace, welcher typisch mehrere taken branches enthalten kann. Befehlsfolgen, die aufgrund von taken branches (weit) auseinander liegen, werden in kontinuierlicher Folge abgespeichert. Gepaart mit multiple branch prediction können mehrere zusammenhängende Basisblöcke parallel gefetched werden. (ergibt hohe issue rate) Kapitel 5 - Risc Wie berechnet sich die Prozessorleistung? Die Prozessorleistung ist umgekehrt proportional zur Ausführungszeit eines Algorithmus und wird aus folgenden drei Parametern
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itBits und Prozess-ID. Das Adress-Tag ist nichts weiter als ein Teil der Adresse, welche bei einem Zugriff als Index gilt. Ein Datenblock ist in der Praxis meistens zwischen 16 und 64 KByte groß. <span>Welche Cache-Arten kennen Sie? Ein Cache-Eintrag besteht aus einem Tag (Identifikator) und den Daten. Die Implementierung unterscheidet sich. Es gibt voll-, einfach assoziative und Satzassoziative Caches . Wie arbeitet ein vollassoziativer Cache? Das Tag Feld ist hier die assoziierende Adresse des Datums im Speicher. Die Hardware ist bei vollassoziativen Caches aufwendig, da diese bei ein
Original toplevel document
Grundprinzipien der Rechnerarchitekturaubt : ) Preemptives Multitasking ist echtes Multitasking. Ein externer Timer steuert die Umschaltung der Tasks. Die Tasks können somit keinen Einfluss auf die Betriebsmittelumschaltung nehmen. <span>Kapitel 4 - Speicherhierarchie und Caches Was bedeutet die Eigenschaft Lokalität? Aus programmtechnischer Sicht wiederholen sich oft Befehle und ganze Programmteile. Somit werden Daten oft wiederholt angefordert. Es gibt nun zwei Arten von Lokalität: Was ist Zeitliche Lokalität? Auf ein gerade zugegriffenes Datum wird sicher bald wieder zugegriffen. Was ist Räumliche Lokalität? Auf Daten, deren Adressen benachbart sind, wird mit hoher Wahrscheinlichkeit auch zugegriffen. Anzumerken ist, daß Datenzugriffe eine geringere Lokalität zeigen als Befehlszugriffe. Nach welchen Merkmalen lassen sich Caches klassifizieren? Cache-Größe (damit verbundener Hardware-Aufwand) Größe einer Cachezeile (Verschmutzungseffekt) Cache-Organisation (Vollassoziativ/Direct Mapped/Satz-Assoziativ) Schreibstrategie (Write-Through /-Allocate oder -Back) Split-Cache-Design (Transfer-Bandbreiten) Multi-level Cache-Hierarchien (Workingssetgrößen) Effective Working Set (Overflow-, Victim-, Trace Cache) Innere Cache-Parallelität (Streaming) Kohärenz-Verfahren (Snooping, MESI) Wie ist ein Cache aufgebaut? Zeile 1 Adress-Tag Datenblock Control(Bits) Zeile 2 Adress-Tag Datenblock Control(Bits) Zeile 3 Adress-Tag Datenblock Control(Bits) ... Adress-Tag Datenblock Control(Bits) Zeile n Adress-Tag Datenblock Control(Bits) Control-Bits sind z.B. Valid-Bits, Dirty-Bits und Prozess-ID. Das Adress-Tag ist nichts weiter als ein Teil der Adresse, welche bei einem Zugriff als Index gilt. Ein Datenblock ist in der Praxis meistens zwischen 16 und 64 KByte groß. Welche Cache-Arten kennen Sie? Ein Cache-Eintrag besteht aus einem Tag (Identifikator) und den Daten. Die Implementierung unterscheidet sich. Es gibt voll-, einfach assoziative und Satzassoziative Caches . Wie arbeitet ein vollassoziativer Cache? Das Tag Feld ist hier die assoziierende Adresse des Datums im Speicher. Die Hardware ist bei vollassoziativen Caches aufwendig, da diese bei einem Cache Zugriff alle Tags gleichzeitig mit der anliegenden Adresse vergleicht. Dies ist zwar extrem schnell, aber sehr teuer. Außerdem wird er sehr langsam wenn die Anzahl der Cachezeilen hinreichend groß wird. Da bei vollassoziativen Cachen ein Datum an jede Stelle des Caches platziert werden kann, muss eine Logik her, welche eine Entscheidung trifft. Als Plazierungsstrategie wird oft LRU verwendet. Dies ist seht aufwendig! Wie arbeitet ein Direct-Mapped-Cache (einfach assoziativer Cache)? Beim Direct-Mapped-Cache entscheidet eine Map-Funktion, welche Zeile im Cache mit der anliegenden Adresse referenziert wird (somit ist kein LRU o.ä. notwendig). Dabei wird einem Hauptspeicherblock genau ein Cache-Block zugeordnet (n:1 Beziehung). Oft wird eine Funktion wie (A mod Cachesize / Zeilengröße) zur Berechnung der Cachezeile aus der anliegenden Adresse benutzt, da bei diesem Verfahren dann nur (A / Cachesize) als Tag in jeder Cachezeile gespeichert werden muss. Vorteil dieser Variante ist die einfache, kostengünstige Integration (nur Komperator notwendig) und die hohe Geschwindigkeit. Leider neigt ein Direct-Mapped-Cache zu vielen Konflikten (ähnlich den Kollisionen bei Hash-Tables), welche zusätzliche Cache-Misses bildet, da mehrere Adressen auf die gleiche Cachezeile verweisen. Wie arbeitet ein n-Wege-Satz Cache (Satzassoziativer Cache)? Diese Variante ist nichts anderes als eine Implementation mehrerer parallel verknüpfter Direct-Mapped-Caches. Sie stellt quasi einen Kompromiss zwischen Cache-Effizienz und Aufwand dar. Die Arbeitsweise ist die gleiche, nur das die Map-Funktion nicht nur auf eine Zeile im Speicher zeigt, sondern auf n. Die Hardware des Caches vergleicht alle n Tags gleichzeitig, mit dem anliegenden Index. Ist eine der Tags gleich dem Index, ist dies ein Cache-Hit. Diese Technik reduziert die hohe Anfälligkeit von Direct-Mapped-Caches für Konflikte, benötigt aber mehr Chipfläche. Welche Schreibstrategien für Caches gibt es? Write-Back,Write-Throug und Write-Allocate. Write-Back-Strategie? Ein zu lesendes Datum wird entweder bei einem Hit aus dem Cache gelesen oder im Falle eines Misses, aus dem Hauptspeicher geholt und parallel in den Cache eingetragen. Im Falle der Aktualisierung, muss erst das Dirty-Bit der zu überschreibenden Cache-Line geprüft werden, um diese gegebenenfalls in den Hauptspeicher zurückzuschreiben. (Write-Back) Vorteil dieser Strategie ist das bei Hits kein Hauptspeicherverkehr oder Busbelastung auftritt. Alle Operationen können schnell innerhalb der Working-Sets mit Cache-Speed erfolgen. Somit arbeitet die CPU ungebremst. Problematisch wird dies, wenn mehrere Bus-Master am Bus hängen. Um Inkonsistenzen zu vermeiden sind dann spezielle Synchronisationsprotololle wie MESI notwendig. Concurrent Write-Back? Bei einfachen Write-Back-Caches muss die CPU im Falle eines Cache-Misses warten, bis die neue Cache-Line aus dem Speicher geholt wurde. Um diese Wartezeit im Mittel zu eliminieren, wird die alte Zeile zunächst in einen Writebuffer zwischengespeichert und später, parallel zu nachfolgenden Cache-Referenzen in den Hauptspeicher übernommen. (Sonderform: Buffered Line Refill) Wenn auch beim Lesen ein Line-(Read)-Buffer verwendet wird, spricht man von einem Streaming Cache. Write-Through-Strategie? Write-Through schreibt immer in den Hauptspeicher und falls sich eine Kopie auch im Cache befindet, so wird diese aktualisiert. Genau aus diesem Grund ist kein Rückschreiben eines Dirty-Datums notwendig, da es zu keinen Inkonsistenzen zwischen RAM und Cache kommen kann. Nachteil ist aber, dass nur bei Leseoperationen ein Geschwindigkeitsvorteil erzielt werden kann Buffered Write-Through Im Mittel erfolgen nach jeder Write-Operation zwei Read-Operationen. Deshalb kann ein Geschwindigkeitsgewinn erzielt werden, wenn ein schneller Zwischenbuffer (FiFo) vor dem Speicher plaziert wird, welcher einige Write-Operationen aufnehmen kann. Wird nun eine Leseoperation ausgeführt, so kann das Datum falls es noch in dem schnellen Buffer steht, direkt aus diesem gelesen werden. Write Allocate Hier wird immer in den Hauptspeicher und in den Cache geschrieben - auch wenn das Datum sich noch nicht im Cache befand. Zusammenspiel bei Cache-Misses Write-Allocate wird meistens mit Write-Back Strategie gemeinsam verwendet. Write-Allocate bedeutet dabei nichts weiter, als das der Hauptspeicher-Block in den Cache geladen wird. Beim No-write-Allocate (Write-Around) wird das Datum direkt im Hauptspeicher modifiziert, weshalb Write Around meist mit Write-Through verbunden wird. Zusammenfassung Caches Write-Back wird üblicherweise mit Write-Allocate kombiniert. Beim Write Allocate (fetch-on-write) wird ein Block gelesen und in Cache gespeichert. Beim No-write-allocate (write-around) wird der Block in der unteren Ebene der Speicherhierarchie modifiziert und nicht nicht im Cache geladen. No-write-allocate wird deshalb meist bei Write-through verwendet. Was ist der Unterschied zwischen einen logischen und einen physischen Cache? Physische Caches liegen vor der MMU und speichern somit nur physikalische Adressen. Ein logischer Cache liegt zwischen CPU und MMU und speichert logische Adressen. Vorteil von logischen Caches ist daher, dass die Adressumrechnung bei einem Hit entfällt. Ein großer Nachteil sind aber die Synonym-Probleme bei Multiprozessorsystemen. Des weiteren wird bei Taskwechsel ein Cache-Flush notwendig. Multi-Level-Caches und Split-Caches Durch Hintereinanderlegen von verschiedenen Caches kann ein gleitender Übergang zu immer größeren und langsameren Speichern erreicht werden. First Level Caches sind meist n-Wege-Satzassoziativ und folgende Direct-Mapped. Split-Caches trennen Code und Daten und sind somit viel flexibler und besser an das Zugriffsverhalten in Bezug auf Strategie oder Assoziativität zu optimieren. Dabei unterscheidet man eine Havard-Architektur von der multiplexed Havard-Architektur (von Neumann Prinzip). Die reine Harvard trennt nicht nur Cache sondern auch den Hauptspeicher in Daten und Codebereich. Bei von Neumann liegen Daten und Code zusammen im Hauptspeicher und werden nur im Cache getrennt. Durch Trennung von Code und Daten verdoppelt sich die Bandbreite, da zeitgleich zugegriffen werden kann. Was geschieht wenn kein Platz mehr im Cache vorhanden ist? Es muss eine Cache-Line ausgewählt werden, die mit den neuen benötigten Daten überschrieben werden kann. Die Auswahl erfolgt meistens mit LRU - Last Recently Used. D.h. die am längsten nicht genutzte Cache-Line fliegt raus. Was ist ein Burst-Cache? Burst Caches schreiben nicht nur eine Zeile in den Speicher zurück, sondern gleich mehrere, um die Bandbreite auszunutzen und somit Zeit zu sparen. Zusammenhänge zwischen Caches, TLB's und Page Tables Folgende vier Fragen stellen sich bei Caches, TLB's und auch bei Page Tables: Wo kann ein Block eingelagert werden? (Direct Mapped also nur an einem Ort, Set Assoziativ an mehreren Orten oder Voll Assoziativ, also überall) Wie kann ein Block gefunden werden? (indexiert, limitierte Suche, komplette Suche oder lookup table wie Page Tables) Wie wird ein Block bei einem Miss aktualisiert? (normalerweise über LRU oder random Methoden) Wie wird mit Schreiboperationen umgegangen? (Write Through oder Write Back) Ein TLB ist ein Translation Lookaside Buffer und ist ein kleiner Cache für die Page Table, um Seitenzugriffe zu beschleunigen. Was ist ein Trace-Cache Ein Trace Cache ist ein spezieller Befehlscache, der "Traces" des aktuellen Programmlauf protokolliert. Dabei speichert jede Zeile einen Trace, welcher typisch mehrere taken branches enthalten kann. Befehlsfolgen, die aufgrund von taken branches (weit) auseinander liegen, werden in kontinuierlicher Folge abgespeichert. Gepaart mit multiple branch prediction können mehrere zusammenhängende Basisblöcke parallel gefetched werden. (ergibt hohe issue rate) Kapitel 5 - Risc Wie berechnet sich die Prozessorleistung? Die Prozessorleistung ist umgekehrt proportional zur Ausführungszeit eines Algorithmus und wird aus folgenden drei Parametern
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open it-Arten kennen Sie? Ein Cache-Eintrag besteht aus einem Tag (Identifikator) und den Daten. Die Implementierung unterscheidet sich. Es gibt voll-, einfach assoziative und Satzassoziative Caches . <span>Wie arbeitet ein vollassoziativer Cache? Das Tag Feld ist hier die assoziierende Adresse des Datums im Speicher. Die Hardware ist bei vollassoziativen Caches aufwendig, da diese bei einem Cache Zugriff alle Tags gleichzeitig mit der anliegenden Adresse vergleicht. Dies ist zwar extrem schnell, aber sehr teuer. Außerdem wird er sehr langsam wenn die Anzahl der Cachezeilen hinreichend groß wird. Da bei vollassoziativen Cachen ein Datum an jede Stelle des Caches platziert werden kann, muss eine Logik her, welche eine Entscheidung trifft. Als Plazierungsstrategie wird oft LRU verwendet. Dies ist seht aufwendig! Wie arbeitet ein Direct-Mapped-Cache (einfach assoziativer Cache)? Beim Direct-Mapped-Cache entscheidet eine Map-Funktion, welche Zeile im Cache mit der anliegenden Adresse referenziert
Original toplevel document
Grundprinzipien der Rechnerarchitekturaubt : ) Preemptives Multitasking ist echtes Multitasking. Ein externer Timer steuert die Umschaltung der Tasks. Die Tasks können somit keinen Einfluss auf die Betriebsmittelumschaltung nehmen. <span>Kapitel 4 - Speicherhierarchie und Caches Was bedeutet die Eigenschaft Lokalität? Aus programmtechnischer Sicht wiederholen sich oft Befehle und ganze Programmteile. Somit werden Daten oft wiederholt angefordert. Es gibt nun zwei Arten von Lokalität: Was ist Zeitliche Lokalität? Auf ein gerade zugegriffenes Datum wird sicher bald wieder zugegriffen. Was ist Räumliche Lokalität? Auf Daten, deren Adressen benachbart sind, wird mit hoher Wahrscheinlichkeit auch zugegriffen. Anzumerken ist, daß Datenzugriffe eine geringere Lokalität zeigen als Befehlszugriffe. Nach welchen Merkmalen lassen sich Caches klassifizieren? Cache-Größe (damit verbundener Hardware-Aufwand) Größe einer Cachezeile (Verschmutzungseffekt) Cache-Organisation (Vollassoziativ/Direct Mapped/Satz-Assoziativ) Schreibstrategie (Write-Through /-Allocate oder -Back) Split-Cache-Design (Transfer-Bandbreiten) Multi-level Cache-Hierarchien (Workingssetgrößen) Effective Working Set (Overflow-, Victim-, Trace Cache) Innere Cache-Parallelität (Streaming) Kohärenz-Verfahren (Snooping, MESI) Wie ist ein Cache aufgebaut? Zeile 1 Adress-Tag Datenblock Control(Bits) Zeile 2 Adress-Tag Datenblock Control(Bits) Zeile 3 Adress-Tag Datenblock Control(Bits) ... Adress-Tag Datenblock Control(Bits) Zeile n Adress-Tag Datenblock Control(Bits) Control-Bits sind z.B. Valid-Bits, Dirty-Bits und Prozess-ID. Das Adress-Tag ist nichts weiter als ein Teil der Adresse, welche bei einem Zugriff als Index gilt. Ein Datenblock ist in der Praxis meistens zwischen 16 und 64 KByte groß. Welche Cache-Arten kennen Sie? Ein Cache-Eintrag besteht aus einem Tag (Identifikator) und den Daten. Die Implementierung unterscheidet sich. Es gibt voll-, einfach assoziative und Satzassoziative Caches . Wie arbeitet ein vollassoziativer Cache? Das Tag Feld ist hier die assoziierende Adresse des Datums im Speicher. Die Hardware ist bei vollassoziativen Caches aufwendig, da diese bei einem Cache Zugriff alle Tags gleichzeitig mit der anliegenden Adresse vergleicht. Dies ist zwar extrem schnell, aber sehr teuer. Außerdem wird er sehr langsam wenn die Anzahl der Cachezeilen hinreichend groß wird. Da bei vollassoziativen Cachen ein Datum an jede Stelle des Caches platziert werden kann, muss eine Logik her, welche eine Entscheidung trifft. Als Plazierungsstrategie wird oft LRU verwendet. Dies ist seht aufwendig! Wie arbeitet ein Direct-Mapped-Cache (einfach assoziativer Cache)? Beim Direct-Mapped-Cache entscheidet eine Map-Funktion, welche Zeile im Cache mit der anliegenden Adresse referenziert wird (somit ist kein LRU o.ä. notwendig). Dabei wird einem Hauptspeicherblock genau ein Cache-Block zugeordnet (n:1 Beziehung). Oft wird eine Funktion wie (A mod Cachesize / Zeilengröße) zur Berechnung der Cachezeile aus der anliegenden Adresse benutzt, da bei diesem Verfahren dann nur (A / Cachesize) als Tag in jeder Cachezeile gespeichert werden muss. Vorteil dieser Variante ist die einfache, kostengünstige Integration (nur Komperator notwendig) und die hohe Geschwindigkeit. Leider neigt ein Direct-Mapped-Cache zu vielen Konflikten (ähnlich den Kollisionen bei Hash-Tables), welche zusätzliche Cache-Misses bildet, da mehrere Adressen auf die gleiche Cachezeile verweisen. Wie arbeitet ein n-Wege-Satz Cache (Satzassoziativer Cache)? Diese Variante ist nichts anderes als eine Implementation mehrerer parallel verknüpfter Direct-Mapped-Caches. Sie stellt quasi einen Kompromiss zwischen Cache-Effizienz und Aufwand dar. Die Arbeitsweise ist die gleiche, nur das die Map-Funktion nicht nur auf eine Zeile im Speicher zeigt, sondern auf n. Die Hardware des Caches vergleicht alle n Tags gleichzeitig, mit dem anliegenden Index. Ist eine der Tags gleich dem Index, ist dies ein Cache-Hit. Diese Technik reduziert die hohe Anfälligkeit von Direct-Mapped-Caches für Konflikte, benötigt aber mehr Chipfläche. Welche Schreibstrategien für Caches gibt es? Write-Back,Write-Throug und Write-Allocate. Write-Back-Strategie? Ein zu lesendes Datum wird entweder bei einem Hit aus dem Cache gelesen oder im Falle eines Misses, aus dem Hauptspeicher geholt und parallel in den Cache eingetragen. Im Falle der Aktualisierung, muss erst das Dirty-Bit der zu überschreibenden Cache-Line geprüft werden, um diese gegebenenfalls in den Hauptspeicher zurückzuschreiben. (Write-Back) Vorteil dieser Strategie ist das bei Hits kein Hauptspeicherverkehr oder Busbelastung auftritt. Alle Operationen können schnell innerhalb der Working-Sets mit Cache-Speed erfolgen. Somit arbeitet die CPU ungebremst. Problematisch wird dies, wenn mehrere Bus-Master am Bus hängen. Um Inkonsistenzen zu vermeiden sind dann spezielle Synchronisationsprotololle wie MESI notwendig. Concurrent Write-Back? Bei einfachen Write-Back-Caches muss die CPU im Falle eines Cache-Misses warten, bis die neue Cache-Line aus dem Speicher geholt wurde. Um diese Wartezeit im Mittel zu eliminieren, wird die alte Zeile zunächst in einen Writebuffer zwischengespeichert und später, parallel zu nachfolgenden Cache-Referenzen in den Hauptspeicher übernommen. (Sonderform: Buffered Line Refill) Wenn auch beim Lesen ein Line-(Read)-Buffer verwendet wird, spricht man von einem Streaming Cache. Write-Through-Strategie? Write-Through schreibt immer in den Hauptspeicher und falls sich eine Kopie auch im Cache befindet, so wird diese aktualisiert. Genau aus diesem Grund ist kein Rückschreiben eines Dirty-Datums notwendig, da es zu keinen Inkonsistenzen zwischen RAM und Cache kommen kann. Nachteil ist aber, dass nur bei Leseoperationen ein Geschwindigkeitsvorteil erzielt werden kann Buffered Write-Through Im Mittel erfolgen nach jeder Write-Operation zwei Read-Operationen. Deshalb kann ein Geschwindigkeitsgewinn erzielt werden, wenn ein schneller Zwischenbuffer (FiFo) vor dem Speicher plaziert wird, welcher einige Write-Operationen aufnehmen kann. Wird nun eine Leseoperation ausgeführt, so kann das Datum falls es noch in dem schnellen Buffer steht, direkt aus diesem gelesen werden. Write Allocate Hier wird immer in den Hauptspeicher und in den Cache geschrieben - auch wenn das Datum sich noch nicht im Cache befand. Zusammenspiel bei Cache-Misses Write-Allocate wird meistens mit Write-Back Strategie gemeinsam verwendet. Write-Allocate bedeutet dabei nichts weiter, als das der Hauptspeicher-Block in den Cache geladen wird. Beim No-write-Allocate (Write-Around) wird das Datum direkt im Hauptspeicher modifiziert, weshalb Write Around meist mit Write-Through verbunden wird. Zusammenfassung Caches Write-Back wird üblicherweise mit Write-Allocate kombiniert. Beim Write Allocate (fetch-on-write) wird ein Block gelesen und in Cache gespeichert. Beim No-write-allocate (write-around) wird der Block in der unteren Ebene der Speicherhierarchie modifiziert und nicht nicht im Cache geladen. No-write-allocate wird deshalb meist bei Write-through verwendet. Was ist der Unterschied zwischen einen logischen und einen physischen Cache? Physische Caches liegen vor der MMU und speichern somit nur physikalische Adressen. Ein logischer Cache liegt zwischen CPU und MMU und speichert logische Adressen. Vorteil von logischen Caches ist daher, dass die Adressumrechnung bei einem Hit entfällt. Ein großer Nachteil sind aber die Synonym-Probleme bei Multiprozessorsystemen. Des weiteren wird bei Taskwechsel ein Cache-Flush notwendig. Multi-Level-Caches und Split-Caches Durch Hintereinanderlegen von verschiedenen Caches kann ein gleitender Übergang zu immer größeren und langsameren Speichern erreicht werden. First Level Caches sind meist n-Wege-Satzassoziativ und folgende Direct-Mapped. Split-Caches trennen Code und Daten und sind somit viel flexibler und besser an das Zugriffsverhalten in Bezug auf Strategie oder Assoziativität zu optimieren. Dabei unterscheidet man eine Havard-Architektur von der multiplexed Havard-Architektur (von Neumann Prinzip). Die reine Harvard trennt nicht nur Cache sondern auch den Hauptspeicher in Daten und Codebereich. Bei von Neumann liegen Daten und Code zusammen im Hauptspeicher und werden nur im Cache getrennt. Durch Trennung von Code und Daten verdoppelt sich die Bandbreite, da zeitgleich zugegriffen werden kann. Was geschieht wenn kein Platz mehr im Cache vorhanden ist? Es muss eine Cache-Line ausgewählt werden, die mit den neuen benötigten Daten überschrieben werden kann. Die Auswahl erfolgt meistens mit LRU - Last Recently Used. D.h. die am längsten nicht genutzte Cache-Line fliegt raus. Was ist ein Burst-Cache? Burst Caches schreiben nicht nur eine Zeile in den Speicher zurück, sondern gleich mehrere, um die Bandbreite auszunutzen und somit Zeit zu sparen. Zusammenhänge zwischen Caches, TLB's und Page Tables Folgende vier Fragen stellen sich bei Caches, TLB's und auch bei Page Tables: Wo kann ein Block eingelagert werden? (Direct Mapped also nur an einem Ort, Set Assoziativ an mehreren Orten oder Voll Assoziativ, also überall) Wie kann ein Block gefunden werden? (indexiert, limitierte Suche, komplette Suche oder lookup table wie Page Tables) Wie wird ein Block bei einem Miss aktualisiert? (normalerweise über LRU oder random Methoden) Wie wird mit Schreiboperationen umgegangen? (Write Through oder Write Back) Ein TLB ist ein Translation Lookaside Buffer und ist ein kleiner Cache für die Page Table, um Seitenzugriffe zu beschleunigen. Was ist ein Trace-Cache Ein Trace Cache ist ein spezieller Befehlscache, der "Traces" des aktuellen Programmlauf protokolliert. Dabei speichert jede Zeile einen Trace, welcher typisch mehrere taken branches enthalten kann. Befehlsfolgen, die aufgrund von taken branches (weit) auseinander liegen, werden in kontinuierlicher Folge abgespeichert. Gepaart mit multiple branch prediction können mehrere zusammenhängende Basisblöcke parallel gefetched werden. (ergibt hohe issue rate) Kapitel 5 - Risc Wie berechnet sich die Prozessorleistung? Die Prozessorleistung ist umgekehrt proportional zur Ausführungszeit eines Algorithmus und wird aus folgenden drei Parametern
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itCachen ein Datum an jede Stelle des Caches platziert werden kann, muss eine Logik her, welche eine Entscheidung trifft. Als Plazierungsstrategie wird oft LRU verwendet. Dies ist seht aufwendig! <span>Wie arbeitet ein Direct-Mapped-Cache (einfach assoziativer Cache)? Beim Direct-Mapped-Cache entscheidet eine Map-Funktion, welche Zeile im Cache mit der anliegenden Adresse referenziert wird (somit ist kein LRU o.ä. notwendig). Dabei wird einem Hauptspeicherblock genau ein Cache-Block zugeordnet (n:1 Beziehung). Oft wird eine Funktion wie (A mod Cachesize / Zeilengröße) zur Berechnung der Cachezeile aus der anliegenden Adresse benutzt, da bei diesem Verfahren dann nur (A / Cachesize) als Tag in jeder Cachezeile gespeichert werden muss. Vorteil dieser Variante ist die einfache, kostengünstige Integration (nur Komperator notwendig) und die hohe Geschwindigkeit. Leider neigt ein Direct-Mapped-Cache zu vielen Konflikten (ähnlich den Kollisionen bei Hash-Tables), welche zusätzliche Cache-Misses bildet, da mehrere Adressen auf die gleiche Cachezeile verweisen. Wie arbeitet ein n-Wege-Satz Cache (Satzassoziativer Cache)? Diese Variante ist nichts anderes als eine Implementation mehrerer parallel verknüpfter Direct-Mapped-Caches. Sie stellt qua
Original toplevel document
Grundprinzipien der Rechnerarchitekturaubt : ) Preemptives Multitasking ist echtes Multitasking. Ein externer Timer steuert die Umschaltung der Tasks. Die Tasks können somit keinen Einfluss auf die Betriebsmittelumschaltung nehmen. <span>Kapitel 4 - Speicherhierarchie und Caches Was bedeutet die Eigenschaft Lokalität? Aus programmtechnischer Sicht wiederholen sich oft Befehle und ganze Programmteile. Somit werden Daten oft wiederholt angefordert. Es gibt nun zwei Arten von Lokalität: Was ist Zeitliche Lokalität? Auf ein gerade zugegriffenes Datum wird sicher bald wieder zugegriffen. Was ist Räumliche Lokalität? Auf Daten, deren Adressen benachbart sind, wird mit hoher Wahrscheinlichkeit auch zugegriffen. Anzumerken ist, daß Datenzugriffe eine geringere Lokalität zeigen als Befehlszugriffe. Nach welchen Merkmalen lassen sich Caches klassifizieren? Cache-Größe (damit verbundener Hardware-Aufwand) Größe einer Cachezeile (Verschmutzungseffekt) Cache-Organisation (Vollassoziativ/Direct Mapped/Satz-Assoziativ) Schreibstrategie (Write-Through /-Allocate oder -Back) Split-Cache-Design (Transfer-Bandbreiten) Multi-level Cache-Hierarchien (Workingssetgrößen) Effective Working Set (Overflow-, Victim-, Trace Cache) Innere Cache-Parallelität (Streaming) Kohärenz-Verfahren (Snooping, MESI) Wie ist ein Cache aufgebaut? Zeile 1 Adress-Tag Datenblock Control(Bits) Zeile 2 Adress-Tag Datenblock Control(Bits) Zeile 3 Adress-Tag Datenblock Control(Bits) ... Adress-Tag Datenblock Control(Bits) Zeile n Adress-Tag Datenblock Control(Bits) Control-Bits sind z.B. Valid-Bits, Dirty-Bits und Prozess-ID. Das Adress-Tag ist nichts weiter als ein Teil der Adresse, welche bei einem Zugriff als Index gilt. Ein Datenblock ist in der Praxis meistens zwischen 16 und 64 KByte groß. Welche Cache-Arten kennen Sie? Ein Cache-Eintrag besteht aus einem Tag (Identifikator) und den Daten. Die Implementierung unterscheidet sich. Es gibt voll-, einfach assoziative und Satzassoziative Caches . Wie arbeitet ein vollassoziativer Cache? Das Tag Feld ist hier die assoziierende Adresse des Datums im Speicher. Die Hardware ist bei vollassoziativen Caches aufwendig, da diese bei einem Cache Zugriff alle Tags gleichzeitig mit der anliegenden Adresse vergleicht. Dies ist zwar extrem schnell, aber sehr teuer. Außerdem wird er sehr langsam wenn die Anzahl der Cachezeilen hinreichend groß wird. Da bei vollassoziativen Cachen ein Datum an jede Stelle des Caches platziert werden kann, muss eine Logik her, welche eine Entscheidung trifft. Als Plazierungsstrategie wird oft LRU verwendet. Dies ist seht aufwendig! Wie arbeitet ein Direct-Mapped-Cache (einfach assoziativer Cache)? Beim Direct-Mapped-Cache entscheidet eine Map-Funktion, welche Zeile im Cache mit der anliegenden Adresse referenziert wird (somit ist kein LRU o.