Edited, memorised or added to reading queue
on 21-Jun-2024 (Fri)
Do you want BuboFlash to help you learning these things? Click here to log in or create user.
Flashcard 7629448809740
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itIn the future, predictions on the level of products and individual tastes will be in our focus, enabling sophisticated recommendation products. This will require richer input descriptions at individual time-steps. Likewise, more sophisticated RNN architecture
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itWas ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adressraum verschiedenen I/O-Devices zuzuordnen oder Getrennten I/O Adressraum, bei dem auf einer speziellen Adressleitung die E/A-Adresse auf den Bus gelegt wird. (veraltete Variante) Was ist eine Task? Ein Task ist ein eigenständiges Programm / Prozess von vielen im Multitasksystem. Es wird von einem TSS (Task State Segment) beschrieben. Bei einem Taskwechsel werden
Original toplevel document
Grundprinzipien der Rechnerarchitekturauf. Ein DMA-Controller wirkt wie ein weiterer Prozessor am Bus. Um Inkonsistenzen im Speicher zu vermeiden, muss ein DMA-Controller eng mit dem Speichermanagment des Systems zusammenarbeiten. <span>Was ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adressraum verschiedenen I/O-Devices zuzuordnen oder Getrennten I/O Adressraum, bei dem auf einer speziellen Adressleitung die E/A-Adresse auf den Bus gelegt wird. (veraltete Variante) Was ist eine Task? Ein Task ist ein eigenständiges Programm / Prozess von vielen im Multitasksystem. Es wird von einem TSS (Task State Segment) beschrieben. Bei einem Taskwechsel werden alle Informationen in diesem TSS gespeichert. Jeder TSS-Deskriptor steht in der GDT. Die GDT hat beim i486 8192 Einträge, jedoch ist der 0. Eintrag immer leer. Somit sind maximal 8191 verschiedene Prozesse möglich (inclusive des Betriebssystems). Wie werden Task-Wechsel realisiert? Ein Taskwechsel geschieht durch Auswahl eines Task-Gates aus Globaler Deskriptor Tabelle (Task State Segment = TSS). Ein TSS Enthält alle Informationen, die einen Task ausmachen: verwendete Prozessor-Register LDT-Selektor (einer Pro Task) welche die Segment-Deskriptoren des Prozesses enthält Stack-Segment-Pointer Verwaltungsinformation Adresse der Paging-Tabellen I/O-Map Base Adresse Busy-Bit, definiert den aktuell rechnenden Task (genau einer im System) TR (Task Register) enthält den aktuellen TSS (Selektor des Descriptors des aktuellen TSS) TSS-Descriptoren nur in GDT! Bsp: Scheduler als Task ( Umschalter ) Umschalten durch jeweiligen Austausch des Back-Link, IRETD zum anderen Task, z.B. Timer-Interrupt-Task. Welche Möglichkeiten für Privilegwechsel gibt es? CALL in eine Prozedur mit anderen Privilegde-Level (CALL-Gate) JMP in eine Prozedur mit anderen Privi legde-Level (TASK-Gate) INT (TRAP-Gate) TASK-Gate durch erzwungenen Prozeßwechsel IRET Rücksprung aus INT-Handler Was ist der Unterschied zwischen einem Selektor und einem Deskriptor? Ein Selektor Segment-Register wählt einen Deskriptor in (GLI)DT aus, ein Deskriptor Eintrag in (GLI)DT, beschreibt das Segment. Weshalb ist es sinnvoll, dass ein TSS-Descriptor nur in der GDT stehen darf? Es soll verhindert werden, daß ein USER-Programm in einen anderen Task springt. Da Taskwechsel nur über TASK-Gates erfolgen (dieses zeigt auf einen TSS-Deskriptor) muß der CurrentPrivilegdeLevel (CPL vom CS:) numerisch kleiner sein, als das des geforderten TSS-Deskriptor (DPL) bzw. kleiner als der (RPL) des Segments wo sich der TSS-Deskriptor aufhält. Damit wird sichergestellt, daß der Taskwechsel nur von "höherem" Code (OS) aus ausgeführt werden kann. Würde ein TSS-Deskriptor in der LDT stehen, könnte es dort mit einem höheren RPL versehen werden, und der USER-Code könnte sich zum OS-CODE etablieren! Welche Grundtypen von Deskriptoren gibt es? IDT LDT GDT CODE-Segment DATA-Segment STACK-Segment CODE-Segment DATA-Segment STACK-Segment INT-Gate TRAP-Gate TASK-Gate TASK-Gate TASK-Gate CALL-Gate Welche grundlegenden Adressierungsarten gibt es? Unmittelbare Adressierung Direktadressierung (Direct Adressing) Registeradressierung Indirekte Registeradressierung Indizierte Adressierung Basisindizierte Adressierung Stapeladressierung Unmittelbare Adressierung Der Adressteil der Instruktion enthält den Operanden selbst, anstatt eines Verweises. Solche Operanden werden als Direktoperanden (Immediate) bezeichnet Bsp: MOV R4, 5H (5H wird direkt in R4 gespeichert) Direktadressierung (Direct Adressing) Es wird eine volle Adresse des Operanden angegeben Deshalb nur für globale Variablen anwendbar, da Instruktion immer auf gleiche Speicehrzeile zugreift Registeradressierung Das gleiche Prinzip wie Direct Adressing, nur das Register anstelle von Speicherzellen verwendet werden In Registern sollten die am häufigsten verwendeten Variablen abgelegt werden, da Register vielfach schneller als Hauptspeicher sind Load/Store-Architekturen nutzen fast nur diesen Registermode (außer es muss vom oder zum Speicher transferiert werden) Indirekte Registeradressierung Die Adresse wird nicht direkt angegeben, sondern indirekt über ein Register Das Register enthält somit einen Pointer auf eine Speicherzelle Vorteil ist, daß auf Speicher referenziert werden kann, aber keine volle Speicheradresse notwendig wird Indizierte Adressierung Der Speicher wird durch Angabe eines Registers und eines konstanten Offsets adressiert Häufig benutzt bei Arrayzugriffen, wie A = B[i] (MOV R1, B[R2]) Basisindizierte Adressierung Speicheradresse wird hier durch Addition zweier Register und einen optionalen Offset berechnet Eines der Register stellt die Basis dar und ein anderes den Index Stapeladressierung Hier ist gar keine Adressangabe notwendig Somit sind die Instruktionen sehr kurz Die Stapeladressierung arbeitet mit der umgekehrten polnischen Notation (Postfix) Kapitel 3 - Speicherschutz und Multitasking Um unberechtigte Zugriffe, Datenaufrufe oder Systemprozedurecalls zu vermeiden und Task-Isolation zu gewährleisten, ist ein ausgeklügeltes Sp
Flashcard 7641418566924
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itYou can normalize your dataset using the scikit-learn object MinMaxScaler
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itKapitel 6 - Pipelining Wozu dient Pipelining? Pipelining soll es ermöglichen Befehle überlappt auszuführen. Dazu sind ein einheitliches Befehlsformat fester Länge Grundlage. Deshalb werden werden nur auf Register getätigt. Für Speicheroperationen wird die LOAD / STORE Philosophie verfolgt, um langsame Hauptspeicherzugriffe zu minimieren. Was ist Voraussetzung für Pipelining? Die Befehlsverarbeitungsphase muss sich in mehrere voneinander unabhängige Phasen unterteilen lassen. Die einfachste Form einer Pipeline ist die 5-
Original toplevel document
Grundprinzipien der Rechnerarchitektureinen Verweis auf die Nächste enthalten. Sprünge sind einfach möglich. Angewandt wird dies in Form von Opcodes, welche nichts anderes als Adressen auf Mikroinstruktionen im Steuerspeicher sind. <span>Kapitel 6 - Pipelining Wozu dient Pipelining? Pipelining soll es ermöglichen Befehle überlappt auszuführen. Dazu sind ein einheitliches Befehlsformat fester Länge Grundlage. Deshalb werden werden nur auf Register getätigt. Für Speicheroperationen wird die LOAD / STORE Philosophie verfolgt, um langsame Hauptspeicherzugriffe zu minimieren. Was ist Voraussetzung für Pipelining? Die Befehlsverarbeitungsphase muss sich in mehrere voneinander unabhängige Phasen unterteilen lassen. Die einfachste Form einer Pipeline ist die 5-stufige mit folgenden Phasen: Befehl holen Befehl dekodieren Befehl ausführen Auf Speicher zugreifen Ergebnis in Register schreiben Moderene CPU's haben weitaus komplexere Pipelines, in denen die einzelnen Stufen wiederrum in mehrere sich überlappende Phasen aufgeteilt werden. Der allgemeine Aufbau einer (fünfstufigen) Pipeline Um Parallelität in der Befehlsausführungsphase zu erreichen, wird der Datenpfad so konstruiert, daß folgende (hier fünf) Phasen unabhänig voneinander arbeiten können. Nur so ist es möglich eine verzahnte Abarbeitung mehrerer Befehle zu erreichen. Abb.: Die Piplelinestufen Somit wird ,nachdem eine Pipeline gefüllt ist, im Optimalfall pro Takt ein Befehl fertig. (CPI = 1) Welche Pipeline-Konflikte müssen behandelt werden? Datenabhängigkeiten (Data Hazards) Sind logische Abhängigkeiten, welche eine verzögerte Abarbeitung erfordern, weil z.B. ein Folgebefehl auf ein Ergebnis eines anderen Befehles warten muss. Jump- / Branchverzögerungen (Control Hazards) Bei Sprungbefehlen liegt oft das Sprungziel nach der Dekodieung noch nicht fest. Somit müssen Techniken eingesetzt werden um diese Wartezeiten zu minimieren. (Branch Prediction) Ressourcenkonflikte (Structural Hazards) Bei bestimmten Befehlskombinationen ist es unter Umständen möglich, daß ein Teilwerk seine Arbeit wiederholen muss. Solche Ressourcenkonflikte treten dann auf, wenn nicht jeder Teilphase völlig unabhängige Teilwerke zugeordnet sind. Ein Beispiel ist z.B. ein zeitgleicher Lesezugriff eines LOAD/STORE Befehles, welcher sich zwangsweise mit einem eventuellen MEM ACCESS eines anderen Befehles überschneidet. Abhilfe können hier Dual-Port RAM, Havard-Architektur oder getrennte Code- und Datencaches schaffen. Welche drei verschiedenen Datenabhängigkeiten gibt es? RAW, WAW und WAR-Konflikte sind Datenabnhänigkeiten, welche in Pipelines auftreten können. Dabei ist das RAW-Problem für Pipelines typisch. WAR Konflikte treten eher bei Out-Of-Order Execution auf. Um Read-After-Write Konflikte aufzulösen, gibt es verschiedene Ansätze wie Softwarelösungen ( Compileroptimierung), Scoreboarding (zentrale Steuerlogik) und Forwarding (zusätzlicher Datenpfad). Was ist Forwarding? Beim Forwarding wird ein Bypass eingerichtet, welcher ein Ergebniss einer Operation schon einem Folgebefehl zur Verfügung stellt, bevor es überhaupt in ein Register geschrieben wurde. Aber trotz Load-Forwarding hat ein Ladebefehl eine Verzögerung, welche nicht gänzlich eliminiert werden kann. In diesem Fall kann die Delayed-Load Technik oder auch eine Befehlsumordnung Anhilfe schaffen. Was ist die Delayed Load-Technik? Bei der Delayed Load-Technik wird die Verzögerung nach einem LOAD Befehl als architektonisches Merkmal angesehn und den Compilerbauern offengelegt. Diese können nun durch Befehlsumordnungen versuchen, nach einem LOAD-Befehl einen datenunabhängigen Befehl einzufügen, um den Slot zu füllen. Zusammenfassung Pipelining Pipelines werden in allen modernen CPUs benutzt. Die UltraSparc2 hat neun und der P2 zwölf Stufen. Der Intel Pentium Itanium weißt eine 20 stufige Superpinepline (pipeline in der sich einzelne Stufen überlappen können) auf! Pipes werden heutzutage in Kombination mit der Superskalartechnik verwendet, um höchste Effizienz und Parallelverarbeitung gewährleisten zu können. Die fünf grundlegenden Stufen einer einfachen Pipeline sind IF,ID,EX,MEM und WB. Takte T = Befehle + (Pipestufen - 1) Folgende Abhängigkeiten verhindern, dass die CPI auf eins gehen: Strucual Hazards bzw. Ressourcenkonflikte IF und MEM wollen gleichzeitig auf Speicher lesend oder schreibend zugreifen. Das geht nicht, außer bei Dual-Port-RAM, welcher aber sehr teuer ist. Dieses Problem tritt aber bei modernen CPU's kaum noch auf, da eh intern eine Havard-ähnliche Architektur mit getrenntem Befehls- und Datencache gearbeitet wird. Data Hazards bzw. Datenabhängigkeiten Ein Folgebefehl wartet auf das Writeback der darüber liegenden Pipe, da er von diesem Befehl abhängig ist. Dies kann durch Nops bzw. Stalls ineffizient gelöst werden. Besser der Programmierer oder der Compiler löst diese Abhängigkeiten durch eine clevere Umordnung der Befehlsfolge auf. Es gibt aber noch eine andere Möglichkeit, welche aber hardwareseitig unterstützt werden muss. (VLIW, Superskalar) Forwarding Beim Forwarding werden Ergebnisse, sobald sie vorliegen an die nächste Stufe weitergereicht und nicht erst auf das Write Back gewartet. In anderen Worten: Das Ergebnis der ALU wird dieser sofort wieder eingespeist. Control Hazards bzw. Sprungverzögerungen Sprungergebnisse stehen erst in der Write Back Phase an. Moderne Prozessoren haben aber schon in der Fetch/Decode-Einheit eine Logik, welche die Zieladresse des Sprunges berechnet. Eine andere Möglichkeit ist die des spekulativen Ausführens. Hier tritt aber das Problem auf, dass viel Aufwand bei falscher Spekulation getrieben werden muss. Was ist der Unterschied zwischen echten und unechten Datenabhängigkeiten? Echte Datenabhängigkeiten sind RAW-Konflikte, bei dem ein Befehl auf die Beendigung eines Anderen warten muss, da er das Ergebnis als Operand benötigt. Unechte Datenabhängigkeit sind Abhängigkeiten, welche nur durch Namensabhängigkeit entstehen. Es gibt zwei Arten unechter Datenabhängigkeit: Antidependence sind WAR-Konflikte, welche entstehen, wenn ein Folgebefehl auf ein Register schreiben möchte, das noch von einem Anderen benutzt wird. Output Dependece sind WAW-Konflikte, welche entstehen, wenn mehrere Befehle auf ein und das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. D
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itmat fester Länge Grundlage. Deshalb werden werden nur auf Register getätigt. Für Speicheroperationen wird die LOAD / STORE Philosophie verfolgt, um langsame Hauptspeicherzugriffe zu minimieren. <span>Was ist Voraussetzung für Pipelining? Die Befehlsverarbeitungsphase muss sich in mehrere voneinander unabhängige Phasen unterteilen lassen. Die einfachste Form einer Pipeline ist die 5-stufige mit folgenden Phasen: Befehl holen Befehl dekodieren Befehl ausführen Auf Speicher zugreifen Ergebnis in Register schreiben Moderene
Original toplevel document
Grundprinzipien der Rechnerarchitektureinen Verweis auf die Nächste enthalten. Sprünge sind einfach möglich. Angewandt wird dies in Form von Opcodes, welche nichts anderes als Adressen auf Mikroinstruktionen im Steuerspeicher sind. <span>Kapitel 6 - Pipelining Wozu dient Pipelining? Pipelining soll es ermöglichen Befehle überlappt auszuführen. Dazu sind ein einheitliches Befehlsformat fester Länge Grundlage. Deshalb werden werden nur auf Register getätigt. Für Speicheroperationen wird die LOAD / STORE Philosophie verfolgt, um langsame Hauptspeicherzugriffe zu minimieren. Was ist Voraussetzung für Pipelining? Die Befehlsverarbeitungsphase muss sich in mehrere voneinander unabhängige Phasen unterteilen lassen. Die einfachste Form einer Pipeline ist die 5-stufige mit folgenden Phasen: Befehl holen Befehl dekodieren Befehl ausführen Auf Speicher zugreifen Ergebnis in Register schreiben Moderene CPU's haben weitaus komplexere Pipelines, in denen die einzelnen Stufen wiederrum in mehrere sich überlappende Phasen aufgeteilt werden. Der allgemeine Aufbau einer (fünfstufigen) Pipeline Um Parallelität in der Befehlsausführungsphase zu erreichen, wird der Datenpfad so konstruiert, daß folgende (hier fünf) Phasen unabhänig voneinander arbeiten können. Nur so ist es möglich eine verzahnte Abarbeitung mehrerer Befehle zu erreichen. Abb.: Die Piplelinestufen Somit wird ,nachdem eine Pipeline gefüllt ist, im Optimalfall pro Takt ein Befehl fertig. (CPI = 1) Welche Pipeline-Konflikte müssen behandelt werden? Datenabhängigkeiten (Data Hazards) Sind logische Abhängigkeiten, welche eine verzögerte Abarbeitung erfordern, weil z.B. ein Folgebefehl auf ein Ergebnis eines anderen Befehles warten muss. Jump- / Branchverzögerungen (Control Hazards) Bei Sprungbefehlen liegt oft das Sprungziel nach der Dekodieung noch nicht fest. Somit müssen Techniken eingesetzt werden um diese Wartezeiten zu minimieren. (Branch Prediction) Ressourcenkonflikte (Structural Hazards) Bei bestimmten Befehlskombinationen ist es unter Umständen möglich, daß ein Teilwerk seine Arbeit wiederholen muss. Solche Ressourcenkonflikte treten dann auf, wenn nicht jeder Teilphase völlig unabhängige Teilwerke zugeordnet sind. Ein Beispiel ist z.B. ein zeitgleicher Lesezugriff eines LOAD/STORE Befehles, welcher sich zwangsweise mit einem eventuellen MEM ACCESS eines anderen Befehles überschneidet. Abhilfe können hier Dual-Port RAM, Havard-Architektur oder getrennte Code- und Datencaches schaffen. Welche drei verschiedenen Datenabhängigkeiten gibt es? RAW, WAW und WAR-Konflikte sind Datenabnhänigkeiten, welche in Pipelines auftreten können. Dabei ist das RAW-Problem für Pipelines typisch. WAR Konflikte treten eher bei Out-Of-Order Execution auf. Um Read-After-Write Konflikte aufzulösen, gibt es verschiedene Ansätze wie Softwarelösungen ( Compileroptimierung), Scoreboarding (zentrale Steuerlogik) und Forwarding (zusätzlicher Datenpfad). Was ist Forwarding? Beim Forwarding wird ein Bypass eingerichtet, welcher ein Ergebniss einer Operation schon einem Folgebefehl zur Verfügung stellt, bevor es überhaupt in ein Register geschrieben wurde. Aber trotz Load-Forwarding hat ein Ladebefehl eine Verzögerung, welche nicht gänzlich