ä. notwendig). Dabei wird einem Hauptspeicherblock genau ein Cache-Block zugeordnet (n:1 Beziehung). Oft wird eine Funktion wie (A mod Cachesize / Zeilengröße) zur Berechnung der Cachezeile aus der anliegenden Adresse benutzt, da bei diesem Verfahren dann nur (A / Cachesize) als Tag in jeder Cachezeile gespeichert werden muss. Vorteil dieser Variante ist die einfache, kostengünstige Integration (nur Komperator notwendig) und die hohe Geschwindigkeit. Leider neigt ein Direct-Mapped-Cache zu vielen Konflikten (ähnlich den Kollisionen bei Hash-Tables), welche zusätzliche Cache-Misses bildet, da mehrere Adressen auf die gleiche Cachezeile verweisen. Wie arbeitet ein n-Wege-Satz Cache (Satzassoziativer Cache)? Diese Variante ist nichts anderes als eine Implementation mehrerer parallel verknüpfter Direct-Mapped-Caches. Sie stellt quasi einen Kompromiss zwischen Cache-Effizienz und Aufwand dar. Die Arbeitsweise ist die gleiche, nur das die Map-Funktion nicht nur auf eine Zeile im Speicher zeigt, sondern auf n. Die Hardware des Caches vergleicht alle n Tags gleichzeitig, mit dem anliegenden Index. Ist eine der Tags gleich dem Index, ist dies ein Cache-Hit. Diese Technik reduziert die hohe Anfälligkeit von Direct-Mapped-Caches für Konflikte, benötigt aber mehr Chipfläche. Welche Schreibstrategien für Caches gibt es? Write-Back,Write-Throug und Write-Allocate. Write-Back-Strategie? Ein zu lesendes Datum wird entweder bei einem Hit aus dem Cache gelesen oder im Falle eines Misses, aus dem Hauptspeicher geholt und parallel in den Cache eingetragen. Im Falle der Aktualisierung, muss erst das Dirty-Bit der zu überschreibenden Cache-Line geprüft werden, um diese gegebenenfalls in den Hauptspeicher zurückzuschreiben. (Write-Back) Vorteil dieser Strategie ist das bei Hits kein Hauptspeicherverkehr oder Busbelastung auftritt. Alle Operationen können schnell innerhalb der Working-Sets mit Cache-Speed erfolgen. Somit arbeitet die CPU ungebremst. Problematisch wird dies, wenn mehrere Bus-Master am Bus hängen. Um Inkonsistenzen zu vermeiden sind dann spezielle Synchronisationsprotololle wie MESI notwendig. Concurrent Write-Back? Bei einfachen Write-Back-Caches muss die CPU im Falle eines Cache-Misses warten, bis die neue Cache-Line aus dem Speicher geholt wurde. Um diese Wartezeit im Mittel zu eliminieren, wird die alte Zeile zunächst in einen Writebuffer zwischengespeichert und später, parallel zu nachfolgenden Cache-Referenzen in den Hauptspeicher übernommen. (Sonderform: Buffered Line Refill) Wenn auch beim Lesen ein Line-(Read)-Buffer verwendet wird, spricht man von einem Streaming Cache. Write-Through-Strategie? Write-Through schreibt immer in den Hauptspeicher und falls sich eine Kopie auch im Cache befindet, so wird diese aktualisiert. Genau aus diesem Grund ist kein Rückschreiben eines Dirty-Datums notwendig, da es zu keinen Inkonsistenzen zwischen RAM und Cache kommen kann. Nachteil ist aber, dass nur bei Leseoperationen ein Geschwindigkeitsvorteil erzielt werden kann Buffered Write-Through Im Mittel erfolgen nach jeder Write-Operation zwei Read-Operationen. Deshalb kann ein Geschwindigkeitsgewinn erzielt werden, wenn ein schneller Zwischenbuffer (FiFo) vor dem Speicher plaziert wird, welcher einige Write-Operationen aufnehmen kann. Wird nun eine Leseoperation ausgeführt, so kann das Datum falls es noch in dem schnellen Buffer steht, direkt aus diesem gelesen werden. Write Allocate Hier wird immer in den Hauptspeicher und in den Cache geschrieben - auch wenn das Datum sich noch nicht im Cache befand. Zusammenspiel bei Cache-Misses Write-Allocate wird meistens mit Write-Back Strategie gemeinsam verwendet. Write-Allocate bedeutet dabei nichts weiter, als das der Hauptspeicher-Block in den Cache geladen wird. Beim No-write-Allocate (Write-Around) wird das Datum direkt im Hauptspeicher modifiziert, weshalb Write Around meist mit Write-Through verbunden wird. Zusammenfassung Caches Write-Back wird üblicherweise mit Write-Allocate kombiniert. Beim Write Allocate (fetch-on-write) wird ein Block gelesen und in Cache gespeichert. Beim No-write-allocate (write-around) wird der Block in der unteren Ebene der Speicherhierarchie modifiziert und nicht nicht im Cache geladen. No-write-allocate wird deshalb meist bei Write-through verwendet. Was ist der Unterschied zwischen einen logischen und einen physischen Cache? Physische Caches liegen vor der MMU und speichern somit nur physikalische Adressen. Ein logischer Cache liegt zwischen CPU und MMU und speichert logische Adressen. Vorteil von logischen Caches ist daher, dass die Adressumrechnung bei einem Hit entfällt. Ein großer Nachteil sind aber die Synonym-Probleme bei Multiprozessorsystemen. Des weiteren wird bei Taskwechsel ein Cache-Flush notwendig. Multi-Level-Caches und Split-Caches Durch Hintereinanderlegen von verschiedenen Caches kann ein gleitender Übergang zu immer größeren und langsameren Speichern erreicht werden. First Level Caches sind meist n-Wege-Satzassoziativ und folgende Direct-Mapped. Split-Caches trennen Code und Daten und sind somit viel flexibler und besser an das Zugriffsverhalten in Bezug auf Strategie oder Assoziativität zu optimieren. Dabei unterscheidet man eine Havard-Architektur von der multiplexed Havard-Architektur (von Neumann Prinzip). Die reine Harvard trennt nicht nur Cache sondern auch den Hauptspeicher in Daten und Codebereich. Bei von Neumann liegen Daten und Code zusammen im Hauptspeicher und werden nur im Cache getrennt. Durch Trennung von Code und Daten verdoppelt sich die Bandbreite, da zeitgleich zugegriffen werden kann. Was geschieht wenn kein Platz mehr im Cache vorhanden ist? Es muss eine Cache-Line ausgewählt werden, die mit den neuen benötigten Daten überschrieben werden kann. Die Auswahl erfolgt meistens mit LRU - Last Recently Used. D.h. die am längsten nicht genutzte Cache-Line fliegt raus. Was ist ein Burst-Cache? Burst Caches schreiben nicht nur eine Zeile in den Speicher zurück, sondern gleich mehrere, um die Bandbreite auszunutzen und somit Zeit zu sparen. Zusammenhänge zwischen Caches, TLB's und Page Tables Folgende vier Fragen stellen sich bei Caches, TLB's und auch bei Page Tables: Wo kann ein Block eingelagert werden? (Direct Mapped also nur an einem Ort, Set Assoziativ an mehreren Orten oder Voll Assoziativ, also überall) Wie kann ein Block gefunden werden? (indexiert, limitierte Suche, komplette Suche oder lookup table wie Page Tables) Wie wird ein Block bei einem Miss aktualisiert? (normalerweise über LRU oder random Methoden) Wie wird mit Schreiboperationen umgegangen? (Write Through oder Write Back) Ein TLB ist ein Translation Lookaside Buffer und ist ein kleiner Cache für die Page Table, um Seitenzugriffe zu beschleunigen. Was ist ein Trace-Cache Ein Trace Cache ist ein spezieller Befehlscache, der "Traces" des aktuellen Programmlauf protokolliert. Dabei speichert jede Zeile einen Trace, welcher typisch mehrere taken branches enthalten kann. Befehlsfolgen, die aufgrund von taken branches (weit) auseinander liegen, werden in kontinuierlicher Folge abgespeichert. Gepaart mit multiple branch prediction können mehrere zusammenhängende Basisblöcke parallel gefetched werden. (ergibt hohe issue rate) Kapitel 5 - Risc Wie berechnet sich die Prozessorleistung? Die Prozessorleistung ist umgekehrt proportional zur Ausführungszeit eines Algorithmus und wird aus folgenden drei Parametern
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itliegenden Index. Ist eine der Tags gleich dem Index, ist dies ein Cache-Hit. Diese Technik reduziert die hohe Anfälligkeit von Direct-Mapped-Caches für Konflikte, benötigt aber mehr Chipfläche. <span>Welche Schreibstrategien für Caches gibt es? Write-Back,Write-Throug und Write-Allocate. Write-Back-Strategie? Ein zu lesendes Datum wird entweder bei einem Hit aus dem Cache gelesen oder im Falle eines Misses, aus dem Hauptspeicher geholt und parallel in den Cache eingetra
Original toplevel document
Grundprinzipien der Rechnerarchitekturaubt : ) Preemptives Multitasking ist echtes Multitasking. Ein externer Timer steuert die Umschaltung der Tasks. Die Tasks können somit keinen Einfluss auf die Betriebsmittelumschaltung nehmen. <span>Kapitel 4 - Speicherhierarchie und Caches Was bedeutet die Eigenschaft Lokalität? Aus programmtechnischer Sicht wiederholen sich oft Befehle und ganze Programmteile. Somit werden Daten oft wiederholt angefordert. Es gibt nun zwei Arten von Lokalität: Was ist Zeitliche Lokalität? Auf ein gerade zugegriffenes Datum wird sicher bald wieder zugegriffen. Was ist Räumliche Lokalität? Auf Daten, deren Adressen benachbart sind, wird mit hoher Wahrscheinlichkeit auch zugegriffen. Anzumerken ist, daß Datenzugriffe eine geringere Lokalität zeigen als Befehlszugriffe. Nach welchen Merkmalen lassen sich Caches klassifizieren? Cache-Größe (damit verbundener Hardware-Aufwand) Größe einer Cachezeile (Verschmutzungseffekt) Cache-Organisation (Vollassoziativ/Direct Mapped/Satz-Assoziativ) Schreibstrategie (Write-Through /-Allocate oder -Back) Split-Cache-Design (Transfer-Bandbreiten) Multi-level Cache-Hierarchien (Workingssetgrößen) Effective Working Set (Overflow-, Victim-, Trace Cache) Innere Cache-Parallelität (Streaming) Kohärenz-Verfahren (Snooping, MESI) Wie ist ein Cache aufgebaut? Zeile 1 Adress-Tag Datenblock Control(Bits) Zeile 2 Adress-Tag Datenblock Control(Bits) Zeile 3 Adress-Tag Datenblock Control(Bits) ... Adress-Tag Datenblock Control(Bits) Zeile n Adress-Tag Datenblock Control(Bits) Control-Bits sind z.B. Valid-Bits, Dirty-Bits und Prozess-ID. Das Adress-Tag ist nichts weiter als ein Teil der Adresse, welche bei einem Zugriff als Index gilt. Ein Datenblock ist in der Praxis meistens zwischen 16 und 64 KByte groß. Welche Cache-Arten kennen Sie? Ein Cache-Eintrag besteht aus einem Tag (Identifikator) und den Daten. Die Implementierung unterscheidet sich. Es gibt voll-, einfach assoziative und Satzassoziative Caches . Wie arbeitet ein vollassoziativer Cache? Das Tag Feld ist hier die assoziierende Adresse des Datums im Speicher. Die Hardware ist bei vollassoziativen Caches aufwendig, da diese bei einem Cache Zugriff alle Tags gleichzeitig mit der anliegenden Adresse vergleicht. Dies ist zwar extrem schnell, aber sehr teuer. Außerdem wird er sehr langsam wenn die Anzahl der Cachezeilen hinreichend groß wird. Da bei vollassoziativen Cachen ein Datum an jede Stelle des Caches platziert werden kann, muss eine Logik her, welche eine Entscheidung trifft. Als Plazierungsstrategie wird oft LRU verwendet. Dies ist seht aufwendig! Wie arbeitet ein Direct-Mapped-Cache (einfach assoziativer Cache)? Beim Direct-Mapped-Cache entscheidet eine Map-Funktion, welche Zeile im Cache mit der anliegenden Adresse referenziert wird (somit ist kein LRU o.ä. notwendig). Dabei wird einem Hauptspeicherblock genau ein Cache-Block zugeordnet (n:1 Beziehung). Oft wird eine Funktion wie (A mod Cachesize / Zeilengröße) zur Berechnung der Cachezeile aus der anliegenden Adresse benutzt, da bei diesem Verfahren dann nur (A / Cachesize) als Tag in jeder Cachezeile gespeichert werden muss. Vorteil dieser Variante ist die einfache, kostengünstige Integration (nur Komperator notwendig) und die hohe Geschwindigkeit. Leider neigt ein Direct-Mapped-Cache zu vielen Konflikten (ähnlich den Kollisionen bei Hash-Tables), welche zusätzliche Cache-Misses bildet, da mehrere Adressen auf die gleiche Cachezeile verweisen. Wie arbeitet ein n-Wege-Satz Cache (Satzassoziativer Cache)? Diese Variante ist nichts anderes als eine Implementation mehrerer parallel verknüpfter Direct-Mapped-Caches. Sie stellt quasi einen Kompromiss zwischen Cache-Effizienz und Aufwand dar. Die Arbeitsweise ist die gleiche, nur das die Map-Funktion nicht nur auf eine Zeile im Speicher zeigt, sondern auf n. Die Hardware des Caches vergleicht alle n Tags gleichzeitig, mit dem anliegenden Index. Ist eine der Tags gleich dem Index, ist dies ein Cache-Hit. Diese Technik reduziert die hohe Anfälligkeit von Direct-Mapped-Caches für Konflikte, benötigt aber mehr Chipfläche. Welche Schreibstrategien für Caches gibt es? Write-Back,Write-Throug und Write-Allocate. Write-Back-Strategie? Ein zu lesendes Datum wird entweder bei einem Hit aus dem Cache gelesen oder im Falle eines Misses, aus dem Hauptspeicher geholt und parallel in den Cache eingetragen. Im Falle der Aktualisierung, muss erst das Dirty-Bit der zu überschreibenden Cache-Line geprüft werden, um diese gegebenenfalls in den Hauptspeicher zurückzuschreiben. (Write-Back) Vorteil dieser Strategie ist das bei Hits kein Hauptspeicherverkehr oder Busbelastung auftritt. Alle Operationen können schnell innerhalb der Working-Sets mit Cache-Speed erfolgen. Somit arbeitet die CPU ungebremst. Problematisch wird dies, wenn mehrere Bus-Master am Bus hängen. Um Inkonsistenzen zu vermeiden sind dann spezielle Synchronisationsprotololle wie MESI notwendig. Concurrent Write-Back? Bei einfachen Write-Back-Caches muss die CPU im Falle eines Cache-Misses warten, bis die neue Cache-Line aus dem Speicher geholt wurde. Um diese Wartezeit im Mittel zu eliminieren, wird die alte Zeile zunächst in einen Writebuffer zwischengespeichert und später, parallel zu nachfolgenden Cache-Referenzen in den Hauptspeicher übernommen. (Sonderform: Buffered Line Refill) Wenn auch beim Lesen ein Line-(Read)-Buffer verwendet wird, spricht man von einem Streaming Cache. Write-Through-Strategie? Write-Through schreibt immer in den Hauptspeicher und falls sich eine Kopie auch im Cache befindet, so wird diese aktualisiert. Genau aus diesem Grund ist kein Rückschreiben eines Dirty-Datums notwendig, da es zu keinen Inkonsistenzen zwischen RAM und Cache kommen kann. Nachteil ist aber, dass nur bei Leseoperationen ein Geschwindigkeitsvorteil erzielt werden kann Buffered Write-Through Im Mittel erfolgen nach jeder Write-Operation zwei Read-Operationen. Deshalb kann ein Geschwindigkeitsgewinn erzielt werden, wenn ein schneller Zwischenbuffer (FiFo) vor dem Speicher plaziert wird, welcher einige Write-Operationen aufnehmen kann. Wird nun eine Leseoperation ausgeführt, so kann das Datum falls es noch in dem schnellen Buffer steht, direkt aus diesem gelesen werden. Write Allocate Hier wird immer in den Hauptspeicher und in den Cache geschrieben - auch wenn das Datum sich noch nicht im Cache befand. Zusammenspiel bei Cache-Misses Write-Allocate wird meistens mit Write-Back Strategie gemeinsam verwendet. Write-Allocate bedeutet dabei nichts weiter, als das der Hauptspeicher-Block in den Cache geladen wird. Beim No-write-Allocate (Write-Around) wird das Datum direkt im Hauptspeicher modifiziert, weshalb Write Around meist mit Write-Through verbunden wird. Zusammenfassung Caches Write-Back wird üblicherweise mit Write-Allocate kombiniert. Beim Write Allocate (fetch-on-write) wird ein Block gelesen und in Cache gespeichert. Beim No-write-allocate (write-around) wird der Block in der unteren Ebene der Speicherhierarchie modifiziert und nicht nicht im Cache geladen. No-write-allocate wird deshalb meist bei Write-through verwendet. Was ist der Unterschied zwischen einen logischen und einen physischen Cache? Physische Caches liegen vor der MMU und speichern somit nur physikalische Adressen. Ein logischer Cache liegt zwischen CPU und MMU und speichert logische Adressen. Vorteil von logischen Caches ist daher, dass die Adressumrechnung bei einem Hit entfällt. Ein großer Nachteil sind aber die Synonym-Probleme bei Multiprozessorsystemen. Des weiteren wird bei Taskwechsel ein Cache-Flush notwendig. Multi-Level-Caches und Split-Caches Durch Hintereinanderlegen von verschiedenen Caches kann ein gleitender Übergang zu immer größeren und langsameren Speichern erreicht werden. First Level Caches sind meist n-Wege-Satzassoziativ und folgende Direct-Mapped. Split-Caches trennen Code und Daten und sind somit viel flexibler und besser an das Zugriffsverhalten in Bezug auf Strategie oder Assoziativität zu optimieren. Dabei unterscheidet man eine Havard-Architektur von der multiplexed Havard-Architektur (von Neumann Prinzip). Die reine Harvard trennt nicht nur Cache sondern auch den Hauptspeicher in Daten und Codebereich. Bei von Neumann liegen Daten und Code zusammen im Hauptspeicher und werden nur im Cache getrennt. Durch Trennung von Code und Daten verdoppelt sich die Bandbreite, da zeitgleich zugegriffen werden kann. Was geschieht wenn kein Platz mehr im Cache vorhanden ist? Es muss eine Cache-Line ausgewählt werden, die mit den neuen benötigten Daten überschrieben werden kann. Die Auswahl erfolgt meistens mit LRU - Last Recently Used. D.h. die am längsten nicht genutzte Cache-Line fliegt raus. Was ist ein Burst-Cache? Burst Caches schreiben nicht nur eine Zeile in den Speicher zurück, sondern gleich mehrere, um die Bandbreite auszunutzen und somit Zeit zu sparen. Zusammenhänge zwischen Caches, TLB's und Page Tables Folgende vier Fragen stellen sich bei Caches, TLB's und auch bei Page Tables: Wo kann ein Block eingelagert werden? (Direct Mapped also nur an einem Ort, Set Assoziativ an mehreren Orten oder Voll Assoziativ, also überall) Wie kann ein Block gefunden werden? (indexiert, limitierte Suche, komplette Suche oder lookup table wie Page Tables) Wie wird ein Block bei einem Miss aktualisiert? (normalerweise über LRU oder random Methoden) Wie wird mit Schreiboperationen umgegangen? (Write Through oder Write Back) Ein TLB ist ein Translation Lookaside Buffer und ist ein kleiner Cache für die Page Table, um Seitenzugriffe zu beschleunigen. Was ist ein Trace-Cache Ein Trace Cache ist ein spezieller Befehlscache, der "Traces" des aktuellen Programmlauf protokolliert. Dabei speichert jede Zeile einen Trace, welcher typisch mehrere taken branches enthalten kann. Befehlsfolgen, die aufgrund von taken branches (weit) auseinander liegen, werden in kontinuierlicher Folge abgespeichert. Gepaart mit multiple branch prediction können mehrere zusammenhängende Basisblöcke parallel gefetched werden. (ergibt hohe issue rate) Kapitel 5 - Risc Wie berechnet sich die Prozessorleistung? Die Prozessorleistung ist umgekehrt proportional zur Ausführungszeit eines Algorithmus und wird aus folgenden drei Parametern
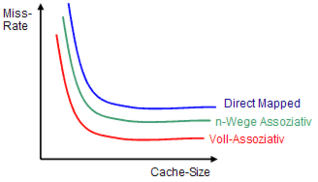
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itr neigt ein Direct-Mapped-Cache zu vielen Konflikten (ähnlich den Kollisionen bei Hash-Tables), welche zusätzliche Cache-Misses bildet, da mehrere Adressen auf die gleiche Cachezeile verweisen. <span>Wie arbeitet ein n-Wege-Satz Cache (Satzassoziativer Cache)? Diese Variante ist nichts anderes als eine Implementation mehrerer parallel verknüpfter Direct-Mapped-Caches. Sie stellt quasi einen Kompromiss zwischen Cache-Effizienz und Aufwand dar. Die Arbeitsweise ist die gleiche, nur das die Map-Funktion nicht nur auf eine Zeile im Speicher zeigt, sondern auf n. Die Hardware des Caches vergleicht alle n Tags gleichzeitig, mit dem anliegenden Index. Ist eine der Tags gleich dem Index, ist dies ein Cache-Hit. Diese Technik reduziert die hohe Anfälligkeit von Direct-Mapped-Caches für Konflikte, benötigt aber mehr Chipfläche. Welche Schreibstrategien für Caches gibt es? Write-Back,Write-Throug und Write-Allocate. Write-Back-Strategie? Ein zu lesendes Datum wird entweder bei einem Hit aus dem Cache gelesen od
Original toplevel document
Grundprinzipien der Rechnerarchitekturaubt : ) Preemptives Multitasking ist echtes Multitasking. Ein externer Timer steuert die Umschaltung der Tasks. Die Tasks können somit keinen Einfluss auf die Betriebsmittelumschaltung nehmen. <span>Kapitel 4 - Speicherhierarchie und Caches Was bedeutet die Eigenschaft Lokalität? Aus programmtechnischer Sicht wiederholen sich oft Befehle und ganze Programmteile. Somit werden Daten oft wiederholt angefordert. Es gibt nun zwei Arten von Lokalität: Was ist Zeitliche Lokalität? Auf ein gerade zugegriffenes Datum wird sicher bald wieder zugegriffen. Was ist Räumliche Lokalität? Auf Daten, deren Adressen benachbart sind, wird mit hoher Wahrscheinlichkeit auch zugegriffen. Anzumerken ist, daß Datenzugriffe eine geringere Lokalität zeigen als Befehlszugriffe. Nach welchen Merkmalen lassen sich Caches klassifizieren? Cache-Größe (damit verbundener Hardware-Aufwand) Größe einer Cachezeile (Verschmutzungseffekt) Cache-Organisation (Vollassoziativ/Direct Mapped/Satz-Assoziativ) Schreibstrategie (Write-Through /-Allocate oder -Back) Split-Cache-Design (Transfer-Bandbreiten) Multi-level Cache-Hierarchien (Workingssetgrößen) Effective Working Set (Overflow-, Victim-, Trace Cache) Innere Cache-Parallelität (Streaming) Kohärenz-Verfahren (Snooping, MESI) Wie ist ein Cache aufgebaut? Zeile 1 Adress-Tag Datenblock Control(Bits) Zeile 2 Adress-Tag Datenblock Control(Bits) Zeile 3 Adress-Tag Datenblock Control(Bits) ... Adress-Tag Datenblock Control(Bits) Zeile n Adress-Tag Datenblock Control(Bits) Control-Bits sind z.B. Valid-Bits, Dirty-Bits und Prozess-ID. Das Adress-Tag ist nichts weiter als ein Teil der Adresse, welche bei einem Zugriff als Index gilt. Ein Datenblock ist in der Praxis meistens zwischen 16 und 64 KByte groß. Welche Cache-Arten kennen Sie? Ein Cache-Eintrag besteht aus einem Tag (Identifikator) und den Daten. Die Implementierung unterscheidet sich. Es gibt voll-, einfach assoziative und Satzassoziative Caches . Wie arbeitet ein vollassoziativer Cache? Das Tag Feld ist hier die assoziierende Adresse des Datums im Speicher. Die Hardware ist bei vollassoziativen Caches aufwendig, da diese bei einem Cache Zugriff alle Tags gleichzeitig mit der anliegenden Adresse vergleicht. Dies ist zwar extrem schnell, aber sehr teuer. Außerdem wird er sehr langsam wenn die Anzahl der Cachezeilen hinreichend groß wird. Da bei vollassoziativen Cachen ein Datum an jede Stelle des Caches platziert werden kann, muss eine Logik her, welche eine Entscheidung trifft. Als Plazierungsstrategie wird oft LRU verwendet. Dies ist seht aufwendig! Wie arbeitet ein Direct-Mapped-Cache (einfach assoziativer Cache)? Beim Direct-Mapped-Cache entscheidet eine Map-Funktion, welche Zeile im Cache mit der anliegenden Adresse referenziert wird (somit ist kein LRU o.ä. notwendig). Dabei wird einem Hauptspeicherblock genau ein Cache-Block zugeordnet (n:1 Beziehung). Oft wird eine Funktion wie (A mod Cachesize / Zeilengröße) zur Berechnung der Cachezeile aus der anliegenden Adresse benutzt, da bei diesem Verfahren dann nur (A / Cachesize) als Tag in jeder Cachezeile gespeichert werden muss. Vorteil dieser Variante ist die einfache, kostengünstige Integration (nur Komperator notwendig) und die hohe Geschwindigkeit. Leider neigt ein Direct-Mapped-Cache zu vielen Konflikten (ähnlich den Kollisionen bei Hash-Tables), welche zusätzliche Cache-Misses bildet, da mehrere Adressen auf die gleiche Cachezeile verweisen. Wie arbeitet ein n-Wege-Satz Cache (Satzassoziativer Cache)? Diese Variante ist nichts anderes als eine Implementation mehrerer parallel verknüpfter Direct-Mapped-Caches. Sie stellt quasi einen Kompromiss zwischen Cache-Effizienz und Aufwand dar. Die Arbeitsweise ist die gleiche, nur das die Map-Funktion nicht nur auf eine Zeile im Speicher zeigt, sondern auf n. Die Hardware des Caches vergleicht alle n Tags gleichzeitig, mit dem anliegenden Index. Ist eine der Tags gleich dem Index, ist dies ein Cache-Hit. Diese Technik reduziert die hohe Anfälligkeit von Direct-Mapped-Caches für Konflikte, benötigt aber mehr Chipfläche. Welche Schreibstrategien für Caches gibt es? Write-Back,Write-Throug und Write-Allocate. Write-Back-Strategie? Ein zu lesendes Datum wird entweder bei einem Hit aus dem Cache gelesen oder im Falle eines Misses, aus dem Hauptspeicher geholt und parallel in den Cache eingetragen. Im Falle der Aktualisierung, muss erst das Dirty-Bit der zu überschreibenden Cache-Line geprüft werden, um diese gegebenenfalls in den Hauptspeicher zurückzuschreiben. (Write-Back) Vorteil dieser Strategie ist das bei Hits kein Hauptspeicherverkehr oder Busbelastung auftritt. Alle Operationen können schnell innerhalb der Working-Sets mit Cache-Speed erfolgen. Somit arbeitet die CPU ungebremst. Problematisch wird dies, wenn mehrere Bus-Master am Bus hängen. Um Inkonsistenzen zu vermeiden sind dann spezielle Synchronisationsprotololle wie MESI notwendig. Concurrent Write-Back? Bei einfachen Write-Back-Caches muss die CPU im Falle eines Cache-Misses warten, bis die neue Cache-Line aus dem Speicher geholt wurde. Um diese Wartezeit im Mittel zu eliminieren, wird die alte Zeile zunächst in einen Writebuffer zwischengespeichert und später, parallel zu nachfolgenden Cache-Referenzen in den Hauptspeicher übernommen. (Sonderform: Buffered Line Refill) Wenn auch beim Lesen ein Line-(Read)-Buffer verwendet wird, spricht man von einem Streaming Cache. Write-Through-Strategie? Write-Through schreibt immer in den Hauptspeicher und falls sich eine Kopie auch im Cache befindet, so wird diese aktualisiert. Genau aus diesem Grund ist kein Rückschreiben eines Dirty-Datums notwendig, da es zu keinen Inkonsistenzen zwischen RAM und Cache kommen kann. Nachteil ist aber, dass nur bei Leseoperationen ein Geschwindigkeitsvorteil erzielt werden kann Buffered Write-Through Im Mittel erfolgen nach jeder Write-Operation zwei Read-Operationen. Deshalb kann ein Geschwindigkeitsgewinn erzielt werden, wenn ein schneller Zwischenbuffer (FiFo) vor dem Speicher plaziert wird, welcher einige Write-Operationen aufnehmen kann. Wird nun eine Leseoperation ausgeführt, so kann das Datum falls es noch in dem schnellen Buffer steht, direkt aus diesem gelesen werden. Write Allocate Hier wird immer in den Hauptspeicher und in den Cache geschrieben - auch wenn das Datum sich noch nicht im Cache befand. Zusammenspiel bei Cache-Misses Write-Allocate wird meistens mit Write-Back Strategie gemeinsam verwendet. Write-Allocate bedeutet dabei nichts weiter, als das der Hauptspeicher-Block in den Cache geladen wird. Beim No-write-Allocate (Write-Around) wird das Datum direkt im Hauptspeicher modifiziert, weshalb Write Around meist mit Write-Through verbunden wird. Zusammenfassung Caches Write-Back wird üblicherweise mit Write-Allocate kombiniert. Beim Write Allocate (fetch-on-write) wird ein Block gelesen und in Cache gespeichert. Beim No-write-allocate (write-around) wird der Block in der unteren Ebene der Speicherhierarchie modifiziert und nicht nicht im Cache geladen. No-write-allocate wird deshalb meist bei Write-through verwendet. Was ist der Unterschied zwischen einen logischen und einen physischen Cache? Physische Caches liegen vor der MMU und speichern somit nur physikalische Adressen. Ein logischer Cache liegt zwischen CPU und MMU und speichert logische Adressen. Vorteil von logischen Caches ist daher, dass die Adressumrechnung bei einem Hit entfällt. Ein großer Nachteil sind aber die Synonym-Probleme bei Multiprozessorsystemen. Des weiteren wird bei Taskwechsel ein Cache-Flush notwendig. Multi-Level-Caches und Split-Caches Durch Hintereinanderlegen von verschiedenen Caches kann ein gleitender Übergang zu immer größeren und langsameren Speichern erreicht werden. First Level Caches sind meist n-Wege-Satzassoziativ und folgende Direct-Mapped. Split-Caches trennen Code und Daten und sind somit viel flexibler und besser an das Zugriffsverhalten in Bezug auf Strategie oder Assoziativität zu optimieren. Dabei unterscheidet man eine Havard-Architektur von der multiplexed Havard-Architektur (von Neumann Prinzip). Die reine Harvard trennt nicht nur Cache sondern auch den Hauptspeicher in Daten und Codebereich. Bei von Neumann liegen Daten und Code zusammen im Hauptspeicher und werden nur im Cache getrennt. Durch Trennung von Code und Daten verdoppelt sich die Bandbreite, da zeitgleich zugegriffen werden kann. Was geschieht wenn kein Platz mehr im Cache vorhanden ist? Es muss eine Cache-Line ausgewählt werden, die mit den neuen benötigten Daten überschrieben werden kann. Die Auswahl erfolgt meistens mit LRU - Last Recently Used. D.h. die am längsten nicht genutzte Cache-Line fliegt raus. Was ist ein Burst-Cache? Burst Caches schreiben nicht nur eine Zeile in den Speicher zurück, sondern gleich mehrere, um die Bandbreite auszunutzen und somit Zeit zu sparen. Zusammenhänge zwischen Caches, TLB's und Page Tables Folgende vier Fragen stellen sich bei Caches, TLB's und auch bei Page Tables: Wo kann ein Block eingelagert werden? (Direct Mapped also nur an einem Ort, Set Assoziativ an mehreren Orten oder Voll Assoziativ, also überall) Wie kann ein Block gefunden werden? (indexiert, limitierte Suche, komplette Suche oder lookup table wie Page Tables) Wie wird ein Block bei einem Miss aktualisiert? (normalerweise über LRU oder random Methoden) Wie wird mit Schreiboperationen umgegangen? (Write Through oder Write Back) Ein TLB ist ein Translation Lookaside Buffer und ist ein kleiner Cache für die Page Table, um Seitenzugriffe zu beschleunigen. Was ist ein Trace-Cache Ein Trace Cache ist ein spezieller Befehlscache, der "Traces" des aktuellen Programmlauf protokolliert. Dabei speichert jede Zeile einen Trace, welcher typisch mehrere taken branches enthalten kann. Befehlsfolgen, die aufgrund von taken branches (weit) auseinander liegen, werden in kontinuierlicher Folge abgespeichert. Gepaart mit multiple branch prediction können mehrere zusammenhängende Basisblöcke parallel gefetched werden. (ergibt hohe issue rate) Kapitel 5 - Risc Wie berechnet sich die Prozessorleistung? Die Prozessorleistung ist umgekehrt proportional zur Ausführungszeit eines Algorithmus und wird aus folgenden drei Parametern
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itSprungverlusten? Predict Not Taken / Predict-Taken (fixed prediction) Objektcode basiert (statisch) dynamisch Brach-Prediction mit History Buffern (correlating / non-correlating) Delayed-Branch <span>Wie funktioniert die Predict-Not-Taken bzw. Predict-Taken Methodik? Hier wird nichts weiter gemacht als entweder alle Sprünge voreingestellt abzulehnen oder alle Sprünge ersteinmal ohne Gewähr duchzuführen. Allgemeine Programmstatistiken sagen aus, dass mehr bedingte Sprünge ausgeführt als abgewiesen werden. Wie funktioniert die Delayed-Branch Methode? Hier wird ein sprungunabhängiger Befehl in den Delay Slot eingeschleust. Dies muss somit schon von den Compilerbauern berücksichtigt werden.
Original toplevel document
Grundprinzipien der Rechnerarchitekturund das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! <span>Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. Da das Ziel eines Sprungbefehles oft erst festgestellt werden muss, liegt diese Adresse erst ab der MEM ACCESS Phase bereit. Somit kann das erneute Laden des Programmcounters auch erst in dieser Phase geschehen. So verzögert sich das Holen des nächsten Befehles um einige Takte. Durch eine Optimierung der Pipeline kann zwar die stall-Phase verkleinert, aber nicht ausgeschlossen werden. (durch Verlegung des Sprungbedingungstests in die Decode-Phase) Welche Methoden gibt es zur Reduzierung von Sprungverlusten? Predict Not Taken / Predict-Taken (fixed prediction) Objektcode basiert (statisch) dynamisch Brach-Prediction mit History Buffern (correlating / non-correlating) Delayed-Branch Wie funktioniert die Predict-Not-Taken bzw. Predict-Taken Methodik? Hier wird nichts weiter gemacht als entweder alle Sprünge voreingestellt abzulehnen oder alle Sprünge ersteinmal ohne Gewähr duchzuführen. Allgemeine Programmstatistiken sagen aus, dass mehr bedingte Sprünge ausgeführt als abgewiesen werden. Wie funktioniert die Delayed-Branch Methode? Hier wird ein sprungunabhängiger Befehl in den Delay Slot eingeschleust. Dies muss somit schon von den Compilerbauern berücksichtigt werden. Um diese Bedingung zu Umgehen wird die "Cancelling Branches"-Technik eingesetzt. Im Mittel werden dann trotzdem die Branch-Verluste verringert. Durch ein zusätzliches Bit im Befehlscode gibt der Compiler die wahrscheinlichste Sprungrichtung an. Nun kann entsprechend dieser Annahme ein Befehl in den Delay Slot eingefügt werden, der nur gültig ist, wenn der Sprung richtig vorhergesagt war. Falls nicht wird der Delay-Slot-Befehl abgebrochen (gecancelt). Dynamische Branch-Prediction Um Wartezeiten durch bedingte Sprünge zu vermeiden, sollte das Sprungziel schon mit dem Ende der Fetch-Phase zur Verfügung stehen. Es gibt zwei Ansätze Sprungzielspeicher (branch-target-buffer = BTB) Sprungvorhersage-Puffer (Branch History Table = BHT) Wie arbeitet eine Branch History Table? In dieser Tabelle wird im Grunde nur durch ein Bit (oder mehr) vermerkt, ob ein Sprung durchgeführt wurde oder nicht. Als Index der Tabelle dient der niederwertige Teil der Adresse des dazugehörigen Sprungbefehls. Nun kann die Pipeline in der Fetchphase nach einem eventuell vorhandenen Eintrag schauen und diesen als Entscheidungsgrundlage nehmen. Welchen Nachteil hat die 1-Bit Sprungvorhersage? Es wird nicht nur bei einem Schleifenaustritt der Sprung falsch vorhergesagt, sondern auch die erste Vorhersage bei erneuter Verwendung der Schleife. Wie arbeitet die 2-Bit-Sprungvorhersage mit BHT? Durch einen einfachen Zähler kann man den Nachteil der 1-Bit-Vorhersage minimieren. Hier wird die Vorhersage erst geändert, wenn sie zweimal falsch war. Es hat sich gezeigt, daß durch Zähler mit mehr als 2 Bit sich die Performance nicht weiter signifikant erhöhen läßt. Abb.: 2-Bit-Sprungvorhersagenautomat Wie arbeitet der Branch-Target-Buffer? Hier wird die Zieladresse eines gemachten Sprungs direkt gespeichert, um diese gegebenfalls ohne Verzögerung wiederzuverwenden. So kann bei einem Hit (Index stimmt mit Befehlsadresse überein) sofort der Instruction Counter mit der dazugehörigen Sprungadresse geladen werden). Exeptions Exeptions unterbrechen den Programmablauf Aufgrund verschiedenster Fehler oder Anforderungen, wie Softwareinterrupts, Page Faults oder anderen Verletzungen. Bei synchronen Exeptions treten die Fehler stehts an der gleichen Programmstelle auf. Asynchrone werden durch externe Geräte ausgelöst und können nach dem laufenden Befehl ausgeführt werden. Was sind Precice Exeptions? Sind Exeptions, welche garantieren, dass die Exeptions direkt nach oder während des Befehles ausgeführt werden und kein Folgebefehl vorher abgearbeitet wird. Zusammenfassung der Sprungvorhersage Sprungvorhersage ist extrem wichtig für Pipelining und Superskalarität, um stalls und Verzögerungen zu minimieren. Bei statischer Vorhersage werden Rückwärtssprünge meist erst durchgeführt und Vorwärtssprünge nicht. Wurde ein Sprung falsch vorhergesagt, muss die angefangene Instruktion rückgängig gemacht werden, was aufwendig ist. Deshalb gibt es ausgeklügelte Verfahren für die Branch Prediction. Statische Sprungvorhersage Es werden Compiler benutzt, die spezielle Sprungbefehle mitführen, welche ein Bit für die Sprungvorhersage enthalten. Da der Compiler ja weiß, wie oft eine Schleife durchlaufen wird, ist das sehr effizient. Dies muss aber architektonisch von der Hardware unterstützt werden. Des Weiteren ist kein Speicher für die History Table notwendig, was es kostengünstiger macht. Statische Verfahren erreichen eine Trefferrate von 65 bis 85%, was für moderne CPU's mit Superpipelines zu wenig ist. Dynamische Verfahren erreichen Trefferraten bei der Vorhersage von 98% und mehr! Dynamische Sprungvorhersage Es gibt zwei grundlegende Methoden. BHT und BTB. Die Branch History Table (Branch Predicion Buffer) ist ein Cache, in der alle bedingten Sprünge protokolliert werden. ( bis zu mehereren Tausend) Einfachste Version enthält ein Valid-Bit (Branch taken oder nicht), welches durch den niederwertigen Teil der Sprungadresse adressiert wird. Kompliziere Implementationen arbeiten nach dem n-Wege Prinzip. Durch Second Chance kann dieses Verfahren noch verbessert werden. Der Branch Target Buffer speichert nicht nur die taken-Bits, sondern auch die Sprungzieladresse, um null Verluste bei wiederholtem Aufruf zu haben. Das setzt voraus, dass nur taken branches aufgenommen werden. Bei einem Hit in der BTB kann somit während der Fetch Phase der Program Counter überschrieben werden. Werden keine History Bits mitgeführt spricht man vom BTAB. Wie arbeitet Second Chance? Nach Beenden einer Schleife wird ein Sprung logischerweise falsch vorhergesagt. Um zu vermeiden, dass nun fälschlicherweise das Sprungbit falsch gesetzt wird (da ja die gleiche Schleife noch mal durchlaufen werden kann), ändert man dieses erst nach der zweiten falschen Vorhersage. Leicht zu implementieren als Finite State Machine mit vier Zuständen. Nachteil der dynamischen Vorhersage ist die notwendige teuere und komplexere Hardware. Was ist der Vorteil von BHT gegenüber BTB? Branch Target Buffer loggen nur, ob ein Sprung genommen wurde oder nicht. Daher gibt es bei MIPS-Architekturen die BTB verwenden immernoch die sogenannten Branch Delay Slots, da die Sprungadresse trotzdem neu ermittelt werden muss. BHT beseitigen diesen Nachteil, da sie die Sprungadresse mit abspeichern und diese dann sofort in den IP geladen werden kann. Was sind Correlating Predictors? Betrachten wir folgendes Codefragment, fällt uns auf, daß ein Branch Predictor, der nur einen Sprung als Entscheidungsgrundlage einbezieht, den Zusammenhang der drei Sprünge nicht erkennen kann. if (a==10) //1. Sprung a=0; if (b=0) //2. Sprung b=0; if (a!=b){ //3. Sprung ... //abhängig von 1. und 2. Sprung } Um diese Abhängigkeiten in eine Sprungvorhersage einbeziehen zu können, sind Correlating Predictors notwendig. Solche Einheiten werden oft als (m,n)-Predictors bezeichnet. protokolliert wird das Verhalten der letzten m Sprünge je mit einem n-Bit Predictor (z.B. 2-Bit Second Chance) somit wird aus 2^m*n-Bit Preticors ausgewählt, um Vorhersage für den jeweiligen Sprung zu treffen Wie werden Correlating Predictors hardwaremäßig implementiert? Das Implementieren dieser Predictors ist weitaus einfacher, als man es annehmen würde. Es wird einfach für die History-Bits ein m-Bit-Shift Register verwendet, um die letzten m Sprünge zu speichern. Welche Performancesteigerung ist durch Correlating Predictors erreichbar? Eqntott ist ein Benchmark, welches speziell mehrere voneinander abhängige Sprünge simuliert. Hier sinkt die Fehlvorhersage von 20% auf unter 8%! Beim GCC-Compiler sind dagegen keine Unterschiede zwischen Correlating Predictors und normaler 2-Bit Sprungvorhersage erkennbar. Kapitel 8 - Superskalarität Was bedeutet superskalar? Mit normalen Pipelines (Überlappen von Instruktionen) ist nur eine maximale Performance von einem Befehl / Takt technisch und theor
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open ite Sprünge voreingestellt abzulehnen oder alle Sprünge ersteinmal ohne Gewähr duchzuführen. Allgemeine Programmstatistiken sagen aus, dass mehr bedingte Sprünge ausgeführt als abgewiesen werden. <span>Wie funktioniert die Delayed-Branch Methode? Hier wird ein sprungunabhängiger Befehl in den Delay Slot eingeschleust. Dies muss somit schon von den Compilerbauern berücksichtigt werden. Um diese Bedingung zu Umgehen wird die "Cancelling Branches"-Technik eingesetzt. Im Mittel werden dann trotzdem die Branch-Verluste verringert. Durch ein zusätzliches Bit im Befehlscode gibt der Compiler die wahrscheinlichste Sprungrichtung an. Nun kann entsprechend dieser Annahme ein Befehl in den Delay Slot eingefügt werden, der nur gültig ist, wenn der Sprung richtig vorhergesagt war. Falls nicht wird der Delay-Slot-Befehl abgebrochen (gecancelt). Dynamische Branch-Prediction Um Wartezeiten durch bedingte Sprünge zu vermeiden, sollte das Sprungziel schon mit dem Ende der Fetch-Phase zur Verfügung stehen. Es gibt zwei Ansätze Spru
Original toplevel document
Grundprinzipien der Rechnerarchitekturund das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! <span>Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. Da das Ziel eines Sprungbefehles oft erst festgestellt werden muss, liegt diese Adresse erst ab der MEM ACCESS Phase bereit. Somit kann das erneute Laden des Programmcounters auch erst in dieser Phase geschehen. So verzögert sich das Holen des nächsten Befehles um einige Takte. Durch eine Optimierung der Pipeline kann zwar die stall-Phase verkleinert, aber nicht ausgeschlossen werden. (durch Verlegung des Sprungbedingungstests in die Decode-Phase) Welche Methoden gibt es zur Reduzierung von Sprungverlusten? Predict Not Taken / Predict-Taken (fixed prediction) Objektcode basiert (statisch) dynamisch Brach-Prediction mit History Buffern (correlating / non-correlating) Delayed-Branch Wie funktioniert die Predict-Not-Taken bzw. Predict-Taken Methodik? Hier wird nichts weiter gemacht als entweder alle Sprünge voreingestellt abzulehnen oder alle Sprünge ersteinmal ohne Gewähr duchzuführen. Allgemeine Programmstatistiken sagen aus, dass mehr bedingte Sprünge ausgeführt als abgewiesen werden. Wie funktioniert die Delayed-Branch Methode? Hier wird ein sprungunabhängiger Befehl in den Delay Slot eingeschleust. Dies muss somit schon von den Compilerbauern berücksichtigt werden. Um diese Bedingung zu Umgehen wird die "Cancelling Branches"-Technik eingesetzt. Im Mittel werden dann trotzdem die Branch-Verluste verringert. Durch ein zusätzliches Bit im Befehlscode gibt der Compiler die wahrscheinlichste Sprungrichtung an. Nun kann entsprechend dieser Annahme ein Befehl in den Delay Slot eingefügt werden, der nur gültig ist, wenn der Sprung richtig vorhergesagt war. Falls nicht wird der Delay-Slot-Befehl abgebrochen (gecancelt). Dynamische Branch-Prediction Um Wartezeiten durch bedingte Sprünge zu vermeiden, sollte das Sprungziel schon mit dem Ende der Fetch-Phase zur Verfügung stehen. Es gibt zwei Ansätze Sprungzielspeicher (branch-target-buffer = BTB) Sprungvorhersage-Puffer (Branch History Table = BHT) Wie arbeitet eine Branch History Table? In dieser Tabelle wird im Grunde nur durch ein Bit (oder mehr) vermerkt, ob ein Sprung durchgeführt wurde oder nicht. Als Index der Tabelle dient der niederwertige Teil der Adresse des dazugehörigen Sprungbefehls. Nun kann die Pipeline in der Fetchphase nach einem eventuell vorhandenen Eintrag schauen und diesen als Entscheidungsgrundlage nehmen. Welchen Nachteil hat die 1-Bit Sprungvorhersage? Es wird nicht nur bei einem Schleifenaustritt der Sprung falsch vorhergesagt, sondern auch die erste Vorhersage bei erneuter Verwendung der Schleife. Wie arbeitet die 2-Bit-Sprungvorhersage mit BHT? Durch einen einfachen Zähler kann man den Nachteil der 1-Bit-Vorhersage minimieren. Hier wird die Vorhersage erst geändert, wenn sie zweimal falsch war. Es hat sich gezeigt, daß durch Zähler mit mehr als 2 Bit sich die Performance nicht weiter signifikant erhöhen läßt. Abb.: 2-Bit-Sprungvorhersagenautomat Wie arbeitet der Branch-Target-Buffer? Hier wird die Zieladresse eines gemachten Sprungs direkt gespeichert, um diese gegebenfalls ohne Verzögerung wiederzuverwenden. So kann bei einem Hit (Index stimmt mit Befehlsadresse überein) sofort der Instruction Counter mit der dazugehörigen Sprungadresse geladen werden). Exeptions Exeptions unterbrechen den Programmablauf Aufgrund verschiedenster Fehler oder Anforderungen, wie Softwareinterrupts, Page Faults oder anderen Verletzungen. Bei synchronen Exeptions treten die Fehler stehts an der gleichen Programmstelle auf. Asynchrone werden durch externe Geräte ausgelöst und können nach dem laufenden Befehl ausgeführt werden. Was sind Precice Exeptions? Sind Exeptions, welche garantieren, dass die Exeptions direkt nach oder während des Befehles ausgeführt werden und kein Folgebefehl vorher abgearbeitet wird. Zusammenfassung der Sprungvorhersage Sprungvorhersage ist extrem wichtig für Pipelining und Superskalarität, um stalls und Verzögerungen zu minimieren. Bei statischer Vorhersage werden Rückwärtssprünge meist erst durchgeführt und Vorwärtssprünge nicht. Wurde ein Sprung falsch vorhergesagt, muss die angefangene Instruktion rückgängig gemacht werden, was aufwendig ist. Deshalb gibt es ausgeklügelte Verfahren für die Branch Prediction. Statische Sprungvorhersage Es werden Compiler benutzt, die spezielle Sprungbefehle mitführen, welche ein Bit für die Sprungvorhersage enthalten. Da der Compiler ja weiß, wie oft eine Schleife durchlaufen wird, ist das sehr effizient. Dies muss aber architektonisch von der Hardware unterstützt werden. Des Weiteren ist kein Speicher für die History Table notwendig, was es kostengünstiger macht. Statische Verfahren erreichen eine Trefferrate von 65 bis 85%, was für moderne CPU's mit Superpipelines zu wenig ist. Dynamische Verfahren erreichen Trefferraten bei der Vorhersage von 98% und mehr! Dynamische Sprungvorhersage Es gibt zwei grundlegende Methoden. BHT und BTB. Die Branch History Table (Branch Predicion Buffer) ist ein Cache, in der alle bedingten Sprünge protokolliert werden. ( bis zu mehereren Tausend) Einfachste Version enthält ein Valid-Bit (Branch taken oder nicht), welches durch den niederwertigen Teil der Sprungadresse adressiert wird. Kompliziere Implementationen arbeiten nach dem n-Wege Prinzip. Durch Second Chance kann dieses Verfahren noch verbessert werden. Der Branch Target Buffer speichert nicht nur die taken-Bits, sondern auch die Sprungzieladresse, um null Verluste bei wiederholtem Aufruf zu haben. Das setzt voraus, dass nur taken branches aufgenommen werden. Bei einem Hit in der BTB kann somit während der Fetch Phase der Program Counter überschrieben werden. Werden keine History Bits mitgeführt spricht man vom BTAB. Wie arbeitet Second Chance? Nach Beenden einer Schleife wird ein Sprung logischerweise falsch vorhergesagt. Um zu vermeiden, dass nun fälschlicherweise das Sprungbit falsch gesetzt wird (da ja die gleiche Schleife noch mal durchlaufen werden kann), ändert man dieses erst nach der zweiten falschen Vorhersage. Leicht zu implementieren als Finite State Machine mit vier Zuständen. Nachteil der dynamischen Vorhersage ist die notwendige teuere und komplexere Hardware. Was ist der Vorteil von BHT gegenüber BTB? Branch Target Buffer loggen nur, ob ein Sprung genommen wurde oder nicht. Daher gibt es bei MIPS-Architekturen die BTB verwenden immernoch die sogenannten Branch Delay Slots, da die Sprungadresse trotzdem neu ermittelt werden muss. BHT beseitigen diesen Nachteil, da sie die Sprungadresse mit abspeichern und diese dann sofort in den IP geladen werden kann. Was sind Correlating Predictors? Betrachten wir folgendes Codefragment, fällt uns auf, daß ein Branch Predictor, der nur einen Sprung als Entscheidungsgrundlage einbezieht, den Zusammenhang der drei Sprünge nicht erkennen kann. if (a==10) //1. Sprung a=0; if (b=0) //2. Sprung b=0; if (a!=b){ //3. Sprung ... //abhängig von 1. und 2. Sprung } Um diese Abhängigkeiten in eine Sprungvorhersage einbeziehen zu können, sind Correlating Predictors notwendig. Solche Einheiten werden oft als (m,n)-Predictors bezeichnet. protokolliert wird das Verhalten der letzten m Sprünge je mit einem n-Bit Predictor (z.B. 2-Bit Second Chance) somit wird aus 2^m*n-Bit Preticors ausgewählt, um Vorhersage für den jeweiligen Sprung zu treffen Wie werden Correlating Predictors hardwaremäßig implementiert? Das Implementieren dieser Predictors ist weitaus einfacher, als man es annehmen würde. Es wird einfach für die History-Bits ein m-Bit-Shift Register verwendet, um die letzten m Sprünge zu speichern. Welche Performancesteigerung ist durch Correlating Predictors erreichbar? Eqntott ist ein Benchmark, welches speziell mehrere voneinander abhängige Sprünge simuliert. Hier sinkt die Fehlvorhersage von 20% auf unter 8%! Beim GCC-Compiler sind dagegen keine Unterschiede zwischen Correlating Predictors und normaler 2-Bit Sprungvorhersage erkennbar. Kapitel 8 - Superskalarität Was bedeutet superskalar? Mit normalen Pipelines (Überlappen von Instruktionen) ist nur eine maximale Performance von einem Befehl / Takt technisch und theor
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itrwertige Teil der Adresse des dazugehörigen Sprungbefehls. Nun kann die Pipeline in der Fetchphase nach einem eventuell vorhandenen Eintrag schauen und diesen als Entscheidungsgrundlage nehmen. <span>Welchen Nachteil hat die 1-Bit Sprungvorhersage? Es wird nicht nur bei einem Schleifenaustritt der Sprung falsch vorhergesagt, sondern auch die erste Vorhersage bei erneuter Verwendung der Schleife. Wie arbeitet die 2-Bit-Sprungvorhersage mit BHT? Durch einen einfachen Zähler kann man den Nachteil der 1-Bit-Vorhersage minimieren. Hier wird die Vorhersage erst geändert, wenn sie zweimal falsch war. Es hat sich gezeigt, daß durch Zähler mit mehr als 2 Bit sich die Performance nicht weiter signifikant erhöhen läßt. Abb.: 2-Bit-Sprungvorhersagenautomat Wie arbeitet der Branch-Target-Buffer? Hier wird die Zieladresse eines gemachten Sprungs direkt gespeichert, um diese gegebenfalls ohne Verzögerung wiederzuverwenden. So kann bei einem
Original toplevel document
Grundprinzipien der Rechnerarchitekturund das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! <span>Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. Da das Ziel eines Sprungbefehles oft erst festgestellt werden muss, liegt diese Adresse erst ab der MEM ACCESS Phase bereit. Somit kann das erneute Laden des Programmcounters auch erst in dieser Phase geschehen. So verzögert sich das Holen des nächsten Befehles um einige Takte. Durch eine Optimierung der Pipeline kann zwar die stall-Phase verkleinert, aber nicht ausgeschlossen werden. (durch Verlegung des Sprungbedingungstests in die Decode-Phase) Welche Methoden gibt es zur Reduzierung von Sprungverlusten? Predict Not Taken / Predict-Taken (fixed prediction) Objektcode basiert (statisch) dynamisch Brach-Prediction mit History Buffern (correlating / non-correlating) Delayed-Branch Wie funktioniert die Predict-Not-Taken bzw. Predict-Taken Methodik? Hier wird nichts weiter gemacht als entweder alle Sprünge voreingestellt abzulehnen oder alle Sprünge ersteinmal ohne Gewähr duchzuführen. Allgemeine Programmstatistiken sagen aus, dass mehr bedingte Sprünge ausgeführt als abgewiesen werden. Wie funktioniert die Delayed-Branch Methode? Hier wird ein sprungunabhängiger Befehl in den Delay Slot eingeschleust. Dies muss somit schon von den Compilerbauern berücksichtigt werden. Um diese Bedingung zu Umgehen wird die "Cancelling Branches"-Technik eingesetzt. Im Mittel werden dann trotzdem die Branch-Verluste verringert. Durch ein zusätzliches Bit im Befehlscode gibt der Compiler die wahrscheinlichste Sprungrichtung an. Nun kann entsprechend dieser Annahme ein Befehl in den Delay Slot eingefügt werden, der nur gültig ist, wenn der Sprung richtig vorhergesagt war. Falls nicht wird der Delay-Slot-Befehl abgebrochen (gecancelt). Dynamische Branch-Prediction Um Wartezeiten durch bedingte Sprünge zu vermeiden, sollte das Sprungziel schon mit dem Ende der Fetch-Phase zur Verfügung stehen. Es gibt zwei Ansätze Sprungzielspeicher (branch-target-buffer = BTB) Sprungvorhersage-Puffer (Branch History Table = BHT) Wie arbeitet eine Branch History Table? In dieser Tabelle wird im Grunde nur durch ein Bit (oder mehr) vermerkt, ob ein Sprung durchgeführt wurde oder nicht. Als Index der Tabelle dient der niederwertige Teil der Adresse des dazugehörigen Sprungbefehls. Nun kann die Pipeline in der Fetchphase nach einem eventuell vorhandenen Eintrag schauen und diesen als Entscheidungsgrundlage nehmen. Welchen Nachteil hat die 1-Bit Sprungvorhersage? Es wird nicht nur bei einem Schleifenaustritt der Sprung falsch vorhergesagt, sondern auch die erste Vorhersage bei erneuter Verwendung der Schleife. Wie arbeitet die 2-Bit-Sprungvorhersage mit BHT? Durch einen einfachen Zähler kann man den Nachteil der 1-Bit-Vorhersage minimieren. Hier wird die Vorhersage erst geändert, wenn sie zweimal falsch war. Es hat sich gezeigt, daß durch Zähler mit mehr als 2 Bit sich die Performance nicht weiter signifikant erhöhen läßt. Abb.: 2-Bit-Sprungvorhersagenautomat Wie arbeitet der Branch-Target-Buffer? Hier wird die Zieladresse eines gemachten Sprungs direkt gespeichert, um diese gegebenfalls ohne Verzögerung wiederzuverwenden. So kann bei einem Hit (Index stimmt mit Befehlsadresse überein) sofort der Instruction Counter mit der dazugehörigen Sprungadresse geladen werden). Exeptions Exeptions unterbrechen den Programmablauf Aufgrund verschiedenster Fehler oder Anforderungen, wie Softwareinterrupts, Page Faults oder anderen Verletzungen. Bei synchronen Exeptions treten die Fehler stehts an der gleichen Programmstelle auf. Asynchrone werden durch externe Geräte ausgelöst und können nach dem laufenden Befehl ausgeführt werden. Was sind Precice Exeptions? Sind Exeptions, welche garantieren, dass die Exeptions direkt nach oder während des Befehles ausgeführt werden und kein Folgebefehl vorher abgearbeitet wird. Zusammenfassung der Sprungvorhersage Sprungvorhersage ist extrem wichtig für Pipelining und Superskalarität, um stalls und Verzögerungen zu minimieren. Bei statischer Vorhersage werden Rückwärtssprünge meist erst durchgeführt und Vorwärtssprünge nicht. Wurde ein Sprung falsch vorhergesagt, muss die angefangene Instruktion rückgängig gemacht werden, was aufwendig ist. Deshalb gibt es ausgeklügelte Verfahren für die Branch Prediction. Statische Sprungvorhersage Es werden Compiler benutzt, die spezielle Sprungbefehle mitführen, welche ein Bit für die Sprungvorhersage enthalten. Da der Compiler ja weiß, wie oft eine Schleife durchlaufen wird, ist das sehr effizient. Dies muss aber architektonisch von der Hardware unterstützt werden. Des Weiteren ist kein Speicher für die History Table notwendig, was es kostengünstiger macht. Statische Verfahren erreichen eine Trefferrate von 65 bis 85%, was für moderne CPU's mit Superpipelines zu wenig ist. Dynamische Verfahren erreichen Trefferraten bei der Vorhersage von 98% und mehr! Dynamische Sprungvorhersage Es gibt zwei grundlegende Methoden. BHT und BTB. Die Branch History Table (Branch Predicion Buffer) ist ein Cache, in der alle bedingten Sprünge protokolliert werden. ( bis zu mehereren Tausend) Einfachste Version enthält ein Valid-Bit (Branch taken oder nicht), welches durch den niederwertigen Teil der Sprungadresse adressiert wird. Kompliziere Implementationen arbeiten nach dem n-Wege Prinzip. Durch Second Chance kann dieses Verfahren noch verbessert werden. Der Branch Target Buffer speichert nicht nur die taken-Bits, sondern auch die Sprungzieladresse, um null Verluste bei wiederholtem Aufruf zu haben. Das setzt voraus, dass nur taken branches aufgenommen werden. Bei einem Hit in der BTB kann somit während der Fetch Phase der Program Counter überschrieben werden. Werden keine History Bits mitgeführt spricht man vom BTAB. Wie arbeitet Second Chance? Nach Beenden einer Schleife wird ein Sprung logischerweise falsch vorhergesagt. Um zu vermeiden, dass nun fälschlicherweise das Sprungbit falsch gesetzt wird (da ja die gleiche Schleife noch mal durchlaufen werden kann), ändert man dieses erst nach der zweiten falschen Vorhersage. Leicht zu implementieren als Finite State Machine mit vier Zuständen. Nachteil der dynamischen Vorhersage ist die notwendige teuere und komplexere Hardware. Was ist der Vorteil von BHT gegenüber BTB? Branch Target Buffer loggen nur, ob ein Sprung genommen wurde oder nicht. Daher gibt es bei MIPS-Architekturen die BTB verwenden immernoch die sogenannten Branch Delay Slots, da die Sprungadresse trotzdem neu ermittelt werden muss. BHT beseitigen diesen Nachteil, da sie die Sprungadresse mit abspeichern und diese dann sofort in den IP geladen werden kann. Was sind Correlating Predictors? Betrachten wir folgendes Codefragment, fällt uns auf, daß ein Branch Predictor, der nur einen Sprung als Entscheidungsgrundlage einbezieht, den Zusammenhang der drei Sprünge nicht erkennen kann. if (a==10) //1. Sprung a=0; if (b=0) //2. Sprung b=0; if (a!=b){ //3. Sprung ... //abhängig von 1. und 2. Sprung } Um diese Abhängigkeiten in eine Sprungvorhersage einbeziehen zu können, sind Correlating Predictors notwendig. Solche Einheiten werden oft als (m,n)-Predictors bezeichnet. protokolliert wird das Verhalten der letzten m Sprünge je mit einem n-Bit Predictor (z.B. 2-Bit Second Chance) somit wird aus 2^m*n-Bit Preticors ausgewählt, um Vorhersage für den jeweiligen Sprung zu treffen Wie werden Correlating Predictors hardwaremäßig implementiert? Das Implementieren dieser Predictors ist weitaus einfacher, als man es annehmen würde. Es wird einfach für die History-Bits ein m-Bit-Shift Register verwendet, um die letzten m Sprünge zu speichern. Welche Performancesteigerung ist durch Correlating Predictors erreichbar? Eqntott ist ein Benchmark, welches speziell mehrere voneinander abhängige Sprünge simuliert. Hier sinkt die Fehlvorhersage von 20% auf unter 8%! Beim GCC-Compiler sind dagegen keine Unterschiede zwischen Correlating Predictors und normaler 2-Bit Sprungvorhersage erkennbar. Kapitel 8 - Superskalarität Was bedeutet superskalar? Mit normalen Pipelines (Überlappen von Instruktionen) ist nur eine maximale Performance von einem Befehl / Takt technisch und theor
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itgeändert, wenn sie zweimal falsch war. Es hat sich gezeigt, daß durch Zähler mit mehr als 2 Bit sich die Performance nicht weiter signifikant erhöhen läßt. Abb.: 2-Bit-Sprungvorhersagenautomat <span>Wie arbeitet der Branch-Target-Buffer? Hier wird die Zieladresse eines gemachten Sprungs direkt gespeichert, um diese gegebenfalls ohne Verzögerung wiederzuverwenden. So kann bei einem Hit (Index stimmt mit Befehlsadresse überein) sofort der Instruction Counter mit der dazugehörigen Sprungadresse geladen werden). Exeptions Exeptions unterbrechen den Programmablauf Aufgrund verschiedenster Fehler oder Anforderungen, wie Softwareinterrupts, Page Faults oder anderen Verletzungen. Bei synchronen Exe
Original toplevel document