eliminiert werden kann. In diesem Fall kann die Delayed-Load Technik oder auch eine Befehlsumordnung Anhilfe schaffen. Was ist die Delayed Load-Technik? Bei der Delayed Load-Technik wird die Verzögerung nach einem LOAD Befehl als architektonisches Merkmal angesehn und den Compilerbauern offengelegt. Diese können nun durch Befehlsumordnungen versuchen, nach einem LOAD-Befehl einen datenunabhängigen Befehl einzufügen, um den Slot zu füllen. Zusammenfassung Pipelining Pipelines werden in allen modernen CPUs benutzt. Die UltraSparc2 hat neun und der P2 zwölf Stufen. Der Intel Pentium Itanium weißt eine 20 stufige Superpinepline (pipeline in der sich einzelne Stufen überlappen können) auf! Pipes werden heutzutage in Kombination mit der Superskalartechnik verwendet, um höchste Effizienz und Parallelverarbeitung gewährleisten zu können. Die fünf grundlegenden Stufen einer einfachen Pipeline sind IF,ID,EX,MEM und WB. Takte T = Befehle + (Pipestufen - 1) Folgende Abhängigkeiten verhindern, dass die CPI auf eins gehen: Strucual Hazards bzw. Ressourcenkonflikte IF und MEM wollen gleichzeitig auf Speicher lesend oder schreibend zugreifen. Das geht nicht, außer bei Dual-Port-RAM, welcher aber sehr teuer ist. Dieses Problem tritt aber bei modernen CPU's kaum noch auf, da eh intern eine Havard-ähnliche Architektur mit getrenntem Befehls- und Datencache gearbeitet wird. Data Hazards bzw. Datenabhängigkeiten Ein Folgebefehl wartet auf das Writeback der darüber liegenden Pipe, da er von diesem Befehl abhängig ist. Dies kann durch Nops bzw. Stalls ineffizient gelöst werden. Besser der Programmierer oder der Compiler löst diese Abhängigkeiten durch eine clevere Umordnung der Befehlsfolge auf. Es gibt aber noch eine andere Möglichkeit, welche aber hardwareseitig unterstützt werden muss. (VLIW, Superskalar) Forwarding Beim Forwarding werden Ergebnisse, sobald sie vorliegen an die nächste Stufe weitergereicht und nicht erst auf das Write Back gewartet. In anderen Worten: Das Ergebnis der ALU wird dieser sofort wieder eingespeist. Control Hazards bzw. Sprungverzögerungen Sprungergebnisse stehen erst in der Write Back Phase an. Moderne Prozessoren haben aber schon in der Fetch/Decode-Einheit eine Logik, welche die Zieladresse des Sprunges berechnet. Eine andere Möglichkeit ist die des spekulativen Ausführens. Hier tritt aber das Problem auf, dass viel Aufwand bei falscher Spekulation getrieben werden muss. Was ist der Unterschied zwischen echten und unechten Datenabhängigkeiten? Echte Datenabhängigkeiten sind RAW-Konflikte, bei dem ein Befehl auf die Beendigung eines Anderen warten muss, da er das Ergebnis als Operand benötigt. Unechte Datenabhängigkeit sind Abhängigkeiten, welche nur durch Namensabhängigkeit entstehen. Es gibt zwei Arten unechter Datenabhängigkeit: Antidependence sind WAR-Konflikte, welche entstehen, wenn ein Folgebefehl auf ein Register schreiben möchte, das noch von einem Anderen benutzt wird. Output Dependece sind WAW-Konflikte, welche entstehen, wenn mehrere Befehle auf ein und das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. D
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itlgt, um langsame Hauptspeicherzugriffe zu minimieren. Was ist Voraussetzung für Pipelining? Die Befehlsverarbeitungsphase muss sich in mehrere voneinander unabhängige Phasen unterteilen lassen. <span>Die einfachste Form einer Pipeline ist die 5-stufige mit folgenden Phasen: Befehl holen Befehl dekodieren Befehl ausführen Auf Speicher zugreifen Ergebnis in Register schreiben Moderene CPU's haben weitaus komplexere Pipelines, in denen die einzelnen Stufen wiederrum in mehrere sich überlappende Phasen aufgeteilt werden. Der allgemeine Aufbau einer (fünfstufig
Original toplevel document
Grundprinzipien der Rechnerarchitektureinen Verweis auf die Nächste enthalten. Sprünge sind einfach möglich. Angewandt wird dies in Form von Opcodes, welche nichts anderes als Adressen auf Mikroinstruktionen im Steuerspeicher sind. <span>Kapitel 6 - Pipelining Wozu dient Pipelining? Pipelining soll es ermöglichen Befehle überlappt auszuführen. Dazu sind ein einheitliches Befehlsformat fester Länge Grundlage. Deshalb werden werden nur auf Register getätigt. Für Speicheroperationen wird die LOAD / STORE Philosophie verfolgt, um langsame Hauptspeicherzugriffe zu minimieren. Was ist Voraussetzung für Pipelining? Die Befehlsverarbeitungsphase muss sich in mehrere voneinander unabhängige Phasen unterteilen lassen. Die einfachste Form einer Pipeline ist die 5-stufige mit folgenden Phasen: Befehl holen Befehl dekodieren Befehl ausführen Auf Speicher zugreifen Ergebnis in Register schreiben Moderene CPU's haben weitaus komplexere Pipelines, in denen die einzelnen Stufen wiederrum in mehrere sich überlappende Phasen aufgeteilt werden. Der allgemeine Aufbau einer (fünfstufigen) Pipeline Um Parallelität in der Befehlsausführungsphase zu erreichen, wird der Datenpfad so konstruiert, daß folgende (hier fünf) Phasen unabhänig voneinander arbeiten können. Nur so ist es möglich eine verzahnte Abarbeitung mehrerer Befehle zu erreichen. Abb.: Die Piplelinestufen Somit wird ,nachdem eine Pipeline gefüllt ist, im Optimalfall pro Takt ein Befehl fertig. (CPI = 1) Welche Pipeline-Konflikte müssen behandelt werden? Datenabhängigkeiten (Data Hazards) Sind logische Abhängigkeiten, welche eine verzögerte Abarbeitung erfordern, weil z.B. ein Folgebefehl auf ein Ergebnis eines anderen Befehles warten muss. Jump- / Branchverzögerungen (Control Hazards) Bei Sprungbefehlen liegt oft das Sprungziel nach der Dekodieung noch nicht fest. Somit müssen Techniken eingesetzt werden um diese Wartezeiten zu minimieren. (Branch Prediction) Ressourcenkonflikte (Structural Hazards) Bei bestimmten Befehlskombinationen ist es unter Umständen möglich, daß ein Teilwerk seine Arbeit wiederholen muss. Solche Ressourcenkonflikte treten dann auf, wenn nicht jeder Teilphase völlig unabhängige Teilwerke zugeordnet sind. Ein Beispiel ist z.B. ein zeitgleicher Lesezugriff eines LOAD/STORE Befehles, welcher sich zwangsweise mit einem eventuellen MEM ACCESS eines anderen Befehles überschneidet. Abhilfe können hier Dual-Port RAM, Havard-Architektur oder getrennte Code- und Datencaches schaffen. Welche drei verschiedenen Datenabhängigkeiten gibt es? RAW, WAW und WAR-Konflikte sind Datenabnhänigkeiten, welche in Pipelines auftreten können. Dabei ist das RAW-Problem für Pipelines typisch. WAR Konflikte treten eher bei Out-Of-Order Execution auf. Um Read-After-Write Konflikte aufzulösen, gibt es verschiedene Ansätze wie Softwarelösungen ( Compileroptimierung), Scoreboarding (zentrale Steuerlogik) und Forwarding (zusätzlicher Datenpfad). Was ist Forwarding? Beim Forwarding wird ein Bypass eingerichtet, welcher ein Ergebniss einer Operation schon einem Folgebefehl zur Verfügung stellt, bevor es überhaupt in ein Register geschrieben wurde. Aber trotz Load-Forwarding hat ein Ladebefehl eine Verzögerung, welche nicht gänzlich eliminiert werden kann. In diesem Fall kann die Delayed-Load Technik oder auch eine Befehlsumordnung Anhilfe schaffen. Was ist die Delayed Load-Technik? Bei der Delayed Load-Technik wird die Verzögerung nach einem LOAD Befehl als architektonisches Merkmal angesehn und den Compilerbauern offengelegt. Diese können nun durch Befehlsumordnungen versuchen, nach einem LOAD-Befehl einen datenunabhängigen Befehl einzufügen, um den Slot zu füllen. Zusammenfassung Pipelining Pipelines werden in allen modernen CPUs benutzt. Die UltraSparc2 hat neun und der P2 zwölf Stufen. Der Intel Pentium Itanium weißt eine 20 stufige Superpinepline (pipeline in der sich einzelne Stufen überlappen können) auf! Pipes werden heutzutage in Kombination mit der Superskalartechnik verwendet, um höchste Effizienz und Parallelverarbeitung gewährleisten zu können. Die fünf grundlegenden Stufen einer einfachen Pipeline sind IF,ID,EX,MEM und WB. Takte T = Befehle + (Pipestufen - 1) Folgende Abhängigkeiten verhindern, dass die CPI auf eins gehen: Strucual Hazards bzw. Ressourcenkonflikte IF und MEM wollen gleichzeitig auf Speicher lesend oder schreibend zugreifen. Das geht nicht, außer bei Dual-Port-RAM, welcher aber sehr teuer ist. Dieses Problem tritt aber bei modernen CPU's kaum noch auf, da eh intern eine Havard-ähnliche Architektur mit getrenntem Befehls- und Datencache gearbeitet wird. Data Hazards bzw. Datenabhängigkeiten Ein Folgebefehl wartet auf das Writeback der darüber liegenden Pipe, da er von diesem Befehl abhängig ist. Dies kann durch Nops bzw. Stalls ineffizient gelöst werden. Besser der Programmierer oder der Compiler löst diese Abhängigkeiten durch eine clevere Umordnung der Befehlsfolge auf. Es gibt aber noch eine andere Möglichkeit, welche aber hardwareseitig unterstützt werden muss. (VLIW, Superskalar) Forwarding Beim Forwarding werden Ergebnisse, sobald sie vorliegen an die nächste Stufe weitergereicht und nicht erst auf das Write Back gewartet. In anderen Worten: Das Ergebnis der ALU wird dieser sofort wieder eingespeist. Control Hazards bzw. Sprungverzögerungen Sprungergebnisse stehen erst in der Write Back Phase an. Moderne Prozessoren haben aber schon in der Fetch/Decode-Einheit eine Logik, welche die Zieladresse des Sprunges berechnet. Eine andere Möglichkeit ist die des spekulativen Ausführens. Hier tritt aber das Problem auf, dass viel Aufwand bei falscher Spekulation getrieben werden muss. Was ist der Unterschied zwischen echten und unechten Datenabhängigkeiten? Echte Datenabhängigkeiten sind RAW-Konflikte, bei dem ein Befehl auf die Beendigung eines Anderen warten muss, da er das Ergebnis als Operand benötigt. Unechte Datenabhängigkeit sind Abhängigkeiten, welche nur durch Namensabhängigkeit entstehen. Es gibt zwei Arten unechter Datenabhängigkeit: Antidependence sind WAR-Konflikte, welche entstehen, wenn ein Folgebefehl auf ein Register schreiben möchte, das noch von einem Anderen benutzt wird. Output Dependece sind WAW-Konflikte, welche entstehen, wenn mehrere Befehle auf ein und das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. D
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itso konstruiert, daß folgende (hier fünf) Phasen unabhänig voneinander arbeiten können. Nur so ist es möglich eine verzahnte Abarbeitung mehrerer Befehle zu erreichen. Abb.: Die Piplelinestufen <span>Somit wird ,nachdem eine Pipeline gefüllt ist, im Optimalfall pro Takt ein Befehl fertig. (CPI = 1) Welche Pipeline-Konflikte müssen behandelt werden? Datenabhängigkeiten (Data Hazards) Sind logische Abhängigkeiten, welche eine verzögerte Abarbeitung erfordern, weil z.B. ein Folgebefe
Original toplevel document
Grundprinzipien der Rechnerarchitektureinen Verweis auf die Nächste enthalten. Sprünge sind einfach möglich. Angewandt wird dies in Form von Opcodes, welche nichts anderes als Adressen auf Mikroinstruktionen im Steuerspeicher sind. <span>Kapitel 6 - Pipelining Wozu dient Pipelining? Pipelining soll es ermöglichen Befehle überlappt auszuführen. Dazu sind ein einheitliches Befehlsformat fester Länge Grundlage. Deshalb werden werden nur auf Register getätigt. Für Speicheroperationen wird die LOAD / STORE Philosophie verfolgt, um langsame Hauptspeicherzugriffe zu minimieren. Was ist Voraussetzung für Pipelining? Die Befehlsverarbeitungsphase muss sich in mehrere voneinander unabhängige Phasen unterteilen lassen. Die einfachste Form einer Pipeline ist die 5-stufige mit folgenden Phasen: Befehl holen Befehl dekodieren Befehl ausführen Auf Speicher zugreifen Ergebnis in Register schreiben Moderene CPU's haben weitaus komplexere Pipelines, in denen die einzelnen Stufen wiederrum in mehrere sich überlappende Phasen aufgeteilt werden. Der allgemeine Aufbau einer (fünfstufigen) Pipeline Um Parallelität in der Befehlsausführungsphase zu erreichen, wird der Datenpfad so konstruiert, daß folgende (hier fünf) Phasen unabhänig voneinander arbeiten können. Nur so ist es möglich eine verzahnte Abarbeitung mehrerer Befehle zu erreichen. Abb.: Die Piplelinestufen Somit wird ,nachdem eine Pipeline gefüllt ist, im Optimalfall pro Takt ein Befehl fertig. (CPI = 1) Welche Pipeline-Konflikte müssen behandelt werden? Datenabhängigkeiten (Data Hazards) Sind logische Abhängigkeiten, welche eine verzögerte Abarbeitung erfordern, weil z.B. ein Folgebefehl auf ein Ergebnis eines anderen Befehles warten muss. Jump- / Branchverzögerungen (Control Hazards) Bei Sprungbefehlen liegt oft das Sprungziel nach der Dekodieung noch nicht fest. Somit müssen Techniken eingesetzt werden um diese Wartezeiten zu minimieren. (Branch Prediction) Ressourcenkonflikte (Structural Hazards) Bei bestimmten Befehlskombinationen ist es unter Umständen möglich, daß ein Teilwerk seine Arbeit wiederholen muss. Solche Ressourcenkonflikte treten dann auf, wenn nicht jeder Teilphase völlig unabhängige Teilwerke zugeordnet sind. Ein Beispiel ist z.B. ein zeitgleicher Lesezugriff eines LOAD/STORE Befehles, welcher sich zwangsweise mit einem eventuellen MEM ACCESS eines anderen Befehles überschneidet. Abhilfe können hier Dual-Port RAM, Havard-Architektur oder getrennte Code- und Datencaches schaffen. Welche drei verschiedenen Datenabhängigkeiten gibt es? RAW, WAW und WAR-Konflikte sind Datenabnhänigkeiten, welche in Pipelines auftreten können. Dabei ist das RAW-Problem für Pipelines typisch. WAR Konflikte treten eher bei Out-Of-Order Execution auf. Um Read-After-Write Konflikte aufzulösen, gibt es verschiedene Ansätze wie Softwarelösungen ( Compileroptimierung), Scoreboarding (zentrale Steuerlogik) und Forwarding (zusätzlicher Datenpfad). Was ist Forwarding? Beim Forwarding wird ein Bypass eingerichtet, welcher ein Ergebniss einer Operation schon einem Folgebefehl zur Verfügung stellt, bevor es überhaupt in ein Register geschrieben wurde. Aber trotz Load-Forwarding hat ein Ladebefehl eine Verzögerung, welche nicht gänzlich eliminiert werden kann. In diesem Fall kann die Delayed-Load Technik oder auch eine Befehlsumordnung Anhilfe schaffen. Was ist die Delayed Load-Technik? Bei der Delayed Load-Technik wird die Verzögerung nach einem LOAD Befehl als architektonisches Merkmal angesehn und den Compilerbauern offengelegt. Diese können nun durch Befehlsumordnungen versuchen, nach einem LOAD-Befehl einen datenunabhängigen Befehl einzufügen, um den Slot zu füllen. Zusammenfassung Pipelining Pipelines werden in allen modernen CPUs benutzt. Die UltraSparc2 hat neun und der P2 zwölf Stufen. Der Intel Pentium Itanium weißt eine 20 stufige Superpinepline (pipeline in der sich einzelne Stufen überlappen können) auf! Pipes werden heutzutage in Kombination mit der Superskalartechnik verwendet, um höchste Effizienz und Parallelverarbeitung gewährleisten zu können. Die fünf grundlegenden Stufen einer einfachen Pipeline sind IF,ID,EX,MEM und WB. Takte T = Befehle + (Pipestufen - 1) Folgende Abhängigkeiten verhindern, dass die CPI auf eins gehen: Strucual Hazards bzw. Ressourcenkonflikte IF und MEM wollen gleichzeitig auf Speicher lesend oder schreibend zugreifen. Das geht nicht, außer bei Dual-Port-RAM, welcher aber sehr teuer ist. Dieses Problem tritt aber bei modernen CPU's kaum noch auf, da eh intern eine Havard-ähnliche Architektur mit getrenntem Befehls- und Datencache gearbeitet wird. Data Hazards bzw. Datenabhängigkeiten Ein Folgebefehl wartet auf das Writeback der darüber liegenden Pipe, da er von diesem Befehl abhängig ist. Dies kann durch Nops bzw. Stalls ineffizient gelöst werden. Besser der Programmierer oder der Compiler löst diese Abhängigkeiten durch eine clevere Umordnung der Befehlsfolge auf. Es gibt aber noch eine andere Möglichkeit, welche aber hardwareseitig unterstützt werden muss. (VLIW, Superskalar) Forwarding Beim Forwarding werden Ergebnisse, sobald sie vorliegen an die nächste Stufe weitergereicht und nicht erst auf das Write Back gewartet. In anderen Worten: Das Ergebnis der ALU wird dieser sofort wieder eingespeist. Control Hazards bzw. Sprungverzögerungen Sprungergebnisse stehen erst in der Write Back Phase an. Moderne Prozessoren haben aber schon in der Fetch/Decode-Einheit eine Logik, welche die Zieladresse des Sprunges berechnet. Eine andere Möglichkeit ist die des spekulativen Ausführens. Hier tritt aber das Problem auf, dass viel Aufwand bei falscher Spekulation getrieben werden muss. Was ist der Unterschied zwischen echten und unechten Datenabhängigkeiten? Echte Datenabhängigkeiten sind RAW-Konflikte, bei dem ein Befehl auf die Beendigung eines Anderen warten muss, da er das Ergebnis als Operand benötigt. Unechte Datenabhängigkeit sind Abhängigkeiten, welche nur durch Namensabhängigkeit entstehen. Es gibt zwei Arten unechter Datenabhängigkeit: Antidependence sind WAR-Konflikte, welche entstehen, wenn ein Folgebefehl auf ein Register schreiben möchte, das noch von einem Anderen benutzt wird. Output Dependece sind WAW-Konflikte, welche entstehen, wenn mehrere Befehle auf ein und das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. D
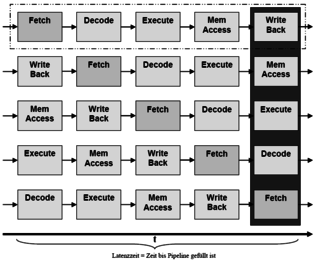