Grundprinzipien der Rechnerarchitekturund das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! <span>Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. Da das Ziel eines Sprungbefehles oft erst festgestellt werden muss, liegt diese Adresse erst ab der MEM ACCESS Phase bereit. Somit kann das erneute Laden des Programmcounters auch erst in dieser Phase geschehen. So verzögert sich das Holen des nächsten Befehles um einige Takte. Durch eine Optimierung der Pipeline kann zwar die stall-Phase verkleinert, aber nicht ausgeschlossen werden. (durch Verlegung des Sprungbedingungstests in die Decode-Phase) Welche Methoden gibt es zur Reduzierung von Sprungverlusten? Predict Not Taken / Predict-Taken (fixed prediction) Objektcode basiert (statisch) dynamisch Brach-Prediction mit History Buffern (correlating / non-correlating) Delayed-Branch Wie funktioniert die Predict-Not-Taken bzw. Predict-Taken Methodik? Hier wird nichts weiter gemacht als entweder alle Sprünge voreingestellt abzulehnen oder alle Sprünge ersteinmal ohne Gewähr duchzuführen. Allgemeine Programmstatistiken sagen aus, dass mehr bedingte Sprünge ausgeführt als abgewiesen werden. Wie funktioniert die Delayed-Branch Methode? Hier wird ein sprungunabhängiger Befehl in den Delay Slot eingeschleust. Dies muss somit schon von den Compilerbauern berücksichtigt werden. Um diese Bedingung zu Umgehen wird die "Cancelling Branches"-Technik eingesetzt. Im Mittel werden dann trotzdem die Branch-Verluste verringert. Durch ein zusätzliches Bit im Befehlscode gibt der Compiler die wahrscheinlichste Sprungrichtung an. Nun kann entsprechend dieser Annahme ein Befehl in den Delay Slot eingefügt werden, der nur gültig ist, wenn der Sprung richtig vorhergesagt war. Falls nicht wird der Delay-Slot-Befehl abgebrochen (gecancelt). Dynamische Branch-Prediction Um Wartezeiten durch bedingte Sprünge zu vermeiden, sollte das Sprungziel schon mit dem Ende der Fetch-Phase zur Verfügung stehen. Es gibt zwei Ansätze Sprungzielspeicher (branch-target-buffer = BTB) Sprungvorhersage-Puffer (Branch History Table = BHT) Wie arbeitet eine Branch History Table? In dieser Tabelle wird im Grunde nur durch ein Bit (oder mehr) vermerkt, ob ein Sprung durchgeführt wurde oder nicht. Als Index der Tabelle dient der niederwertige Teil der Adresse des dazugehörigen Sprungbefehls. Nun kann die Pipeline in der Fetchphase nach einem eventuell vorhandenen Eintrag schauen und diesen als Entscheidungsgrundlage nehmen. Welchen Nachteil hat die 1-Bit Sprungvorhersage? Es wird nicht nur bei einem Schleifenaustritt der Sprung falsch vorhergesagt, sondern auch die erste Vorhersage bei erneuter Verwendung der Schleife. Wie arbeitet die 2-Bit-Sprungvorhersage mit BHT? Durch einen einfachen Zähler kann man den Nachteil der 1-Bit-Vorhersage minimieren. Hier wird die Vorhersage erst geändert, wenn sie zweimal falsch war. Es hat sich gezeigt, daß durch Zähler mit mehr als 2 Bit sich die Performance nicht weiter signifikant erhöhen läßt. Abb.: 2-Bit-Sprungvorhersagenautomat Wie arbeitet der Branch-Target-Buffer? Hier wird die Zieladresse eines gemachten Sprungs direkt gespeichert, um diese gegebenfalls ohne Verzögerung wiederzuverwenden. So kann bei einem Hit (Index stimmt mit Befehlsadresse überein) sofort der Instruction Counter mit der dazugehörigen Sprungadresse geladen werden). Exeptions Exeptions unterbrechen den Programmablauf Aufgrund verschiedenster Fehler oder Anforderungen, wie Softwareinterrupts, Page Faults oder anderen Verletzungen. Bei synchronen Exeptions treten die Fehler stehts an der gleichen Programmstelle auf. Asynchrone werden durch externe Geräte ausgelöst und können nach dem laufenden Befehl ausgeführt werden. Was sind Precice Exeptions? Sind Exeptions, welche garantieren, dass die Exeptions direkt nach oder während des Befehles ausgeführt werden und kein Folgebefehl vorher abgearbeitet wird. Zusammenfassung der Sprungvorhersage Sprungvorhersage ist extrem wichtig für Pipelining und Superskalarität, um stalls und Verzögerungen zu minimieren. Bei statischer Vorhersage werden Rückwärtssprünge meist erst durchgeführt und Vorwärtssprünge nicht. Wurde ein Sprung falsch vorhergesagt, muss die angefangene Instruktion rückgängig gemacht werden, was aufwendig ist. Deshalb gibt es ausgeklügelte Verfahren für die Branch Prediction. Statische Sprungvorhersage Es werden Compiler benutzt, die spezielle Sprungbefehle mitführen, welche ein Bit für die Sprungvorhersage enthalten. Da der Compiler ja weiß, wie oft eine Schleife durchlaufen wird, ist das sehr effizient. Dies muss aber architektonisch von der Hardware unterstützt werden. Des Weiteren ist kein Speicher für die History Table notwendig, was es kostengünstiger macht. Statische Verfahren erreichen eine Trefferrate von 65 bis 85%, was für moderne CPU's mit Superpipelines zu wenig ist. Dynamische Verfahren erreichen Trefferraten bei der Vorhersage von 98% und mehr! Dynamische Sprungvorhersage Es gibt zwei grundlegende Methoden. BHT und BTB. Die Branch History Table (Branch Predicion Buffer) ist ein Cache, in der alle bedingten Sprünge protokolliert werden. ( bis zu mehereren Tausend) Einfachste Version enthält ein Valid-Bit (Branch taken oder nicht), welches durch den niederwertigen Teil der Sprungadresse adressiert wird. Kompliziere Implementationen arbeiten nach dem n-Wege Prinzip. Durch Second Chance kann dieses Verfahren noch verbessert werden. Der Branch Target Buffer speichert nicht nur die taken-Bits, sondern auch die Sprungzieladresse, um null Verluste bei wiederholtem Aufruf zu haben. Das setzt voraus, dass nur taken branches aufgenommen werden. Bei einem Hit in der BTB kann somit während der Fetch Phase der Program Counter überschrieben werden. Werden keine History Bits mitgeführt spricht man vom BTAB. Wie arbeitet Second Chance? Nach Beenden einer Schleife wird ein Sprung logischerweise falsch vorhergesagt. Um zu vermeiden, dass nun fälschlicherweise das Sprungbit falsch gesetzt wird (da ja die gleiche Schleife noch mal durchlaufen werden kann), ändert man dieses erst nach der zweiten falschen Vorhersage. Leicht zu implementieren als Finite State Machine mit vier Zuständen. Nachteil der dynamischen Vorhersage ist die notwendige teuere und komplexere Hardware. Was ist der Vorteil von BHT gegenüber BTB? Branch Target Buffer loggen nur, ob ein Sprung genommen wurde oder nicht. Daher gibt es bei MIPS-Architekturen die BTB verwenden immernoch die sogenannten Branch Delay Slots, da die Sprungadresse trotzdem neu ermittelt werden muss. BHT beseitigen diesen Nachteil, da sie die Sprungadresse mit abspeichern und diese dann sofort in den IP geladen werden kann. Was sind Correlating Predictors? Betrachten wir folgendes Codefragment, fällt uns auf, daß ein Branch Predictor, der nur einen Sprung als Entscheidungsgrundlage einbezieht, den Zusammenhang der drei Sprünge nicht erkennen kann. if (a==10) //1. Sprung a=0; if (b=0) //2. Sprung b=0; if (a!=b){ //3. Sprung ... //abhängig von 1. und 2. Sprung } Um diese Abhängigkeiten in eine Sprungvorhersage einbeziehen zu können, sind Correlating Predictors notwendig. Solche Einheiten werden oft als (m,n)-Predictors bezeichnet. protokolliert wird das Verhalten der letzten m Sprünge je mit einem n-Bit Predictor (z.B. 2-Bit Second Chance) somit wird aus 2^m*n-Bit Preticors ausgewählt, um Vorhersage für den jeweiligen Sprung zu treffen Wie werden Correlating Predictors hardwaremäßig implementiert? Das Implementieren dieser Predictors ist weitaus einfacher, als man es annehmen würde. Es wird einfach für die History-Bits ein m-Bit-Shift Register verwendet, um die letzten m Sprünge zu speichern. Welche Performancesteigerung ist durch Correlating Predictors erreichbar? Eqntott ist ein Benchmark, welches speziell mehrere voneinander abhängige Sprünge simuliert. Hier sinkt die Fehlvorhersage von 20% auf unter 8%! Beim GCC-Compiler sind dagegen keine Unterschiede zwischen Correlating Predictors und normaler 2-Bit Sprungvorhersage erkennbar. Kapitel 8 - Superskalarität Was bedeutet superskalar? Mit normalen Pipelines (Überlappen von Instruktionen) ist nur eine maximale Performance von einem Befehl / Takt technisch und theor
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itwerden. Was sind Precice Exeptions? Sind Exeptions, welche garantieren, dass die Exeptions direkt nach oder während des Befehles ausgeführt werden und kein Folgebefehl vorher abgearbeitet wird. <span>Zusammenfassung der Sprungvorhersage Sprungvorhersage ist extrem wichtig für Pipelining und Superskalarität, um stalls und Verzögerungen zu minimieren. Bei statischer Vorhersage werden Rückwärtssprünge meist erst durchgeführt und Vorwärtssprünge nicht. Wurde ein Sprung falsch vorhergesagt, muss die angefangene Instruktion rückgängig gemacht werden, was aufwendig ist. Deshalb gibt es ausgeklügelte Verfahren für die Branch Prediction. Statische Sprungvorhersage Es werden Compiler benutzt, die spezielle Sprungbefehle mitführen, welche ein Bit für die Sprungvorhersage enthalten. Da der Compiler ja weiß, wie oft eine Sc
Original toplevel document
Grundprinzipien der Rechnerarchitekturund das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! <span>Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. Da das Ziel eines Sprungbefehles oft erst festgestellt werden muss, liegt diese Adresse erst ab der MEM ACCESS Phase bereit. Somit kann das erneute Laden des Programmcounters auch erst in dieser Phase geschehen. So verzögert sich das Holen des nächsten Befehles um einige Takte. Durch eine Optimierung der Pipeline kann zwar die stall-Phase verkleinert, aber nicht ausgeschlossen werden. (durch Verlegung des Sprungbedingungstests in die Decode-Phase) Welche Methoden gibt es zur Reduzierung von Sprungverlusten? Predict Not Taken / Predict-Taken (fixed prediction) Objektcode basiert (statisch) dynamisch Brach-Prediction mit History Buffern (correlating / non-correlating) Delayed-Branch Wie funktioniert die Predict-Not-Taken bzw. Predict-Taken Methodik? Hier wird nichts weiter gemacht als entweder alle Sprünge voreingestellt abzulehnen oder alle Sprünge ersteinmal ohne Gewähr duchzuführen. Allgemeine Programmstatistiken sagen aus, dass mehr bedingte Sprünge ausgeführt als abgewiesen werden. Wie funktioniert die Delayed-Branch Methode? Hier wird ein sprungunabhängiger Befehl in den Delay Slot eingeschleust. Dies muss somit schon von den Compilerbauern berücksichtigt werden. Um diese Bedingung zu Umgehen wird die "Cancelling Branches"-Technik eingesetzt. Im Mittel werden dann trotzdem die Branch-Verluste verringert. Durch ein zusätzliches Bit im Befehlscode gibt der Compiler die wahrscheinlichste Sprungrichtung an. Nun kann entsprechend dieser Annahme ein Befehl in den Delay Slot eingefügt werden, der nur gültig ist, wenn der Sprung richtig vorhergesagt war. Falls nicht wird der Delay-Slot-Befehl abgebrochen (gecancelt). Dynamische Branch-Prediction Um Wartezeiten durch bedingte Sprünge zu vermeiden, sollte das Sprungziel schon mit dem Ende der Fetch-Phase zur Verfügung stehen. Es gibt zwei Ansätze Sprungzielspeicher (branch-target-buffer = BTB) Sprungvorhersage-Puffer (Branch History Table = BHT) Wie arbeitet eine Branch History Table? In dieser Tabelle wird im Grunde nur durch ein Bit (oder mehr) vermerkt, ob ein Sprung durchgeführt wurde oder nicht. Als Index der Tabelle dient der niederwertige Teil der Adresse des dazugehörigen Sprungbefehls. Nun kann die Pipeline in der Fetchphase nach einem eventuell vorhandenen Eintrag schauen und diesen als Entscheidungsgrundlage nehmen. Welchen Nachteil hat die 1-Bit Sprungvorhersage? Es wird nicht nur bei einem Schleifenaustritt der Sprung falsch vorhergesagt, sondern auch die erste Vorhersage bei erneuter Verwendung der Schleife. Wie arbeitet die 2-Bit-Sprungvorhersage mit BHT? Durch einen einfachen Zähler kann man den Nachteil der 1-Bit-Vorhersage minimieren. Hier wird die Vorhersage erst geändert, wenn sie zweimal falsch war. Es hat sich gezeigt, daß durch Zähler mit mehr als 2 Bit sich die Performance nicht weiter signifikant erhöhen läßt. Abb.: 2-Bit-Sprungvorhersagenautomat Wie arbeitet der Branch-Target-Buffer? Hier wird die Zieladresse eines gemachten Sprungs direkt gespeichert, um diese gegebenfalls ohne Verzögerung wiederzuverwenden. So kann bei einem Hit (Index stimmt mit Befehlsadresse überein) sofort der Instruction Counter mit der dazugehörigen Sprungadresse geladen werden). Exeptions Exeptions unterbrechen den Programmablauf Aufgrund verschiedenster Fehler oder Anforderungen, wie Softwareinterrupts, Page Faults oder anderen Verletzungen. Bei synchronen Exeptions treten die Fehler stehts an der gleichen Programmstelle auf. Asynchrone werden durch externe Geräte ausgelöst und können nach dem laufenden Befehl ausgeführt werden. Was sind Precice Exeptions? Sind Exeptions, welche garantieren, dass die Exeptions direkt nach oder während des Befehles ausgeführt werden und kein Folgebefehl vorher abgearbeitet wird. Zusammenfassung der Sprungvorhersage Sprungvorhersage ist extrem wichtig für Pipelining und Superskalarität, um stalls und Verzögerungen zu minimieren. Bei statischer Vorhersage werden Rückwärtssprünge meist erst durchgeführt und Vorwärtssprünge nicht. Wurde ein Sprung falsch vorhergesagt, muss die angefangene Instruktion rückgängig gemacht werden, was aufwendig ist. Deshalb gibt es ausgeklügelte Verfahren für die Branch Prediction. Statische Sprungvorhersage Es werden Compiler benutzt, die spezielle Sprungbefehle mitführen, welche ein Bit für die Sprungvorhersage enthalten. Da der Compiler ja weiß, wie oft eine Schleife durchlaufen wird, ist das sehr effizient. Dies muss aber architektonisch von der Hardware unterstützt werden. Des Weiteren ist kein Speicher für die History Table notwendig, was es kostengünstiger macht. Statische Verfahren erreichen eine Trefferrate von 65 bis 85%, was für moderne CPU's mit Superpipelines zu wenig ist. Dynamische Verfahren erreichen Trefferraten bei der Vorhersage von 98% und mehr! Dynamische Sprungvorhersage Es gibt zwei grundlegende Methoden. BHT und BTB. Die Branch History Table (Branch Predicion Buffer) ist ein Cache, in der alle bedingten Sprünge protokolliert werden. ( bis zu mehereren Tausend) Einfachste Version enthält ein Valid-Bit (Branch taken oder nicht), welches durch den niederwertigen Teil der Sprungadresse adressiert wird. Kompliziere Implementationen arbeiten nach dem n-Wege Prinzip. Durch Second Chance kann dieses Verfahren noch verbessert werden. Der Branch Target Buffer speichert nicht nur die taken-Bits, sondern auch die Sprungzieladresse, um null Verluste bei wiederholtem Aufruf zu haben. Das setzt voraus, dass nur taken branches aufgenommen werden. Bei einem Hit in der BTB kann somit während der Fetch Phase der Program Counter überschrieben werden. Werden keine History Bits mitgeführt spricht man vom BTAB. Wie arbeitet Second Chance? Nach Beenden einer Schleife wird ein Sprung logischerweise falsch vorhergesagt. Um zu vermeiden, dass nun fälschlicherweise das Sprungbit falsch gesetzt wird (da ja die gleiche Schleife noch mal durchlaufen werden kann), ändert man dieses erst nach der zweiten falschen Vorhersage. Leicht zu implementieren als Finite State Machine mit vier Zuständen. Nachteil der dynamischen Vorhersage ist die notwendige teuere und komplexere Hardware. Was ist der Vorteil von BHT gegenüber BTB? Branch Target Buffer loggen nur, ob ein Sprung genommen wurde oder nicht. Daher gibt es bei MIPS-Architekturen die BTB verwenden immernoch die sogenannten Branch Delay Slots, da die Sprungadresse trotzdem neu ermittelt werden muss. BHT beseitigen diesen Nachteil, da sie die Sprungadresse mit abspeichern und diese dann sofort in den IP geladen werden kann. Was sind Correlating Predictors? Betrachten wir folgendes Codefragment, fällt uns auf, daß ein Branch Predictor, der nur einen Sprung als Entscheidungsgrundlage einbezieht, den Zusammenhang der drei Sprünge nicht erkennen kann. if (a==10) //1. Sprung a=0; if (b=0) //2. Sprung b=0; if (a!=b){ //3. Sprung ... //abhängig von 1. und 2. Sprung } Um diese Abhängigkeiten in eine Sprungvorhersage einbeziehen zu können, sind Correlating Predictors notwendig. Solche Einheiten werden oft als (m,n)-Predictors bezeichnet. protokolliert wird das Verhalten der letzten m Sprünge je mit einem n-Bit Predictor (z.B. 2-Bit Second Chance) somit wird aus 2^m*n-Bit Preticors ausgewählt, um Vorhersage für den jeweiligen Sprung zu treffen Wie werden Correlating Predictors hardwaremäßig implementiert? Das Implementieren dieser Predictors ist weitaus einfacher, als man es annehmen würde. Es wird einfach für die History-Bits ein m-Bit-Shift Register verwendet, um die letzten m Sprünge zu speichern. Welche Performancesteigerung ist durch Correlating Predictors erreichbar? Eqntott ist ein Benchmark, welches speziell mehrere voneinander abhängige Sprünge simuliert. Hier sinkt die Fehlvorhersage von 20% auf unter 8%! Beim GCC-Compiler sind dagegen keine Unterschiede zwischen Correlating Predictors und normaler 2-Bit Sprungvorhersage erkennbar. Kapitel 8 - Superskalarität Was bedeutet superskalar? Mit normalen Pipelines (Überlappen von Instruktionen) ist nur eine maximale Performance von einem Befehl / Takt technisch und theor
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itebenfalls ohne Verzögerung wiederzuverwenden. So kann bei einem Hit (Index stimmt mit Befehlsadresse überein) sofort der Instruction Counter mit der dazugehörigen Sprungadresse geladen werden). <span>Exeptions Exeptions unterbrechen den Programmablauf Aufgrund verschiedenster Fehler oder Anforderungen, wie Softwareinterrupts, Page Faults oder anderen Verletzungen. Bei synchronen Exeptions treten die Fehler stehts an der gleichen Programmstelle auf. Asynchrone werden durch externe Geräte ausgelöst und können nach dem laufenden Befehl ausgeführt werden. Was sind Precice Exeptions? Sind Exeptions, welche garantieren, dass die Exeptions direkt nach oder während des Befehles ausgeführt werden und kein Folgebefehl vorher abgearbeitet wird. Zusammenfassung der Sprungvorhersage Sprungvorhersage ist extrem wichtig für Pipelining und Superskalarität, um stalls und Verzögerungen zu minimieren. Bei statischer Vorhersage werden
Original toplevel document
Grundprinzipien der Rechnerarchitekturund das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! <span>Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. Da das Ziel eines Sprungbefehles oft erst festgestellt werden muss, liegt diese Adresse erst ab der MEM ACCESS Phase bereit. Somit kann das erneute Laden des Programmcounters auch erst in dieser Phase geschehen. So verzögert sich das Holen des nächsten Befehles um einige Takte. Durch eine Optimierung der Pipeline kann zwar die stall-Phase verkleinert, aber nicht ausgeschlossen werden. (durch Verlegung des Sprungbedingungstests in die Decode-Phase) Welche Methoden gibt es zur Reduzierung von Sprungverlusten? Predict Not Taken / Predict-Taken (fixed prediction) Objektcode basiert (statisch) dynamisch Brach-Prediction mit History Buffern (correlating / non-correlating) Delayed-Branch Wie funktioniert die Predict-Not-Taken bzw. Predict-Taken Methodik? Hier wird nichts weiter gemacht als entweder alle Sprünge voreingestellt abzulehnen oder alle Sprünge ersteinmal ohne Gewähr duchzuführen. Allgemeine Programmstatistiken sagen aus, dass mehr bedingte Sprünge ausgeführt als abgewiesen werden. Wie funktioniert die Delayed-Branch Methode? Hier wird ein sprungunabhängiger Befehl in den Delay Slot eingeschleust. Dies muss somit schon von den Compilerbauern berücksichtigt werden. Um diese Bedingung zu Umgehen wird die "Cancelling Branches"-Technik eingesetzt. Im Mittel werden dann trotzdem die Branch-Verluste verringert. Durch ein zusätzliches Bit im Befehlscode gibt der Compiler die wahrscheinlichste Sprungrichtung an. Nun kann entsprechend dieser Annahme ein Befehl in den Delay Slot eingefügt werden, der nur gültig ist, wenn der Sprung richtig vorhergesagt war. Falls nicht wird der Delay-Slot-Befehl abgebrochen (gecancelt). Dynamische Branch-Prediction Um Wartezeiten durch bedingte Sprünge zu vermeiden, sollte das Sprungziel schon mit dem Ende der Fetch-Phase zur Verfügung stehen. Es gibt zwei Ansätze Sprungzielspeicher (branch-target-buffer = BTB) Sprungvorhersage-Puffer (Branch History Table = BHT) Wie arbeitet eine Branch History Table? In dieser Tabelle wird im Grunde nur durch ein Bit (oder mehr) vermerkt, ob ein Sprung durchgeführt wurde oder nicht. Als Index der Tabelle dient der niederwertige Teil der Adresse des dazugehörigen Sprungbefehls. Nun kann die Pipeline in der Fetchphase nach einem eventuell vorhandenen Eintrag schauen und diesen als Entscheidungsgrundlage nehmen. Welchen Nachteil hat die 1-Bit Sprungvorhersage? Es wird nicht nur bei einem Schleifenaustritt der Sprung falsch vorhergesagt, sondern auch die erste Vorhersage bei erneuter Verwendung der Schleife. Wie arbeitet die 2-Bit-Sprungvorhersage mit BHT? Durch einen einfachen Zähler kann man den Nachteil der 1-Bit-Vorhersage minimieren. Hier wird die Vorhersage erst geändert, wenn sie zweimal falsch war. Es hat sich gezeigt, daß durch Zähler mit mehr als 2 Bit sich die Performance nicht weiter signifikant erhöhen läßt. Abb.: 2-Bit-Sprungvorhersagenautomat Wie arbeitet der Branch-Target-Buffer? Hier wird die Zieladresse eines gemachten Sprungs direkt gespeichert, um diese gegebenfalls ohne Verzögerung wiederzuverwenden. So kann bei einem Hit (Index stimmt mit Befehlsadresse überein) sofort der Instruction Counter mit der dazugehörigen Sprungadresse geladen werden). Exeptions Exeptions unterbrechen den Programmablauf Aufgrund verschiedenster Fehler oder Anforderungen, wie Softwareinterrupts, Page Faults oder anderen Verletzungen. Bei synchronen Exeptions treten die Fehler stehts an der gleichen Programmstelle auf. Asynchrone werden durch externe Geräte ausgelöst und können nach dem laufenden Befehl ausgeführt werden. Was sind Precice Exeptions? Sind Exeptions, welche garantieren, dass die Exeptions direkt nach oder während des Befehles ausgeführt werden und kein Folgebefehl vorher abgearbeitet wird. Zusammenfassung der Sprungvorhersage Sprungvorhersage ist extrem wichtig für Pipelining und Superskalarität, um stalls und Verzögerungen zu minimieren. Bei statischer Vorhersage werden Rückwärtssprünge meist erst durchgeführt und Vorwärtssprünge nicht. Wurde ein Sprung falsch vorhergesagt, muss die angefangene Instruktion rückgängig gemacht werden, was aufwendig ist. Deshalb gibt es ausgeklügelte Verfahren für die Branch Prediction. Statische Sprungvorhersage Es werden Compiler benutzt, die spezielle Sprungbefehle mitführen, welche ein Bit für die Sprungvorhersage enthalten. Da der Compiler ja weiß, wie oft eine Schleife durchlaufen wird, ist das sehr effizient. Dies muss aber architektonisch von der Hardware unterstützt werden. Des Weiteren ist kein Speicher für die History Table notwendig, was es kostengünstiger macht. Statische Verfahren erreichen eine Trefferrate von 65 bis 85%, was für moderne CPU's mit Superpipelines zu wenig ist. Dynamische Verfahren erreichen Trefferraten bei der Vorhersage von 98% und mehr! Dynamische Sprungvorhersage Es gibt zwei grundlegende Methoden. BHT und BTB. Die Branch History Table (Branch Predicion Buffer) ist ein Cache, in der alle bedingten Sprünge protokolliert werden. ( bis zu mehereren Tausend) Einfachste Version enthält ein Valid-Bit (Branch taken oder nicht), welches durch den niederwertigen Teil der Sprungadresse adressiert wird. Kompliziere Implementationen arbeiten nach dem n-Wege Prinzip. Durch Second Chance kann dieses Verfahren noch verbessert werden. Der Branch Target Buffer speichert nicht nur die taken-Bits, sondern auch die Sprungzieladresse, um null Verluste bei wiederholtem Aufruf zu haben. Das setzt voraus, dass nur taken branches aufgenommen werden. Bei einem Hit in der BTB kann somit während der Fetch Phase der Program Counter überschrieben werden. Werden keine History Bits mitgeführt spricht man vom BTAB. Wie arbeitet Second Chance? Nach Beenden einer Schleife wird ein Sprung logischerweise falsch vorhergesagt. Um zu vermeiden, dass nun fälschlicherweise das Sprungbit falsch gesetzt wird (da ja die gleiche Schleife noch mal durchlaufen werden kann), ändert man dieses erst nach der zweiten falschen Vorhersage. Leicht zu implementieren als Finite State Machine mit vier Zuständen. Nachteil der dynamischen Vorhersage ist die notwendige teuere und komplexere Hardware. Was ist der Vorteil von BHT gegenüber BTB? Branch Target Buffer loggen nur, ob ein Sprung genommen wurde oder nicht. Daher gibt es bei MIPS-Architekturen die BTB verwenden immernoch die sogenannten Branch Delay Slots, da die Sprungadresse trotzdem neu ermittelt werden muss. BHT beseitigen diesen Nachteil, da sie die Sprungadresse mit abspeichern und diese dann sofort in den IP geladen werden kann. Was sind Correlating Predictors? Betrachten wir folgendes Codefragment, fällt uns auf, daß ein Branch Predictor, der nur einen Sprung als Entscheidungsgrundlage einbezieht, den Zusammenhang der drei Sprünge nicht erkennen kann. if (a==10) //1. Sprung a=0; if (b=0) //2. Sprung b=0; if (a!=b){ //3. Sprung ... //abhängig von 1. und 2. Sprung } Um diese Abhängigkeiten in eine Sprungvorhersage einbeziehen zu können, sind Correlating Predictors notwendig. Solche Einheiten werden oft als (m,n)-Predictors bezeichnet. protokolliert wird das Verhalten der letzten m Sprünge je mit einem n-Bit Predictor (z.B. 2-Bit Second Chance) somit wird aus 2^m*n-Bit Preticors ausgewählt, um Vorhersage für den jeweiligen Sprung zu treffen Wie werden Correlating Predictors hardwaremäßig implementiert? Das Implementieren dieser Predictors ist weitaus einfacher, als man es annehmen würde. Es wird einfach für die History-Bits ein m-Bit-Shift Register verwendet, um die letzten m Sprünge zu speichern. Welche Performancesteigerung ist durch Correlating Predictors erreichbar? Eqntott ist ein Benchmark, welches speziell mehrere voneinander abhängige Sprünge simuliert. Hier sinkt die Fehlvorhersage von 20% auf unter 8%! Beim GCC-Compiler sind dagegen keine Unterschiede zwischen Correlating Predictors und normaler 2-Bit Sprungvorhersage erkennbar. Kapitel 8 - Superskalarität Was bedeutet superskalar? Mit normalen Pipelines (Überlappen von Instruktionen) ist nur eine maximale Performance von einem Befehl / Takt technisch und theor
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itge nicht. Wurde ein Sprung falsch vorhergesagt, muss die angefangene Instruktion rückgängig gemacht werden, was aufwendig ist. Deshalb gibt es ausgeklügelte Verfahren für die Branch Prediction. <span>Statische Sprungvorhersage Es werden Compiler benutzt, die spezielle Sprungbefehle mitführen, welche ein Bit für die Sprungvorhersage enthalten. Da der Compiler ja weiß, wie oft eine Schleife durchlaufen wird, ist das sehr effizient. Dies muss aber architektonisch von der Hardware unterstützt werden. Des Weiteren ist kein Speicher für die History Table notwendig, was es kostengünstiger macht. Statische Verfahren erreichen eine Trefferrate von 65 bis 85%, was für moderne CPU's mit Superpipelines zu wenig ist. Dynamische Verfahren erreichen Trefferraten bei der Vorhersage von 98% und mehr! Dynamische Sprungvorhersage Es gibt zwei grundlegende Methoden. BHT und BTB. Die Branch History Table (Branch Predicion Buffer) ist ein Cache, in der alle bedingten Sprünge protokollier
Original toplevel document
Grundprinzipien der Rechnerarchitekturund das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! <span>Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. Da das Ziel eines Sprungbefehles oft erst festgestellt werden muss, liegt diese Adresse erst ab der MEM ACCESS Phase bereit. Somit kann das erneute Laden des Programmcounters auch erst in dieser Phase geschehen. So verzögert sich das Holen des nächsten Befehles um einige Takte. Durch eine Optimierung der Pipeline kann zwar die stall-Phase verkleinert, aber nicht ausgeschlossen werden. (durch Verlegung des Sprungbedingungstests in die Decode-Phase) Welche Methoden gibt es zur Reduzierung von Sprungverlusten? Predict Not Taken / Predict-Taken (fixed prediction) Objektcode basiert (statisch) dynamisch Brach-Prediction mit History Buffern (correlating / non-correlating) Delayed-Branch Wie funktioniert die Predict-Not-Taken bzw. Predict-Taken Methodik? Hier wird nichts weiter gemacht als entweder alle Sprünge voreingestellt abzulehnen oder alle Sprünge ersteinmal ohne Gewähr duchzuführen. Allgemeine Programmstatistiken sagen aus, dass mehr bedingte Sprünge ausgeführt als abgewiesen werden. Wie funktioniert die Delayed-Branch Methode? Hier wird ein sprungunabhängiger Befehl in den Delay Slot eingeschleust. Dies muss somit schon von den Compilerbauern berücksichtigt werden. Um diese Bedingung zu Umgehen wird die "Cancelling Branches"-Technik eingesetzt. Im Mittel werden dann trotzdem die Branch-Verluste verringert. Durch ein zusätzliches Bit im Befehlscode gibt der Compiler die wahrscheinlichste Sprungrichtung an. Nun kann entsprechend dieser Annahme ein Befehl in den Delay Slot eingefügt werden, der nur gültig ist, wenn der Sprung richtig vorhergesagt war. Falls nicht wird der Delay-Slot-Befehl abgebrochen (gecancelt). Dynamische Branch-Prediction Um Wartezeiten durch bedingte Sprünge zu vermeiden, sollte das Sprungziel schon mit dem Ende der Fetch-Phase zur Verfügung stehen. Es gibt zwei Ansätze Sprungzielspeicher (branch-target-buffer = BTB) Sprungvorhersage-Puffer (Branch History Table = BHT) Wie arbeitet eine Branch History Table? In dieser Tabelle wird im Grunde nur durch ein Bit (oder mehr) vermerkt, ob ein Sprung durchgeführt wurde oder nicht. Als Index der Tabelle dient der niederwertige Teil der Adresse des dazugehörigen Sprungbefehls. Nun kann die Pipeline in der Fetchphase nach einem eventuell vorhandenen Eintrag schauen und diesen als Entscheidungsgrundlage nehmen. Welchen Nachteil hat die 1-Bit Sprungvorhersage? Es wird nicht nur bei einem Schleifenaustritt der Sprung falsch vorhergesagt, sondern auch die erste Vorhersage bei erneuter Verwendung der Schleife. Wie arbeitet die 2-Bit-Sprungvorhersage mit BHT? Durch einen einfachen Zähler kann man den Nachteil der 1-Bit-Vorhersage minimieren. Hier wird die Vorhersage erst geändert, wenn sie zweimal falsch war. Es hat sich gezeigt, daß durch Zähler mit mehr als 2 Bit sich die Performance nicht weiter signifikant erhöhen läßt. Abb.: 2-Bit-Sprungvorhersagenautomat Wie arbeitet der Branch-Target-Buffer? Hier wird die Zieladresse eines gemachten Sprungs direkt gespeichert, um diese gegebenfalls ohne Verzögerung wiederzuverwenden. So kann bei einem Hit (Index stimmt mit Befehlsadresse überein) sofort der Instruction Counter mit der dazugehörigen Sprungadresse geladen werden). Exeptions Exeptions unterbrechen den Programmablauf Aufgrund verschiedenster Fehler oder Anforderungen, wie Softwareinterrupts, Page Faults oder anderen Verletzungen. Bei synchronen Exeptions treten die Fehler stehts an der gleichen Programmstelle auf. Asynchrone werden durch externe Geräte ausgelöst und können nach dem laufenden Befehl ausgeführt werden. Was sind Precice Exeptions? Sind Exeptions, welche garantieren, dass die Exeptions direkt nach oder während des Befehles ausgeführt werden und kein Folgebefehl vorher abgearbeitet wird. Zusammenfassung der Sprungvorhersage Sprungvorhersage ist extrem wichtig für Pipelining und Superskalarität, um stalls und Verzögerungen zu minimieren. Bei statischer Vorhersage werden Rückwärtssprünge meist erst durchgeführt und Vorwärtssprünge nicht. Wurde ein Sprung falsch vorhergesagt, muss die angefangene Instruktion rückgängig gemacht werden, was aufwendig ist. Deshalb gibt es ausgeklügelte Verfahren für die Branch Prediction. Statische Sprungvorhersage Es werden Compiler benutzt, die spezielle Sprungbefehle mitführen, welche ein Bit für die Sprungvorhersage enthalten. Da der Compiler ja weiß, wie oft eine Schleife durchlaufen wird, ist das sehr effizient. Dies muss aber architektonisch von der Hardware unterstützt werden. Des Weiteren ist kein Speicher für die History Table notwendig, was es kostengünstiger macht. Statische Verfahren erreichen eine Trefferrate von 65 bis 85%, was für moderne CPU's mit Superpipelines zu wenig ist. Dynamische Verfahren erreichen Trefferraten bei der Vorhersage von 98% und mehr! Dynamische Sprungvorhersage Es gibt zwei grundlegende Methoden. BHT und BTB. Die Branch History Table (Branch Predicion Buffer) ist ein Cache, in der alle bedingten Sprünge protokolliert werden. ( bis zu mehereren Tausend) Einfachste Version enthält ein Valid-Bit (Branch taken oder nicht), welches durch den niederwertigen Teil der Sprungadresse adressiert wird. Kompliziere Implementationen arbeiten nach dem n-Wege Prinzip. Durch Second Chance kann dieses Verfahren noch verbessert werden. Der Branch Target Buffer speichert nicht nur die taken-Bits, sondern auch die Sprungzieladresse, um null Verluste bei wiederholtem Aufruf zu haben. Das setzt voraus, dass nur taken branches aufgenommen werden. Bei einem Hit in der BTB kann somit während der Fetch Phase der Program Counter überschrieben werden. Werden keine History Bits mitgeführt spricht man vom BTAB. Wie arbeitet Second Chance? Nach Beenden einer Schleife wird ein Sprung logischerweise falsch vorhergesagt. Um zu vermeiden, dass nun fälschlicherweise das Sprungbit falsch gesetzt wird (da ja die gleiche Schleife noch mal durchlaufen werden kann), ändert man dieses erst nach der zweiten falschen Vorhersage. Leicht zu implementieren als Finite State Machine mit vier Zuständen. Nachteil der dynamischen Vorhersage ist die notwendige teuere und komplexere Hardware. Was ist der Vorteil von BHT gegenüber BTB? Branch Target Buffer loggen nur, ob ein Sprung genommen wurde oder nicht. Daher gibt es bei MIPS-Architekturen die BTB verwenden immernoch die sogenannten Branch Delay Slots, da die Sprungadresse trotzdem neu ermittelt werden muss. BHT beseitigen diesen Nachteil, da sie die Sprungadresse mit abspeichern und diese dann sofort in den IP geladen werden kann. Was sind Correlating Predictors? Betrachten wir folgendes Codefragment, fällt uns auf, daß ein Branch Predictor, der nur einen Sprung als Entscheidungsgrundlage einbezieht, den Zusammenhang der drei Sprünge nicht erkennen kann. if (a==10) //1. Sprung a=0; if (b=0) //2. Sprung b=0; if (a!=b){ //3. Sprung ... //abhängig von 1. und 2. Sprung } Um diese Abhängigkeiten in eine Sprungvorhersage einbeziehen zu können, sind Correlating Predictors notwendig. Solche Einheiten werden oft als (m,n)-Predictors bezeichnet. protokolliert wird das Verhalten der letzten m Sprünge je mit einem n-Bit Predictor (z.B. 2-Bit Second Chance) somit wird aus 2^m*n-Bit Preticors ausgewählt, um Vorhersage für den jeweiligen Sprung zu treffen Wie werden Correlating Predictors hardwaremäßig implementiert? Das Implementieren dieser Predictors ist weitaus einfacher, als man es annehmen würde. Es wird einfach für die History-Bits ein m-Bit-Shift Register verwendet, um die letzten m Sprünge zu speichern. Welche Performancesteigerung ist durch Correlating Predictors erreichbar? Eqntott ist ein Benchmark, welches speziell mehrere voneinander abhängige Sprünge simuliert. Hier sinkt die Fehlvorhersage von 20% auf unter 8%! Beim GCC-Compiler sind dagegen keine Unterschiede zwischen Correlating Predictors und normaler 2-Bit Sprungvorhersage erkennbar. Kapitel 8 - Superskalarität Was bedeutet superskalar? Mit normalen Pipelines (Überlappen von Instruktionen) ist nur eine maximale Performance von einem Befehl / Takt technisch und theor
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itsche Verfahren erreichen eine Trefferrate von 65 bis 85%, was für moderne CPU's mit Superpipelines zu wenig ist. Dynamische Verfahren erreichen Trefferraten bei der Vorhersage von 98% und mehr! <span>Dynamische Sprungvorhersage Es gibt zwei grundlegende Methoden. BHT und BTB. Die Branch History Table (Branch Predicion Buffer) ist ein Cache, in der alle bedingten Sprünge protokolliert werden. ( bis zu mehereren Tausend) Einfachste Version enthält ein Valid-Bit (Branch taken oder nicht), welches durch den niederwertigen Teil der Sprungadresse adressiert wird. Kompliziere Implementationen arbeiten nach dem n-Wege Prinzip. Durch Second Chance kann dieses Verfahren noch verbessert werden. Der Branch Target Buffer speichert nicht nur die taken-Bits, sondern auch die Sprungzieladresse, um null Verluste bei wiederholtem Aufruf zu haben. Das setzt voraus, dass nur taken branches aufgenommen werden. Bei einem Hit in der BTB kann somit während der Fetch Phase der Program Counter überschrieben werden. Werden keine History Bits mitgeführt spricht man vom BTAB. Wie arbeitet Second Chance? Nach Beenden einer Schleife wird ein Sprung logischerweise falsch vorhergesagt. Um zu vermeiden, dass nun fälschlicherweise das Sprungbit falsch gesetzt wird (da ja die gleiche Schleife noch mal durchlaufen werden kann), ändert man dieses erst nach der zweiten falschen Vorhersage. Leicht zu implementieren als Finite State Machine mit vier Zuständen. Nachteil der dynamischen Vorhersage ist die notwendige teuere und komplexere Hardware. Was ist der Vorteil von BHT gegenüber BTB? Branch Target Buffer loggen nur, ob ein Sprung genommen wurde oder nicht. Daher gibt es bei MIPS-Architekturen die BTB verwenden immernoch die sogenannten Branch Delay Slots, da die Sprungadresse trotzdem neu ermittelt werden muss. BHT beseitigen diesen Nachteil, da sie die Sprungadresse mit abspeichern und diese dann sofort in den IP geladen werden kann. Was sind Correlating Predictors? Betrachten wir folgendes Codefragment, fällt uns auf, daß ein Branch Predictor, der nur einen Sprung als Entscheidungsgrundlage einbezieht, den Zusammenhang der drei Sprünge nicht erkennen kann. if (a==10) //1. Sprung a=0; if (b=0) //2. Sprung b=0; if (a!=b){ //3. Sprung ... //abhängig von 1. und 2. Sprung } Um diese Abhängigkeiten in eine Sprungvorhersage einbeziehen zu können, sind Correlating Predictors notwendig. Solche Einheiten werden oft als (m,n)-Predictors bezeichnet. protokolliert wird das Verhalten der letzten m Sprünge je mit einem n-Bit Predictor (z.B. 2-Bit Second Chance) somit wird aus 2^m*n-Bit Preticors ausgewählt, um Vorhersage für den jeweiligen Sprung zu treffen Wie werden Correlating Predictors hardwaremäßig implementiert? Das Implementieren dieser Predictors ist weitaus einfacher, als man es annehmen würde. Es wird einfach für die History-Bits ein m-Bit-Shift Register verwendet, um die letzten m Sprünge zu speichern. Welche Performancesteigerung ist durch Correlating Predictors erreichbar? Eqntott ist ein Benchmark, welches speziell mehrere voneinander abhängige Sprünge simuliert. Hier sinkt die Fehlvorhersage von 20% auf unter 8%! Beim GCC-Compiler sind dagegen keine Unterschiede zwischen Correlating Predictors und normaler 2-Bit Sprungvorhersage erkennbar. <span>
Original toplevel document
Grundprinzipien der Rechnerarchitekturund das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! <span>Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. Da das Ziel eines Sprungbefehles oft erst festgestellt werden muss, liegt diese Adresse erst ab der MEM ACCESS Phase bereit. Somit kann das erneute Laden des Programmcounters auch erst in dieser Phase geschehen. So verzögert sich das Holen des nächsten Befehles um einige Takte. Durch eine Optimierung der Pipeline kann zwar die stall-Phase verkleinert, aber nicht ausgeschlossen werden. (durch Verlegung des Sprungbedingungstests in die Decode-Phase) Welche Methoden gibt es zur Reduzierung von Sprungverlusten? Predict Not Taken / Predict-Taken (fixed prediction) Objektcode basiert (statisch) dynamisch Brach-Prediction mit History Buffern (correlating / non-correlating) Delayed-Branch Wie funktioniert die Predict-Not-Taken bzw. Predict-Taken Methodik? Hier wird nichts weiter gemacht als entweder alle Sprünge voreingestellt abzulehnen oder alle Sprünge ersteinmal ohne Gewähr duchzuführen. Allgemeine Programmstatistiken sagen aus, dass mehr bedingte Sprünge ausgeführt als abgewiesen werden. Wie funktioniert die Delayed-Branch Methode? Hier wird ein sprungunabhängiger Befehl in den Delay Slot eingeschleust. Dies muss somit schon von den Compilerbauern berücksichtigt werden. Um diese Bedingung zu Umgehen wird die "Cancelling Branches"-Technik eingesetzt. Im Mittel werden dann trotzdem die Branch-Verluste verringert. Durch ein zusätzliches Bit im Befehlscode gibt der Compiler die wahrscheinlichste Sprungrichtung an. Nun kann entsprechend dieser Annahme ein Befehl in den Delay Slot eingefügt werden, der nur gültig ist, wenn der Sprung richtig vorhergesagt war. Falls nicht wird der Delay-Slot-Befehl abgebrochen (gecancelt). Dynamische Branch-Prediction Um Wartezeiten durch bedingte Sprünge zu vermeiden, sollte das Sprungziel schon mit dem Ende der Fetch-Phase zur Verfügung stehen. Es gibt zwei Ansätze Sprungzielspeicher (branch-target-buffer = BTB) Sprungvorhersage-Puffer (Branch History Table = BHT) Wie arbeitet eine Branch History Table? In dieser Tabelle wird im Grunde nur durch ein Bit (oder mehr) vermerkt, ob ein Sprung durchgeführt wurde oder nicht. Als Index der Tabelle dient der niederwertige Teil der Adresse des dazugehörigen Sprungbefehls. Nun kann die Pipeline in der Fetchphase nach einem eventuell vorhandenen Eintrag schauen und diesen als Entscheidungsgrundlage nehmen. Welchen Nachteil hat die 1-Bit Sprungvorhersage? Es wird nicht nur bei einem Schleifenaustritt der Sprung falsch vorhergesagt, sondern auch die erste Vorhersage bei erneuter Verwendung der Schleife. Wie arbeitet die 2-Bit-Sprungvorhersage mit BHT? Durch einen einfachen Zähler kann man den Nachteil der 1-Bit-Vorhersage minimieren. Hier wird die Vorhersage erst geändert, wenn sie zweimal falsch war. Es hat sich gezeigt, daß durch Zähler mit mehr als 2 Bit sich die Performance nicht weiter signifikant erhöhen läßt. Abb.: 2-Bit-Sprungvorhersagenautomat Wie arbeitet der Branch-Target-Buffer? Hier wird die Zieladresse eines gemachten Sprungs direkt gespeichert, um diese gegebenfalls ohne Verzögerung wiederzuverwenden. So kann bei einem Hit (Index stimmt mit Befehlsadresse überein) sofort der Instruction Counter mit der dazugehörigen Sprungadresse geladen werden). Exeptions Exeptions unterbrechen den Programmablauf Aufgrund verschiedenster Fehler oder Anforderungen, wie Softwareinterrupts, Page Faults oder anderen Verletzungen. Bei synchronen Exeptions treten die Fehler stehts an der gleichen Programmstelle auf. Asynchrone werden durch externe Geräte ausgelöst und können nach dem laufenden Befehl ausgeführt werden. Was sind Precice Exeptions? Sind Exeptions, welche garantieren, dass die Exeptions direkt nach oder während des Befehles ausgeführt werden und kein Folgebefehl vorher abgearbeitet wird. Zusammenfassung der Sprungvorhersage Sprungvorhersage ist extrem wichtig für Pipelining und Superskalarität, um stalls und Verzögerungen zu minimieren. Bei statischer Vorhersage werden Rückwärtssprünge meist erst durchgeführt und Vorwärtssprünge nicht. Wurde ein Sprung falsch vorhergesagt, muss die angefangene Instruktion rückgängig gemacht werden, was aufwendig ist. Deshalb gibt es ausgeklügelte Verfahren für die Branch Prediction. Statische Sprungvorhersage Es werden Compiler benutzt, die spezielle Sprungbefehle mitführen, welche ein Bit für die Sprungvorhersage enthalten. Da der Compiler ja weiß, wie oft eine Schleife durchlaufen wird, ist das sehr effizient. Dies muss aber architektonisch von der Hardware unterstützt werden. Des Weiteren ist kein Speicher für die History Table notwendig, was es kostengünstiger macht. Statische Verfahren erreichen eine Trefferrate von 65 bis 85%, was für moderne CPU's mit Superpipelines zu wenig ist. Dynamische Verfahren erreichen Trefferraten bei der Vorhersage von 98% und mehr! Dynamische Sprungvorhersage Es gibt zwei grundlegende Methoden. BHT und BTB. Die Branch History Table (Branch Predicion Buffer) ist ein Cache, in der alle bedingten Sprünge protokolliert werden. ( bis zu mehereren Tausend) Einfachste Version enthält ein Valid-Bit (Branch taken oder nicht), welches durch den niederwertigen Teil der Sprungadresse adressiert wird. Kompliziere Implementationen arbeiten nach dem n-Wege Prinzip. Durch Second Chance kann dieses Verfahren noch verbessert werden. Der Branch Target Buffer speichert nicht nur die taken-Bits, sondern auch die Sprungzieladresse, um null Verluste bei wiederholtem Aufruf zu haben. Das setzt voraus, dass nur taken branches aufgenommen werden. Bei einem Hit in der BTB kann somit während der Fetch Phase der Program Counter überschrieben werden. Werden keine History Bits mitgeführt spricht man vom BTAB. Wie arbeitet Second Chance? Nach Beenden einer Schleife wird ein Sprung logischerweise falsch vorhergesagt. Um zu vermeiden, dass nun fälschlicherweise das Sprungbit falsch gesetzt wird (da ja die gleiche Schleife noch mal durchlaufen werden kann), ändert man dieses erst nach der zweiten falschen Vorhersage. Leicht zu implementieren als Finite State Machine mit vier Zuständen. Nachteil der dynamischen Vorhersage ist die notwendige teuere und komplexere Hardware. Was ist der Vorteil von BHT gegenüber BTB? Branch Target Buffer loggen nur, ob ein Sprung genommen wurde oder nicht. Daher gibt es bei MIPS-Architekturen die BTB verwenden immernoch die sogenannten Branch Delay Slots, da die Sprungadresse trotzdem neu ermittelt werden muss. BHT beseitigen diesen Nachteil, da sie die Sprungadresse mit abspeichern und diese dann sofort in den IP geladen werden kann. Was sind Correlating Predictors? Betrachten wir folgendes Codefragment, fällt uns auf, daß ein Branch Predictor, der nur einen Sprung als Entscheidungsgrundlage einbezieht, den Zusammenhang der drei Sprünge nicht erkennen kann. if (a==10) //1. Sprung a=0; if (b=0) //2. Sprung b=0; if (a!=b){ //3. Sprung ... //abhängig von 1. und 2. Sprung } Um diese Abhängigkeiten in eine Sprungvorhersage einbeziehen zu können, sind Correlating Predictors notwendig. Solche Einheiten werden oft als (m,n)-Predictors bezeichnet. protokolliert wird das Verhalten der letzten m Sprünge je mit einem n-Bit Predictor (z.B. 2-Bit Second Chance) somit wird aus 2^m*n-Bit Preticors ausgewählt, um Vorhersage für den jeweiligen Sprung zu treffen Wie werden Correlating Predictors hardwaremäßig implementiert? Das Implementieren dieser Predictors ist weitaus einfacher, als man es annehmen würde. Es wird einfach für die History-Bits ein m-Bit-Shift Register verwendet, um die letzten m Sprünge zu speichern. Welche Performancesteigerung ist durch Correlating Predictors erreichbar? Eqntott ist ein Benchmark, welches speziell mehrere voneinander abhängige Sprünge simuliert. Hier sinkt die Fehlvorhersage von 20% auf unter 8%! Beim GCC-Compiler sind dagegen keine Unterschiede zwischen Correlating Predictors und normaler 2-Bit Sprungvorhersage erkennbar. Kapitel 8 - Superskalarität Was bedeutet superskalar? Mit normalen Pipelines (Überlappen von Instruktionen) ist nur eine maximale Performance von einem Befehl / Takt technisch und theor
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itchiedenen Unterbrechungen! Wenn in der Literatur von Interrupts gesprochen wird, so werden oft externe, asynchrone Interrupts gemeint, welche meistens in Zusammenhang mit E/A-Geräten auftreten. <span>Wie arbeiten Traps (Fangstellen?) Traps sind eine Art automatische Prozeduraufrufe, welche durch eine vom Programm verursachte Bedingung eingeleitet werden. Solch eine Bedingung kann z.B. Gleitkommaüberlauf, Schutzverletzung oder Stapelüberlauf. Findet ein Überlauf statt, so stoppt die Ablaufsteuerung die Ausführung und holt von einer bestimmten Stelle im Speicher die Adresse des Trap-Handlers (Prozedur), mit der dann der Programmcounter überschrieben wird. Wesentliches Merkmal eines Traps ist, daß es durch Ausnahmebedingungen ausgelöst wird, welche durch Hardware oder Mikroprogramme erkannt werden. Wie arbeiten Interrupts Interrupts sind Unterbrechungen der Ablaufsteuerung. Wie es für Traps Trap-Handler gibt, gibt es für Interrupts Interrupt-Handler. Nach Abarbeitung des Interrupt
Original toplevel document
Grundprinzipien der Rechnerarchitekturrt das Big-Endian-Format. Falls Worte so in den Speicher passen, das keine Verschiebungen auftreten, heißt der Speicher aligned. Prüfen kann man dies durch die Formel Adresse mod Wortlänge = 0? <span>Kapitel 2 - Interrupts und DMA Klassifizieren Sie die verschiedenen Unterbrechungen! Wenn in der Literatur von Interrupts gesprochen wird, so werden oft externe, asynchrone Interrupts gemeint, welche meistens in Zusammenhang mit E/A-Geräten auftreten. Wie arbeiten Traps (Fangstellen?) Traps sind eine Art automatische Prozeduraufrufe, welche durch eine vom Programm verursachte Bedingung eingeleitet werden. Solch eine Bedingung kann z.B. Gleitkommaüberlauf, Schutzverletzung oder Stapelüberlauf. Findet ein Überlauf statt, so stoppt die Ablaufsteuerung die Ausführung und holt von einer bestimmten Stelle im Speicher die Adresse des Trap-Handlers (Prozedur), mit der dann der Programmcounter überschrieben wird. Wesentliches Merkmal eines Traps ist, daß es durch Ausnahmebedingungen ausgelöst wird, welche durch Hardware oder Mikroprogramme erkannt werden. Wie arbeiten Interrupts Interrupts sind Unterbrechungen der Ablaufsteuerung. Wie es für Traps Trap-Handler gibt, gibt es für Interrupts Interrupt-Handler. Nach Abarbeitung des Interrupt-Handlers wird die Kontrolle wieder an das Programm zurückgegeben. Der interne Zustand des Prozessors (IP, Register, ...) muss nun exakt wiederhergestellt werden. Der Unterschied zwischen Traps und Interrupts ist nun, daß Traps synchron mit dem ausgeführten Programm laufen. Deshalb werden sie auch erst nach der Befehlsausführung erkannt und ausgeführt. Asynchrone Interrupts sind dagegen unabhängig vom gerade ausgeführten Programm. Interrupt’s stammen von echten physikalischen INT-Quellen wie z.B. IRQ3 von COM1 kommt. Diese springen über ein Interrupt-Gate. Interrupt’s die per Software mit INT-Befehl ausgelöst werden, springen über Trap-Gates! Wenn ein Interrupt ein Interrupt-Gate durchläuft, wird das IF=0 automatisch gesetzt, d.h. es gehen überhaupt keine Interrupts mehr durch. Asynchrone Interrupts können also nicht unterbrochen werden. Trap-Gates dürfen unterbrochen werden, da sie nicht zeitkritisch sind. Interrupt- und Trap-Gates führen nicht zu Taskwechsel über ein TSS. Das retten der Register ist dem INT-Handler überlassen. Was sind Software Interrupts? Software-Interrupts werden von Programmen mit Hilfe von speziellen Maschinenbefehlen aufgerufen. Dabei müssen diese nur eine Nummer für das benötigte Interrupt kennen. Über diese Nummer wird in der Interrupt-Vektor-Tabelle die Adresse des Interrupt-Unterprogrammes (ISR) referenziert und ausgeführt. Was versteht man unter internen und externen Interrupts? Externe Interrupts sind asynchron, wie nichtvektorisierte und vektorisierte Interrupts. Interne sind synchron, wie Software Interrupts oder Exection-Traps (Reaktionen auf interne Fehler wie FPU-Errors oder Page-Faults). Was ist Polling? Polling ist das zyklische Abfragen von einen oder mehreren E/A-Devices zur Feststellung der Kommunikationsbereitschaft bzw. zum Einholen von Kommunikationswünschen. Vorteile des Pollings Nachteile des Pollings Einfach zu Implementieren Hoher Programm-Overhead Kommunikationsanforderungen erfolgen synchron zum Programmablauf Die meisten Anfragen an die Geräte sind unnötig Je mehr Geräte am Bus hängen, um so mehr steigt Reaktionszeit. Priorisierung bei zeitgleichen Anfragen erfordert zusätzlichen Zeitaufwand Aufgrund der vielen Nachteile sollte besser eine asynchrone Kommunikation mit den Geräten durch die Hardware unterstützt werden (Interrupts). Das Interrupt-Prinzip Es kann auch über eine Art "hardware-gestütztes Polling" über spezielle Interrupt-Signalleitungen eine Kommunikationsanforderung festgestellt werden. Dazu muss aber die Befehlsverarbeitungschleife um eine Unterbrechungsanfrage erweitert werden. Erklären Sie den Unterschied zwischen vektorisierten und nichtvektorisierten Interrupts! Man unterscheidet vektorisierten und nichtvektorisierten Interrupt. Bei nichtvektorisierten Interrupts wird dem Interruptsignal eine feste Adresse zugeordnet. Bei vektorisierten Interrupts wird dynamisch eine wahlfreie Adresse zugeordnet, welche durch die CPU über ein definiertes Protokoll vom Datenbus gelesen wird. Was passiert beim Auftreten eines Interrupts? 1. Sperren weiterer Unterbrechungen mit gleicher oder geringerer Priotität Unterbrechungen mit höherer Wichtigkeit dürfen normalerweise solche mit geringerer Wichtigkeit wieder unterbrechen 2. Rettung wichtiger Register-Informationen(Prozessorstatus) alle Prozessor-Register retten, die durch die Interruptbehandlung überschrieben würden heute gibt es dafür spezielle Maschinenbefehle 3. Bestimmen der Interruptquelle (durch Hardware realisiert) 4. Laden des zugehörigen Interruptvektors d.h. das Herstellen des Anfangszustandes für gewählte Interruptroutine 5. Abarbeitung der Interruptroutine Retten weiterer Zustandsinformationen, sofern nicht durch Hardware realisiert meistens Übernahme weiterer Parameter von definierten Stellen (bei Systemaufruf Ruf-Nr. und weitere Parameter oder bei Geräte-Interrupt Gerätestatusbits wie E/A Fortschritt, Fehler etc.) eigentliche Behandlung des Interrupts, z.B. Setzen eines Flags (z.B. bei Gleitkommaüberlauf oder Aufruf zum Rückpositionieren und erneutem Lesen bei Lesefehler bei Magnetbandkassette (komplizierterer Fall) 6. Rückkehr zur unterbrochenen Aufgabe entweder Rückspeichern der geretteten Registerinformationen, d.h. Wiederherstellen des Prozessorzustandes oder Bearbeitung einer neuen Aufgabe, z.B. bei Uhrinterrupt nach Ablauf einer Zeitscheibe oder Zustand "HALT" nach schwerem Fehler, z.B. Spannungsausfall (abort) Welche beiden Zustandssicherungskonzepte gibt es totale Sicherung aller bislang nicht automatisch gesicherten Register der CPU-Status des unterbrochenen Programms wird komplett eingefroren auch die invarianten Anteile werden gesichert, der Programmzustand ist damit leicht zugreifbar weit verbreitet bei Allzweckbetriebssystemen (z.B. UNIX & Co.) partielle Sicherung der im weiteren Verlauf nicht gesicherten Register der CPU-Status des unterbrochenen Programms wird teilweise eingefroren es wird nur der wirklich von Änderungen betroffene Anteil gesichert der Programmzustand ist damit nicht leicht zugreifbar weit verbreitet bei Spezialzweckbetriebssystemen Was stellt das Hauptproblem bei Interrupts dar Interrupts verhalten sich nicht deterministisch. D.h. ihre Abarbeitungszeit variiert. Sie sollte trotzdem so gering wie möglich gehalten werden. Warum wird DMA oft Interrupts vorgezogen? Zwar befreien Interrupts die Prozessoren vom Warten auf E/A Ereignisse, aber vektorisierte Interrupts benötigen viele Taktzyklen zu ihrer Abarbeitung. Dieser Overhead steigt natürlich, um so weniger Datenmengen bei einer Interruptauslösung übertragen werden. Interrupts werden erst nach der Befehlsabarbeitung erkannt und ausgeführt. Dies ist ein Problem bei Echtzeitanwendungen, da sich diese Verzögerung negativ auswirken kann. Außerdem kommt es durch Interrupts bei Instruction-Set-Parallismus oft zu Pipeline-Neustarts. Die Lösung dieser Probleme wäre ein direkter Speicherzugriff eines Devices, da so der Prozessor komplett umgangen werden kann. Wie kann DMA implementiert werden? Zentral Ein zentraler DMA-Controller steht allen Geräten zu Verfügung. Dezentral: Jede E/A-Einheit hat ihren eigenen DMA-Controller implementiert und kann selbst Busmaster werden Probleme bei DMA treten vor allem durch ihre Unabhängigkeit und die dadurch notwendigen Schutzmaßnahmen auf. Ein DMA-Controller wirkt wie ein weiterer Prozessor am Bus. Um Inkonsistenzen im Speicher zu vermeiden, muss ein DMA-Controller eng mit dem Speichermanagment des Systems zusammenarbeiten. Was ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adr
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itder dann der Programmcounter überschrieben wird. Wesentliches Merkmal eines Traps ist, daß es durch Ausnahmebedingungen ausgelöst wird, welche durch Hardware oder Mikroprogramme erkannt werden. <span>Wie arbeiten Interrupts Interrupts sind Unterbrechungen der Ablaufsteuerung. Wie es für Traps Trap-Handler gibt, gibt es für Interrupts Interrupt-Handler. Nach Abarbeitung des Interrupt-Handlers wird die Kontrolle wieder an das Programm zurückgegeben. Der interne Zustand des Prozessors (IP, Register, ...) muss nun exakt wiederhergestellt werden. Der Unterschied zwischen Traps und Interrupts ist nun, daß Traps synchron mit dem ausgeführten Programm laufen. Deshalb werden sie auch erst nach der Befehlsausführung erkannt und ausgeführt. Asynchrone Interrupts sind dagegen unabhängig vom gerade ausgeführten Programm. Interrupt’s stammen von echten physikalischen INT-Quellen wie z.B. IRQ3 von COM1 kommt. Diese springen über ein Interrupt-Gate. Interrupt’s die per Software mit INT-Befehl ausgelöst werden, springen über Trap-Gates! Wenn ein Interrupt ein Interrupt-Gate durchläuft, wird das IF=0 automatisch gesetzt, d.h. es gehen überhaupt keine Interrupts mehr durch. Asynchrone Interrupts können also nicht unterbrochen werden. Trap-Gates dürfen unterbrochen werden, da sie nicht zeitkritisch sind. Interrupt- und Trap-Gates führen nicht zu Taskwechsel über ein TSS. Das retten der Register ist dem INT-Handler überlassen. Was sind Software Interrupts? Software-Interrupts werden von Programmen mit Hilfe von speziellen Maschinenbefehlen aufgerufen. Dabei müssen diese nur eine Nummer für das benötigte Inter
Original toplevel document
Grundprinzipien der Rechnerarchitekturrt das Big-Endian-Format. Falls Worte so in den Speicher passen, das keine Verschiebungen auftreten, heißt der Speicher aligned. Prüfen kann man dies durch die Formel Adresse mod Wortlänge = 0? <span>Kapitel 2 - Interrupts und DMA Klassifizieren Sie die verschiedenen Unterbrechungen! Wenn in der Literatur von Interrupts gesprochen wird, so werden oft externe, asynchrone Interrupts gemeint, welche meistens in Zusammenhang mit E/A-Geräten auftreten. Wie arbeiten Traps (Fangstellen?) Traps sind eine Art automatische Prozeduraufrufe, welche durch eine vom Programm verursachte Bedingung eingeleitet werden. Solch eine Bedingung kann z.B. Gleitkommaüberlauf, Schutzverletzung oder Stapelüberlauf. Findet ein Überlauf statt, so stoppt die Ablaufsteuerung die Ausführung und holt von einer bestimmten Stelle im Speicher die Adresse des Trap-Handlers (Prozedur), mit der dann der Programmcounter überschrieben wird. Wesentliches Merkmal eines Traps ist, daß es durch Ausnahmebedingungen ausgelöst wird, welche durch Hardware oder Mikroprogramme erkannt werden. Wie arbeiten Interrupts Interrupts sind Unterbrechungen der Ablaufsteuerung. Wie es für Traps Trap-Handler gibt, gibt es für Interrupts Interrupt-Handler. Nach Abarbeitung des Interrupt-Handlers wird die Kontrolle wieder an das Programm zurückgegeben. Der interne Zustand des Prozessors (IP, Register, ...) muss nun exakt wiederhergestellt werden. Der Unterschied zwischen Traps und Interrupts ist nun, daß Traps synchron mit dem ausgeführten Programm laufen. Deshalb werden sie auch erst nach der Befehlsausführung erkannt und ausgeführt. Asynchrone Interrupts sind dagegen unabhängig vom gerade ausgeführten Programm. Interrupt’s stammen von echten physikalischen INT-Quellen wie z.B. IRQ3 von COM1 kommt. Diese springen über ein Interrupt-Gate. Interrupt’s die per Software mit INT-Befehl ausgelöst werden, springen über Trap-Gates! Wenn ein Interrupt ein Interrupt-Gate durchläuft, wird das IF=0 automatisch gesetzt, d.h. es gehen überhaupt keine Interrupts mehr durch. Asynchrone Interrupts können also nicht unterbrochen werden. Trap-Gates dürfen unterbrochen werden, da sie nicht zeitkritisch sind. Interrupt- und Trap-Gates führen nicht zu Taskwechsel über ein TSS. Das retten der Register ist dem INT-Handler überlassen. Was sind Software Interrupts? Software-Interrupts werden von Programmen mit Hilfe von speziellen Maschinenbefehlen aufgerufen. Dabei müssen diese nur eine Nummer für das benötigte Interrupt kennen. Über diese Nummer wird in der Interrupt-Vektor-Tabelle die Adresse des Interrupt-Unterprogrammes (ISR) referenziert und ausgeführt. Was versteht man unter internen und externen Interrupts? Externe Interrupts sind asynchron, wie nichtvektorisierte und vektorisierte Interrupts. Interne sind synchron, wie Software Interrupts oder Exection-Traps (Reaktionen auf interne Fehler wie FPU-Errors oder Page-Faults). Was ist Polling? Polling ist das zyklische Abfragen von einen oder mehreren E/A-Devices zur Feststellung der Kommunikationsbereitschaft bzw. zum Einholen von Kommunikationswünschen. Vorteile des Pollings Nachteile des Pollings Einfach zu Implementieren Hoher Programm-Overhead Kommunikationsanforderungen erfolgen synchron zum Programmablauf Die meisten Anfragen an die Geräte sind unnötig Je mehr Geräte am Bus hängen, um so mehr steigt Reaktionszeit. Priorisierung bei zeitgleichen Anfragen erfordert zusätzlichen Zeitaufwand Aufgrund der vielen Nachteile sollte besser eine asynchrone Kommunikation mit den Geräten durch die Hardware unterstützt werden (Interrupts). Das Interrupt-Prinzip Es kann auch über eine Art "hardware-gestütztes Polling" über spezielle Interrupt-Signalleitungen eine Kommunikationsanforderung festgestellt werden. Dazu muss aber die Befehlsverarbeitungschleife um eine Unterbrechungsanfrage erweitert werden. Erklären Sie den Unterschied zwischen vektorisierten und nichtvektorisierten Interrupts! Man unterscheidet vektorisierten und nichtvektorisierten Interrupt. Bei nichtvektorisierten Interrupts wird dem Interruptsignal eine feste Adresse zugeordnet. Bei vektorisierten Interrupts wird dynamisch eine wahlfreie Adresse zugeordnet, welche durch die CPU über ein definiertes Protokoll vom Datenbus gelesen wird. Was passiert beim Auftreten eines Interrupts? 1. Sperren weiterer Unterbrechungen mit gleicher oder geringerer Priotität Unterbrechungen mit höherer Wichtigkeit dürfen normalerweise solche mit geringerer Wichtigkeit wieder unterbrechen 2. Rettung wichtiger Register-Informationen(Prozessorstatus) alle Prozessor-Register retten, die durch die Interruptbehandlung überschrieben würden heute gibt es dafür spezielle Maschinenbefehle 3. Bestimmen der Interruptquelle (durch Hardware realisiert) 4. Laden des zugehörigen Interruptvektors d.h. das Herstellen des Anfangszustandes für gewählte Interruptroutine 5. Abarbeitung der Interruptroutine Retten weiterer Zustandsinformationen, sofern nicht durch Hardware realisiert meistens Übernahme weiterer Parameter von definierten Stellen (bei Systemaufruf Ruf-Nr. und weitere Parameter oder bei Geräte-Interrupt Gerätestatusbits wie E/A Fortschritt, Fehler etc.) eigentliche Behandlung des Interrupts, z.B. Setzen eines Flags (z.B. bei Gleitkommaüberlauf oder Aufruf zum Rückpositionieren und erneutem Lesen bei Lesefehler bei Magnetbandkassette (komplizierterer Fall) 6. Rückkehr zur unterbrochenen Aufgabe entweder Rückspeichern der geretteten Registerinformationen, d.h. Wiederherstellen des Prozessorzustandes oder Bearbeitung einer neuen Aufgabe, z.B. bei Uhrinterrupt nach Ablauf einer Zeitscheibe oder Zustand "HALT" nach schwerem Fehler, z.B. Spannungsausfall (abort) Welche beiden Zustandssicherungskonzepte gibt es totale Sicherung aller bislang nicht automatisch gesicherten Register der CPU-Status des unterbrochenen Programms wird komplett eingefroren auch die invarianten Anteile werden gesichert, der Programmzustand ist damit leicht zugreifbar weit verbreitet bei Allzweckbetriebssystemen (z.B. UNIX & Co.) partielle Sicherung der im weiteren Verlauf nicht gesicherten Register der CPU-Status des unterbrochenen Programms wird teilweise eingefroren es wird nur der wirklich von Änderungen betroffene Anteil gesichert der Programmzustand ist damit nicht leicht zugreifbar weit verbreitet bei Spezialzweckbetriebssystemen Was stellt das Hauptproblem bei Interrupts dar Interrupts verhalten sich nicht deterministisch. D.h. ihre Abarbeitungszeit variiert. Sie sollte trotzdem so gering wie möglich gehalten werden. Warum wird DMA oft Interrupts vorgezogen? Zwar befreien Interrupts die Prozessoren vom Warten auf E/A Ereignisse, aber vektorisierte Interrupts benötigen viele Taktzyklen zu ihrer Abarbeitung. Dieser Overhead steigt natürlich, um so weniger Datenmengen bei einer Interruptauslösung übertragen werden. Interrupts werden erst nach der Befehlsabarbeitung erkannt und ausgeführt. Dies ist ein Problem bei Echtzeitanwendungen, da sich diese Verzögerung negativ auswirken kann. Außerdem kommt es durch Interrupts bei Instruction-Set-Parallismus oft zu Pipeline-Neustarts. Die Lösung dieser Probleme wäre ein direkter Speicherzugriff eines Devices, da so der Prozessor komplett umgangen werden kann. Wie kann DMA implementiert werden? Zentral Ein zentraler DMA-Controller steht allen Geräten zu Verfügung. Dezentral: Jede E/A-Einheit hat ihren eigenen DMA-Controller implementiert und kann selbst Busmaster werden Probleme bei DMA treten vor allem durch ihre Unabhängigkeit und die dadurch notwendigen Schutzmaßnahmen auf. Ein DMA-Controller wirkt wie ein weiterer Prozessor am Bus. Um Inkonsistenzen im Speicher zu vermeiden, muss ein DMA-Controller eng mit dem Speichermanagment des Systems zusammenarbeiten. Was ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adr