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open iteicher zugreifen Ergebnis in Register schreiben Moderene CPU's haben weitaus komplexere Pipelines, in denen die einzelnen Stufen wiederrum in mehrere sich überlappende Phasen aufgeteilt werden. <span>Der allgemeine Aufbau einer (fünfstufigen) Pipeline Um Parallelität in der Befehlsausführungsphase zu erreichen, wird der Datenpfad so konstruiert, daß folgende (hier fünf) Phasen unabhänig voneinander arbeiten können. Nur so ist es möglich eine verzahnte Abarbeitung mehrerer Befehle zu erreichen. Abb.: Die Piplelinestufen Somit wird ,nachdem eine Pipeline gefüllt ist, im Optimalfall pro Takt ein Befehl fertig. (CPI = 1) Welche Pipeline-Konflikte müssen behandelt werden? Datenabhängigkeiten (Data Hazards)
Original toplevel document
Grundprinzipien der Rechnerarchitektureinen Verweis auf die Nächste enthalten. Sprünge sind einfach möglich. Angewandt wird dies in Form von Opcodes, welche nichts anderes als Adressen auf Mikroinstruktionen im Steuerspeicher sind. <span>Kapitel 6 - Pipelining Wozu dient Pipelining? Pipelining soll es ermöglichen Befehle überlappt auszuführen. Dazu sind ein einheitliches Befehlsformat fester Länge Grundlage. Deshalb werden werden nur auf Register getätigt. Für Speicheroperationen wird die LOAD / STORE Philosophie verfolgt, um langsame Hauptspeicherzugriffe zu minimieren. Was ist Voraussetzung für Pipelining? Die Befehlsverarbeitungsphase muss sich in mehrere voneinander unabhängige Phasen unterteilen lassen. Die einfachste Form einer Pipeline ist die 5-stufige mit folgenden Phasen: Befehl holen Befehl dekodieren Befehl ausführen Auf Speicher zugreifen Ergebnis in Register schreiben Moderene CPU's haben weitaus komplexere Pipelines, in denen die einzelnen Stufen wiederrum in mehrere sich überlappende Phasen aufgeteilt werden. Der allgemeine Aufbau einer (fünfstufigen) Pipeline Um Parallelität in der Befehlsausführungsphase zu erreichen, wird der Datenpfad so konstruiert, daß folgende (hier fünf) Phasen unabhänig voneinander arbeiten können. Nur so ist es möglich eine verzahnte Abarbeitung mehrerer Befehle zu erreichen. Abb.: Die Piplelinestufen Somit wird ,nachdem eine Pipeline gefüllt ist, im Optimalfall pro Takt ein Befehl fertig. (CPI = 1) Welche Pipeline-Konflikte müssen behandelt werden? Datenabhängigkeiten (Data Hazards) Sind logische Abhängigkeiten, welche eine verzögerte Abarbeitung erfordern, weil z.B. ein Folgebefehl auf ein Ergebnis eines anderen Befehles warten muss. Jump- / Branchverzögerungen (Control Hazards) Bei Sprungbefehlen liegt oft das Sprungziel nach der Dekodieung noch nicht fest. Somit müssen Techniken eingesetzt werden um diese Wartezeiten zu minimieren. (Branch Prediction) Ressourcenkonflikte (Structural Hazards) Bei bestimmten Befehlskombinationen ist es unter Umständen möglich, daß ein Teilwerk seine Arbeit wiederholen muss. Solche Ressourcenkonflikte treten dann auf, wenn nicht jeder Teilphase völlig unabhängige Teilwerke zugeordnet sind. Ein Beispiel ist z.B. ein zeitgleicher Lesezugriff eines LOAD/STORE Befehles, welcher sich zwangsweise mit einem eventuellen MEM ACCESS eines anderen Befehles überschneidet. Abhilfe können hier Dual-Port RAM, Havard-Architektur oder getrennte Code- und Datencaches schaffen. Welche drei verschiedenen Datenabhängigkeiten gibt es? RAW, WAW und WAR-Konflikte sind Datenabnhänigkeiten, welche in Pipelines auftreten können. Dabei ist das RAW-Problem für Pipelines typisch. WAR Konflikte treten eher bei Out-Of-Order Execution auf. Um Read-After-Write Konflikte aufzulösen, gibt es verschiedene Ansätze wie Softwarelösungen ( Compileroptimierung), Scoreboarding (zentrale Steuerlogik) und Forwarding (zusätzlicher Datenpfad). Was ist Forwarding? Beim Forwarding wird ein Bypass eingerichtet, welcher ein Ergebniss einer Operation schon einem Folgebefehl zur Verfügung stellt, bevor es überhaupt in ein Register geschrieben wurde. Aber trotz Load-Forwarding hat ein Ladebefehl eine Verzögerung, welche nicht gänzlich eliminiert werden kann. In diesem Fall kann die Delayed-Load Technik oder auch eine Befehlsumordnung Anhilfe schaffen. Was ist die Delayed Load-Technik? Bei der Delayed Load-Technik wird die Verzögerung nach einem LOAD Befehl als architektonisches Merkmal angesehn und den Compilerbauern offengelegt. Diese können nun durch Befehlsumordnungen versuchen, nach einem LOAD-Befehl einen datenunabhängigen Befehl einzufügen, um den Slot zu füllen. Zusammenfassung Pipelining Pipelines werden in allen modernen CPUs benutzt. Die UltraSparc2 hat neun und der P2 zwölf Stufen. Der Intel Pentium Itanium weißt eine 20 stufige Superpinepline (pipeline in der sich einzelne Stufen überlappen können) auf! Pipes werden heutzutage in Kombination mit der Superskalartechnik verwendet, um höchste Effizienz und Parallelverarbeitung gewährleisten zu können. Die fünf grundlegenden Stufen einer einfachen Pipeline sind IF,ID,EX,MEM und WB. Takte T = Befehle + (Pipestufen - 1) Folgende Abhängigkeiten verhindern, dass die CPI auf eins gehen: Strucual Hazards bzw. Ressourcenkonflikte IF und MEM wollen gleichzeitig auf Speicher lesend oder schreibend zugreifen. Das geht nicht, außer bei Dual-Port-RAM, welcher aber sehr teuer ist. Dieses Problem tritt aber bei modernen CPU's kaum noch auf, da eh intern eine Havard-ähnliche Architektur mit getrenntem Befehls- und Datencache gearbeitet wird. Data Hazards bzw. Datenabhängigkeiten Ein Folgebefehl wartet auf das Writeback der darüber liegenden Pipe, da er von diesem Befehl abhängig ist. Dies kann durch Nops bzw. Stalls ineffizient gelöst werden. Besser der Programmierer oder der Compiler löst diese Abhängigkeiten durch eine clevere Umordnung der Befehlsfolge auf. Es gibt aber noch eine andere Möglichkeit, welche aber hardwareseitig unterstützt werden muss. (VLIW, Superskalar) Forwarding Beim Forwarding werden Ergebnisse, sobald sie vorliegen an die nächste Stufe weitergereicht und nicht erst auf das Write Back gewartet. In anderen Worten: Das Ergebnis der ALU wird dieser sofort wieder eingespeist. Control Hazards bzw. Sprungverzögerungen Sprungergebnisse stehen erst in der Write Back Phase an. Moderne Prozessoren haben aber schon in der Fetch/Decode-Einheit eine Logik, welche die Zieladresse des Sprunges berechnet. Eine andere Möglichkeit ist die des spekulativen Ausführens. Hier tritt aber das Problem auf, dass viel Aufwand bei falscher Spekulation getrieben werden muss. Was ist der Unterschied zwischen echten und unechten Datenabhängigkeiten? Echte Datenabhängigkeiten sind RAW-Konflikte, bei dem ein Befehl auf die Beendigung eines Anderen warten muss, da er das Ergebnis als Operand benötigt. Unechte Datenabhängigkeit sind Abhängigkeiten, welche nur durch Namensabhängigkeit entstehen. Es gibt zwei Arten unechter Datenabhängigkeit: Antidependence sind WAR-Konflikte, welche entstehen, wenn ein Folgebefehl auf ein Register schreiben möchte, das noch von einem Anderen benutzt wird. Output Dependece sind WAW-Konflikte, welche entstehen, wenn mehrere Befehle auf ein und das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. D
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itle zu erreichen. Abb.: Die Piplelinestufen Somit wird ,nachdem eine Pipeline gefüllt ist, im Optimalfall pro Takt ein Befehl fertig. (CPI = 1) Welche Pipeline-Konflikte müssen behandelt werden? <span>Datenabhängigkeiten (Data Hazards) Sind logische Abhängigkeiten, welche eine verzögerte Abarbeitung erfordern, weil z.B. ein Folgebefehl auf ein Ergebnis eines anderen Befehles warten muss. Jump- / Branchverzögerungen (Control Hazards) Bei Sprungbefehlen liegt oft das Sprungziel nach der Dekodieung noch nicht fest. Somit müssen Techniken eingesetzt werden um diese Wartezei
Original toplevel document
Grundprinzipien der Rechnerarchitektureinen Verweis auf die Nächste enthalten. Sprünge sind einfach möglich. Angewandt wird dies in Form von Opcodes, welche nichts anderes als Adressen auf Mikroinstruktionen im Steuerspeicher sind. <span>Kapitel 6 - Pipelining Wozu dient Pipelining? Pipelining soll es ermöglichen Befehle überlappt auszuführen. Dazu sind ein einheitliches Befehlsformat fester Länge Grundlage. Deshalb werden werden nur auf Register getätigt. Für Speicheroperationen wird die LOAD / STORE Philosophie verfolgt, um langsame Hauptspeicherzugriffe zu minimieren. Was ist Voraussetzung für Pipelining? Die Befehlsverarbeitungsphase muss sich in mehrere voneinander unabhängige Phasen unterteilen lassen. Die einfachste Form einer Pipeline ist die 5-stufige mit folgenden Phasen: Befehl holen Befehl dekodieren Befehl ausführen Auf Speicher zugreifen Ergebnis in Register schreiben Moderene CPU's haben weitaus komplexere Pipelines, in denen die einzelnen Stufen wiederrum in mehrere sich überlappende Phasen aufgeteilt werden. Der allgemeine Aufbau einer (fünfstufigen) Pipeline Um Parallelität in der Befehlsausführungsphase zu erreichen, wird der Datenpfad so konstruiert, daß folgende (hier fünf) Phasen unabhänig voneinander arbeiten können. Nur so ist es möglich eine verzahnte Abarbeitung mehrerer Befehle zu erreichen. Abb.: Die Piplelinestufen Somit wird ,nachdem eine Pipeline gefüllt ist, im Optimalfall pro Takt ein Befehl fertig. (CPI = 1) Welche Pipeline-Konflikte müssen behandelt werden? Datenabhängigkeiten (Data Hazards) Sind logische Abhängigkeiten, welche eine verzögerte Abarbeitung erfordern, weil z.B. ein Folgebefehl auf ein Ergebnis eines anderen Befehles warten muss. Jump- / Branchverzögerungen (Control Hazards) Bei Sprungbefehlen liegt oft das Sprungziel nach der Dekodieung noch nicht fest. Somit müssen Techniken eingesetzt werden um diese Wartezeiten zu minimieren. (Branch Prediction) Ressourcenkonflikte (Structural Hazards) Bei bestimmten Befehlskombinationen ist es unter Umständen möglich, daß ein Teilwerk seine Arbeit wiederholen muss. Solche Ressourcenkonflikte treten dann auf, wenn nicht jeder Teilphase völlig unabhängige Teilwerke zugeordnet sind. Ein Beispiel ist z.B. ein zeitgleicher Lesezugriff eines LOAD/STORE Befehles, welcher sich zwangsweise mit einem eventuellen MEM ACCESS eines anderen Befehles überschneidet. Abhilfe können hier Dual-Port RAM, Havard-Architektur oder getrennte Code- und Datencaches schaffen. Welche drei verschiedenen Datenabhängigkeiten gibt es? RAW, WAW und WAR-Konflikte sind Datenabnhänigkeiten, welche in Pipelines auftreten können. Dabei ist das RAW-Problem für Pipelines typisch. WAR Konflikte treten eher bei Out-Of-Order Execution auf. Um Read-After-Write Konflikte aufzulösen, gibt es verschiedene Ansätze wie Softwarelösungen ( Compileroptimierung), Scoreboarding (zentrale Steuerlogik) und Forwarding (zusätzlicher Datenpfad). Was ist Forwarding? Beim Forwarding wird ein Bypass eingerichtet, welcher ein Ergebniss einer Operation schon einem Folgebefehl zur Verfügung stellt, bevor es überhaupt in ein Register geschrieben wurde. Aber trotz Load-Forwarding hat ein Ladebefehl eine Verzögerung, welche nicht gänzlich eliminiert werden kann. In diesem Fall kann die Delayed-Load Technik oder auch eine Befehlsumordnung Anhilfe schaffen. Was ist die Delayed Load-Technik? Bei der Delayed Load-Technik wird die Verzögerung nach einem LOAD Befehl als architektonisches Merkmal angesehn und den Compilerbauern offengelegt. Diese können nun durch Befehlsumordnungen versuchen, nach einem LOAD-Befehl einen datenunabhängigen Befehl einzufügen, um den Slot zu füllen. Zusammenfassung Pipelining Pipelines werden in allen modernen CPUs benutzt. Die UltraSparc2 hat neun und der P2 zwölf Stufen. Der Intel Pentium Itanium weißt eine 20 stufige Superpinepline (pipeline in der sich einzelne Stufen überlappen können) auf! Pipes werden heutzutage in Kombination mit der Superskalartechnik verwendet, um höchste Effizienz und Parallelverarbeitung gewährleisten zu können. Die fünf grundlegenden Stufen einer einfachen Pipeline sind IF,ID,EX,MEM und WB. Takte T = Befehle + (Pipestufen - 1) Folgende Abhängigkeiten verhindern, dass die CPI auf eins gehen: Strucual Hazards bzw. Ressourcenkonflikte IF und MEM wollen gleichzeitig auf Speicher lesend oder schreibend zugreifen. Das geht nicht, außer bei Dual-Port-RAM, welcher aber sehr teuer ist. Dieses Problem tritt aber bei modernen CPU's kaum noch auf, da eh intern eine Havard-ähnliche Architektur mit getrenntem Befehls- und Datencache gearbeitet wird. Data Hazards bzw. Datenabhängigkeiten Ein Folgebefehl wartet auf das Writeback der darüber liegenden Pipe, da er von diesem Befehl abhängig ist. Dies kann durch Nops bzw. Stalls ineffizient gelöst werden. Besser der Programmierer oder der Compiler löst diese Abhängigkeiten durch eine clevere Umordnung der Befehlsfolge auf. Es gibt aber noch eine andere Möglichkeit, welche aber hardwareseitig unterstützt werden muss. (VLIW, Superskalar) Forwarding Beim Forwarding werden Ergebnisse, sobald sie vorliegen an die nächste Stufe weitergereicht und nicht erst auf das Write Back gewartet. In anderen Worten: Das Ergebnis der ALU wird dieser sofort wieder eingespeist. Control Hazards bzw. Sprungverzögerungen Sprungergebnisse stehen erst in der Write Back Phase an. Moderne Prozessoren haben aber schon in der Fetch/Decode-Einheit eine Logik, welche die Zieladresse des Sprunges berechnet. Eine andere Möglichkeit ist die des spekulativen Ausführens. Hier tritt aber das Problem auf, dass viel Aufwand bei falscher Spekulation getrieben werden muss. Was ist der Unterschied zwischen echten und unechten Datenabhängigkeiten? Echte Datenabhängigkeiten sind RAW-Konflikte, bei dem ein Befehl auf die Beendigung eines Anderen warten muss, da er das Ergebnis als Operand benötigt. Unechte Datenabhängigkeit sind Abhängigkeiten, welche nur durch Namensabhängigkeit entstehen. Es gibt zwei Arten unechter Datenabhängigkeit: Antidependence sind WAR-Konflikte, welche entstehen, wenn ein Folgebefehl auf ein Register schreiben möchte, das noch von einem Anderen benutzt wird. Output Dependece sind WAW-Konflikte, welche entstehen, wenn mehrere Befehle auf ein und das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. D
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open iten? Datenabhängigkeiten (Data Hazards) Sind logische Abhängigkeiten, welche eine verzögerte Abarbeitung erfordern, weil z.B. ein Folgebefehl auf ein Ergebnis eines anderen Befehles warten muss. <span>Jump- / Branchverzögerungen (Control Hazards) Bei Sprungbefehlen liegt oft das Sprungziel nach der Dekodieung noch nicht fest. Somit müssen Techniken eingesetzt werden um diese Wartezeiten zu minimieren. (Branch Prediction) Ressourcenkonflikte (Structural Hazards) Bei bestimmten Befehlskombinationen ist es unter Umständen möglich, daß ein Teilwerk seine Arbeit wiederholen muss. Solche Ressourcenkonflikte t
Original toplevel document