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itsen diese nur eine Nummer für das benötigte Interrupt kennen. Über diese Nummer wird in der Interrupt-Vektor-Tabelle die Adresse des Interrupt-Unterprogrammes (ISR) referenziert und ausgeführt. <span>Was versteht man unter internen und externen Interrupts? Externe Interrupts sind asynchron, wie nichtvektorisierte und vektorisierte Interrupts. Interne sind synchron, wie Software Interrupts oder Exection-Traps (Reaktionen auf interne Fehler wie FPU-Errors oder Page-Faults). Was ist Polling? Polling ist das zyklische Abfragen von einen oder mehreren E/A-Devices zur Feststellung der Kommunikationsbereitschaft bzw. zum Einholen von Kommunikationswünschen. Vor
Original toplevel document
Grundprinzipien der Rechnerarchitekturrt das Big-Endian-Format. Falls Worte so in den Speicher passen, das keine Verschiebungen auftreten, heißt der Speicher aligned. Prüfen kann man dies durch die Formel Adresse mod Wortlänge = 0? <span>Kapitel 2 - Interrupts und DMA Klassifizieren Sie die verschiedenen Unterbrechungen! Wenn in der Literatur von Interrupts gesprochen wird, so werden oft externe, asynchrone Interrupts gemeint, welche meistens in Zusammenhang mit E/A-Geräten auftreten. Wie arbeiten Traps (Fangstellen?) Traps sind eine Art automatische Prozeduraufrufe, welche durch eine vom Programm verursachte Bedingung eingeleitet werden. Solch eine Bedingung kann z.B. Gleitkommaüberlauf, Schutzverletzung oder Stapelüberlauf. Findet ein Überlauf statt, so stoppt die Ablaufsteuerung die Ausführung und holt von einer bestimmten Stelle im Speicher die Adresse des Trap-Handlers (Prozedur), mit der dann der Programmcounter überschrieben wird. Wesentliches Merkmal eines Traps ist, daß es durch Ausnahmebedingungen ausgelöst wird, welche durch Hardware oder Mikroprogramme erkannt werden. Wie arbeiten Interrupts Interrupts sind Unterbrechungen der Ablaufsteuerung. Wie es für Traps Trap-Handler gibt, gibt es für Interrupts Interrupt-Handler. Nach Abarbeitung des Interrupt-Handlers wird die Kontrolle wieder an das Programm zurückgegeben. Der interne Zustand des Prozessors (IP, Register, ...) muss nun exakt wiederhergestellt werden. Der Unterschied zwischen Traps und Interrupts ist nun, daß Traps synchron mit dem ausgeführten Programm laufen. Deshalb werden sie auch erst nach der Befehlsausführung erkannt und ausgeführt. Asynchrone Interrupts sind dagegen unabhängig vom gerade ausgeführten Programm. Interrupt’s stammen von echten physikalischen INT-Quellen wie z.B. IRQ3 von COM1 kommt. Diese springen über ein Interrupt-Gate. Interrupt’s die per Software mit INT-Befehl ausgelöst werden, springen über Trap-Gates! Wenn ein Interrupt ein Interrupt-Gate durchläuft, wird das IF=0 automatisch gesetzt, d.h. es gehen überhaupt keine Interrupts mehr durch. Asynchrone Interrupts können also nicht unterbrochen werden. Trap-Gates dürfen unterbrochen werden, da sie nicht zeitkritisch sind. Interrupt- und Trap-Gates führen nicht zu Taskwechsel über ein TSS. Das retten der Register ist dem INT-Handler überlassen. Was sind Software Interrupts? Software-Interrupts werden von Programmen mit Hilfe von speziellen Maschinenbefehlen aufgerufen. Dabei müssen diese nur eine Nummer für das benötigte Interrupt kennen. Über diese Nummer wird in der Interrupt-Vektor-Tabelle die Adresse des Interrupt-Unterprogrammes (ISR) referenziert und ausgeführt. Was versteht man unter internen und externen Interrupts? Externe Interrupts sind asynchron, wie nichtvektorisierte und vektorisierte Interrupts. Interne sind synchron, wie Software Interrupts oder Exection-Traps (Reaktionen auf interne Fehler wie FPU-Errors oder Page-Faults). Was ist Polling? Polling ist das zyklische Abfragen von einen oder mehreren E/A-Devices zur Feststellung der Kommunikationsbereitschaft bzw. zum Einholen von Kommunikationswünschen. Vorteile des Pollings Nachteile des Pollings Einfach zu Implementieren Hoher Programm-Overhead Kommunikationsanforderungen erfolgen synchron zum Programmablauf Die meisten Anfragen an die Geräte sind unnötig Je mehr Geräte am Bus hängen, um so mehr steigt Reaktionszeit. Priorisierung bei zeitgleichen Anfragen erfordert zusätzlichen Zeitaufwand Aufgrund der vielen Nachteile sollte besser eine asynchrone Kommunikation mit den Geräten durch die Hardware unterstützt werden (Interrupts). Das Interrupt-Prinzip Es kann auch über eine Art "hardware-gestütztes Polling" über spezielle Interrupt-Signalleitungen eine Kommunikationsanforderung festgestellt werden. Dazu muss aber die Befehlsverarbeitungschleife um eine Unterbrechungsanfrage erweitert werden. Erklären Sie den Unterschied zwischen vektorisierten und nichtvektorisierten Interrupts! Man unterscheidet vektorisierten und nichtvektorisierten Interrupt. Bei nichtvektorisierten Interrupts wird dem Interruptsignal eine feste Adresse zugeordnet. Bei vektorisierten Interrupts wird dynamisch eine wahlfreie Adresse zugeordnet, welche durch die CPU über ein definiertes Protokoll vom Datenbus gelesen wird. Was passiert beim Auftreten eines Interrupts? 1. Sperren weiterer Unterbrechungen mit gleicher oder geringerer Priotität Unterbrechungen mit höherer Wichtigkeit dürfen normalerweise solche mit geringerer Wichtigkeit wieder unterbrechen 2. Rettung wichtiger Register-Informationen(Prozessorstatus) alle Prozessor-Register retten, die durch die Interruptbehandlung überschrieben würden heute gibt es dafür spezielle Maschinenbefehle 3. Bestimmen der Interruptquelle (durch Hardware realisiert) 4. Laden des zugehörigen Interruptvektors d.h. das Herstellen des Anfangszustandes für gewählte Interruptroutine 5. Abarbeitung der Interruptroutine Retten weiterer Zustandsinformationen, sofern nicht durch Hardware realisiert meistens Übernahme weiterer Parameter von definierten Stellen (bei Systemaufruf Ruf-Nr. und weitere Parameter oder bei Geräte-Interrupt Gerätestatusbits wie E/A Fortschritt, Fehler etc.) eigentliche Behandlung des Interrupts, z.B. Setzen eines Flags (z.B. bei Gleitkommaüberlauf oder Aufruf zum Rückpositionieren und erneutem Lesen bei Lesefehler bei Magnetbandkassette (komplizierterer Fall) 6. Rückkehr zur unterbrochenen Aufgabe entweder Rückspeichern der geretteten Registerinformationen, d.h. Wiederherstellen des Prozessorzustandes oder Bearbeitung einer neuen Aufgabe, z.B. bei Uhrinterrupt nach Ablauf einer Zeitscheibe oder Zustand "HALT" nach schwerem Fehler, z.B. Spannungsausfall (abort) Welche beiden Zustandssicherungskonzepte gibt es totale Sicherung aller bislang nicht automatisch gesicherten Register der CPU-Status des unterbrochenen Programms wird komplett eingefroren auch die invarianten Anteile werden gesichert, der Programmzustand ist damit leicht zugreifbar weit verbreitet bei Allzweckbetriebssystemen (z.B. UNIX & Co.) partielle Sicherung der im weiteren Verlauf nicht gesicherten Register der CPU-Status des unterbrochenen Programms wird teilweise eingefroren es wird nur der wirklich von Änderungen betroffene Anteil gesichert der Programmzustand ist damit nicht leicht zugreifbar weit verbreitet bei Spezialzweckbetriebssystemen Was stellt das Hauptproblem bei Interrupts dar Interrupts verhalten sich nicht deterministisch. D.h. ihre Abarbeitungszeit variiert. Sie sollte trotzdem so gering wie möglich gehalten werden. Warum wird DMA oft Interrupts vorgezogen? Zwar befreien Interrupts die Prozessoren vom Warten auf E/A Ereignisse, aber vektorisierte Interrupts benötigen viele Taktzyklen zu ihrer Abarbeitung. Dieser Overhead steigt natürlich, um so weniger Datenmengen bei einer Interruptauslösung übertragen werden. Interrupts werden erst nach der Befehlsabarbeitung erkannt und ausgeführt. Dies ist ein Problem bei Echtzeitanwendungen, da sich diese Verzögerung negativ auswirken kann. Außerdem kommt es durch Interrupts bei Instruction-Set-Parallismus oft zu Pipeline-Neustarts. Die Lösung dieser Probleme wäre ein direkter Speicherzugriff eines Devices, da so der Prozessor komplett umgangen werden kann. Wie kann DMA implementiert werden? Zentral Ein zentraler DMA-Controller steht allen Geräten zu Verfügung. Dezentral: Jede E/A-Einheit hat ihren eigenen DMA-Controller implementiert und kann selbst Busmaster werden Probleme bei DMA treten vor allem durch ihre Unabhängigkeit und die dadurch notwendigen Schutzmaßnahmen auf. Ein DMA-Controller wirkt wie ein weiterer Prozessor am Bus. Um Inkonsistenzen im Speicher zu vermeiden, muss ein DMA-Controller eng mit dem Speichermanagment des Systems zusammenarbeiten. Was ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adr
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itrap-Gates dürfen unterbrochen werden, da sie nicht zeitkritisch sind. Interrupt- und Trap-Gates führen nicht zu Taskwechsel über ein TSS. Das retten der Register ist dem INT-Handler überlassen. <span>Was sind Software Interrupts? Software-Interrupts werden von Programmen mit Hilfe von speziellen Maschinenbefehlen aufgerufen. Dabei müssen diese nur eine Nummer für das benötigte Interrupt kennen. Über diese Nummer wird in der Interrupt-Vektor-Tabelle die Adresse des Interrupt-Unterprogrammes (ISR) referenziert und ausgeführt. Was versteht man unter internen und externen Interrupts? Externe Interrupts sind asynchron, wie nichtvektorisierte und vektorisierte Interrupts. Interne sind synchron, wie Software Inte
Original toplevel document
Grundprinzipien der Rechnerarchitekturrt das Big-Endian-Format. Falls Worte so in den Speicher passen, das keine Verschiebungen auftreten, heißt der Speicher aligned. Prüfen kann man dies durch die Formel Adresse mod Wortlänge = 0? <span>Kapitel 2 - Interrupts und DMA Klassifizieren Sie die verschiedenen Unterbrechungen! Wenn in der Literatur von Interrupts gesprochen wird, so werden oft externe, asynchrone Interrupts gemeint, welche meistens in Zusammenhang mit E/A-Geräten auftreten. Wie arbeiten Traps (Fangstellen?) Traps sind eine Art automatische Prozeduraufrufe, welche durch eine vom Programm verursachte Bedingung eingeleitet werden. Solch eine Bedingung kann z.B. Gleitkommaüberlauf, Schutzverletzung oder Stapelüberlauf. Findet ein Überlauf statt, so stoppt die Ablaufsteuerung die Ausführung und holt von einer bestimmten Stelle im Speicher die Adresse des Trap-Handlers (Prozedur), mit der dann der Programmcounter überschrieben wird. Wesentliches Merkmal eines Traps ist, daß es durch Ausnahmebedingungen ausgelöst wird, welche durch Hardware oder Mikroprogramme erkannt werden. Wie arbeiten Interrupts Interrupts sind Unterbrechungen der Ablaufsteuerung. Wie es für Traps Trap-Handler gibt, gibt es für Interrupts Interrupt-Handler. Nach Abarbeitung des Interrupt-Handlers wird die Kontrolle wieder an das Programm zurückgegeben. Der interne Zustand des Prozessors (IP, Register, ...) muss nun exakt wiederhergestellt werden. Der Unterschied zwischen Traps und Interrupts ist nun, daß Traps synchron mit dem ausgeführten Programm laufen. Deshalb werden sie auch erst nach der Befehlsausführung erkannt und ausgeführt. Asynchrone Interrupts sind dagegen unabhängig vom gerade ausgeführten Programm. Interrupt’s stammen von echten physikalischen INT-Quellen wie z.B. IRQ3 von COM1 kommt. Diese springen über ein Interrupt-Gate. Interrupt’s die per Software mit INT-Befehl ausgelöst werden, springen über Trap-Gates! Wenn ein Interrupt ein Interrupt-Gate durchläuft, wird das IF=0 automatisch gesetzt, d.h. es gehen überhaupt keine Interrupts mehr durch. Asynchrone Interrupts können also nicht unterbrochen werden. Trap-Gates dürfen unterbrochen werden, da sie nicht zeitkritisch sind. Interrupt- und Trap-Gates führen nicht zu Taskwechsel über ein TSS. Das retten der Register ist dem INT-Handler überlassen. Was sind Software Interrupts? Software-Interrupts werden von Programmen mit Hilfe von speziellen Maschinenbefehlen aufgerufen. Dabei müssen diese nur eine Nummer für das benötigte Interrupt kennen. Über diese Nummer wird in der Interrupt-Vektor-Tabelle die Adresse des Interrupt-Unterprogrammes (ISR) referenziert und ausgeführt. Was versteht man unter internen und externen Interrupts? Externe Interrupts sind asynchron, wie nichtvektorisierte und vektorisierte Interrupts. Interne sind synchron, wie Software Interrupts oder Exection-Traps (Reaktionen auf interne Fehler wie FPU-Errors oder Page-Faults). Was ist Polling? Polling ist das zyklische Abfragen von einen oder mehreren E/A-Devices zur Feststellung der Kommunikationsbereitschaft bzw. zum Einholen von Kommunikationswünschen. Vorteile des Pollings Nachteile des Pollings Einfach zu Implementieren Hoher Programm-Overhead Kommunikationsanforderungen erfolgen synchron zum Programmablauf Die meisten Anfragen an die Geräte sind unnötig Je mehr Geräte am Bus hängen, um so mehr steigt Reaktionszeit. Priorisierung bei zeitgleichen Anfragen erfordert zusätzlichen Zeitaufwand Aufgrund der vielen Nachteile sollte besser eine asynchrone Kommunikation mit den Geräten durch die Hardware unterstützt werden (Interrupts). Das Interrupt-Prinzip Es kann auch über eine Art "hardware-gestütztes Polling" über spezielle Interrupt-Signalleitungen eine Kommunikationsanforderung festgestellt werden. Dazu muss aber die Befehlsverarbeitungschleife um eine Unterbrechungsanfrage erweitert werden. Erklären Sie den Unterschied zwischen vektorisierten und nichtvektorisierten Interrupts! Man unterscheidet vektorisierten und nichtvektorisierten Interrupt. Bei nichtvektorisierten Interrupts wird dem Interruptsignal eine feste Adresse zugeordnet. Bei vektorisierten Interrupts wird dynamisch eine wahlfreie Adresse zugeordnet, welche durch die CPU über ein definiertes Protokoll vom Datenbus gelesen wird. Was passiert beim Auftreten eines Interrupts? 1. Sperren weiterer Unterbrechungen mit gleicher oder geringerer Priotität Unterbrechungen mit höherer Wichtigkeit dürfen normalerweise solche mit geringerer Wichtigkeit wieder unterbrechen 2. Rettung wichtiger Register-Informationen(Prozessorstatus) alle Prozessor-Register retten, die durch die Interruptbehandlung überschrieben würden heute gibt es dafür spezielle Maschinenbefehle 3. Bestimmen der Interruptquelle (durch Hardware realisiert) 4. Laden des zugehörigen Interruptvektors d.h. das Herstellen des Anfangszustandes für gewählte Interruptroutine 5. Abarbeitung der Interruptroutine Retten weiterer Zustandsinformationen, sofern nicht durch Hardware realisiert meistens Übernahme weiterer Parameter von definierten Stellen (bei Systemaufruf Ruf-Nr. und weitere Parameter oder bei Geräte-Interrupt Gerätestatusbits wie E/A Fortschritt, Fehler etc.) eigentliche Behandlung des Interrupts, z.B. Setzen eines Flags (z.B. bei Gleitkommaüberlauf oder Aufruf zum Rückpositionieren und erneutem Lesen bei Lesefehler bei Magnetbandkassette (komplizierterer Fall) 6. Rückkehr zur unterbrochenen Aufgabe entweder Rückspeichern der geretteten Registerinformationen, d.h. Wiederherstellen des Prozessorzustandes oder Bearbeitung einer neuen Aufgabe, z.B. bei Uhrinterrupt nach Ablauf einer Zeitscheibe oder Zustand "HALT" nach schwerem Fehler, z.B. Spannungsausfall (abort) Welche beiden Zustandssicherungskonzepte gibt es totale Sicherung aller bislang nicht automatisch gesicherten Register der CPU-Status des unterbrochenen Programms wird komplett eingefroren auch die invarianten Anteile werden gesichert, der Programmzustand ist damit leicht zugreifbar weit verbreitet bei Allzweckbetriebssystemen (z.B. UNIX & Co.) partielle Sicherung der im weiteren Verlauf nicht gesicherten Register der CPU-Status des unterbrochenen Programms wird teilweise eingefroren es wird nur der wirklich von Änderungen betroffene Anteil gesichert der Programmzustand ist damit nicht leicht zugreifbar weit verbreitet bei Spezialzweckbetriebssystemen Was stellt das Hauptproblem bei Interrupts dar Interrupts verhalten sich nicht deterministisch. D.h. ihre Abarbeitungszeit variiert. Sie sollte trotzdem so gering wie möglich gehalten werden. Warum wird DMA oft Interrupts vorgezogen? Zwar befreien Interrupts die Prozessoren vom Warten auf E/A Ereignisse, aber vektorisierte Interrupts benötigen viele Taktzyklen zu ihrer Abarbeitung. Dieser Overhead steigt natürlich, um so weniger Datenmengen bei einer Interruptauslösung übertragen werden. Interrupts werden erst nach der Befehlsabarbeitung erkannt und ausgeführt. Dies ist ein Problem bei Echtzeitanwendungen, da sich diese Verzögerung negativ auswirken kann. Außerdem kommt es durch Interrupts bei Instruction-Set-Parallismus oft zu Pipeline-Neustarts. Die Lösung dieser Probleme wäre ein direkter Speicherzugriff eines Devices, da so der Prozessor komplett umgangen werden kann. Wie kann DMA implementiert werden? Zentral Ein zentraler DMA-Controller steht allen Geräten zu Verfügung. Dezentral: Jede E/A-Einheit hat ihren eigenen DMA-Controller implementiert und kann selbst Busmaster werden Probleme bei DMA treten vor allem durch ihre Unabhängigkeit und die dadurch notwendigen Schutzmaßnahmen auf. Ein DMA-Controller wirkt wie ein weiterer Prozessor am Bus. Um Inkonsistenzen im Speicher zu vermeiden, muss ein DMA-Controller eng mit dem Speichermanagment des Systems zusammenarbeiten. Was ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adr
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itynchron, wie nichtvektorisierte und vektorisierte Interrupts. Interne sind synchron, wie Software Interrupts oder Exection-Traps (Reaktionen auf interne Fehler wie FPU-Errors oder Page-Faults). <span>Was ist Polling? Polling ist das zyklische Abfragen von einen oder mehreren E/A-Devices zur Feststellung der Kommunikationsbereitschaft bzw. zum Einholen von Kommunikationswünschen. Vorteile des Pollings Nachteile des Pollings Einfach zu Implementieren Hoher Programm-Overhead Kommunikationsanforderungen erfolgen synchron zum Programmablauf Die meisten Anfragen an die Geräte sind unnötig Je mehr Geräte am Bus hängen, um so mehr steigt Reaktionszeit. Priorisierung bei zeitgleichen Anfragen erfordert zusätzlichen Zeitaufwand Aufgrund der vielen Nachteile sollte besser eine asynchrone Kommunikation mit den Geräten durch die Hardware unterstützt werden (Interrupts). Das Interrupt-Prinzip Es kann auch über eine Art "hardware-gestütztes Polling" über spezielle Interrupt-Signalleitungen eine Kommunikationsanforderung festgestellt werden. Dazu muss abe
Original toplevel document
Grundprinzipien der Rechnerarchitekturrt das Big-Endian-Format. Falls Worte so in den Speicher passen, das keine Verschiebungen auftreten, heißt der Speicher aligned. Prüfen kann man dies durch die Formel Adresse mod Wortlänge = 0? <span>Kapitel 2 - Interrupts und DMA Klassifizieren Sie die verschiedenen Unterbrechungen! Wenn in der Literatur von Interrupts gesprochen wird, so werden oft externe, asynchrone Interrupts gemeint, welche meistens in Zusammenhang mit E/A-Geräten auftreten. Wie arbeiten Traps (Fangstellen?) Traps sind eine Art automatische Prozeduraufrufe, welche durch eine vom Programm verursachte Bedingung eingeleitet werden. Solch eine Bedingung kann z.B. Gleitkommaüberlauf, Schutzverletzung oder Stapelüberlauf. Findet ein Überlauf statt, so stoppt die Ablaufsteuerung die Ausführung und holt von einer bestimmten Stelle im Speicher die Adresse des Trap-Handlers (Prozedur), mit der dann der Programmcounter überschrieben wird. Wesentliches Merkmal eines Traps ist, daß es durch Ausnahmebedingungen ausgelöst wird, welche durch Hardware oder Mikroprogramme erkannt werden. Wie arbeiten Interrupts Interrupts sind Unterbrechungen der Ablaufsteuerung. Wie es für Traps Trap-Handler gibt, gibt es für Interrupts Interrupt-Handler. Nach Abarbeitung des Interrupt-Handlers wird die Kontrolle wieder an das Programm zurückgegeben. Der interne Zustand des Prozessors (IP, Register, ...) muss nun exakt wiederhergestellt werden. Der Unterschied zwischen Traps und Interrupts ist nun, daß Traps synchron mit dem ausgeführten Programm laufen. Deshalb werden sie auch erst nach der Befehlsausführung erkannt und ausgeführt. Asynchrone Interrupts sind dagegen unabhängig vom gerade ausgeführten Programm. Interrupt’s stammen von echten physikalischen INT-Quellen wie z.B. IRQ3 von COM1 kommt. Diese springen über ein Interrupt-Gate. Interrupt’s die per Software mit INT-Befehl ausgelöst werden, springen über Trap-Gates! Wenn ein Interrupt ein Interrupt-Gate durchläuft, wird das IF=0 automatisch gesetzt, d.h. es gehen überhaupt keine Interrupts mehr durch. Asynchrone Interrupts können also nicht unterbrochen werden. Trap-Gates dürfen unterbrochen werden, da sie nicht zeitkritisch sind. Interrupt- und Trap-Gates führen nicht zu Taskwechsel über ein TSS. Das retten der Register ist dem INT-Handler überlassen. Was sind Software Interrupts? Software-Interrupts werden von Programmen mit Hilfe von speziellen Maschinenbefehlen aufgerufen. Dabei müssen diese nur eine Nummer für das benötigte Interrupt kennen. Über diese Nummer wird in der Interrupt-Vektor-Tabelle die Adresse des Interrupt-Unterprogrammes (ISR) referenziert und ausgeführt. Was versteht man unter internen und externen Interrupts? Externe Interrupts sind asynchron, wie nichtvektorisierte und vektorisierte Interrupts. Interne sind synchron, wie Software Interrupts oder Exection-Traps (Reaktionen auf interne Fehler wie FPU-Errors oder Page-Faults). Was ist Polling? Polling ist das zyklische Abfragen von einen oder mehreren E/A-Devices zur Feststellung der Kommunikationsbereitschaft bzw. zum Einholen von Kommunikationswünschen. Vorteile des Pollings Nachteile des Pollings Einfach zu Implementieren Hoher Programm-Overhead Kommunikationsanforderungen erfolgen synchron zum Programmablauf Die meisten Anfragen an die Geräte sind unnötig Je mehr Geräte am Bus hängen, um so mehr steigt Reaktionszeit. Priorisierung bei zeitgleichen Anfragen erfordert zusätzlichen Zeitaufwand Aufgrund der vielen Nachteile sollte besser eine asynchrone Kommunikation mit den Geräten durch die Hardware unterstützt werden (Interrupts). Das Interrupt-Prinzip Es kann auch über eine Art "hardware-gestütztes Polling" über spezielle Interrupt-Signalleitungen eine Kommunikationsanforderung festgestellt werden. Dazu muss aber die Befehlsverarbeitungschleife um eine Unterbrechungsanfrage erweitert werden. Erklären Sie den Unterschied zwischen vektorisierten und nichtvektorisierten Interrupts! Man unterscheidet vektorisierten und nichtvektorisierten Interrupt. Bei nichtvektorisierten Interrupts wird dem Interruptsignal eine feste Adresse zugeordnet. Bei vektorisierten Interrupts wird dynamisch eine wahlfreie Adresse zugeordnet, welche durch die CPU über ein definiertes Protokoll vom Datenbus gelesen wird. Was passiert beim Auftreten eines Interrupts? 1. Sperren weiterer Unterbrechungen mit gleicher oder geringerer Priotität Unterbrechungen mit höherer Wichtigkeit dürfen normalerweise solche mit geringerer Wichtigkeit wieder unterbrechen 2. Rettung wichtiger Register-Informationen(Prozessorstatus) alle Prozessor-Register retten, die durch die Interruptbehandlung überschrieben würden heute gibt es dafür spezielle Maschinenbefehle 3. Bestimmen der Interruptquelle (durch Hardware realisiert) 4. Laden des zugehörigen Interruptvektors d.h. das Herstellen des Anfangszustandes für gewählte Interruptroutine 5. Abarbeitung der Interruptroutine Retten weiterer Zustandsinformationen, sofern nicht durch Hardware realisiert meistens Übernahme weiterer Parameter von definierten Stellen (bei Systemaufruf Ruf-Nr. und weitere Parameter oder bei Geräte-Interrupt Gerätestatusbits wie E/A Fortschritt, Fehler etc.) eigentliche Behandlung des Interrupts, z.B. Setzen eines Flags (z.B. bei Gleitkommaüberlauf oder Aufruf zum Rückpositionieren und erneutem Lesen bei Lesefehler bei Magnetbandkassette (komplizierterer Fall) 6. Rückkehr zur unterbrochenen Aufgabe entweder Rückspeichern der geretteten Registerinformationen, d.h. Wiederherstellen des Prozessorzustandes oder Bearbeitung einer neuen Aufgabe, z.B. bei Uhrinterrupt nach Ablauf einer Zeitscheibe oder Zustand "HALT" nach schwerem Fehler, z.B. Spannungsausfall (abort) Welche beiden Zustandssicherungskonzepte gibt es totale Sicherung aller bislang nicht automatisch gesicherten Register der CPU-Status des unterbrochenen Programms wird komplett eingefroren auch die invarianten Anteile werden gesichert, der Programmzustand ist damit leicht zugreifbar weit verbreitet bei Allzweckbetriebssystemen (z.B. UNIX & Co.) partielle Sicherung der im weiteren Verlauf nicht gesicherten Register der CPU-Status des unterbrochenen Programms wird teilweise eingefroren es wird nur der wirklich von Änderungen betroffene Anteil gesichert der Programmzustand ist damit nicht leicht zugreifbar weit verbreitet bei Spezialzweckbetriebssystemen Was stellt das Hauptproblem bei Interrupts dar Interrupts verhalten sich nicht deterministisch. D.h. ihre Abarbeitungszeit variiert. Sie sollte trotzdem so gering wie möglich gehalten werden. Warum wird DMA oft Interrupts vorgezogen? Zwar befreien Interrupts die Prozessoren vom Warten auf E/A Ereignisse, aber vektorisierte Interrupts benötigen viele Taktzyklen zu ihrer Abarbeitung. Dieser Overhead steigt natürlich, um so weniger Datenmengen bei einer Interruptauslösung übertragen werden. Interrupts werden erst nach der Befehlsabarbeitung erkannt und ausgeführt. Dies ist ein Problem bei Echtzeitanwendungen, da sich diese Verzögerung negativ auswirken kann. Außerdem kommt es durch Interrupts bei Instruction-Set-Parallismus oft zu Pipeline-Neustarts. Die Lösung dieser Probleme wäre ein direkter Speicherzugriff eines Devices, da so der Prozessor komplett umgangen werden kann. Wie kann DMA implementiert werden? Zentral Ein zentraler DMA-Controller steht allen Geräten zu Verfügung. Dezentral: Jede E/A-Einheit hat ihren eigenen DMA-Controller implementiert und kann selbst Busmaster werden Probleme bei DMA treten vor allem durch ihre Unabhängigkeit und die dadurch notwendigen Schutzmaßnahmen auf. Ein DMA-Controller wirkt wie ein weiterer Prozessor am Bus. Um Inkonsistenzen im Speicher zu vermeiden, muss ein DMA-Controller eng mit dem Speichermanagment des Systems zusammenarbeiten. Was ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adr
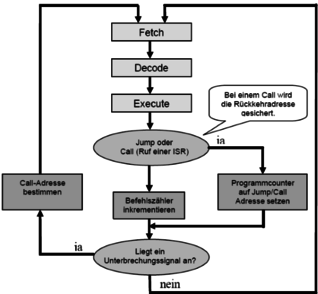
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itleichen Anfragen erfordert zusätzlichen Zeitaufwand Aufgrund der vielen Nachteile sollte besser eine asynchrone Kommunikation mit den Geräten durch die Hardware unterstützt werden (Interrupts). <span>Das Interrupt-Prinzip Es kann auch über eine Art "hardware-gestütztes Polling" über spezielle Interrupt-Signalleitungen eine Kommunikationsanforderung festgestellt werden. Dazu muss aber die Befehlsverarbeitungschleife um eine Unterbrechungsanfrage erweitert werden. Erklären Sie den Unterschied zwischen vektorisierten und nichtvektorisierten Interrupts! Man unterscheidet vektorisierten und nichtvektorisierten Interrupt. Bei nichtvektorisierten Inte