Grundprinzipien der Rechnerarchitektureinen Verweis auf die Nächste enthalten. Sprünge sind einfach möglich. Angewandt wird dies in Form von Opcodes, welche nichts anderes als Adressen auf Mikroinstruktionen im Steuerspeicher sind. <span>Kapitel 6 - Pipelining Wozu dient Pipelining? Pipelining soll es ermöglichen Befehle überlappt auszuführen. Dazu sind ein einheitliches Befehlsformat fester Länge Grundlage. Deshalb werden werden nur auf Register getätigt. Für Speicheroperationen wird die LOAD / STORE Philosophie verfolgt, um langsame Hauptspeicherzugriffe zu minimieren. Was ist Voraussetzung für Pipelining? Die Befehlsverarbeitungsphase muss sich in mehrere voneinander unabhängige Phasen unterteilen lassen. Die einfachste Form einer Pipeline ist die 5-stufige mit folgenden Phasen: Befehl holen Befehl dekodieren Befehl ausführen Auf Speicher zugreifen Ergebnis in Register schreiben Moderene CPU's haben weitaus komplexere Pipelines, in denen die einzelnen Stufen wiederrum in mehrere sich überlappende Phasen aufgeteilt werden. Der allgemeine Aufbau einer (fünfstufigen) Pipeline Um Parallelität in der Befehlsausführungsphase zu erreichen, wird der Datenpfad so konstruiert, daß folgende (hier fünf) Phasen unabhänig voneinander arbeiten können. Nur so ist es möglich eine verzahnte Abarbeitung mehrerer Befehle zu erreichen. Abb.: Die Piplelinestufen Somit wird ,nachdem eine Pipeline gefüllt ist, im Optimalfall pro Takt ein Befehl fertig. (CPI = 1) Welche Pipeline-Konflikte müssen behandelt werden? Datenabhängigkeiten (Data Hazards) Sind logische Abhängigkeiten, welche eine verzögerte Abarbeitung erfordern, weil z.B. ein Folgebefehl auf ein Ergebnis eines anderen Befehles warten muss. Jump- / Branchverzögerungen (Control Hazards) Bei Sprungbefehlen liegt oft das Sprungziel nach der Dekodieung noch nicht fest. Somit müssen Techniken eingesetzt werden um diese Wartezeiten zu minimieren. (Branch Prediction) Ressourcenkonflikte (Structural Hazards) Bei bestimmten Befehlskombinationen ist es unter Umständen möglich, daß ein Teilwerk seine Arbeit wiederholen muss. Solche Ressourcenkonflikte treten dann auf, wenn nicht jeder Teilphase völlig unabhängige Teilwerke zugeordnet sind. Ein Beispiel ist z.B. ein zeitgleicher Lesezugriff eines LOAD/STORE Befehles, welcher sich zwangsweise mit einem eventuellen MEM ACCESS eines anderen Befehles überschneidet. Abhilfe können hier Dual-Port RAM, Havard-Architektur oder getrennte Code- und Datencaches schaffen. Welche drei verschiedenen Datenabhängigkeiten gibt es? RAW, WAW und WAR-Konflikte sind Datenabnhänigkeiten, welche in Pipelines auftreten können. Dabei ist das RAW-Problem für Pipelines typisch. WAR Konflikte treten eher bei Out-Of-Order Execution auf. Um Read-After-Write Konflikte aufzulösen, gibt es verschiedene Ansätze wie Softwarelösungen ( Compileroptimierung), Scoreboarding (zentrale Steuerlogik) und Forwarding (zusätzlicher Datenpfad). Was ist Forwarding? Beim Forwarding wird ein Bypass eingerichtet, welcher ein Ergebniss einer Operation schon einem Folgebefehl zur Verfügung stellt, bevor es überhaupt in ein Register geschrieben wurde. Aber trotz Load-Forwarding hat ein Ladebefehl eine Verzögerung, welche nicht gänzlich eliminiert werden kann. In diesem Fall kann die Delayed-Load Technik oder auch eine Befehlsumordnung Anhilfe schaffen. Was ist die Delayed Load-Technik? Bei der Delayed Load-Technik wird die Verzögerung nach einem LOAD Befehl als architektonisches Merkmal angesehn und den Compilerbauern offengelegt. Diese können nun durch Befehlsumordnungen versuchen, nach einem LOAD-Befehl einen datenunabhängigen Befehl einzufügen, um den Slot zu füllen. Zusammenfassung Pipelining Pipelines werden in allen modernen CPUs benutzt. Die UltraSparc2 hat neun und der P2 zwölf Stufen. Der Intel Pentium Itanium weißt eine 20 stufige Superpinepline (pipeline in der sich einzelne Stufen überlappen können) auf! Pipes werden heutzutage in Kombination mit der Superskalartechnik verwendet, um höchste Effizienz und Parallelverarbeitung gewährleisten zu können. Die fünf grundlegenden Stufen einer einfachen Pipeline sind IF,ID,EX,MEM und WB. Takte T = Befehle + (Pipestufen - 1) Folgende Abhängigkeiten verhindern, dass die CPI auf eins gehen: Strucual Hazards bzw. Ressourcenkonflikte IF und MEM wollen gleichzeitig auf Speicher lesend oder schreibend zugreifen. Das geht nicht, außer bei Dual-Port-RAM, welcher aber sehr teuer ist. Dieses Problem tritt aber bei modernen CPU's kaum noch auf, da eh intern eine Havard-ähnliche Architektur mit getrenntem Befehls- und Datencache gearbeitet wird. Data Hazards bzw. Datenabhängigkeiten Ein Folgebefehl wartet auf das Writeback der darüber liegenden Pipe, da er von diesem Befehl abhängig ist. Dies kann durch Nops bzw. Stalls ineffizient gelöst werden. Besser der Programmierer oder der Compiler löst diese Abhängigkeiten durch eine clevere Umordnung der Befehlsfolge auf. Es gibt aber noch eine andere Möglichkeit, welche aber hardwareseitig unterstützt werden muss. (VLIW, Superskalar) Forwarding Beim Forwarding werden Ergebnisse, sobald sie vorliegen an die nächste Stufe weitergereicht und nicht erst auf das Write Back gewartet. In anderen Worten: Das Ergebnis der ALU wird dieser sofort wieder eingespeist. Control Hazards bzw. Sprungverzögerungen Sprungergebnisse stehen erst in der Write Back Phase an. Moderne Prozessoren haben aber schon in der Fetch/Decode-Einheit eine Logik, welche die Zieladresse des Sprunges berechnet. Eine andere Möglichkeit ist die des spekulativen Ausführens. Hier tritt aber das Problem auf, dass viel Aufwand bei falscher Spekulation getrieben werden muss. Was ist der Unterschied zwischen echten und unechten Datenabhängigkeiten? Echte Datenabhängigkeiten sind RAW-Konflikte, bei dem ein Befehl auf die Beendigung eines Anderen warten muss, da er das Ergebnis als Operand benötigt. Unechte Datenabhängigkeit sind Abhängigkeiten, welche nur durch Namensabhängigkeit entstehen. Es gibt zwei Arten unechter Datenabhängigkeit: Antidependence sind WAR-Konflikte, welche entstehen, wenn ein Folgebefehl auf ein Register schreiben möchte, das noch von einem Anderen benutzt wird. Output Dependece sind WAW-Konflikte, welche entstehen, wenn mehrere Befehle auf ein und das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. D
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itontrol Hazards) Bei Sprungbefehlen liegt oft das Sprungziel nach der Dekodieung noch nicht fest. Somit müssen Techniken eingesetzt werden um diese Wartezeiten zu minimieren. (Branch Prediction) <span>Ressourcenkonflikte (Structural Hazards) Bei bestimmten Befehlskombinationen ist es unter Umständen möglich, daß ein Teilwerk seine Arbeit wiederholen muss. Solche Ressourcenkonflikte treten dann auf, wenn nicht jeder Teilphase völlig unabhängige Teilwerke zugeordnet sind. Ein Beispiel ist z.B. ein zeitgleicher Lesezugriff eines LOAD/STORE Befehles, welcher sich zwangsweise mit einem eventuellen MEM ACCESS eines anderen Befehles überschneidet. Abhilfe können hier Dual-Port RAM, Havard-Architektur oder getrennte Code- und Datencaches schaffen. Welche drei verschiedenen Datenabhängigkeiten gibt es? RAW, WAW und WAR-Konflikte sind Datenabnhänigkeiten, welche in Pipelines auftreten können. Dabei ist das RAW-Problem für Pipelines
Original toplevel document
Grundprinzipien der Rechnerarchitektureinen Verweis auf die Nächste enthalten. Sprünge sind einfach möglich. Angewandt wird dies in Form von Opcodes, welche nichts anderes als Adressen auf Mikroinstruktionen im Steuerspeicher sind. <span>Kapitel 6 - Pipelining Wozu dient Pipelining? Pipelining soll es ermöglichen Befehle überlappt auszuführen. Dazu sind ein einheitliches Befehlsformat fester Länge Grundlage. Deshalb werden werden nur auf Register getätigt. Für Speicheroperationen wird die LOAD / STORE Philosophie verfolgt, um langsame Hauptspeicherzugriffe zu minimieren. Was ist Voraussetzung für Pipelining? Die Befehlsverarbeitungsphase muss sich in mehrere voneinander unabhängige Phasen unterteilen lassen. Die einfachste Form einer Pipeline ist die 5-stufige mit folgenden Phasen: Befehl holen Befehl dekodieren Befehl ausführen Auf Speicher zugreifen Ergebnis in Register schreiben Moderene CPU's haben weitaus komplexere Pipelines, in denen die einzelnen Stufen wiederrum in mehrere sich überlappende Phasen aufgeteilt werden. Der allgemeine Aufbau einer (fünfstufigen) Pipeline Um Parallelität in der Befehlsausführungsphase zu erreichen, wird der Datenpfad so konstruiert, daß folgende (hier fünf) Phasen unabhänig voneinander arbeiten können. Nur so ist es möglich eine verzahnte Abarbeitung mehrerer Befehle zu erreichen. Abb.: Die Piplelinestufen Somit wird ,nachdem eine Pipeline gefüllt ist, im Optimalfall pro Takt ein Befehl fertig. (CPI = 1) Welche Pipeline-Konflikte müssen behandelt werden? Datenabhängigkeiten (Data Hazards) Sind logische Abhängigkeiten, welche eine verzögerte Abarbeitung erfordern, weil z.B. ein Folgebefehl auf ein Ergebnis eines anderen Befehles warten muss. Jump- / Branchverzögerungen (Control Hazards) Bei Sprungbefehlen liegt oft das Sprungziel nach der Dekodieung noch nicht fest. Somit müssen Techniken eingesetzt werden um diese Wartezeiten zu minimieren. (Branch Prediction) Ressourcenkonflikte (Structural Hazards) Bei bestimmten Befehlskombinationen ist es unter Umständen möglich, daß ein Teilwerk seine Arbeit wiederholen muss. Solche Ressourcenkonflikte treten dann auf, wenn nicht jeder Teilphase völlig unabhängige Teilwerke zugeordnet sind. Ein Beispiel ist z.B. ein zeitgleicher Lesezugriff eines LOAD/STORE Befehles, welcher sich zwangsweise mit einem eventuellen MEM ACCESS eines anderen Befehles überschneidet. Abhilfe können hier Dual-Port RAM, Havard-Architektur oder getrennte Code- und Datencaches schaffen. Welche drei verschiedenen Datenabhängigkeiten gibt es? RAW, WAW und WAR-Konflikte sind Datenabnhänigkeiten, welche in Pipelines auftreten können. Dabei ist das RAW-Problem für Pipelines typisch. WAR Konflikte treten eher bei Out-Of-Order Execution auf. Um Read-After-Write Konflikte aufzulösen, gibt es verschiedene Ansätze wie Softwarelösungen ( Compileroptimierung), Scoreboarding (zentrale Steuerlogik) und Forwarding (zusätzlicher Datenpfad). Was ist Forwarding? Beim Forwarding wird ein Bypass eingerichtet, welcher ein Ergebniss einer Operation schon einem Folgebefehl zur Verfügung stellt, bevor es überhaupt in ein Register geschrieben wurde. Aber trotz Load-Forwarding hat ein Ladebefehl eine Verzögerung, welche nicht gänzlich eliminiert werden kann. In diesem Fall kann die Delayed-Load Technik oder auch eine Befehlsumordnung Anhilfe schaffen. Was ist die Delayed Load-Technik? Bei der Delayed Load-Technik wird die Verzögerung nach einem LOAD Befehl als architektonisches Merkmal angesehn und den Compilerbauern offengelegt. Diese können nun durch Befehlsumordnungen versuchen, nach einem LOAD-Befehl einen datenunabhängigen Befehl einzufügen, um den Slot zu füllen. Zusammenfassung Pipelining Pipelines werden in allen modernen CPUs benutzt. Die UltraSparc2 hat neun und der P2 zwölf Stufen. Der Intel Pentium Itanium weißt eine 20 stufige Superpinepline (pipeline in der sich einzelne Stufen überlappen können) auf! Pipes werden heutzutage in Kombination mit der Superskalartechnik verwendet, um höchste Effizienz und Parallelverarbeitung gewährleisten zu können. Die fünf grundlegenden Stufen einer einfachen Pipeline sind IF,ID,EX,MEM und WB. Takte T = Befehle + (Pipestufen - 1) Folgende Abhängigkeiten verhindern, dass die CPI auf eins gehen: Strucual Hazards bzw. Ressourcenkonflikte IF und MEM wollen gleichzeitig auf Speicher lesend oder schreibend zugreifen. Das geht nicht, außer bei Dual-Port-RAM, welcher aber sehr teuer ist. Dieses Problem tritt aber bei modernen CPU's kaum noch auf, da eh intern eine Havard-ähnliche Architektur mit getrenntem Befehls- und Datencache gearbeitet wird. Data Hazards bzw. Datenabhängigkeiten Ein Folgebefehl wartet auf das Writeback der darüber liegenden Pipe, da er von diesem Befehl abhängig ist. Dies kann durch Nops bzw. Stalls ineffizient gelöst werden. Besser der Programmierer oder der Compiler löst diese Abhängigkeiten durch eine clevere Umordnung der Befehlsfolge auf. Es gibt aber noch eine andere Möglichkeit, welche aber hardwareseitig unterstützt werden muss. (VLIW, Superskalar) Forwarding Beim Forwarding werden Ergebnisse, sobald sie vorliegen an die nächste Stufe weitergereicht und nicht erst auf das Write Back gewartet. In anderen Worten: Das Ergebnis der ALU wird dieser sofort wieder eingespeist. Control Hazards bzw. Sprungverzögerungen Sprungergebnisse stehen erst in der Write Back Phase an. Moderne Prozessoren haben aber schon in der Fetch/Decode-Einheit eine Logik, welche die Zieladresse des Sprunges berechnet. Eine andere Möglichkeit ist die des spekulativen Ausführens. Hier tritt aber das Problem auf, dass viel Aufwand bei falscher Spekulation getrieben werden muss. Was ist der Unterschied zwischen echten und unechten Datenabhängigkeiten? Echte Datenabhängigkeiten sind RAW-Konflikte, bei dem ein Befehl auf die Beendigung eines Anderen warten muss, da er das Ergebnis als Operand benötigt. Unechte Datenabhängigkeit sind Abhängigkeiten, welche nur durch Namensabhängigkeit entstehen. Es gibt zwei Arten unechter Datenabhängigkeit: Antidependence sind WAR-Konflikte, welche entstehen, wenn ein Folgebefehl auf ein Register schreiben möchte, das noch von einem Anderen benutzt wird. Output Dependece sind WAW-Konflikte, welche entstehen, wenn mehrere Befehle auf ein und das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. D
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itcher sich zwangsweise mit einem eventuellen MEM ACCESS eines anderen Befehles überschneidet. Abhilfe können hier Dual-Port RAM, Havard-Architektur oder getrennte Code- und Datencaches schaffen. <span>Welche drei verschiedenen Datenabhängigkeiten gibt es? RAW, WAW und WAR-Konflikte sind Datenabnhänigkeiten, welche in Pipelines auftreten können. Dabei ist das RAW-Problem für Pipelines typisch. WAR Konflikte treten eher bei Out-Of-Order Execution auf. Um Read-After-Write Konflikte aufzulösen, gibt es verschiedene Ansätze wie Softwarelösungen ( Compileroptimierung), Scoreboarding (zentrale Steuerlogik) und Forwarding (zusätzlicher Datenpfad). Was ist Forwarding? Beim Forwarding wird ein Bypass eingerichtet, welcher ein Ergebniss einer Operation schon einem Folgebefehl zur Verfügung stellt, bevor es überhaupt in ein Register
Original toplevel document
Grundprinzipien der Rechnerarchitektureinen Verweis auf die Nächste enthalten. Sprünge sind einfach möglich. Angewandt wird dies in Form von Opcodes, welche nichts anderes als Adressen auf Mikroinstruktionen im Steuerspeicher sind. <span>Kapitel 6 - Pipelining Wozu dient Pipelining? Pipelining soll es ermöglichen Befehle überlappt auszuführen. Dazu sind ein einheitliches Befehlsformat fester Länge Grundlage. Deshalb werden werden nur auf Register getätigt. Für Speicheroperationen wird die LOAD / STORE Philosophie verfolgt, um langsame Hauptspeicherzugriffe zu minimieren. Was ist Voraussetzung für Pipelining? Die Befehlsverarbeitungsphase muss sich in mehrere voneinander unabhängige Phasen unterteilen lassen. Die einfachste Form einer Pipeline ist die 5-stufige mit folgenden Phasen: Befehl holen Befehl dekodieren Befehl ausführen Auf Speicher zugreifen Ergebnis in Register schreiben Moderene CPU's haben weitaus komplexere Pipelines, in denen die einzelnen Stufen wiederrum in mehrere sich überlappende Phasen aufgeteilt werden. Der allgemeine Aufbau einer (fünfstufigen) Pipeline Um Parallelität in der Befehlsausführungsphase zu erreichen, wird der Datenpfad so konstruiert, daß folgende (hier fünf) Phasen unabhänig voneinander arbeiten können. Nur so ist es möglich eine verzahnte Abarbeitung mehrerer Befehle zu erreichen. Abb.: Die Piplelinestufen Somit wird ,nachdem eine Pipeline gefüllt ist, im Optimalfall pro Takt ein Befehl fertig. (CPI = 1) Welche Pipeline-Konflikte müssen behandelt werden? Datenabhängigkeiten (Data Hazards) Sind logische Abhängigkeiten, welche eine verzögerte Abarbeitung erfordern, weil z.B. ein Folgebefehl auf ein Ergebnis eines anderen Befehles warten muss. Jump- / Branchverzögerungen (Control Hazards) Bei Sprungbefehlen liegt oft das Sprungziel nach der Dekodieung noch nicht fest. Somit müssen Techniken eingesetzt werden um diese Wartezeiten zu minimieren. (Branch Prediction) Ressourcenkonflikte (Structural Hazards) Bei bestimmten Befehlskombinationen ist es unter Umständen möglich, daß ein Teilwerk seine Arbeit wiederholen muss. Solche Ressourcenkonflikte treten dann auf, wenn nicht jeder Teilphase völlig unabhängige Teilwerke zugeordnet sind. Ein Beispiel ist z.B. ein zeitgleicher Lesezugriff eines LOAD/STORE Befehles, welcher sich zwangsweise mit einem eventuellen MEM ACCESS eines anderen Befehles überschneidet. Abhilfe können hier Dual-Port RAM, Havard-Architektur oder getrennte Code- und Datencaches schaffen. Welche drei verschiedenen Datenabhängigkeiten gibt es? RAW, WAW und WAR-Konflikte sind Datenabnhänigkeiten, welche in Pipelines auftreten können. Dabei ist das RAW-Problem für Pipelines typisch. WAR Konflikte treten eher bei Out-Of-Order Execution auf. Um Read-After-Write Konflikte aufzulösen, gibt es verschiedene Ansätze wie Softwarelösungen ( Compileroptimierung), Scoreboarding (zentrale Steuerlogik) und Forwarding (zusätzlicher Datenpfad). Was ist Forwarding? Beim Forwarding wird ein Bypass eingerichtet, welcher ein Ergebniss einer Operation schon einem Folgebefehl zur Verfügung stellt, bevor es überhaupt in ein Register geschrieben wurde. Aber trotz Load-Forwarding hat ein Ladebefehl eine Verzögerung, welche nicht gänzlich eliminiert werden kann. In diesem Fall kann die Delayed-Load Technik oder auch eine Befehlsumordnung Anhilfe schaffen. Was ist die Delayed Load-Technik? Bei der Delayed Load-Technik wird die Verzögerung nach einem LOAD Befehl als architektonisches Merkmal angesehn und den Compilerbauern offengelegt. Diese können nun durch Befehlsumordnungen versuchen, nach einem LOAD-Befehl einen datenunabhängigen Befehl einzufügen, um den Slot zu füllen. Zusammenfassung Pipelining Pipelines werden in allen modernen CPUs benutzt. Die UltraSparc2 hat neun und der P2 zwölf Stufen. Der Intel Pentium Itanium weißt eine 20 stufige Superpinepline (pipeline in der sich einzelne Stufen überlappen können) auf! Pipes werden heutzutage in Kombination mit der Superskalartechnik verwendet, um höchste Effizienz und Parallelverarbeitung gewährleisten zu können. Die fünf grundlegenden Stufen einer einfachen Pipeline sind IF,ID,EX,MEM und WB. Takte T = Befehle + (Pipestufen - 1) Folgende Abhängigkeiten verhindern, dass die CPI auf eins gehen: Strucual Hazards bzw. Ressourcenkonflikte IF und MEM wollen gleichzeitig auf Speicher lesend oder schreibend zugreifen. Das geht nicht, außer bei Dual-Port-RAM, welcher aber sehr teuer ist. Dieses Problem tritt aber bei modernen CPU's kaum noch auf, da eh intern eine Havard-ähnliche Architektur mit getrenntem Befehls- und Datencache gearbeitet wird. Data Hazards bzw. Datenabhängigkeiten Ein Folgebefehl wartet auf das Writeback der darüber liegenden Pipe, da er von diesem Befehl abhängig ist. Dies kann durch Nops bzw. Stalls ineffizient gelöst werden. Besser der Programmierer oder der Compiler löst diese Abhängigkeiten durch eine clevere Umordnung der Befehlsfolge auf. Es gibt aber noch eine andere Möglichkeit, welche aber hardwareseitig unterstützt werden muss. (VLIW, Superskalar) Forwarding Beim Forwarding werden Ergebnisse, sobald sie vorliegen an die nächste Stufe weitergereicht und nicht erst auf das Write Back gewartet. In anderen Worten: Das Ergebnis der ALU wird dieser sofort wieder eingespeist. Control Hazards bzw. Sprungverzögerungen Sprungergebnisse stehen erst in der Write Back Phase an. Moderne Prozessoren haben aber schon in der Fetch/Decode-Einheit eine Logik, welche die Zieladresse des Sprunges berechnet. Eine andere Möglichkeit ist die des spekulativen Ausführens. Hier tritt aber das Problem auf, dass viel Aufwand bei falscher Spekulation getrieben werden muss. Was ist der Unterschied zwischen echten und unechten Datenabhängigkeiten? Echte Datenabhängigkeiten sind RAW-Konflikte, bei dem ein Befehl auf die Beendigung eines Anderen warten muss, da er das Ergebnis als Operand benötigt. Unechte Datenabhängigkeit sind Abhängigkeiten, welche nur durch Namensabhängigkeit entstehen. Es gibt zwei Arten unechter Datenabhängigkeit: Antidependence sind WAR-Konflikte, welche entstehen, wenn ein Folgebefehl auf ein Register schreiben möchte, das noch von einem Anderen benutzt wird. Output Dependece sind WAW-Konflikte, welche entstehen, wenn mehrere Befehle auf ein und das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. D
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itUm Read-After-Write Konflikte aufzulösen, gibt es verschiedene Ansätze wie Softwarelösungen ( Compileroptimierung), Scoreboarding (zentrale Steuerlogik) und Forwarding (zusätzlicher Datenpfad). <span>Was ist Forwarding? Beim Forwarding wird ein Bypass eingerichtet, welcher ein Ergebniss einer Operation schon einem Folgebefehl zur Verfügung stellt, bevor es überhaupt in ein Register geschrieben wurde. Aber trotz Load-Forwarding hat ein Ladebefehl eine Verzögerung, welche nicht gänzlich eliminiert werden kann. In diesem Fall kann die Delayed-Load Technik oder auch eine Befehlsumordnung Anhilfe schaffen. Was ist die Delayed Load-Technik? Bei der Delayed Load-Technik wird die Verzögerung nach einem LOAD Befehl als architektonisches Merkmal angesehn und den Compilerbauern offengelegt. Die
Original toplevel document
Grundprinzipien der Rechnerarchitektureinen Verweis auf die Nächste enthalten. Sprünge sind einfach möglich. Angewandt wird dies in Form von Opcodes, welche nichts anderes als Adressen auf Mikroinstruktionen im Steuerspeicher sind. <span>Kapitel 6 - Pipelining Wozu dient Pipelining? Pipelining soll es ermöglichen Befehle überlappt auszuführen. Dazu sind ein einheitliches Befehlsformat fester Länge Grundlage. Deshalb werden werden nur auf Register getätigt. Für Speicheroperationen wird die LOAD / STORE Philosophie verfolgt, um langsame Hauptspeicherzugriffe zu minimieren. Was ist Voraussetzung für Pipelining? Die Befehlsverarbeitungsphase muss sich in mehrere voneinander unabhängige Phasen unterteilen lassen. Die einfachste Form einer Pipeline ist die 5-stufige mit folgenden Phasen: Befehl holen Befehl dekodieren Befehl ausführen Auf Speicher zugreifen Ergebnis in Register schreiben Moderene CPU's haben weitaus komplexere Pipelines, in denen die einzelnen Stufen wiederrum in mehrere sich überlappende Phasen aufgeteilt werden. Der allgemeine Aufbau einer (fünfstufigen) Pipeline Um Parallelität in der Befehlsausführungsphase zu erreichen, wird der Datenpfad so konstruiert, daß folgende (hier fünf) Phasen unabhänig voneinander arbeiten können. Nur so ist es möglich eine verzahnte Abarbeitung mehrerer Befehle zu erreichen. Abb.: Die Piplelinestufen Somit wird ,nachdem eine Pipeline gefüllt ist, im Optimalfall pro Takt ein Befehl fertig. (CPI = 1) Welche Pipeline-Konflikte müssen behandelt werden? Datenabhängigkeiten (Data Hazards) Sind logische Abhängigkeiten, welche eine verzögerte Abarbeitung erfordern, weil z.B. ein Folgebefehl auf ein Ergebnis eines anderen Befehles warten muss. Jump- / Branchverzögerungen (Control Hazards) Bei Sprungbefehlen liegt oft das Sprungziel nach der Dekodieung noch nicht fest. Somit müssen Techniken eingesetzt werden um diese Wartezeiten zu minimieren. (Branch Prediction) Ressourcenkonflikte (Structural Hazards) Bei bestimmten Befehlskombinationen ist es unter Umständen möglich, daß ein Teilwerk seine Arbeit wiederholen muss. Solche Ressourcenkonflikte treten dann auf, wenn nicht jeder Teilphase völlig unabhängige Teilwerke zugeordnet sind. Ein Beispiel ist z.B. ein zeitgleicher Lesezugriff eines LOAD/STORE Befehles, welcher sich zwangsweise mit einem eventuellen MEM ACCESS eines anderen Befehles überschneidet. Abhilfe können hier Dual-Port RAM, Havard-Architektur oder getrennte Code- und Datencaches schaffen. Welche drei verschiedenen Datenabhängigkeiten gibt es? RAW, WAW und WAR-Konflikte sind Datenabnhänigkeiten, welche in Pipelines auftreten können. Dabei ist das RAW-Problem für Pipelines typisch. WAR Konflikte treten eher bei Out-Of-Order Execution auf. Um Read-After-Write Konflikte aufzulösen, gibt es verschiedene Ansätze wie Softwarelösungen ( Compileroptimierung), Scoreboarding (zentrale Steuerlogik) und Forwarding (zusätzlicher Datenpfad). Was ist Forwarding? Beim Forwarding wird ein Bypass eingerichtet, welcher ein Ergebniss einer Operation schon einem Folgebefehl zur Verfügung stellt, bevor es überhaupt in ein Register geschrieben wurde. Aber trotz Load-Forwarding hat ein Ladebefehl eine Verzögerung, welche nicht gänzlich eliminiert werden kann. In diesem Fall kann die Delayed-Load Technik oder auch eine Befehlsumordnung Anhilfe schaffen. Was ist die Delayed Load-Technik? Bei der Delayed Load-Technik wird die Verzögerung nach einem LOAD Befehl als architektonisches Merkmal angesehn und den Compilerbauern offengelegt. Diese können nun durch Befehlsumordnungen versuchen, nach einem LOAD-Befehl einen datenunabhängigen Befehl einzufügen, um den Slot zu füllen. Zusammenfassung Pipelining Pipelines werden in allen modernen CPUs benutzt. Die UltraSparc2 hat neun und der P2 zwölf Stufen. Der Intel Pentium Itanium weißt eine 20 stufige Superpinepline (pipeline in der sich einzelne Stufen überlappen können) auf! Pipes werden heutzutage in Kombination mit der Superskalartechnik verwendet, um höchste Effizienz und Parallelverarbeitung gewährleisten zu können. Die fünf grundlegenden Stufen einer einfachen Pipeline sind IF,ID,EX,MEM und WB. Takte T = Befehle + (Pipestufen - 1) Folgende Abhängigkeiten verhindern, dass die CPI auf eins gehen: Strucual Hazards bzw. Ressourcenkonflikte IF und MEM wollen gleichzeitig auf Speicher lesend oder schreibend zugreifen. Das geht nicht, außer bei Dual-Port-RAM, welcher aber sehr teuer ist. Dieses Problem tritt aber bei modernen CPU's kaum noch auf, da eh intern eine Havard-ähnliche Architektur mit getrenntem Befehls- und Datencache gearbeitet wird. Data Hazards bzw. Datenabhängigkeiten Ein Folgebefehl wartet auf das Writeback der darüber liegenden Pipe, da er von diesem Befehl abhängig ist. Dies kann durch Nops bzw. Stalls ineffizient gelöst werden. Besser der Programmierer oder der Compiler löst diese Abhängigkeiten durch eine clevere Umordnung der Befehlsfolge auf. Es gibt aber noch eine andere Möglichkeit, welche aber hardwareseitig unterstützt werden muss. (VLIW, Superskalar) Forwarding Beim Forwarding werden Ergebnisse, sobald sie vorliegen an die nächste Stufe weitergereicht und nicht erst auf das Write Back gewartet. In anderen Worten: Das Ergebnis der ALU wird dieser sofort wieder eingespeist. Control Hazards bzw. Sprungverzögerungen Sprungergebnisse stehen erst in der Write Back Phase an. Moderne Prozessoren haben aber schon in der Fetch/Decode-Einheit eine Logik, welche die Zieladresse des Sprunges berechnet. Eine andere Möglichkeit ist die des spekulativen Ausführens. Hier tritt aber das Problem auf, dass viel Aufwand bei falscher Spekulation getrieben werden muss. Was ist der Unterschied zwischen echten und unechten Datenabhängigkeiten? Echte Datenabhängigkeiten sind RAW-Konflikte, bei dem ein Befehl auf die Beendigung eines Anderen warten muss, da er das Ergebnis als Operand benötigt. Unechte Datenabhängigkeit sind Abhängigkeiten, welche nur durch Namensabhängigkeit entstehen. Es gibt zwei Arten unechter Datenabhängigkeit: Antidependence sind WAR-Konflikte, welche entstehen, wenn ein Folgebefehl auf ein Register schreiben möchte, das noch von einem Anderen benutzt wird. Output Dependece sind WAW-Konflikte, welche entstehen, wenn mehrere Befehle auf ein und das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. D
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itLoad-Forwarding hat ein Ladebefehl eine Verzögerung, welche nicht gänzlich eliminiert werden kann. In diesem Fall kann die Delayed-Load Technik oder auch eine Befehlsumordnung Anhilfe schaffen. <span>Was ist die Delayed Load-Technik? Bei der Delayed Load-Technik wird die Verzögerung nach einem LOAD Befehl als architektonisches Merkmal angesehn und den Compilerbauern offengelegt. Diese können nun durch Befehlsumordnungen versuchen, nach einem LOAD-Befehl einen datenunabhängigen Befehl einzufügen, um den Slot zu füllen. Zusammenfassung Pipelining Pipelines werden in allen modernen CPUs benutzt. Die UltraSparc2 hat neun und der P2 zwölf Stufen. Der Intel Pentium Itanium weißt eine 20 stufige Superpinepl
Original toplevel document
Grundprinzipien der Rechnerarchitektureinen Verweis auf die Nächste enthalten. Sprünge sind einfach möglich. Angewandt wird dies in Form von Opcodes, welche nichts anderes als Adressen auf Mikroinstruktionen im Steuerspeicher sind. <span>Kapitel 6 - Pipelining Wozu dient Pipelining? Pipelining soll es ermöglichen Befehle überlappt auszuführen. Dazu sind ein einheitliches Befehlsformat fester Länge Grundlage. Deshalb werden werden nur auf Register getätigt. Für Speicheroperationen wird die LOAD / STORE Philosophie verfolgt, um langsame Hauptspeicherzugriffe zu minimieren. Was ist Voraussetzung für Pipelining? Die Befehlsverarbeitungsphase muss sich in mehrere voneinander unabhängige Phasen unterteilen lassen. Die einfachste Form einer Pipeline ist die 5-stufige mit folgenden Phasen: Befehl holen Befehl dekodieren Befehl ausführen Auf Speicher zugreifen Ergebnis in Register schreiben Moderene CPU's haben weitaus komplexere Pipelines, in denen die einzelnen Stufen wiederrum in mehrere sich überlappende Phasen aufgeteilt werden. Der allgemeine Aufbau einer (fünfstufigen) Pipeline Um Parallelität in der Befehlsausführungsphase zu erreichen, wird der Datenpfad so konstruiert, daß folgende (hier fünf) Phasen unabhänig voneinander arbeiten können. Nur so ist es möglich eine verzahnte Abarbeitung mehrerer Befehle zu erreichen. Abb.: Die Piplelinestufen Somit wird ,nachdem eine Pipeline gefüllt ist, im Optimalfall pro Takt ein Befehl fertig. (CPI = 1) Welche Pipeline-Konflikte müssen behandelt werden? Datenabhängigkeiten (Data Hazards) Sind logische Abhängigkeiten, welche eine verzögerte Abarbeitung erfordern, weil z.B. ein Folgebefehl auf ein Ergebnis eines anderen Befehles warten muss. Jump- / Branchverzögerungen (Control Hazards) Bei Sprungbefehlen liegt oft das Sprungziel nach der Dekodieung noch nicht fest. Somit müssen Techniken eingesetzt werden um diese Wartezeiten zu minimieren. (Branch Prediction) Ressourcenkonflikte (Structural Hazards) Bei bestimmten Befehlskombinationen ist es unter Umständen möglich, daß ein Teilwerk seine Arbeit wiederholen muss. Solche Ressourcenkonflikte treten dann auf, wenn nicht jeder Teilphase völlig unabhängige Teilwerke zugeordnet sind. Ein Beispiel ist z.B. ein zeitgleicher Lesezugriff eines LOAD/STORE Befehles, welcher sich zwangsweise mit einem eventuellen MEM ACCESS eines anderen Befehles überschneidet. Abhilfe können hier Dual-Port RAM, Havard-Architektur oder getrennte Code- und Datencaches schaffen. Welche drei verschiedenen Datenabhängigkeiten gibt es? RAW, WAW und WAR-Konflikte sind Datenabnhänigkeiten, welche in Pipelines auftreten können. Dabei ist das RAW-Problem für Pipelines typisch. WAR Konflikte treten eher bei Out-Of-Order Execution auf. Um Read-After-Write Konflikte aufzulösen, gibt es verschiedene Ansätze wie Softwarelösungen ( Compileroptimierung), Scoreboarding (zentrale Steuerlogik) und Forwarding (zusätzlicher Datenpfad). Was ist Forwarding? Beim Forwarding wird ein Bypass eingerichtet, welcher ein Ergebniss einer Operation schon einem Folgebefehl zur Verfügung stellt, bevor es überhaupt in ein Register geschrieben wurde. Aber trotz Load-Forwarding hat ein Ladebefehl eine Verzögerung, welche nicht gänzlich eliminiert werden kann. In diesem Fall kann die Delayed-Load Technik oder auch eine Befehlsumordnung Anhilfe schaffen. Was ist die Delayed Load-Technik? Bei der Delayed Load-Technik wird die Verzögerung nach einem LOAD Befehl als architektonisches Merkmal angesehn und den Compilerbauern offengelegt. Diese können nun durch Befehlsumordnungen versuchen, nach einem LOAD-Befehl einen datenunabhängigen Befehl einzufügen, um den Slot zu füllen. Zusammenfassung Pipelining Pipelines werden in allen modernen CPUs benutzt. Die UltraSparc2 hat neun und der P2 zwölf Stufen. Der Intel Pentium Itanium weißt eine 20 stufige Superpinepline (pipeline in der sich einzelne Stufen überlappen können) auf! Pipes werden heutzutage in Kombination mit der Superskalartechnik verwendet, um höchste Effizienz und Parallelverarbeitung gewährleisten zu können. Die fünf grundlegenden Stufen einer einfachen Pipeline sind IF,ID,EX,MEM und WB. Takte T = Befehle + (Pipestufen - 1) Folgende Abhängigkeiten verhindern, dass die CPI auf eins gehen: Strucual Hazards bzw. Ressourcenkonflikte IF und MEM wollen gleichzeitig auf Speicher lesend oder schreibend zugreifen. Das geht nicht, außer bei Dual-Port-RAM, welcher aber sehr teuer ist. Dieses Problem tritt aber bei modernen CPU's kaum noch auf, da eh intern eine Havard-ähnliche Architektur mit getrenntem Befehls- und Datencache gearbeitet wird. Data Hazards bzw. Datenabhängigkeiten Ein Folgebefehl wartet auf das Writeback der darüber liegenden Pipe, da er von diesem Befehl abhängig ist. Dies kann durch Nops bzw. Stalls ineffizient gelöst werden. Besser der Programmierer oder der Compiler löst diese Abhängigkeiten durch eine clevere Umordnung der Befehlsfolge auf. Es gibt aber noch eine andere Möglichkeit, welche aber hardwareseitig unterstützt werden muss. (VLIW, Superskalar) Forwarding Beim Forwarding werden Ergebnisse, sobald sie vorliegen an die nächste Stufe weitergereicht und nicht erst auf das Write Back gewartet. In anderen Worten: Das Ergebnis der ALU wird dieser sofort wieder eingespeist. Control Hazards bzw. Sprungverzögerungen Sprungergebnisse stehen erst in der Write Back Phase an. Moderne Prozessoren haben aber schon in der Fetch/Decode-Einheit eine Logik, welche die Zieladresse des Sprunges berechnet. Eine andere Möglichkeit ist die des spekulativen Ausführens. Hier tritt aber das Problem auf, dass viel Aufwand bei falscher Spekulation getrieben werden muss. Was ist der Unterschied zwischen echten und unechten Datenabhängigkeiten? Echte Datenabhängigkeiten sind RAW-Konflikte, bei dem ein Befehl auf die Beendigung eines Anderen warten muss, da er das Ergebnis als Operand benötigt. Unechte Datenabhängigkeit sind Abhängigkeiten, welche nur durch Namensabhängigkeit entstehen. Es gibt zwei Arten unechter Datenabhängigkeit: Antidependence sind WAR-Konflikte, welche entstehen, wenn ein Folgebefehl auf ein Register schreiben möchte, das noch von einem Anderen benutzt wird. Output Dependece sind WAW-Konflikte, welche entstehen, wenn mehrere Befehle auf ein und das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. D
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open iterkmal angesehn und den Compilerbauern offengelegt. Diese können nun durch Befehlsumordnungen versuchen, nach einem LOAD-Befehl einen datenunabhängigen Befehl einzufügen, um den Slot zu füllen. <span>Zusammenfassung Pipelining Pipelines werden in allen modernen CPUs benutzt. Die UltraSparc2 hat neun und der P2 zwölf Stufen. Der Intel Pentium Itanium weißt eine 20 stufige Superpinepline (pipeline in der sich einzelne Stufen überlappen können) auf! Pipes werden heutzutage in Kombination mit der Superskalartechnik verwendet, um höchste Effizienz und Parallelverarbeitung gewährleisten zu können. Die fünf grundlegenden Stufen einer einfachen Pipeline sind IF,ID,EX,MEM und WB. Takte T = Befehle + (Pipestufen - 1) Folgende Abhängigkeiten verhindern, dass die CPI auf eins gehen: Strucual Hazards bzw. Ressourcenkonflikte IF und MEM wollen gleichzeitig auf Speicher lesend oder schreibend zugreifen.