Original toplevel document
Grundprinzipien der Rechnerarchitekturrt das Big-Endian-Format. Falls Worte so in den Speicher passen, das keine Verschiebungen auftreten, heißt der Speicher aligned. Prüfen kann man dies durch die Formel Adresse mod Wortlänge = 0? <span>Kapitel 2 - Interrupts und DMA Klassifizieren Sie die verschiedenen Unterbrechungen! Wenn in der Literatur von Interrupts gesprochen wird, so werden oft externe, asynchrone Interrupts gemeint, welche meistens in Zusammenhang mit E/A-Geräten auftreten. Wie arbeiten Traps (Fangstellen?) Traps sind eine Art automatische Prozeduraufrufe, welche durch eine vom Programm verursachte Bedingung eingeleitet werden. Solch eine Bedingung kann z.B. Gleitkommaüberlauf, Schutzverletzung oder Stapelüberlauf. Findet ein Überlauf statt, so stoppt die Ablaufsteuerung die Ausführung und holt von einer bestimmten Stelle im Speicher die Adresse des Trap-Handlers (Prozedur), mit der dann der Programmcounter überschrieben wird. Wesentliches Merkmal eines Traps ist, daß es durch Ausnahmebedingungen ausgelöst wird, welche durch Hardware oder Mikroprogramme erkannt werden. Wie arbeiten Interrupts Interrupts sind Unterbrechungen der Ablaufsteuerung. Wie es für Traps Trap-Handler gibt, gibt es für Interrupts Interrupt-Handler. Nach Abarbeitung des Interrupt-Handlers wird die Kontrolle wieder an das Programm zurückgegeben. Der interne Zustand des Prozessors (IP, Register, ...) muss nun exakt wiederhergestellt werden. Der Unterschied zwischen Traps und Interrupts ist nun, daß Traps synchron mit dem ausgeführten Programm laufen. Deshalb werden sie auch erst nach der Befehlsausführung erkannt und ausgeführt. Asynchrone Interrupts sind dagegen unabhängig vom gerade ausgeführten Programm. Interrupt’s stammen von echten physikalischen INT-Quellen wie z.B. IRQ3 von COM1 kommt. Diese springen über ein Interrupt-Gate. Interrupt’s die per Software mit INT-Befehl ausgelöst werden, springen über Trap-Gates! Wenn ein Interrupt ein Interrupt-Gate durchläuft, wird das IF=0 automatisch gesetzt, d.h. es gehen überhaupt keine Interrupts mehr durch. Asynchrone Interrupts können also nicht unterbrochen werden. Trap-Gates dürfen unterbrochen werden, da sie nicht zeitkritisch sind. Interrupt- und Trap-Gates führen nicht zu Taskwechsel über ein TSS. Das retten der Register ist dem INT-Handler überlassen. Was sind Software Interrupts? Software-Interrupts werden von Programmen mit Hilfe von speziellen Maschinenbefehlen aufgerufen. Dabei müssen diese nur eine Nummer für das benötigte Interrupt kennen. Über diese Nummer wird in der Interrupt-Vektor-Tabelle die Adresse des Interrupt-Unterprogrammes (ISR) referenziert und ausgeführt. Was versteht man unter internen und externen Interrupts? Externe Interrupts sind asynchron, wie nichtvektorisierte und vektorisierte Interrupts. Interne sind synchron, wie Software Interrupts oder Exection-Traps (Reaktionen auf interne Fehler wie FPU-Errors oder Page-Faults). Was ist Polling? Polling ist das zyklische Abfragen von einen oder mehreren E/A-Devices zur Feststellung der Kommunikationsbereitschaft bzw. zum Einholen von Kommunikationswünschen. Vorteile des Pollings Nachteile des Pollings Einfach zu Implementieren Hoher Programm-Overhead Kommunikationsanforderungen erfolgen synchron zum Programmablauf Die meisten Anfragen an die Geräte sind unnötig Je mehr Geräte am Bus hängen, um so mehr steigt Reaktionszeit. Priorisierung bei zeitgleichen Anfragen erfordert zusätzlichen Zeitaufwand Aufgrund der vielen Nachteile sollte besser eine asynchrone Kommunikation mit den Geräten durch die Hardware unterstützt werden (Interrupts). Das Interrupt-Prinzip Es kann auch über eine Art "hardware-gestütztes Polling" über spezielle Interrupt-Signalleitungen eine Kommunikationsanforderung festgestellt werden. Dazu muss aber die Befehlsverarbeitungschleife um eine Unterbrechungsanfrage erweitert werden. Erklären Sie den Unterschied zwischen vektorisierten und nichtvektorisierten Interrupts! Man unterscheidet vektorisierten und nichtvektorisierten Interrupt. Bei nichtvektorisierten Interrupts wird dem Interruptsignal eine feste Adresse zugeordnet. Bei vektorisierten Interrupts wird dynamisch eine wahlfreie Adresse zugeordnet, welche durch die CPU über ein definiertes Protokoll vom Datenbus gelesen wird. Was passiert beim Auftreten eines Interrupts? 1. Sperren weiterer Unterbrechungen mit gleicher oder geringerer Priotität Unterbrechungen mit höherer Wichtigkeit dürfen normalerweise solche mit geringerer Wichtigkeit wieder unterbrechen 2. Rettung wichtiger Register-Informationen(Prozessorstatus) alle Prozessor-Register retten, die durch die Interruptbehandlung überschrieben würden heute gibt es dafür spezielle Maschinenbefehle 3. Bestimmen der Interruptquelle (durch Hardware realisiert) 4. Laden des zugehörigen Interruptvektors d.h. das Herstellen des Anfangszustandes für gewählte Interruptroutine 5. Abarbeitung der Interruptroutine Retten weiterer Zustandsinformationen, sofern nicht durch Hardware realisiert meistens Übernahme weiterer Parameter von definierten Stellen (bei Systemaufruf Ruf-Nr. und weitere Parameter oder bei Geräte-Interrupt Gerätestatusbits wie E/A Fortschritt, Fehler etc.) eigentliche Behandlung des Interrupts, z.B. Setzen eines Flags (z.B. bei Gleitkommaüberlauf oder Aufruf zum Rückpositionieren und erneutem Lesen bei Lesefehler bei Magnetbandkassette (komplizierterer Fall) 6. Rückkehr zur unterbrochenen Aufgabe entweder Rückspeichern der geretteten Registerinformationen, d.h. Wiederherstellen des Prozessorzustandes oder Bearbeitung einer neuen Aufgabe, z.B. bei Uhrinterrupt nach Ablauf einer Zeitscheibe oder Zustand "HALT" nach schwerem Fehler, z.B. Spannungsausfall (abort) Welche beiden Zustandssicherungskonzepte gibt es totale Sicherung aller bislang nicht automatisch gesicherten Register der CPU-Status des unterbrochenen Programms wird komplett eingefroren auch die invarianten Anteile werden gesichert, der Programmzustand ist damit leicht zugreifbar weit verbreitet bei Allzweckbetriebssystemen (z.B. UNIX & Co.) partielle Sicherung der im weiteren Verlauf nicht gesicherten Register der CPU-Status des unterbrochenen Programms wird teilweise eingefroren es wird nur der wirklich von Änderungen betroffene Anteil gesichert der Programmzustand ist damit nicht leicht zugreifbar weit verbreitet bei Spezialzweckbetriebssystemen Was stellt das Hauptproblem bei Interrupts dar Interrupts verhalten sich nicht deterministisch. D.h. ihre Abarbeitungszeit variiert. Sie sollte trotzdem so gering wie möglich gehalten werden. Warum wird DMA oft Interrupts vorgezogen? Zwar befreien Interrupts die Prozessoren vom Warten auf E/A Ereignisse, aber vektorisierte Interrupts benötigen viele Taktzyklen zu ihrer Abarbeitung. Dieser Overhead steigt natürlich, um so weniger Datenmengen bei einer Interruptauslösung übertragen werden. Interrupts werden erst nach der Befehlsabarbeitung erkannt und ausgeführt. Dies ist ein Problem bei Echtzeitanwendungen, da sich diese Verzögerung negativ auswirken kann. Außerdem kommt es durch Interrupts bei Instruction-Set-Parallismus oft zu Pipeline-Neustarts. Die Lösung dieser Probleme wäre ein direkter Speicherzugriff eines Devices, da so der Prozessor komplett umgangen werden kann. Wie kann DMA implementiert werden? Zentral Ein zentraler DMA-Controller steht allen Geräten zu Verfügung. Dezentral: Jede E/A-Einheit hat ihren eigenen DMA-Controller implementiert und kann selbst Busmaster werden Probleme bei DMA treten vor allem durch ihre Unabhängigkeit und die dadurch notwendigen Schutzmaßnahmen auf. Ein DMA-Controller wirkt wie ein weiterer Prozessor am Bus. Um Inkonsistenzen im Speicher zu vermeiden, muss ein DMA-Controller eng mit dem Speichermanagment des Systems zusammenarbeiten. Was ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adr
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itling" über spezielle Interrupt-Signalleitungen eine Kommunikationsanforderung festgestellt werden. Dazu muss aber die Befehlsverarbeitungschleife um eine Unterbrechungsanfrage erweitert werden. <span>Erklären Sie den Unterschied zwischen vektorisierten und nichtvektorisierten Interrupts! Man unterscheidet vektorisierten und nichtvektorisierten Interrupt. Bei nichtvektorisierten Interrupts wird dem Interruptsignal eine feste Adresse zugeordnet. Bei vektorisierten Interrupts wird dynamisch eine wahlfreie Adresse zugeordnet, welche durch die CPU über ein definiertes Protokoll vom Datenbus gelesen wird. Was passiert beim Auftreten eines Interrupts? 1. Sperren weiterer Unterbrechungen mit gleicher oder geringerer Priotität Unterbrechungen mit höherer Wichtigkeit dürfen normalerweise sol
Original toplevel document
Grundprinzipien der Rechnerarchitekturrt das Big-Endian-Format. Falls Worte so in den Speicher passen, das keine Verschiebungen auftreten, heißt der Speicher aligned. Prüfen kann man dies durch die Formel Adresse mod Wortlänge = 0? <span>Kapitel 2 - Interrupts und DMA Klassifizieren Sie die verschiedenen Unterbrechungen! Wenn in der Literatur von Interrupts gesprochen wird, so werden oft externe, asynchrone Interrupts gemeint, welche meistens in Zusammenhang mit E/A-Geräten auftreten. Wie arbeiten Traps (Fangstellen?) Traps sind eine Art automatische Prozeduraufrufe, welche durch eine vom Programm verursachte Bedingung eingeleitet werden. Solch eine Bedingung kann z.B. Gleitkommaüberlauf, Schutzverletzung oder Stapelüberlauf. Findet ein Überlauf statt, so stoppt die Ablaufsteuerung die Ausführung und holt von einer bestimmten Stelle im Speicher die Adresse des Trap-Handlers (Prozedur), mit der dann der Programmcounter überschrieben wird. Wesentliches Merkmal eines Traps ist, daß es durch Ausnahmebedingungen ausgelöst wird, welche durch Hardware oder Mikroprogramme erkannt werden. Wie arbeiten Interrupts Interrupts sind Unterbrechungen der Ablaufsteuerung. Wie es für Traps Trap-Handler gibt, gibt es für Interrupts Interrupt-Handler. Nach Abarbeitung des Interrupt-Handlers wird die Kontrolle wieder an das Programm zurückgegeben. Der interne Zustand des Prozessors (IP, Register, ...) muss nun exakt wiederhergestellt werden. Der Unterschied zwischen Traps und Interrupts ist nun, daß Traps synchron mit dem ausgeführten Programm laufen. Deshalb werden sie auch erst nach der Befehlsausführung erkannt und ausgeführt. Asynchrone Interrupts sind dagegen unabhängig vom gerade ausgeführten Programm. Interrupt’s stammen von echten physikalischen INT-Quellen wie z.B. IRQ3 von COM1 kommt. Diese springen über ein Interrupt-Gate. Interrupt’s die per Software mit INT-Befehl ausgelöst werden, springen über Trap-Gates! Wenn ein Interrupt ein Interrupt-Gate durchläuft, wird das IF=0 automatisch gesetzt, d.h. es gehen überhaupt keine Interrupts mehr durch. Asynchrone Interrupts können also nicht unterbrochen werden. Trap-Gates dürfen unterbrochen werden, da sie nicht zeitkritisch sind. Interrupt- und Trap-Gates führen nicht zu Taskwechsel über ein TSS. Das retten der Register ist dem INT-Handler überlassen. Was sind Software Interrupts? Software-Interrupts werden von Programmen mit Hilfe von speziellen Maschinenbefehlen aufgerufen. Dabei müssen diese nur eine Nummer für das benötigte Interrupt kennen. Über diese Nummer wird in der Interrupt-Vektor-Tabelle die Adresse des Interrupt-Unterprogrammes (ISR) referenziert und ausgeführt. Was versteht man unter internen und externen Interrupts? Externe Interrupts sind asynchron, wie nichtvektorisierte und vektorisierte Interrupts. Interne sind synchron, wie Software Interrupts oder Exection-Traps (Reaktionen auf interne Fehler wie FPU-Errors oder Page-Faults). Was ist Polling? Polling ist das zyklische Abfragen von einen oder mehreren E/A-Devices zur Feststellung der Kommunikationsbereitschaft bzw. zum Einholen von Kommunikationswünschen. Vorteile des Pollings Nachteile des Pollings Einfach zu Implementieren Hoher Programm-Overhead Kommunikationsanforderungen erfolgen synchron zum Programmablauf Die meisten Anfragen an die Geräte sind unnötig Je mehr Geräte am Bus hängen, um so mehr steigt Reaktionszeit. Priorisierung bei zeitgleichen Anfragen erfordert zusätzlichen Zeitaufwand Aufgrund der vielen Nachteile sollte besser eine asynchrone Kommunikation mit den Geräten durch die Hardware unterstützt werden (Interrupts). Das Interrupt-Prinzip Es kann auch über eine Art "hardware-gestütztes Polling" über spezielle Interrupt-Signalleitungen eine Kommunikationsanforderung festgestellt werden. Dazu muss aber die Befehlsverarbeitungschleife um eine Unterbrechungsanfrage erweitert werden. Erklären Sie den Unterschied zwischen vektorisierten und nichtvektorisierten Interrupts! Man unterscheidet vektorisierten und nichtvektorisierten Interrupt. Bei nichtvektorisierten Interrupts wird dem Interruptsignal eine feste Adresse zugeordnet. Bei vektorisierten Interrupts wird dynamisch eine wahlfreie Adresse zugeordnet, welche durch die CPU über ein definiertes Protokoll vom Datenbus gelesen wird. Was passiert beim Auftreten eines Interrupts? 1. Sperren weiterer Unterbrechungen mit gleicher oder geringerer Priotität Unterbrechungen mit höherer Wichtigkeit dürfen normalerweise solche mit geringerer Wichtigkeit wieder unterbrechen 2. Rettung wichtiger Register-Informationen(Prozessorstatus) alle Prozessor-Register retten, die durch die Interruptbehandlung überschrieben würden heute gibt es dafür spezielle Maschinenbefehle 3. Bestimmen der Interruptquelle (durch Hardware realisiert) 4. Laden des zugehörigen Interruptvektors d.h. das Herstellen des Anfangszustandes für gewählte Interruptroutine 5. Abarbeitung der Interruptroutine Retten weiterer Zustandsinformationen, sofern nicht durch Hardware realisiert meistens Übernahme weiterer Parameter von definierten Stellen (bei Systemaufruf Ruf-Nr. und weitere Parameter oder bei Geräte-Interrupt Gerätestatusbits wie E/A Fortschritt, Fehler etc.) eigentliche Behandlung des Interrupts, z.B. Setzen eines Flags (z.B. bei Gleitkommaüberlauf oder Aufruf zum Rückpositionieren und erneutem Lesen bei Lesefehler bei Magnetbandkassette (komplizierterer Fall) 6. Rückkehr zur unterbrochenen Aufgabe entweder Rückspeichern der geretteten Registerinformationen, d.h. Wiederherstellen des Prozessorzustandes oder Bearbeitung einer neuen Aufgabe, z.B. bei Uhrinterrupt nach Ablauf einer Zeitscheibe oder Zustand "HALT" nach schwerem Fehler, z.B. Spannungsausfall (abort) Welche beiden Zustandssicherungskonzepte gibt es totale Sicherung aller bislang nicht automatisch gesicherten Register der CPU-Status des unterbrochenen Programms wird komplett eingefroren auch die invarianten Anteile werden gesichert, der Programmzustand ist damit leicht zugreifbar weit verbreitet bei Allzweckbetriebssystemen (z.B. UNIX & Co.) partielle Sicherung der im weiteren Verlauf nicht gesicherten Register der CPU-Status des unterbrochenen Programms wird teilweise eingefroren es wird nur der wirklich von Änderungen betroffene Anteil gesichert der Programmzustand ist damit nicht leicht zugreifbar weit verbreitet bei Spezialzweckbetriebssystemen Was stellt das Hauptproblem bei Interrupts dar Interrupts verhalten sich nicht deterministisch. D.h. ihre Abarbeitungszeit variiert. Sie sollte trotzdem so gering wie möglich gehalten werden. Warum wird DMA oft Interrupts vorgezogen? Zwar befreien Interrupts die Prozessoren vom Warten auf E/A Ereignisse, aber vektorisierte Interrupts benötigen viele Taktzyklen zu ihrer Abarbeitung. Dieser Overhead steigt natürlich, um so weniger Datenmengen bei einer Interruptauslösung übertragen werden. Interrupts werden erst nach der Befehlsabarbeitung erkannt und ausgeführt. Dies ist ein Problem bei Echtzeitanwendungen, da sich diese Verzögerung negativ auswirken kann. Außerdem kommt es durch Interrupts bei Instruction-Set-Parallismus oft zu Pipeline-Neustarts. Die Lösung dieser Probleme wäre ein direkter Speicherzugriff eines Devices, da so der Prozessor komplett umgangen werden kann. Wie kann DMA implementiert werden? Zentral Ein zentraler DMA-Controller steht allen Geräten zu Verfügung. Dezentral: Jede E/A-Einheit hat ihren eigenen DMA-Controller implementiert und kann selbst Busmaster werden Probleme bei DMA treten vor allem durch ihre Unabhängigkeit und die dadurch notwendigen Schutzmaßnahmen auf. Ein DMA-Controller wirkt wie ein weiterer Prozessor am Bus. Um Inkonsistenzen im Speicher zu vermeiden, muss ein DMA-Controller eng mit dem Speichermanagment des Systems zusammenarbeiten. Was ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adr
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itnal eine feste Adresse zugeordnet. Bei vektorisierten Interrupts wird dynamisch eine wahlfreie Adresse zugeordnet, welche durch die CPU über ein definiertes Protokoll vom Datenbus gelesen wird. <span>Was passiert beim Auftreten eines Interrupts? 1. Sperren weiterer Unterbrechungen mit gleicher oder geringerer Priotität Unterbrechungen mit höherer Wichtigkeit dürfen normalerweise solche mit geringerer Wichtigkeit wieder unterbrechen 2. Rettung wichtiger Register-Informationen(Prozessorstatus) alle Prozessor-Register retten, die durch die Interruptbehandlung überschrieben würden heute gibt es dafür spezielle Maschinenbefehle 3. Bestimmen der Interruptquelle (durch Hardware realisiert) 4. Laden des zugehörigen Interruptvektors d.h. das Herstellen des Anfangszustandes für gewählte Interruptroutine 5. Abarbeitung der Interruptroutine Retten weiterer Zustandsinformationen, sofern nicht durch Hardware realisiert meistens Übernahme weiterer Parameter von definierten Stellen (bei Systemaufruf Ruf-Nr. und weitere Parameter oder bei Geräte-Interrupt Gerätestatusbits wie E/A Fortschritt, Fehler etc.) eigentliche Behandlung des Interrupts, z.B. Setzen eines Flags (z.B. bei Gleitkommaüberlauf oder Aufruf zum Rückpositionieren und erneutem Lesen bei Lesefehler bei Magnetbandkassette (komplizierterer Fall) 6. Rückkehr zur unterbrochenen Aufgabe entweder Rückspeichern der geretteten Registerinformationen, d.h. Wiederherstellen des Prozessorzustandes oder Bearbeitung einer neuen Aufgabe, z.B. bei Uhrinterrupt nach Ablauf einer Zeitscheibe oder Zustand "HALT" nach schwerem Fehler, z.B. Spannungsausfall (abort) Welche beiden Zustandssicherungskonzepte gibt es totale Sicherung aller bislang nicht automatisch gesicherten Register der CPU-Status des unterbrochenen Programms wird komplett eingefro
Original toplevel document
Grundprinzipien der Rechnerarchitekturrt das Big-Endian-Format. Falls Worte so in den Speicher passen, das keine Verschiebungen auftreten, heißt der Speicher aligned. Prüfen kann man dies durch die Formel Adresse mod Wortlänge = 0? <span>Kapitel 2 - Interrupts und DMA Klassifizieren Sie die verschiedenen Unterbrechungen! Wenn in der Literatur von Interrupts gesprochen wird, so werden oft externe, asynchrone Interrupts gemeint, welche meistens in Zusammenhang mit E/A-Geräten auftreten. Wie arbeiten Traps (Fangstellen?) Traps sind eine Art automatische Prozeduraufrufe, welche durch eine vom Programm verursachte Bedingung eingeleitet werden. Solch eine Bedingung kann z.B. Gleitkommaüberlauf, Schutzverletzung oder Stapelüberlauf. Findet ein Überlauf statt, so stoppt die Ablaufsteuerung die Ausführung und holt von einer bestimmten Stelle im Speicher die Adresse des Trap-Handlers (Prozedur), mit der dann der Programmcounter überschrieben wird. Wesentliches Merkmal eines Traps ist, daß es durch Ausnahmebedingungen ausgelöst wird, welche durch Hardware oder Mikroprogramme erkannt werden. Wie arbeiten Interrupts Interrupts sind Unterbrechungen der Ablaufsteuerung. Wie es für Traps Trap-Handler gibt, gibt es für Interrupts Interrupt-Handler. Nach Abarbeitung des Interrupt-Handlers wird die Kontrolle wieder an das Programm zurückgegeben. Der interne Zustand des Prozessors (IP, Register, ...) muss nun exakt wiederhergestellt werden. Der Unterschied zwischen Traps und Interrupts ist nun, daß Traps synchron mit dem ausgeführten Programm laufen. Deshalb werden sie auch erst nach der Befehlsausführung erkannt und ausgeführt. Asynchrone Interrupts sind dagegen unabhängig vom gerade ausgeführten Programm. Interrupt’s stammen von echten physikalischen INT-Quellen wie z.B. IRQ3 von COM1 kommt. Diese springen über ein Interrupt-Gate. Interrupt’s die per Software mit INT-Befehl ausgelöst werden, springen über Trap-Gates! Wenn ein Interrupt ein Interrupt-Gate durchläuft, wird das IF=0 automatisch gesetzt, d.h. es gehen überhaupt keine Interrupts mehr durch. Asynchrone Interrupts können also nicht unterbrochen werden. Trap-Gates dürfen unterbrochen werden, da sie nicht zeitkritisch sind. Interrupt- und Trap-Gates führen nicht zu Taskwechsel über ein TSS. Das retten der Register ist dem INT-Handler überlassen. Was sind Software Interrupts? Software-Interrupts werden von Programmen mit Hilfe von speziellen Maschinenbefehlen aufgerufen. Dabei müssen diese nur eine Nummer für das benötigte Interrupt kennen. Über diese Nummer wird in der Interrupt-Vektor-Tabelle die Adresse des Interrupt-Unterprogrammes (ISR) referenziert und ausgeführt. Was versteht man unter internen und externen Interrupts? Externe Interrupts sind asynchron, wie nichtvektorisierte und vektorisierte Interrupts. Interne sind synchron, wie Software Interrupts oder Exection-Traps (Reaktionen auf interne Fehler wie FPU-Errors oder Page-Faults). Was ist Polling? Polling ist das zyklische Abfragen von einen oder mehreren E/A-Devices zur Feststellung der Kommunikationsbereitschaft bzw. zum Einholen von Kommunikationswünschen. Vorteile des Pollings Nachteile des Pollings Einfach zu Implementieren Hoher Programm-Overhead Kommunikationsanforderungen erfolgen synchron zum Programmablauf Die meisten Anfragen an die Geräte sind unnötig Je mehr Geräte am Bus hängen, um so mehr steigt Reaktionszeit. Priorisierung bei zeitgleichen Anfragen erfordert zusätzlichen Zeitaufwand Aufgrund der vielen Nachteile sollte besser eine asynchrone Kommunikation mit den Geräten durch die Hardware unterstützt werden (Interrupts). Das Interrupt-Prinzip Es kann auch über eine Art "hardware-gestütztes Polling" über spezielle Interrupt-Signalleitungen eine Kommunikationsanforderung festgestellt werden. Dazu muss aber die Befehlsverarbeitungschleife um eine Unterbrechungsanfrage erweitert werden. Erklären Sie den Unterschied zwischen vektorisierten und nichtvektorisierten Interrupts! Man unterscheidet vektorisierten und nichtvektorisierten Interrupt. Bei nichtvektorisierten Interrupts wird dem Interruptsignal eine feste Adresse zugeordnet. Bei vektorisierten Interrupts wird dynamisch eine wahlfreie Adresse zugeordnet, welche durch die CPU über ein definiertes Protokoll vom Datenbus gelesen wird. Was passiert beim Auftreten eines Interrupts? 1. Sperren weiterer Unterbrechungen mit gleicher oder geringerer Priotität Unterbrechungen mit höherer Wichtigkeit dürfen normalerweise solche mit geringerer Wichtigkeit wieder unterbrechen 2. Rettung wichtiger Register-Informationen(Prozessorstatus) alle Prozessor-Register retten, die durch die Interruptbehandlung überschrieben würden heute gibt es dafür spezielle Maschinenbefehle 3. Bestimmen der Interruptquelle (durch Hardware realisiert) 4. Laden des zugehörigen Interruptvektors d.h. das Herstellen des Anfangszustandes für gewählte Interruptroutine 5. Abarbeitung der Interruptroutine Retten weiterer Zustandsinformationen, sofern nicht durch Hardware realisiert meistens Übernahme weiterer Parameter von definierten Stellen (bei Systemaufruf Ruf-Nr. und weitere Parameter oder bei Geräte-Interrupt Gerätestatusbits wie E/A Fortschritt, Fehler etc.) eigentliche Behandlung des Interrupts, z.B. Setzen eines Flags (z.B. bei Gleitkommaüberlauf oder Aufruf zum Rückpositionieren und erneutem Lesen bei Lesefehler bei Magnetbandkassette (komplizierterer Fall) 6. Rückkehr zur unterbrochenen Aufgabe entweder Rückspeichern der geretteten Registerinformationen, d.h. Wiederherstellen des Prozessorzustandes oder Bearbeitung einer neuen Aufgabe, z.B. bei Uhrinterrupt nach Ablauf einer Zeitscheibe oder Zustand "HALT" nach schwerem Fehler, z.B. Spannungsausfall (abort) Welche beiden Zustandssicherungskonzepte gibt es totale Sicherung aller bislang nicht automatisch gesicherten Register der CPU-Status des unterbrochenen Programms wird komplett eingefroren auch die invarianten Anteile werden gesichert, der Programmzustand ist damit leicht zugreifbar weit verbreitet bei Allzweckbetriebssystemen (z.B. UNIX & Co.) partielle Sicherung der im weiteren Verlauf nicht gesicherten Register der CPU-Status des unterbrochenen Programms wird teilweise eingefroren es wird nur der wirklich von Änderungen betroffene Anteil gesichert der Programmzustand ist damit nicht leicht zugreifbar weit verbreitet bei Spezialzweckbetriebssystemen Was stellt das Hauptproblem bei Interrupts dar Interrupts verhalten sich nicht deterministisch. D.h. ihre Abarbeitungszeit variiert. Sie sollte trotzdem so gering wie möglich gehalten werden. Warum wird DMA oft Interrupts vorgezogen? Zwar befreien Interrupts die Prozessoren vom Warten auf E/A Ereignisse, aber vektorisierte Interrupts benötigen viele Taktzyklen zu ihrer Abarbeitung. Dieser Overhead steigt natürlich, um so weniger Datenmengen bei einer Interruptauslösung übertragen werden. Interrupts werden erst nach der Befehlsabarbeitung erkannt und ausgeführt. Dies ist ein Problem bei Echtzeitanwendungen, da sich diese Verzögerung negativ auswirken kann. Außerdem kommt es durch Interrupts bei Instruction-Set-Parallismus oft zu Pipeline-Neustarts. Die Lösung dieser Probleme wäre ein direkter Speicherzugriff eines Devices, da so der Prozessor komplett umgangen werden kann. Wie kann DMA implementiert werden? Zentral Ein zentraler DMA-Controller steht allen Geräten zu Verfügung. Dezentral: Jede E/A-Einheit hat ihren eigenen DMA-Controller implementiert und kann selbst Busmaster werden Probleme bei DMA treten vor allem durch ihre Unabhängigkeit und die dadurch notwendigen Schutzmaßnahmen auf. Ein DMA-Controller wirkt wie ein weiterer Prozessor am Bus. Um Inkonsistenzen im Speicher zu vermeiden, muss ein DMA-Controller eng mit dem Speichermanagment des Systems zusammenarbeiten. Was ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adr
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itrstellen des Prozessorzustandes oder Bearbeitung einer neuen Aufgabe, z.B. bei Uhrinterrupt nach Ablauf einer Zeitscheibe oder Zustand "HALT" nach schwerem Fehler, z.B. Spannungsausfall (abort) <span>Welche beiden Zustandssicherungskonzepte gibt es totale Sicherung aller bislang nicht automatisch gesicherten Register der CPU-Status des unterbrochenen Programms wird komplett eingefroren auch die invarianten Anteile werden gesichert, der Programmzustand ist damit leicht zugreifbar weit verbreitet bei Allzweckbetriebssystemen (z.B. UNIX & Co.) partielle Sicherung der im weiteren Verlauf nicht gesicherten Register der CPU-Status des unterbrochenen Programms wird teilweise eingefroren es wird nur der wirklich von Änderungen betroffene Anteil gesichert der Programmzustand ist damit nicht leicht zugreifbar weit verbreitet bei Spezialzweckbetriebssystemen Was stellt das Hauptproblem bei Interrupts dar Interrupts verhalten sich nicht deterministisch. D.h. ihre Abarbeitungszeit variiert. Sie sollte trotzdem so gering wie möglich gehalten w
Original toplevel document