Original toplevel document
Grundprinzipien der Rechnerarchitektureinen Verweis auf die Nächste enthalten. Sprünge sind einfach möglich. Angewandt wird dies in Form von Opcodes, welche nichts anderes als Adressen auf Mikroinstruktionen im Steuerspeicher sind. <span>Kapitel 6 - Pipelining Wozu dient Pipelining? Pipelining soll es ermöglichen Befehle überlappt auszuführen. Dazu sind ein einheitliches Befehlsformat fester Länge Grundlage. Deshalb werden werden nur auf Register getätigt. Für Speicheroperationen wird die LOAD / STORE Philosophie verfolgt, um langsame Hauptspeicherzugriffe zu minimieren. Was ist Voraussetzung für Pipelining? Die Befehlsverarbeitungsphase muss sich in mehrere voneinander unabhängige Phasen unterteilen lassen. Die einfachste Form einer Pipeline ist die 5-stufige mit folgenden Phasen: Befehl holen Befehl dekodieren Befehl ausführen Auf Speicher zugreifen Ergebnis in Register schreiben Moderene CPU's haben weitaus komplexere Pipelines, in denen die einzelnen Stufen wiederrum in mehrere sich überlappende Phasen aufgeteilt werden. Der allgemeine Aufbau einer (fünfstufigen) Pipeline Um Parallelität in der Befehlsausführungsphase zu erreichen, wird der Datenpfad so konstruiert, daß folgende (hier fünf) Phasen unabhänig voneinander arbeiten können. Nur so ist es möglich eine verzahnte Abarbeitung mehrerer Befehle zu erreichen. Abb.: Die Piplelinestufen Somit wird ,nachdem eine Pipeline gefüllt ist, im Optimalfall pro Takt ein Befehl fertig. (CPI = 1) Welche Pipeline-Konflikte müssen behandelt werden? Datenabhängigkeiten (Data Hazards) Sind logische Abhängigkeiten, welche eine verzögerte Abarbeitung erfordern, weil z.B. ein Folgebefehl auf ein Ergebnis eines anderen Befehles warten muss. Jump- / Branchverzögerungen (Control Hazards) Bei Sprungbefehlen liegt oft das Sprungziel nach der Dekodieung noch nicht fest. Somit müssen Techniken eingesetzt werden um diese Wartezeiten zu minimieren. (Branch Prediction) Ressourcenkonflikte (Structural Hazards) Bei bestimmten Befehlskombinationen ist es unter Umständen möglich, daß ein Teilwerk seine Arbeit wiederholen muss. Solche Ressourcenkonflikte treten dann auf, wenn nicht jeder Teilphase völlig unabhängige Teilwerke zugeordnet sind. Ein Beispiel ist z.B. ein zeitgleicher Lesezugriff eines LOAD/STORE Befehles, welcher sich zwangsweise mit einem eventuellen MEM ACCESS eines anderen Befehles überschneidet. Abhilfe können hier Dual-Port RAM, Havard-Architektur oder getrennte Code- und Datencaches schaffen. Welche drei verschiedenen Datenabhängigkeiten gibt es? RAW, WAW und WAR-Konflikte sind Datenabnhänigkeiten, welche in Pipelines auftreten können. Dabei ist das RAW-Problem für Pipelines typisch. WAR Konflikte treten eher bei Out-Of-Order Execution auf. Um Read-After-Write Konflikte aufzulösen, gibt es verschiedene Ansätze wie Softwarelösungen ( Compileroptimierung), Scoreboarding (zentrale Steuerlogik) und Forwarding (zusätzlicher Datenpfad). Was ist Forwarding? Beim Forwarding wird ein Bypass eingerichtet, welcher ein Ergebniss einer Operation schon einem Folgebefehl zur Verfügung stellt, bevor es überhaupt in ein Register geschrieben wurde. Aber trotz Load-Forwarding hat ein Ladebefehl eine Verzögerung, welche nicht gänzlich eliminiert werden kann. In diesem Fall kann die Delayed-Load Technik oder auch eine Befehlsumordnung Anhilfe schaffen. Was ist die Delayed Load-Technik? Bei der Delayed Load-Technik wird die Verzögerung nach einem LOAD Befehl als architektonisches Merkmal angesehn und den Compilerbauern offengelegt. Diese können nun durch Befehlsumordnungen versuchen, nach einem LOAD-Befehl einen datenunabhängigen Befehl einzufügen, um den Slot zu füllen. Zusammenfassung Pipelining Pipelines werden in allen modernen CPUs benutzt. Die UltraSparc2 hat neun und der P2 zwölf Stufen. Der Intel Pentium Itanium weißt eine 20 stufige Superpinepline (pipeline in der sich einzelne Stufen überlappen können) auf! Pipes werden heutzutage in Kombination mit der Superskalartechnik verwendet, um höchste Effizienz und Parallelverarbeitung gewährleisten zu können. Die fünf grundlegenden Stufen einer einfachen Pipeline sind IF,ID,EX,MEM und WB. Takte T = Befehle + (Pipestufen - 1) Folgende Abhängigkeiten verhindern, dass die CPI auf eins gehen: Strucual Hazards bzw. Ressourcenkonflikte IF und MEM wollen gleichzeitig auf Speicher lesend oder schreibend zugreifen. Das geht nicht, außer bei Dual-Port-RAM, welcher aber sehr teuer ist. Dieses Problem tritt aber bei modernen CPU's kaum noch auf, da eh intern eine Havard-ähnliche Architektur mit getrenntem Befehls- und Datencache gearbeitet wird. Data Hazards bzw. Datenabhängigkeiten Ein Folgebefehl wartet auf das Writeback der darüber liegenden Pipe, da er von diesem Befehl abhängig ist. Dies kann durch Nops bzw. Stalls ineffizient gelöst werden. Besser der Programmierer oder der Compiler löst diese Abhängigkeiten durch eine clevere Umordnung der Befehlsfolge auf. Es gibt aber noch eine andere Möglichkeit, welche aber hardwareseitig unterstützt werden muss. (VLIW, Superskalar) Forwarding Beim Forwarding werden Ergebnisse, sobald sie vorliegen an die nächste Stufe weitergereicht und nicht erst auf das Write Back gewartet. In anderen Worten: Das Ergebnis der ALU wird dieser sofort wieder eingespeist. Control Hazards bzw. Sprungverzögerungen Sprungergebnisse stehen erst in der Write Back Phase an. Moderne Prozessoren haben aber schon in der Fetch/Decode-Einheit eine Logik, welche die Zieladresse des Sprunges berechnet. Eine andere Möglichkeit ist die des spekulativen Ausführens. Hier tritt aber das Problem auf, dass viel Aufwand bei falscher Spekulation getrieben werden muss. Was ist der Unterschied zwischen echten und unechten Datenabhängigkeiten? Echte Datenabhängigkeiten sind RAW-Konflikte, bei dem ein Befehl auf die Beendigung eines Anderen warten muss, da er das Ergebnis als Operand benötigt. Unechte Datenabhängigkeit sind Abhängigkeiten, welche nur durch Namensabhängigkeit entstehen. Es gibt zwei Arten unechter Datenabhängigkeit: Antidependence sind WAR-Konflikte, welche entstehen, wenn ein Folgebefehl auf ein Register schreiben möchte, das noch von einem Anderen benutzt wird. Output Dependece sind WAW-Konflikte, welche entstehen, wenn mehrere Befehle auf ein und das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. D
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open iteladresse des Sprunges berechnet. Eine andere Möglichkeit ist die des spekulativen Ausführens. Hier tritt aber das Problem auf, dass viel Aufwand bei falscher Spekulation getrieben werden muss. <span>Was ist der Unterschied zwischen echten und unechten Datenabhängigkeiten? Echte Datenabhängigkeiten sind RAW-Konflikte, bei dem ein Befehl auf die Beendigung eines Anderen warten muss, da er das Ergebnis als Operand benötigt. Unechte Datenabhängigkeit sind Abhängigkeiten, welche nur durch Namensabhängigkeit entstehen. Es gibt zwei Arten unechter Datenabhängigkeit: Antidependence sind WAR-Konflikte, welche entstehen, wenn ein Folgebefehl auf ein Register schreiben möchte, das noch von einem Anderen benutzt wird. Output Dependece sind WAW-Konflikte, welche entstehen, wenn mehrere Befehle auf ein und das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! <span>
Original toplevel document
Grundprinzipien der Rechnerarchitektureinen Verweis auf die Nächste enthalten. Sprünge sind einfach möglich. Angewandt wird dies in Form von Opcodes, welche nichts anderes als Adressen auf Mikroinstruktionen im Steuerspeicher sind. <span>Kapitel 6 - Pipelining Wozu dient Pipelining? Pipelining soll es ermöglichen Befehle überlappt auszuführen. Dazu sind ein einheitliches Befehlsformat fester Länge Grundlage. Deshalb werden werden nur auf Register getätigt. Für Speicheroperationen wird die LOAD / STORE Philosophie verfolgt, um langsame Hauptspeicherzugriffe zu minimieren. Was ist Voraussetzung für Pipelining? Die Befehlsverarbeitungsphase muss sich in mehrere voneinander unabhängige Phasen unterteilen lassen. Die einfachste Form einer Pipeline ist die 5-stufige mit folgenden Phasen: Befehl holen Befehl dekodieren Befehl ausführen Auf Speicher zugreifen Ergebnis in Register schreiben Moderene CPU's haben weitaus komplexere Pipelines, in denen die einzelnen Stufen wiederrum in mehrere sich überlappende Phasen aufgeteilt werden. Der allgemeine Aufbau einer (fünfstufigen) Pipeline Um Parallelität in der Befehlsausführungsphase zu erreichen, wird der Datenpfad so konstruiert, daß folgende (hier fünf) Phasen unabhänig voneinander arbeiten können. Nur so ist es möglich eine verzahnte Abarbeitung mehrerer Befehle zu erreichen. Abb.: Die Piplelinestufen Somit wird ,nachdem eine Pipeline gefüllt ist, im Optimalfall pro Takt ein Befehl fertig. (CPI = 1) Welche Pipeline-Konflikte müssen behandelt werden? Datenabhängigkeiten (Data Hazards) Sind logische Abhängigkeiten, welche eine verzögerte Abarbeitung erfordern, weil z.B. ein Folgebefehl auf ein Ergebnis eines anderen Befehles warten muss. Jump- / Branchverzögerungen (Control Hazards) Bei Sprungbefehlen liegt oft das Sprungziel nach der Dekodieung noch nicht fest. Somit müssen Techniken eingesetzt werden um diese Wartezeiten zu minimieren. (Branch Prediction) Ressourcenkonflikte (Structural Hazards) Bei bestimmten Befehlskombinationen ist es unter Umständen möglich, daß ein Teilwerk seine Arbeit wiederholen muss. Solche Ressourcenkonflikte treten dann auf, wenn nicht jeder Teilphase völlig unabhängige Teilwerke zugeordnet sind. Ein Beispiel ist z.B. ein zeitgleicher Lesezugriff eines LOAD/STORE Befehles, welcher sich zwangsweise mit einem eventuellen MEM ACCESS eines anderen Befehles überschneidet. Abhilfe können hier Dual-Port RAM, Havard-Architektur oder getrennte Code- und Datencaches schaffen. Welche drei verschiedenen Datenabhängigkeiten gibt es? RAW, WAW und WAR-Konflikte sind Datenabnhänigkeiten, welche in Pipelines auftreten können. Dabei ist das RAW-Problem für Pipelines typisch. WAR Konflikte treten eher bei Out-Of-Order Execution auf. Um Read-After-Write Konflikte aufzulösen, gibt es verschiedene Ansätze wie Softwarelösungen ( Compileroptimierung), Scoreboarding (zentrale Steuerlogik) und Forwarding (zusätzlicher Datenpfad). Was ist Forwarding? Beim Forwarding wird ein Bypass eingerichtet, welcher ein Ergebniss einer Operation schon einem Folgebefehl zur Verfügung stellt, bevor es überhaupt in ein Register geschrieben wurde. Aber trotz Load-Forwarding hat ein Ladebefehl eine Verzögerung, welche nicht gänzlich eliminiert werden kann. In diesem Fall kann die Delayed-Load Technik oder auch eine Befehlsumordnung Anhilfe schaffen. Was ist die Delayed Load-Technik? Bei der Delayed Load-Technik wird die Verzögerung nach einem LOAD Befehl als architektonisches Merkmal angesehn und den Compilerbauern offengelegt. Diese können nun durch Befehlsumordnungen versuchen, nach einem LOAD-Befehl einen datenunabhängigen Befehl einzufügen, um den Slot zu füllen. Zusammenfassung Pipelining Pipelines werden in allen modernen CPUs benutzt. Die UltraSparc2 hat neun und der P2 zwölf Stufen. Der Intel Pentium Itanium weißt eine 20 stufige Superpinepline (pipeline in der sich einzelne Stufen überlappen können) auf! Pipes werden heutzutage in Kombination mit der Superskalartechnik verwendet, um höchste Effizienz und Parallelverarbeitung gewährleisten zu können. Die fünf grundlegenden Stufen einer einfachen Pipeline sind IF,ID,EX,MEM und WB. Takte T = Befehle + (Pipestufen - 1) Folgende Abhängigkeiten verhindern, dass die CPI auf eins gehen: Strucual Hazards bzw. Ressourcenkonflikte IF und MEM wollen gleichzeitig auf Speicher lesend oder schreibend zugreifen. Das geht nicht, außer bei Dual-Port-RAM, welcher aber sehr teuer ist. Dieses Problem tritt aber bei modernen CPU's kaum noch auf, da eh intern eine Havard-ähnliche Architektur mit getrenntem Befehls- und Datencache gearbeitet wird. Data Hazards bzw. Datenabhängigkeiten Ein Folgebefehl wartet auf das Writeback der darüber liegenden Pipe, da er von diesem Befehl abhängig ist. Dies kann durch Nops bzw. Stalls ineffizient gelöst werden. Besser der Programmierer oder der Compiler löst diese Abhängigkeiten durch eine clevere Umordnung der Befehlsfolge auf. Es gibt aber noch eine andere Möglichkeit, welche aber hardwareseitig unterstützt werden muss. (VLIW, Superskalar) Forwarding Beim Forwarding werden Ergebnisse, sobald sie vorliegen an die nächste Stufe weitergereicht und nicht erst auf das Write Back gewartet. In anderen Worten: Das Ergebnis der ALU wird dieser sofort wieder eingespeist. Control Hazards bzw. Sprungverzögerungen Sprungergebnisse stehen erst in der Write Back Phase an. Moderne Prozessoren haben aber schon in der Fetch/Decode-Einheit eine Logik, welche die Zieladresse des Sprunges berechnet. Eine andere Möglichkeit ist die des spekulativen Ausführens. Hier tritt aber das Problem auf, dass viel Aufwand bei falscher Spekulation getrieben werden muss. Was ist der Unterschied zwischen echten und unechten Datenabhängigkeiten? Echte Datenabhängigkeiten sind RAW-Konflikte, bei dem ein Befehl auf die Beendigung eines Anderen warten muss, da er das Ergebnis als Operand benötigt. Unechte Datenabhängigkeit sind Abhängigkeiten, welche nur durch Namensabhängigkeit entstehen. Es gibt zwei Arten unechter Datenabhängigkeit: Antidependence sind WAR-Konflikte, welche entstehen, wenn ein Folgebefehl auf ein Register schreiben möchte, das noch von einem Anderen benutzt wird. Output Dependece sind WAW-Konflikte, welche entstehen, wenn mehrere Befehle auf ein und das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. D
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itdet, um höchste Effizienz und Parallelverarbeitung gewährleisten zu können. Die fünf grundlegenden Stufen einer einfachen Pipeline sind IF,ID,EX,MEM und WB. Takte T = Befehle + (Pipestufen - 1) <span>Folgende Abhängigkeiten verhindern, dass die CPI auf eins gehen: Strucual Hazards bzw. Ressourcenkonflikte IF und MEM wollen gleichzeitig auf Speicher lesend oder schreibend zugreifen. Das geht nicht, außer bei Dual-Port-RAM, welcher aber sehr teuer ist. Dieses Problem tritt aber bei modernen CPU's kaum noch auf, da eh intern eine Havard-ähnliche Architektur mit getrenntem Befehls- und Datencache gearbeitet wird. Data Hazards bzw. Datenabhängigkeiten Ein Folgebefehl wartet auf das Writeback der darüber liegenden Pipe, da er von diesem Befehl abhängig ist. Dies kann durch Nops bzw. Stalls ineffizient gelöst werden. Besser der Programmierer oder der Compiler löst diese Abhängigkeiten durch eine clevere Umordnung der Befehlsfolge auf. Es gibt aber noch eine andere Möglichkeit, welche aber hardwareseitig unterstützt werden muss. (VLIW, Superskalar) Forwarding Beim Forwarding werden Ergebnisse, sobald sie vorliegen an die nächste Stufe weitergereicht und nicht erst auf das Write Back gewartet. In anderen Worten: Das Ergebnis der ALU wird dieser sofort wieder eingespeist. Control Hazards bzw. Sprungverzögerungen Sprungergebnisse stehen erst in der Write Back Phase an. Moderne Prozessoren haben aber schon in der Fetch/Decode-Einheit eine Logik, welche die Zieladresse des Sprunges berechnet. Eine andere Möglichkeit ist die des spekulativen Ausführens. Hier tritt aber das Problem auf, dass viel Aufwand bei falscher Spekulation getrieben werden muss. Was ist der Unterschied zwischen echten und unechten Datenabhängigkeiten? Echte Datenabhängigkeiten sind RAW-Konflikte, bei dem ein Befehl auf die Beendigung eines Anderen warten muss,
Original toplevel document
Grundprinzipien der Rechnerarchitektureinen Verweis auf die Nächste enthalten. Sprünge sind einfach möglich. Angewandt wird dies in Form von Opcodes, welche nichts anderes als Adressen auf Mikroinstruktionen im Steuerspeicher sind. <span>Kapitel 6 - Pipelining Wozu dient Pipelining? Pipelining soll es ermöglichen Befehle überlappt auszuführen. Dazu sind ein einheitliches Befehlsformat fester Länge Grundlage. Deshalb werden werden nur auf Register getätigt. Für Speicheroperationen wird die LOAD / STORE Philosophie verfolgt, um langsame Hauptspeicherzugriffe zu minimieren. Was ist Voraussetzung für Pipelining? Die Befehlsverarbeitungsphase muss sich in mehrere voneinander unabhängige Phasen unterteilen lassen. Die einfachste Form einer Pipeline ist die 5-stufige mit folgenden Phasen: Befehl holen Befehl dekodieren Befehl ausführen Auf Speicher zugreifen Ergebnis in Register schreiben Moderene CPU's haben weitaus komplexere Pipelines, in denen die einzelnen Stufen wiederrum in mehrere sich überlappende Phasen aufgeteilt werden. Der allgemeine Aufbau einer (fünfstufigen) Pipeline Um Parallelität in der Befehlsausführungsphase zu erreichen, wird der Datenpfad so konstruiert, daß folgende (hier fünf) Phasen unabhänig voneinander arbeiten können. Nur so ist es möglich eine verzahnte Abarbeitung mehrerer Befehle zu erreichen. Abb.: Die Piplelinestufen Somit wird ,nachdem eine Pipeline gefüllt ist, im Optimalfall pro Takt ein Befehl fertig. (CPI = 1) Welche Pipeline-Konflikte müssen behandelt werden? Datenabhängigkeiten (Data Hazards) Sind logische Abhängigkeiten, welche eine verzögerte Abarbeitung erfordern, weil z.B. ein Folgebefehl auf ein Ergebnis eines anderen Befehles warten muss. Jump- / Branchverzögerungen (Control Hazards) Bei Sprungbefehlen liegt oft das Sprungziel nach der Dekodieung noch nicht fest. Somit müssen Techniken eingesetzt werden um diese Wartezeiten zu minimieren. (Branch Prediction) Ressourcenkonflikte (Structural Hazards) Bei bestimmten Befehlskombinationen ist es unter Umständen möglich, daß ein Teilwerk seine Arbeit wiederholen muss. Solche Ressourcenkonflikte treten dann auf, wenn nicht jeder Teilphase völlig unabhängige Teilwerke zugeordnet sind. Ein Beispiel ist z.B. ein zeitgleicher Lesezugriff eines LOAD/STORE Befehles, welcher sich zwangsweise mit einem eventuellen MEM ACCESS eines anderen Befehles überschneidet. Abhilfe können hier Dual-Port RAM, Havard-Architektur oder getrennte Code- und Datencaches schaffen. Welche drei verschiedenen Datenabhängigkeiten gibt es? RAW, WAW und WAR-Konflikte sind Datenabnhänigkeiten, welche in Pipelines auftreten können. Dabei ist das RAW-Problem für Pipelines typisch. WAR Konflikte treten eher bei Out-Of-Order Execution auf. Um Read-After-Write Konflikte aufzulösen, gibt es verschiedene Ansätze wie Softwarelösungen ( Compileroptimierung), Scoreboarding (zentrale Steuerlogik) und Forwarding (zusätzlicher Datenpfad). Was ist Forwarding? Beim Forwarding wird ein Bypass eingerichtet, welcher ein Ergebniss einer Operation schon einem Folgebefehl zur Verfügung stellt, bevor es überhaupt in ein Register geschrieben wurde. Aber trotz Load-Forwarding hat ein Ladebefehl eine Verzögerung, welche nicht gänzlich eliminiert werden kann. In diesem Fall kann die Delayed-Load Technik oder auch eine Befehlsumordnung Anhilfe schaffen. Was ist die Delayed Load-Technik? Bei der Delayed Load-Technik wird die Verzögerung nach einem LOAD Befehl als architektonisches Merkmal angesehn und den Compilerbauern offengelegt. Diese können nun durch Befehlsumordnungen versuchen, nach einem LOAD-Befehl einen datenunabhängigen Befehl einzufügen, um den Slot zu füllen. Zusammenfassung Pipelining Pipelines werden in allen modernen CPUs benutzt. Die UltraSparc2 hat neun und der P2 zwölf Stufen. Der Intel Pentium Itanium weißt eine 20 stufige Superpinepline (pipeline in der sich einzelne Stufen überlappen können) auf! Pipes werden heutzutage in Kombination mit der Superskalartechnik verwendet, um höchste Effizienz und Parallelverarbeitung gewährleisten zu können. Die fünf grundlegenden Stufen einer einfachen Pipeline sind IF,ID,EX,MEM und WB. Takte T = Befehle + (Pipestufen - 1) Folgende Abhängigkeiten verhindern, dass die CPI auf eins gehen: Strucual Hazards bzw. Ressourcenkonflikte IF und MEM wollen gleichzeitig auf Speicher lesend oder schreibend zugreifen. Das geht nicht, außer bei Dual-Port-RAM, welcher aber sehr teuer ist. Dieses Problem tritt aber bei modernen CPU's kaum noch auf, da eh intern eine Havard-ähnliche Architektur mit getrenntem Befehls- und Datencache gearbeitet wird. Data Hazards bzw. Datenabhängigkeiten Ein Folgebefehl wartet auf das Writeback der darüber liegenden Pipe, da er von diesem Befehl abhängig ist. Dies kann durch Nops bzw. Stalls ineffizient gelöst werden. Besser der Programmierer oder der Compiler löst diese Abhängigkeiten durch eine clevere Umordnung der Befehlsfolge auf. Es gibt aber noch eine andere Möglichkeit, welche aber hardwareseitig unterstützt werden muss. (VLIW, Superskalar) Forwarding Beim Forwarding werden Ergebnisse, sobald sie vorliegen an die nächste Stufe weitergereicht und nicht erst auf das Write Back gewartet. In anderen Worten: Das Ergebnis der ALU wird dieser sofort wieder eingespeist. Control Hazards bzw. Sprungverzögerungen Sprungergebnisse stehen erst in der Write Back Phase an. Moderne Prozessoren haben aber schon in der Fetch/Decode-Einheit eine Logik, welche die Zieladresse des Sprunges berechnet. Eine andere Möglichkeit ist die des spekulativen Ausführens. Hier tritt aber das Problem auf, dass viel Aufwand bei falscher Spekulation getrieben werden muss. Was ist der Unterschied zwischen echten und unechten Datenabhängigkeiten? Echte Datenabhängigkeiten sind RAW-Konflikte, bei dem ein Befehl auf die Beendigung eines Anderen warten muss, da er das Ergebnis als Operand benötigt. Unechte Datenabhängigkeit sind Abhängigkeiten, welche nur durch Namensabhängigkeit entstehen. Es gibt zwei Arten unechter Datenabhängigkeit: Antidependence sind WAR-Konflikte, welche entstehen, wenn ein Folgebefehl auf ein Register schreiben möchte, das noch von einem Anderen benutzt wird. Output Dependece sind WAW-Konflikte, welche entstehen, wenn mehrere Befehle auf ein und das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. D
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itWas ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adressraum verschiedenen I/O-Devices zuzuordnen oder Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Getrennten I/O Adressraum, bei dem auf einer speziellen Adressleitung di
Original toplevel document
Grundprinzipien der Rechnerarchitekturauf. Ein DMA-Controller wirkt wie ein weiterer Prozessor am Bus. Um Inkonsistenzen im Speicher zu vermeiden, muss ein DMA-Controller eng mit dem Speichermanagment des Systems zusammenarbeiten. <span>Was ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adressraum verschiedenen I/O-Devices zuzuordnen oder Getrennten I/O Adressraum, bei dem auf einer speziellen Adressleitung die E/A-Adresse auf den Bus gelegt wird. (veraltete Variante) Was ist eine Task? Ein Task ist ein eigenständiges Programm / Prozess von vielen im Multitasksystem. Es wird von einem TSS (Task State Segment) beschrieben. Bei einem Taskwechsel werden alle Informationen in diesem TSS gespeichert. Jeder TSS-Deskriptor steht in der GDT. Die GDT hat beim i486 8192 Einträge, jedoch ist der 0. Eintrag immer leer. Somit sind maximal 8191 verschiedene Prozesse möglich (inclusive des Betriebssystems). Wie werden Task-Wechsel realisiert? Ein Taskwechsel geschieht durch Auswahl eines Task-Gates aus Globaler Deskriptor Tabelle (Task State Segment = TSS). Ein TSS Enthält alle Informationen, die einen Task ausmachen: verwendete Prozessor-Register LDT-Selektor (einer Pro Task) welche die Segment-Deskriptoren des Prozesses enthält Stack-Segment-Pointer Verwaltungsinformation Adresse der Paging-Tabellen I/O-Map Base Adresse Busy-Bit, definiert den aktuell rechnenden Task (genau einer im System) TR (Task Register) enthält den aktuellen TSS (Selektor des Descriptors des aktuellen TSS) TSS-Descriptoren nur in GDT! Bsp: Scheduler als Task ( Umschalter ) Umschalten durch jeweiligen Austausch des Back-Link, IRETD zum anderen Task, z.B. Timer-Interrupt-Task. Welche Möglichkeiten für Privilegwechsel gibt es? CALL in eine Prozedur mit anderen Privilegde-Level (CALL-Gate) JMP in eine Prozedur mit anderen Privi legde-Level (TASK-Gate) INT (TRAP-Gate) TASK-Gate durch erzwungenen Prozeßwechsel IRET Rücksprung aus INT-Handler Was ist der Unterschied zwischen einem Selektor und einem Deskriptor? Ein Selektor Segment-Register wählt einen Deskriptor in (GLI)DT aus, ein Deskriptor Eintrag in (GLI)DT, beschreibt das Segment. Weshalb ist es sinnvoll, dass ein TSS-Descriptor nur in der GDT stehen darf? Es soll verhindert werden, daß ein USER-Programm in einen anderen Task springt. Da Taskwechsel nur über TASK-Gates erfolgen (dieses zeigt auf einen TSS-Deskriptor) muß der CurrentPrivilegdeLevel (CPL vom CS:) numerisch kleiner sein, als das des geforderten TSS-Deskriptor (DPL) bzw. kleiner als der (RPL) des Segments wo sich der TSS-Deskriptor aufhält. Damit wird sichergestellt, daß der Taskwechsel nur von "höherem" Code (OS) aus ausgeführt werden kann. Würde ein TSS-Deskriptor in der LDT stehen, könnte es dort mit einem höheren RPL versehen werden, und der USER-Code könnte sich zum OS-CODE etablieren! Welche Grundtypen von Deskriptoren gibt es? IDT LDT GDT CODE-Segment DATA-Segment STACK-Segment CODE-Segment DATA-Segment STACK-Segment INT-Gate TRAP-Gate TASK-Gate TASK-Gate TASK-Gate CALL-Gate Welche grundlegenden Adressierungsarten gibt es? Unmittelbare Adressierung Direktadressierung (Direct Adressing) Registeradressierung Indirekte Registeradressierung Indizierte Adressierung Basisindizierte Adressierung Stapeladressierung Unmittelbare Adressierung Der Adressteil der Instruktion enthält den Operanden selbst, anstatt eines Verweises. Solche Operanden werden als Direktoperanden (Immediate) bezeichnet Bsp: MOV R4, 5H (5H wird direkt in R4 gespeichert) Direktadressierung (Direct Adressing) Es wird eine volle Adresse des Operanden angegeben Deshalb nur für globale Variablen anwendbar, da Instruktion immer auf gleiche Speicehrzeile zugreift Registeradressierung Das gleiche Prinzip wie Direct Adressing, nur das Register anstelle von Speicherzellen verwendet werden In Registern sollten die am häufigsten verwendeten Variablen abgelegt werden, da Register vielfach schneller als Hauptspeicher sind Load/Store-Architekturen nutzen fast nur diesen Registermode (außer es muss vom oder zum Speicher transferiert werden) Indirekte Registeradressierung Die Adresse wird nicht direkt angegeben, sondern indirekt über ein Register Das Register enthält somit einen Pointer auf eine Speicherzelle Vorteil ist, daß auf Speicher referenziert werden kann, aber keine volle Speicheradresse notwendig wird Indizierte Adressierung Der Speicher wird durch Angabe eines Registers und eines konstanten Offsets adressiert Häufig benutzt bei Arrayzugriffen, wie A = B[i] (MOV R1, B[R2]) Basisindizierte Adressierung Speicheradresse wird hier durch Addition zweier Register und einen optionalen Offset berechnet Eines der Register stellt die Basis dar und ein anderes den Index Stapeladressierung Hier ist gar keine Adressangabe notwendig Somit sind die Instruktionen sehr kurz Die Stapeladressierung arbeitet mit der umgekehrten polnischen Notation (Postfix) Kapitel 3 - Speicherschutz und Multitasking Um unberechtigte Zugriffe, Datenaufrufe oder Systemprozedurecalls zu vermeiden und Task-Isolation zu gewährleisten, ist ein ausgeklügeltes Sp
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adressraum verschiedenen I/O-Devices zuzuordnen oder <span>Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Getrennten I/O Adressraum, bei dem auf einer speziellen Adressleitung die E/A-Adresse auf den Bus gelegt wird. (veraltete Variante) <span>
Original toplevel document
Grundprinzipien der Rechnerarchitekturauf. Ein DMA-Controller wirkt wie ein weiterer Prozessor am Bus. Um Inkonsistenzen im Speicher zu vermeiden, muss ein DMA-Controller eng mit dem Speichermanagment des Systems zusammenarbeiten. <span>Was ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adressraum verschiedenen I/O-Devices zuzuordnen oder Getrennten I/O Adressraum, bei dem auf einer speziellen Adressleitung die E/A-Adresse auf den Bus gelegt wird. (veraltete Variante) Was ist eine Task? Ein Task ist ein eigenständiges Programm / Prozess von vielen im Multitasksystem. Es wird von einem TSS (Task State Segment) beschrieben. Bei einem Taskwechsel werden alle Informationen in diesem TSS gespeichert. Jeder TSS-Deskriptor steht in der GDT. Die GDT hat beim i486 8192 Einträge, jedoch ist der 0. Eintrag immer leer. Somit sind maximal 8191 verschiedene Prozesse möglich (inclusive des Betriebssystems). Wie werden Task-Wechsel realisiert? Ein Taskwechsel geschieht durch Auswahl eines Task-Gates aus Globaler Deskriptor Tabelle (Task State Segment = TSS). Ein TSS Enthält alle Informationen, die einen Task ausmachen: verwendete Prozessor-Register LDT-Selektor (einer Pro Task) welche die Segment-Deskriptoren des Prozesses enthält Stack-Segment-Pointer Verwaltungsinformation Adresse der Paging-Tabellen I/O-Map Base Adresse Busy-Bit, definiert den aktuell rechnenden Task (genau einer im System) TR (Task Register) enthält den aktuellen TSS (Selektor des Descriptors des aktuellen TSS) TSS-Descriptoren nur in GDT! Bsp: Scheduler als Task ( Umschalter ) Umschalten durch jeweiligen Austausch des Back-Link, IRETD zum anderen Task, z.B. Timer-Interrupt-Task. Welche Möglichkeiten für Privilegwechsel gibt es? CALL in eine Prozedur mit anderen Privilegde-Level (CALL-Gate) JMP in eine Prozedur mit anderen Privi legde-Level (TASK-Gate) INT (TRAP-Gate) TASK-Gate durch erzwungenen Prozeßwechsel IRET Rücksprung aus INT-Handler Was ist der Unterschied zwischen einem Selektor und einem Deskriptor? Ein Selektor Segment-Register wählt einen Deskriptor in (GLI)DT aus, ein Deskriptor Eintrag in (GLI)DT, beschreibt das Segment. Weshalb ist es sinnvoll, dass ein TSS-Descriptor nur in der GDT stehen darf? Es soll verhindert werden, daß ein USER-Programm in einen anderen Task springt. Da Taskwechsel nur über TASK-Gates erfolgen (dieses zeigt auf einen TSS-Deskriptor) muß der CurrentPrivilegdeLevel (CPL vom CS:) numerisch kleiner sein, als das des geforderten TSS-Deskriptor (DPL) bzw. kleiner als der (RPL) des Segments wo sich der TSS-Deskriptor aufhält. Damit wird sichergestellt, daß der Taskwechsel nur von "höherem" Code (OS) aus ausgeführt werden kann. Würde ein TSS-Deskriptor in der LDT stehen, könnte es dort mit einem höheren RPL versehen werden, und der USER-Code könnte sich zum OS-CODE etablieren! Welche Grundtypen von Deskriptoren gibt es? IDT LDT GDT CODE-Segment DATA-Segment STACK-Segment CODE-Segment DATA-Segment STACK-Segment INT-Gate TRAP-Gate TASK-Gate TASK-Gate TASK-Gate CALL-Gate Welche grundlegenden Adressierungsarten gibt es? Unmittelbare Adressierung Direktadressierung (Direct Adressing) Registeradressierung Indirekte Registeradressierung Indizierte Adressierung Basisindizierte Adressierung Stapeladressierung Unmittelbare Adressierung Der Adressteil der Instruktion enthält den Operanden selbst, anstatt eines Verweises. Solche Operanden werden als Direktoperanden (Immediate) bezeichnet Bsp: MOV R4, 5H (5H wird direkt in R4 gespeichert) Direktadressierung (Direct Adressing) Es wird eine volle Adresse des Operanden angegeben Deshalb nur für globale Variablen anwendbar, da Instruktion immer auf gleiche Speicehrzeile zugreift Registeradressierung Das gleiche Prinzip wie Direct Adressing, nur das Register anstelle von Speicherzellen verwendet werden In Registern sollten die am häufigsten verwendeten Variablen abgelegt werden, da Register vielfach schneller als Hauptspeicher sind Load/Store-Architekturen nutzen fast nur diesen Registermode (außer es muss vom oder zum Speicher transferiert werden) Indirekte Registeradressierung Die Adresse wird nicht direkt angegeben, sondern indirekt über ein Register Das Register enthält somit einen Pointer auf eine Speicherzelle Vorteil ist, daß auf Speicher referenziert werden kann, aber keine volle Speicheradresse notwendig wird Indizierte Adressierung Der Speicher wird durch Angabe eines Registers und eines konstanten Offsets adressiert Häufig benutzt bei Arrayzugriffen, wie A = B[i] (MOV R1, B[R2]) Basisindizierte Adressierung Speicheradresse wird hier durch Addition zweier Register und einen optionalen Offset berechnet Eines der Register stellt die Basis dar und ein anderes den Index Stapeladressierung Hier ist gar keine Adressangabe notwendig Somit sind die Instruktionen sehr kurz Die Stapeladressierung arbeitet mit der umgekehrten polnischen Notation (Postfix) Kapitel 3 - Speicherschutz und Multitasking Um unberechtigte Zugriffe, Datenaufrufe oder Systemprozedurecalls zu vermeiden und Task-Isolation zu gewährleisten, ist ein ausgeklügeltes Sp
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itramms wird komplett eingefroren auch die invarianten Anteile werden gesichert, der Programmzustand ist damit leicht zugreifbar weit verbreitet bei Allzweckbetriebssystemen (z.B. UNIX & Co.) <span>partielle Sicherung der im weiteren Verlauf nicht gesicherten Register der CPU-Status des unterbrochenen Programms wird teilweise eingefroren es wird nur der wirklich von Änderungen betroffene Anteil gesichert der Programmzustand ist damit nicht leicht zugreifbar weit verbreitet bei Spezialzweckbetriebssystemen <span>
Original toplevel document
Grundprinzipien der Rechnerarchitekturrt das Big-Endian-Format. Falls Worte so in den Speicher passen, das keine Verschiebungen auftreten, heißt der Speicher aligned. Prüfen kann man dies durch die Formel Adresse mod Wortlänge = 0? <span>Kapitel 2 - Interrupts und DMA Klassifizieren Sie die verschiedenen Unterbrechungen! Wenn in der Literatur von Interrupts gesprochen wird, so werden oft externe, asynchrone Interrupts gemeint, welche meistens in Zusammenhang mit E/A-Geräten auftreten. Wie arbeiten Traps (Fangstellen?) Traps sind eine Art automatische Prozeduraufrufe, welche durch eine vom Programm verursachte Bedingung eingeleitet werden. Solch eine Bedingung kann z.B. Gleitkommaüberlauf, Schutzverletzung oder Stapelüberlauf. Findet ein Überlauf statt, so stoppt die Ablaufsteuerung die Ausführung und holt von einer bestimmten Stelle im Speicher die Adresse des Trap-Handlers (Prozedur), mit der dann der Programmcounter überschrieben wird. Wesentliches Merkmal eines Traps ist, daß es durch Ausnahmebedingungen ausgelöst wird, welche durch Hardware oder Mikroprogramme erkannt werden. Wie arbeiten Interrupts Interrupts sind Unterbrechungen der Ablaufsteuerung. Wie es für Traps Trap-Handler gibt, gibt es für Interrupts Interrupt-Handler. Nach Abarbeitung des Interrupt-Handlers wird die Kontrolle wieder an das Programm zurückgegeben. Der interne Zustand des Prozessors (IP, Register, ...) muss nun exakt wiederhergestellt werden. Der Unterschied zwischen Traps und Interrupts ist nun, daß Traps synchron mit dem ausgeführten Programm laufen. Deshalb werden sie auch erst nach der Befehlsausführung erkannt und ausgeführt. Asynchrone Interrupts sind dagegen unabhängig vom gerade ausgeführten Programm. Interrupt’s stammen von echten physikalischen INT-Quellen wie z.B. IRQ3 von COM1 kommt. Diese springen über ein Interrupt-Gate. Interrupt’s die per Software mit INT-Befehl ausgelöst werden, springen über Trap-Gates! Wenn ein Interrupt ein Interrupt-Gate durchläuft, wird das IF=0 automatisch gesetzt, d.h. es gehen überhaupt keine Interrupts mehr durch. Asynchrone Interrupts können also nicht unterbrochen werden. Trap-Gates dürfen unterbrochen werden, da sie nicht zeitkritisch sind. Interrupt- und Trap-Gates führen nicht zu Taskwechsel über ein TSS. Das retten der Register ist dem INT-Handler überlassen. Was sind Software Interrupts? Software-Interrupts werden von Programmen mit Hilfe von speziellen Maschinenbefehlen aufgerufen. Dabei müssen diese nur eine Nummer für das benötigte Interrupt kennen. Über diese Nummer wird in der Interrupt-Vektor-Tabelle die Adresse des Interrupt-Unterprogrammes (ISR) referenziert und ausgeführt. Was versteht man unter internen und externen Interrupts? Externe Interrupts sind asynchron, wie nichtvektorisierte und vektorisierte Interrupts. Interne sind synchron, wie Software Interrupts oder Exection-Traps (Reaktionen auf interne Fehler wie FPU-Errors oder Page-Faults). Was ist Polling? Polling ist das zyklische Abfragen von einen oder mehreren E/A-Devices zur Feststellung der Kommunikationsbereitschaft bzw. zum Einholen von Kommunikationswünschen. Vorteile des Pollings Nachteile des Pollings Einfach zu Implementieren Hoher Programm-Overhead Kommunikationsanforderungen erfolgen synchron zum Programmablauf Die meisten Anfragen an die Geräte sind unnötig Je mehr Geräte am Bus hängen, um so mehr steigt Reaktionszeit. Priorisierung bei zeitgleichen Anfragen erfordert zusätzlichen Zeitaufwand Aufgrund der vielen Nachteile sollte besser eine asynchrone Kommunikation mit den Geräten durch die Hardware unterstützt werden (Interrupts). Das Interrupt-Prinzip Es kann auch über eine Art "hardware-gestütztes Polling" über spezielle Interrupt-Signalleitungen eine Kommunikationsanforderung festgestellt werden. Dazu muss aber die Befehlsverarbeitungschleife um eine Unterbrechungsanfrage erweitert werden. Erklären Sie den Unterschied zwischen vektorisierten und nichtvektorisierten Interrupts! Man unterscheidet vektorisierten und nichtvektorisierten Interrupt. Bei nichtvektorisierten Interrupts wird dem Interruptsignal eine feste Adresse zugeordnet. Bei vektorisierten Interrupts wird dynamisch eine wahlfreie Adresse zugeordnet, welche durch die CPU über ein definiertes Protokoll vom Datenbus gelesen wird. Was passiert beim Auftreten eines Interrupts? 1. Sperren weiterer Unterbrechungen mit gleicher oder geringerer Priotität Unterbrechungen mit höherer Wichtigkeit dürfen normalerweise solche mit geringerer Wichtigkeit wieder unterbrechen 2. Rettung wichtiger Register-Informationen(Prozessorstatus) alle Prozessor-Register retten, die durch die Interruptbehandlung überschrieben würden heute gibt es dafür spezielle Maschinenbefehle 3. Bestimmen der Interruptquelle (durch Hardware realisiert) 4. Laden des zugehörigen Interruptvektors d.h. das Herstellen des Anfangszustandes für gewählte Interruptroutine 5. Abarbeitung der Interruptroutine Retten weiterer Zustandsinformationen, sofern nicht durch Hardware realisiert meistens Übernahme weiterer Parameter von definierten Stellen (bei Systemaufruf Ruf-Nr. und weitere Parameter oder bei Geräte-Interrupt Gerätestatusbits wie E/A Fortschritt, Fehler etc.) eigentliche Behandlung des Interrupts, z.B. Setzen eines Flags (z.B. bei Gleitkommaüberlauf oder Aufruf zum Rückpositionieren und erneutem Lesen bei Lesefehler bei Magnetbandkassette (komplizierterer Fall) 6. Rückkehr zur unterbrochenen Aufgabe entweder Rückspeichern der geretteten Registerinformationen, d.h. Wiederherstellen des Prozessorzustandes oder Bearbeitung einer neuen Aufgabe, z.B. bei Uhrinterrupt nach Ablauf einer Zeitscheibe oder Zustand "HALT" nach schwerem Fehler, z.B. Spannungsausfall (abort) Welche beiden Zustandssicherungskonzepte gibt es totale Sicherung aller bislang nicht automatisch gesicherten Register der CPU-Status des unterbrochenen Programms wird komplett eingefroren auch die invarianten Anteile werden gesichert, der Programmzustand ist damit leicht zugreifbar weit verbreitet bei Allzweckbetriebssystemen (z.B. UNIX & Co.) partielle Sicherung der im weiteren Verlauf nicht gesicherten Register der CPU-Status des unterbrochenen Programms wird teilweise eingefroren es wird nur der wirklich von Änderungen betroffene Anteil gesichert der Programmzustand ist damit nicht leicht zugreifbar weit verbreitet bei Spezialzweckbetriebssystemen Was stellt das Hauptproblem bei Interrupts dar Interrupts verhalten sich nicht deterministisch. D.h. ihre Abarbeitungszeit variiert. Sie sollte trotzdem so gering wie möglich gehalten werden. Warum wird DMA oft Interrupts vorgezogen? Zwar befreien Interrupts die Prozessoren vom Warten auf E/A Ereignisse, aber vektorisierte Interrupts benötigen viele Taktzyklen zu ihrer Abarbeitung. Dieser Overhead steigt natürlich, um so weniger Datenmengen bei einer Interruptauslösung übertragen werden. Interrupts werden erst nach der Befehlsabarbeitung erkannt und ausgeführt. Dies ist ein Problem bei Echtzeitanwendungen, da sich diese Verzögerung negativ auswirken kann. Außerdem kommt es durch Interrupts bei Instruction-Set-Parallismus oft zu Pipeline-Neustarts. Die Lösung dieser Probleme wäre ein direkter Speicherzugriff eines Devices, da so der Prozessor komplett umgangen werden kann. Wie kann DMA implementiert werden? Zentral Ein zentraler DMA-Controller steht allen Geräten zu Verfügung. Dezentral: Jede E/A-Einheit hat ihren eigenen DMA-Controller implementiert und kann selbst Busmaster werden Probleme bei DMA treten vor allem durch ihre Unabhängigkeit und die dadurch notwendigen Schutzmaßnahmen auf. Ein DMA-Controller wirkt wie ein weiterer Prozessor am Bus. Um Inkonsistenzen im Speicher zu vermeiden, muss ein DMA-Controller eng mit dem Speichermanagment des Systems zusammenarbeiten. Was ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adr
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itWelche beiden Zustandssicherungskonzepte gibt es totale Sicherung aller bislang nicht automatisch gesicherten Register der CPU-Status des unterbrochenen Programms wird komplett eingefroren auch die invarianten Anteile werden gesichert, der Programmzustand ist damit leicht zugreifbar weit verbreitet bei Allzweckbetriebssystemen (z.B. UNIX & Co.) partielle Sicherung der im weiteren Verlauf nicht gesicherten Register der CPU-Status des unterbrochenen Programms wird teilweise eingefroren es wird nur der wirklich von Änderungen bet
Original toplevel document
Grundprinzipien der Rechnerarchitekturrt das Big-Endian-Format. Falls Worte so in den Speicher passen, das keine Verschiebungen auftreten, heißt der Speicher aligned. Prüfen kann man dies durch die Formel Adresse mod Wortlänge = 0? <span>Kapitel 2 - Interrupts und DMA Klassifizieren Sie die verschiedenen Unterbrechungen! Wenn in der Literatur von Interrupts gesprochen wird, so werden oft externe, asynchrone Interrupts gemeint, welche meistens in Zusammenhang mit E/A-Geräten auftreten. Wie arbeiten Traps (Fangstellen?) Traps sind eine Art automatische Prozeduraufrufe, welche durch eine vom Programm verursachte Bedingung eingeleitet werden. Solch eine Bedingung kann z.B. Gleitkommaüberlauf, Schutzverletzung oder Stapelüberlauf. Findet ein Überlauf statt, so stoppt die Ablaufsteuerung die Ausführung und holt von einer bestimmten Stelle im Speicher die Adresse des Trap-Handlers (Prozedur), mit der dann der Programmcounter überschrieben wird. Wesentliches Merkmal eines Traps ist, daß es durch Ausnahmebedingungen ausgelöst wird, welche durch Hardware oder Mikroprogramme erkannt werden. Wie arbeiten Interrupts Interrupts sind Unterbrechungen der Ablaufsteuerung. Wie es für Traps Trap-Handler gibt, gibt es für Interrupts Interrupt-Handler. Nach Abarbeitung des Interrupt-Handlers wird die Kontrolle wieder an das Programm zurückgegeben. Der interne Zustand des Prozessors (IP, Register, ...) muss nun exakt wiederhergestellt werden. Der Unterschied zwischen Traps und Interrupts ist nun, daß Traps synchron mit dem ausgeführten Programm laufen. Deshalb werden sie auch erst nach der Befehlsausführung erkannt und ausgeführt. Asynchrone Interrupts sind dagegen unabhängig vom gerade ausgeführten Programm. Interrupt’s stammen von echten physikalischen INT-Quellen wie z.B. IRQ3 von COM1 kommt. Diese springen über ein Interrupt-Gate. Interrupt’s die per Software mit INT-Befehl ausgelöst werden, springen über Trap-Gates! Wenn ein Interrupt ein Interrupt-Gate durchläuft, wird das IF=0 automatisch gesetzt, d.h. es gehen überhaupt keine Interrupts mehr durch. Asynchrone Interrupts können also nicht unterbrochen werden. Trap-Gates dürfen unterbrochen werden, da sie nicht zeitkritisch sind. Interrupt- und Trap-Gates führen nicht zu Taskwechsel über ein TSS. Das retten der Register ist dem INT-Handler überlassen. Was sind Software Interrupts? Software-Interrupts werden von Programmen mit Hilfe von speziellen Maschinenbefehlen aufgerufen. Dabei müssen diese nur eine Nummer für das benötigte Interrupt kennen. Über diese Nummer wird in der Interrupt-Vektor-Tabelle die Adresse des Interrupt-Unterprogrammes (ISR) referenziert und ausgeführt. Was versteht man unter internen und externen Interrupts? Externe Interrupts sind asynchron, wie nichtvektorisierte und vektorisierte Interrupts. Interne sind synchron, wie Software Interrupts oder Exection-Traps (Reaktionen auf interne Fehler wie FPU-Errors oder Page-Faults). Was ist