Grundprinzipien der Rechnerarchitekturrt das Big-Endian-Format. Falls Worte so in den Speicher passen, das keine Verschiebungen auftreten, heißt der Speicher aligned. Prüfen kann man dies durch die Formel Adresse mod Wortlänge = 0? <span>Kapitel 2 - Interrupts und DMA Klassifizieren Sie die verschiedenen Unterbrechungen! Wenn in der Literatur von Interrupts gesprochen wird, so werden oft externe, asynchrone Interrupts gemeint, welche meistens in Zusammenhang mit E/A-Geräten auftreten. Wie arbeiten Traps (Fangstellen?) Traps sind eine Art automatische Prozeduraufrufe, welche durch eine vom Programm verursachte Bedingung eingeleitet werden. Solch eine Bedingung kann z.B. Gleitkommaüberlauf, Schutzverletzung oder Stapelüberlauf. Findet ein Überlauf statt, so stoppt die Ablaufsteuerung die Ausführung und holt von einer bestimmten Stelle im Speicher die Adresse des Trap-Handlers (Prozedur), mit der dann der Programmcounter überschrieben wird. Wesentliches Merkmal eines Traps ist, daß es durch Ausnahmebedingungen ausgelöst wird, welche durch Hardware oder Mikroprogramme erkannt werden. Wie arbeiten Interrupts Interrupts sind Unterbrechungen der Ablaufsteuerung. Wie es für Traps Trap-Handler gibt, gibt es für Interrupts Interrupt-Handler. Nach Abarbeitung des Interrupt-Handlers wird die Kontrolle wieder an das Programm zurückgegeben. Der interne Zustand des Prozessors (IP, Register, ...) muss nun exakt wiederhergestellt werden. Der Unterschied zwischen Traps und Interrupts ist nun, daß Traps synchron mit dem ausgeführten Programm laufen. Deshalb werden sie auch erst nach der Befehlsausführung erkannt und ausgeführt. Asynchrone Interrupts sind dagegen unabhängig vom gerade ausgeführten Programm. Interrupt’s stammen von echten physikalischen INT-Quellen wie z.B. IRQ3 von COM1 kommt. Diese springen über ein Interrupt-Gate. Interrupt’s die per Software mit INT-Befehl ausgelöst werden, springen über Trap-Gates! Wenn ein Interrupt ein Interrupt-Gate durchläuft, wird das IF=0 automatisch gesetzt, d.h. es gehen überhaupt keine Interrupts mehr durch. Asynchrone Interrupts können also nicht unterbrochen werden. Trap-Gates dürfen unterbrochen werden, da sie nicht zeitkritisch sind. Interrupt- und Trap-Gates führen nicht zu Taskwechsel über ein TSS. Das retten der Register ist dem INT-Handler überlassen. Was sind Software Interrupts? Software-Interrupts werden von Programmen mit Hilfe von speziellen Maschinenbefehlen aufgerufen. Dabei müssen diese nur eine Nummer für das benötigte Interrupt kennen. Über diese Nummer wird in der Interrupt-Vektor-Tabelle die Adresse des Interrupt-Unterprogrammes (ISR) referenziert und ausgeführt. Was versteht man unter internen und externen Interrupts? Externe Interrupts sind asynchron, wie nichtvektorisierte und vektorisierte Interrupts. Interne sind synchron, wie Software Interrupts oder Exection-Traps (Reaktionen auf interne Fehler wie FPU-Errors oder Page-Faults). Was ist Polling? Polling ist das zyklische Abfragen von einen oder mehreren E/A-Devices zur Feststellung der Kommunikationsbereitschaft bzw. zum Einholen von Kommunikationswünschen. Vorteile des Pollings Nachteile des Pollings Einfach zu Implementieren Hoher Programm-Overhead Kommunikationsanforderungen erfolgen synchron zum Programmablauf Die meisten Anfragen an die Geräte sind unnötig Je mehr Geräte am Bus hängen, um so mehr steigt Reaktionszeit. Priorisierung bei zeitgleichen Anfragen erfordert zusätzlichen Zeitaufwand Aufgrund der vielen Nachteile sollte besser eine asynchrone Kommunikation mit den Geräten durch die Hardware unterstützt werden (Interrupts). Das Interrupt-Prinzip Es kann auch über eine Art "hardware-gestütztes Polling" über spezielle Interrupt-Signalleitungen eine Kommunikationsanforderung festgestellt werden. Dazu muss aber die Befehlsverarbeitungschleife um eine Unterbrechungsanfrage erweitert werden. Erklären Sie den Unterschied zwischen vektorisierten und nichtvektorisierten Interrupts! Man unterscheidet vektorisierten und nichtvektorisierten Interrupt. Bei nichtvektorisierten Interrupts wird dem Interruptsignal eine feste Adresse zugeordnet. Bei vektorisierten Interrupts wird dynamisch eine wahlfreie Adresse zugeordnet, welche durch die CPU über ein definiertes Protokoll vom Datenbus gelesen wird. Was passiert beim Auftreten eines Interrupts? 1. Sperren weiterer Unterbrechungen mit gleicher oder geringerer Priotität Unterbrechungen mit höherer Wichtigkeit dürfen normalerweise solche mit geringerer Wichtigkeit wieder unterbrechen 2. Rettung wichtiger Register-Informationen(Prozessorstatus) alle Prozessor-Register retten, die durch die Interruptbehandlung überschrieben würden heute gibt es dafür spezielle Maschinenbefehle 3. Bestimmen der Interruptquelle (durch Hardware realisiert) 4. Laden des zugehörigen Interruptvektors d.h. das Herstellen des Anfangszustandes für gewählte Interruptroutine 5. Abarbeitung der Interruptroutine Retten weiterer Zustandsinformationen, sofern nicht durch Hardware realisiert meistens Übernahme weiterer Parameter von definierten Stellen (bei Systemaufruf Ruf-Nr. und weitere Parameter oder bei Geräte-Interrupt Gerätestatusbits wie E/A Fortschritt, Fehler etc.) eigentliche Behandlung des Interrupts, z.B. Setzen eines Flags (z.B. bei Gleitkommaüberlauf oder Aufruf zum Rückpositionieren und erneutem Lesen bei Lesefehler bei Magnetbandkassette (komplizierterer Fall) 6. Rückkehr zur unterbrochenen Aufgabe entweder Rückspeichern der geretteten Registerinformationen, d.h. Wiederherstellen des Prozessorzustandes oder Bearbeitung einer neuen Aufgabe, z.B. bei Uhrinterrupt nach Ablauf einer Zeitscheibe oder Zustand "HALT" nach schwerem Fehler, z.B. Spannungsausfall (abort) Welche beiden Zustandssicherungskonzepte gibt es totale Sicherung aller bislang nicht automatisch gesicherten Register der CPU-Status des unterbrochenen Programms wird komplett eingefroren auch die invarianten Anteile werden gesichert, der Programmzustand ist damit leicht zugreifbar weit verbreitet bei Allzweckbetriebssystemen (z.B. UNIX & Co.) partielle Sicherung der im weiteren Verlauf nicht gesicherten Register der CPU-Status des unterbrochenen Programms wird teilweise eingefroren es wird nur der wirklich von Änderungen betroffene Anteil gesichert der Programmzustand ist damit nicht leicht zugreifbar weit verbreitet bei Spezialzweckbetriebssystemen Was stellt das Hauptproblem bei Interrupts dar Interrupts verhalten sich nicht deterministisch. D.h. ihre Abarbeitungszeit variiert. Sie sollte trotzdem so gering wie möglich gehalten werden. Warum wird DMA oft Interrupts vorgezogen? Zwar befreien Interrupts die Prozessoren vom Warten auf E/A Ereignisse, aber vektorisierte Interrupts benötigen viele Taktzyklen zu ihrer Abarbeitung. Dieser Overhead steigt natürlich, um so weniger Datenmengen bei einer Interruptauslösung übertragen werden. Interrupts werden erst nach der Befehlsabarbeitung erkannt und ausgeführt. Dies ist ein Problem bei Echtzeitanwendungen, da sich diese Verzögerung negativ auswirken kann. Außerdem kommt es durch Interrupts bei Instruction-Set-Parallismus oft zu Pipeline-Neustarts. Die Lösung dieser Probleme wäre ein direkter Speicherzugriff eines Devices, da so der Prozessor komplett umgangen werden kann. Wie kann DMA implementiert werden? Zentral Ein zentraler DMA-Controller steht allen Geräten zu Verfügung. Dezentral: Jede E/A-Einheit hat ihren eigenen DMA-Controller implementiert und kann selbst Busmaster werden Probleme bei DMA treten vor allem durch ihre Unabhängigkeit und die dadurch notwendigen Schutzmaßnahmen auf. Ein DMA-Controller wirkt wie ein weiterer Prozessor am Bus. Um Inkonsistenzen im Speicher zu vermeiden, muss ein DMA-Controller eng mit dem Speichermanagment des Systems zusammenarbeiten. Was ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adr
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itteilweise eingefroren es wird nur der wirklich von Änderungen betroffene Anteil gesichert der Programmzustand ist damit nicht leicht zugreifbar weit verbreitet bei Spezialzweckbetriebssystemen <span>Was stellt das Hauptproblem bei Interrupts dar Interrupts verhalten sich nicht deterministisch. D.h. ihre Abarbeitungszeit variiert. Sie sollte trotzdem so gering wie möglich gehalten werden. Warum wird DMA oft Interrupts vorgezogen? Zwar befreien Interrupts die Prozessoren vom Warten auf E/A Ereignisse, aber vektorisierte Interrupts benötigen viele Taktzyklen zu ihrer Abarb
Original toplevel document
Grundprinzipien der Rechnerarchitekturrt das Big-Endian-Format. Falls Worte so in den Speicher passen, das keine Verschiebungen auftreten, heißt der Speicher aligned. Prüfen kann man dies durch die Formel Adresse mod Wortlänge = 0? <span>Kapitel 2 - Interrupts und DMA Klassifizieren Sie die verschiedenen Unterbrechungen! Wenn in der Literatur von Interrupts gesprochen wird, so werden oft externe, asynchrone Interrupts gemeint, welche meistens in Zusammenhang mit E/A-Geräten auftreten. Wie arbeiten Traps (Fangstellen?) Traps sind eine Art automatische Prozeduraufrufe, welche durch eine vom Programm verursachte Bedingung eingeleitet werden. Solch eine Bedingung kann z.B. Gleitkommaüberlauf, Schutzverletzung oder Stapelüberlauf. Findet ein Überlauf statt, so stoppt die Ablaufsteuerung die Ausführung und holt von einer bestimmten Stelle im Speicher die Adresse des Trap-Handlers (Prozedur), mit der dann der Programmcounter überschrieben wird. Wesentliches Merkmal eines Traps ist, daß es durch Ausnahmebedingungen ausgelöst wird, welche durch Hardware oder Mikroprogramme erkannt werden. Wie arbeiten Interrupts Interrupts sind Unterbrechungen der Ablaufsteuerung. Wie es für Traps Trap-Handler gibt, gibt es für Interrupts Interrupt-Handler. Nach Abarbeitung des Interrupt-Handlers wird die Kontrolle wieder an das Programm zurückgegeben. Der interne Zustand des Prozessors (IP, Register, ...) muss nun exakt wiederhergestellt werden. Der Unterschied zwischen Traps und Interrupts ist nun, daß Traps synchron mit dem ausgeführten Programm laufen. Deshalb werden sie auch erst nach der Befehlsausführung erkannt und ausgeführt. Asynchrone Interrupts sind dagegen unabhängig vom gerade ausgeführten Programm. Interrupt’s stammen von echten physikalischen INT-Quellen wie z.B. IRQ3 von COM1 kommt. Diese springen über ein Interrupt-Gate. Interrupt’s die per Software mit INT-Befehl ausgelöst werden, springen über Trap-Gates! Wenn ein Interrupt ein Interrupt-Gate durchläuft, wird das IF=0 automatisch gesetzt, d.h. es gehen überhaupt keine Interrupts mehr durch. Asynchrone Interrupts können also nicht unterbrochen werden. Trap-Gates dürfen unterbrochen werden, da sie nicht zeitkritisch sind. Interrupt- und Trap-Gates führen nicht zu Taskwechsel über ein TSS. Das retten der Register ist dem INT-Handler überlassen. Was sind Software Interrupts? Software-Interrupts werden von Programmen mit Hilfe von speziellen Maschinenbefehlen aufgerufen. Dabei müssen diese nur eine Nummer für das benötigte Interrupt kennen. Über diese Nummer wird in der Interrupt-Vektor-Tabelle die Adresse des Interrupt-Unterprogrammes (ISR) referenziert und ausgeführt. Was versteht man unter internen und externen Interrupts? Externe Interrupts sind asynchron, wie nichtvektorisierte und vektorisierte Interrupts. Interne sind synchron, wie Software Interrupts oder Exection-Traps (Reaktionen auf interne Fehler wie FPU-Errors oder Page-Faults). Was ist Polling? Polling ist das zyklische Abfragen von einen oder mehreren E/A-Devices zur Feststellung der Kommunikationsbereitschaft bzw. zum Einholen von Kommunikationswünschen. Vorteile des Pollings Nachteile des Pollings Einfach zu Implementieren Hoher Programm-Overhead Kommunikationsanforderungen erfolgen synchron zum Programmablauf Die meisten Anfragen an die Geräte sind unnötig Je mehr Geräte am Bus hängen, um so mehr steigt Reaktionszeit. Priorisierung bei zeitgleichen Anfragen erfordert zusätzlichen Zeitaufwand Aufgrund der vielen Nachteile sollte besser eine asynchrone Kommunikation mit den Geräten durch die Hardware unterstützt werden (Interrupts). Das Interrupt-Prinzip Es kann auch über eine Art "hardware-gestütztes Polling" über spezielle Interrupt-Signalleitungen eine Kommunikationsanforderung festgestellt werden. Dazu muss aber die Befehlsverarbeitungschleife um eine Unterbrechungsanfrage erweitert werden. Erklären Sie den Unterschied zwischen vektorisierten und nichtvektorisierten Interrupts! Man unterscheidet vektorisierten und nichtvektorisierten Interrupt. Bei nichtvektorisierten Interrupts wird dem Interruptsignal eine feste Adresse zugeordnet. Bei vektorisierten Interrupts wird dynamisch eine wahlfreie Adresse zugeordnet, welche durch die CPU über ein definiertes Protokoll vom Datenbus gelesen wird. Was passiert beim Auftreten eines Interrupts? 1. Sperren weiterer Unterbrechungen mit gleicher oder geringerer Priotität Unterbrechungen mit höherer Wichtigkeit dürfen normalerweise solche mit geringerer Wichtigkeit wieder unterbrechen 2. Rettung wichtiger Register-Informationen(Prozessorstatus) alle Prozessor-Register retten, die durch die Interruptbehandlung überschrieben würden heute gibt es dafür spezielle Maschinenbefehle 3. Bestimmen der Interruptquelle (durch Hardware realisiert) 4. Laden des zugehörigen Interruptvektors d.h. das Herstellen des Anfangszustandes für gewählte Interruptroutine 5. Abarbeitung der Interruptroutine Retten weiterer Zustandsinformationen, sofern nicht durch Hardware realisiert meistens Übernahme weiterer Parameter von definierten Stellen (bei Systemaufruf Ruf-Nr. und weitere Parameter oder bei Geräte-Interrupt Gerätestatusbits wie E/A Fortschritt, Fehler etc.) eigentliche Behandlung des Interrupts, z.B. Setzen eines Flags (z.B. bei Gleitkommaüberlauf oder Aufruf zum Rückpositionieren und erneutem Lesen bei Lesefehler bei Magnetbandkassette (komplizierterer Fall) 6. Rückkehr zur unterbrochenen Aufgabe entweder Rückspeichern der geretteten Registerinformationen, d.h. Wiederherstellen des Prozessorzustandes oder Bearbeitung einer neuen Aufgabe, z.B. bei Uhrinterrupt nach Ablauf einer Zeitscheibe oder Zustand "HALT" nach schwerem Fehler, z.B. Spannungsausfall (abort) Welche beiden Zustandssicherungskonzepte gibt es totale Sicherung aller bislang nicht automatisch gesicherten Register der CPU-Status des unterbrochenen Programms wird komplett eingefroren auch die invarianten Anteile werden gesichert, der Programmzustand ist damit leicht zugreifbar weit verbreitet bei Allzweckbetriebssystemen (z.B. UNIX & Co.) partielle Sicherung der im weiteren Verlauf nicht gesicherten Register der CPU-Status des unterbrochenen Programms wird teilweise eingefroren es wird nur der wirklich von Änderungen betroffene Anteil gesichert der Programmzustand ist damit nicht leicht zugreifbar weit verbreitet bei Spezialzweckbetriebssystemen Was stellt das Hauptproblem bei Interrupts dar Interrupts verhalten sich nicht deterministisch. D.h. ihre Abarbeitungszeit variiert. Sie sollte trotzdem so gering wie möglich gehalten werden. Warum wird DMA oft Interrupts vorgezogen? Zwar befreien Interrupts die Prozessoren vom Warten auf E/A Ereignisse, aber vektorisierte Interrupts benötigen viele Taktzyklen zu ihrer Abarbeitung. Dieser Overhead steigt natürlich, um so weniger Datenmengen bei einer Interruptauslösung übertragen werden. Interrupts werden erst nach der Befehlsabarbeitung erkannt und ausgeführt. Dies ist ein Problem bei Echtzeitanwendungen, da sich diese Verzögerung negativ auswirken kann. Außerdem kommt es durch Interrupts bei Instruction-Set-Parallismus oft zu Pipeline-Neustarts. Die Lösung dieser Probleme wäre ein direkter Speicherzugriff eines Devices, da so der Prozessor komplett umgangen werden kann. Wie kann DMA implementiert werden? Zentral Ein zentraler DMA-Controller steht allen Geräten zu Verfügung. Dezentral: Jede E/A-Einheit hat ihren eigenen DMA-Controller implementiert und kann selbst Busmaster werden Probleme bei DMA treten vor allem durch ihre Unabhängigkeit und die dadurch notwendigen Schutzmaßnahmen auf. Ein DMA-Controller wirkt wie ein weiterer Prozessor am Bus. Um Inkonsistenzen im Speicher zu vermeiden, muss ein DMA-Controller eng mit dem Speichermanagment des Systems zusammenarbeiten. Was ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adr
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itn Was stellt das Hauptproblem bei Interrupts dar Interrupts verhalten sich nicht deterministisch. D.h. ihre Abarbeitungszeit variiert. Sie sollte trotzdem so gering wie möglich gehalten werden. <span>Warum wird DMA oft Interrupts vorgezogen? Zwar befreien Interrupts die Prozessoren vom Warten auf E/A Ereignisse, aber vektorisierte Interrupts benötigen viele Taktzyklen zu ihrer Abarbeitung. Dieser Overhead steigt natürlich, um so weniger Datenmengen bei einer Interruptauslösung übertragen werden. Interrupts werden erst nach der Befehlsabarbeitung erkannt und ausgeführt. Dies ist ein Problem bei Echtzeitanwendungen, da sich diese Verzögerung negativ auswirken kann. Außerdem kommt es durch Interrupts bei Instruction-Set-Parallismus oft zu Pipeline-Neustarts. Die Lösung dieser Probleme wäre ein direkter Speicherzugriff eines Devices, da so der Prozessor komplett umgangen werden kann. Wie kann DMA implementiert werden? Zentral Ein zentraler DMA-Controller steht allen Geräten zu Verfügung. Dezentral: Jede E/A-Einheit hat ihren eigenen DMA-Controller implementiert und kann selbst Busmaster werden Probleme bei DMA treten vor allem durch ihre Unabhängigkeit und die dadurch notwendigen Schutzmaßnahmen auf. Ein DMA-Controller wirkt wie ein weiterer Prozessor am Bus. Um Inkonsistenzen im Speicher zu vermeiden, muss ein DMA-Controller eng mit dem Speichermanagment des Systems zusammenarbeiten. <span>
Original toplevel document
Grundprinzipien der Rechnerarchitekturrt das Big-Endian-Format. Falls Worte so in den Speicher passen, das keine Verschiebungen auftreten, heißt der Speicher aligned. Prüfen kann man dies durch die Formel Adresse mod Wortlänge = 0? <span>Kapitel 2 - Interrupts und DMA Klassifizieren Sie die verschiedenen Unterbrechungen! Wenn in der Literatur von Interrupts gesprochen wird, so werden oft externe, asynchrone Interrupts gemeint, welche meistens in Zusammenhang mit E/A-Geräten auftreten. Wie arbeiten Traps (Fangstellen?) Traps sind eine Art automatische Prozeduraufrufe, welche durch eine vom Programm verursachte Bedingung eingeleitet werden. Solch eine Bedingung kann z.B. Gleitkommaüberlauf, Schutzverletzung oder Stapelüberlauf. Findet ein Überlauf statt, so stoppt die Ablaufsteuerung die Ausführung und holt von einer bestimmten Stelle im Speicher die Adresse des Trap-Handlers (Prozedur), mit der dann der Programmcounter überschrieben wird. Wesentliches Merkmal eines Traps ist, daß es durch Ausnahmebedingungen ausgelöst wird, welche durch Hardware oder Mikroprogramme erkannt werden. Wie arbeiten Interrupts Interrupts sind Unterbrechungen der Ablaufsteuerung. Wie es für Traps Trap-Handler gibt, gibt es für Interrupts Interrupt-Handler. Nach Abarbeitung des Interrupt-Handlers wird die Kontrolle wieder an das Programm zurückgegeben. Der interne Zustand des Prozessors (IP, Register, ...) muss nun exakt wiederhergestellt werden. Der Unterschied zwischen Traps und Interrupts ist nun, daß Traps synchron mit dem ausgeführten Programm laufen. Deshalb werden sie auch erst nach der Befehlsausführung erkannt und ausgeführt. Asynchrone Interrupts sind dagegen unabhängig vom gerade ausgeführten Programm. Interrupt’s stammen von echten physikalischen INT-Quellen wie z.B. IRQ3 von COM1 kommt. Diese springen über ein Interrupt-Gate. Interrupt’s die per Software mit INT-Befehl ausgelöst werden, springen über Trap-Gates! Wenn ein Interrupt ein Interrupt-Gate durchläuft, wird das IF=0 automatisch gesetzt, d.h. es gehen überhaupt keine Interrupts mehr durch. Asynchrone Interrupts können also nicht unterbrochen werden. Trap-Gates dürfen unterbrochen werden, da sie nicht zeitkritisch sind. Interrupt- und Trap-Gates führen nicht zu Taskwechsel über ein TSS. Das retten der Register ist dem INT-Handler überlassen. Was sind Software Interrupts? Software-Interrupts werden von Programmen mit Hilfe von speziellen Maschinenbefehlen aufgerufen. Dabei müssen diese nur eine Nummer für das benötigte Interrupt kennen. Über diese Nummer wird in der Interrupt-Vektor-Tabelle die Adresse des Interrupt-Unterprogrammes (ISR) referenziert und ausgeführt. Was versteht man unter internen und externen Interrupts? Externe Interrupts sind asynchron, wie nichtvektorisierte und vektorisierte Interrupts. Interne sind synchron, wie Software Interrupts oder Exection-Traps (Reaktionen auf interne Fehler wie FPU-Errors oder Page-Faults). Was ist Polling? Polling ist das zyklische Abfragen von einen oder mehreren E/A-Devices zur Feststellung der Kommunikationsbereitschaft bzw. zum Einholen von Kommunikationswünschen. Vorteile des Pollings Nachteile des Pollings Einfach zu Implementieren Hoher Programm-Overhead Kommunikationsanforderungen erfolgen synchron zum Programmablauf Die meisten Anfragen an die Geräte sind unnötig Je mehr Geräte am Bus hängen, um so mehr steigt Reaktionszeit. Priorisierung bei zeitgleichen Anfragen erfordert zusätzlichen Zeitaufwand Aufgrund der vielen Nachteile sollte besser eine asynchrone Kommunikation mit den Geräten durch die Hardware unterstützt werden (Interrupts). Das Interrupt-Prinzip Es kann auch über eine Art "hardware-gestütztes Polling" über spezielle Interrupt-Signalleitungen eine Kommunikationsanforderung festgestellt werden. Dazu muss aber die Befehlsverarbeitungschleife um eine Unterbrechungsanfrage erweitert werden. Erklären Sie den Unterschied zwischen vektorisierten und nichtvektorisierten Interrupts! Man unterscheidet vektorisierten und nichtvektorisierten Interrupt. Bei nichtvektorisierten Interrupts wird dem Interruptsignal eine feste Adresse zugeordnet. Bei vektorisierten Interrupts wird dynamisch eine wahlfreie Adresse zugeordnet, welche durch die CPU über ein definiertes Protokoll vom Datenbus gelesen wird. Was passiert beim Auftreten eines Interrupts? 1. Sperren weiterer Unterbrechungen mit gleicher oder geringerer Priotität Unterbrechungen mit höherer Wichtigkeit dürfen normalerweise solche mit geringerer Wichtigkeit wieder unterbrechen 2. Rettung wichtiger Register-Informationen(Prozessorstatus) alle Prozessor-Register retten, die durch die Interruptbehandlung überschrieben würden heute gibt es dafür spezielle Maschinenbefehle 3. Bestimmen der Interruptquelle (durch Hardware realisiert) 4. Laden des zugehörigen Interruptvektors d.h. das Herstellen des Anfangszustandes für gewählte Interruptroutine 5. Abarbeitung der Interruptroutine Retten weiterer Zustandsinformationen, sofern nicht durch Hardware realisiert meistens Übernahme weiterer Parameter von definierten Stellen (bei Systemaufruf Ruf-Nr. und weitere Parameter oder bei Geräte-Interrupt Gerätestatusbits wie E/A Fortschritt, Fehler etc.) eigentliche Behandlung des Interrupts, z.B. Setzen eines Flags (z.B. bei Gleitkommaüberlauf oder Aufruf zum Rückpositionieren und erneutem Lesen bei Lesefehler bei Magnetbandkassette (komplizierterer Fall) 6. Rückkehr zur unterbrochenen Aufgabe entweder Rückspeichern der geretteten Registerinformationen, d.h. Wiederherstellen des Prozessorzustandes oder Bearbeitung einer neuen Aufgabe, z.B. bei Uhrinterrupt nach Ablauf einer Zeitscheibe oder Zustand "HALT" nach schwerem Fehler, z.B. Spannungsausfall (abort) Welche beiden Zustandssicherungskonzepte gibt es totale Sicherung aller bislang nicht automatisch gesicherten Register der CPU-Status des unterbrochenen Programms wird komplett eingefroren auch die invarianten Anteile werden gesichert, der Programmzustand ist damit leicht zugreifbar weit verbreitet bei Allzweckbetriebssystemen (z.B. UNIX & Co.) partielle Sicherung der im weiteren Verlauf nicht gesicherten Register der CPU-Status des unterbrochenen Programms wird teilweise eingefroren es wird nur der wirklich von Änderungen betroffene Anteil gesichert der Programmzustand ist damit nicht leicht zugreifbar weit verbreitet bei Spezialzweckbetriebssystemen Was stellt das Hauptproblem bei Interrupts dar Interrupts verhalten sich nicht deterministisch. D.h. ihre Abarbeitungszeit variiert. Sie sollte trotzdem so gering wie möglich gehalten werden. Warum wird DMA oft Interrupts vorgezogen? Zwar befreien Interrupts die Prozessoren vom Warten auf E/A Ereignisse, aber vektorisierte Interrupts benötigen viele Taktzyklen zu ihrer Abarbeitung. Dieser Overhead steigt natürlich, um so weniger Datenmengen bei einer Interruptauslösung übertragen werden. Interrupts werden erst nach der Befehlsabarbeitung erkannt und ausgeführt. Dies ist ein Problem bei Echtzeitanwendungen, da sich diese Verzögerung negativ auswirken kann. Außerdem kommt es durch Interrupts bei Instruction-Set-Parallismus oft zu Pipeline-Neustarts. Die Lösung dieser Probleme wäre ein direkter Speicherzugriff eines Devices, da so der Prozessor komplett umgangen werden kann. Wie kann DMA implementiert werden? Zentral Ein zentraler DMA-Controller steht allen Geräten zu Verfügung. Dezentral: Jede E/A-Einheit hat ihren eigenen DMA-Controller implementiert und kann selbst Busmaster werden Probleme bei DMA treten vor allem durch ihre Unabhängigkeit und die dadurch notwendigen Schutzmaßnahmen auf. Ein DMA-Controller wirkt wie ein weiterer Prozessor am Bus. Um Inkonsistenzen im Speicher zu vermeiden, muss ein DMA-Controller eng mit dem Speichermanagment des Systems zusammenarbeiten. Was ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adr
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itedges to the intervened node(s) removed. This is because the probability for the intervened factor has been set to 1, so we can just ignore that factor (this is the focus of the next section). <span>Another way to see that the intervened node has no causal parents is that the intervened node is set to a constant value, so it no longer depends on any of the variables it depends on in the observational setting (its parents). The graph with edges removed is known as the manipulated graph <span>
Original toplevel document (pdf)
cannot see any pdfsFlashcard 7641034788108
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itLSTM Weights A memory cell has weight parameters for the input, output, as well as an internal state
Original toplevel document (pdf)
cannot see any pdfs
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Flashcard 7641038720268
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itThe internal state in LSTM layers is also accumulated when evaluating a network and when making predictions
Original toplevel document (pdf)
cannot see any pdfsFlashcard 7641041079564
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itAs we discussed in Section 4.2, the graph for the interventional distribution 𝑃(𝑌 | do(𝑡)) is the same as the graph for the observational distribution 𝑃(𝑌, 𝑇, 𝑋) , but with the incoming edges to 𝑇 removed.
Original toplevel document (pdf)
cannot see any pdfsFlashcard 7641042652428
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itThe flow of association is symmetric
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itholidays. In Appendix Section F we provide a further characterization of scenarios where our model performs particularly well and where it does not do so relative to the used benchmark methods. <span>The model brings many practical benefits for the marketing analyst, such as the lack of need for manual encoding of any features in the customer data, a simple optimization objective, and quick estimation on modern computer hardware. We show that incorporating contextual information in the model is straightforward and brings an additional boost in predictive accuracy. However, the model performance is already extremely strong when no context is available beyond the timing of the customer’s transactions. This is welcome news for firms that do not wish to collect personal information on principle, to avoid the questionable ethics of harvesting the ‘‘behavioral surplus” (Zuboff, 2019): our work shows that this is feasible without a big loss of accuracy. We gather evidence from eight diverse real-life settings to demonstrate the model robustness as a flexible, general purpose prediction tool for customer base analysis <span>
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open it1.4.1 LSTM Weights A memory cell has weight parameters for the input, output, as well as an internal state that is built up through exposure to input time steps. Input Weights. Used to weight input for the current time step. Output Weights. Used to weight the output from the last time step. Internal State. Internal state used in the calculation of the output for this time step
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itThe Stacked LSTM is a model that has multiple hidden LSTM layers where each layer contains multiple memory cells.
Original toplevel document (pdf)
cannot see any pdfsFlashcard 7641052089612
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itWe are employing RNNs in production now which offers significant advantages over existing methods: reduced feature engineering; improved empirical performance; and better prediction explanations
Original toplevel document (pdf)
cannot see any pdfsFlashcard 7641054973196
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itThe caution is that LSTMs are not a silver bullet and to carefully consider the framing of your problem.
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Flashcard 7641069391116
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itOrganização é uma entidade estruturada
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Flashcard 7641072012556
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itde um lado temos a administração, cujo papel é orientar e conduzir pessoas e recursos, para que objetivos sejam alcançados (a administração conduz a organização).
Original toplevel document (pdf)
cannot see any pdfsFlashcard 7641073061132
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itde um lado temos a administração, cujo papel é orientar e conduzir pessoas e recursos, para que objetivos sejam alcançados (a administração conduz a organização).
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Flashcard 7641075682572
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itOrganização Formal: É aquela pautada pela racionalidade e pela lógica. É o conjunto de normas que orientam o andamento dos processos organizacionais. A estrutura da organização e as funções são definidas
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Flashcard 7641078828300
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itOrganização Informal: É aquela baseada na espontaneidade. Está associada a questões de ordem social e pessoal que os colaboradores da empresa compartilham dentro do ambiente organizacional. É formada por re
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Flashcard 7641081449740
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open it2.3 - Níveis Organizacionais As organizações podem ser divididas em três níveis: nível estratégico (ou institucional), nível tático (intermediário, ou gerencial) e nível operacional.
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Flashcard 7641084071180
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itNível operacional: É o nível administrativo mais baixo. É onde estão os supervisores. O foco é no curto prazo, no desempenho das tarefas. Os administradores desse nível devem se preocupar em
Original toplevel document (pdf)
cannot see any pdfsFlashcard 7641088789772
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itegundo Chiavenato 10 , a tarefa básica da administração é “interpretar os objetivos globais propostos pela organização e transformá-los em ação organizacional global por meio de planejamento, organização
Original toplevel document (pdf)
cannot see any pdfsFlashcard 7641090362636
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itegundo Chiavenato 10 , a tarefa básica da administração é “interpretar os objetivos globais propostos pela organização e transformá-los em ação organizacional global por meio de planejamento, organização, direção e controle de todos os esfor
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |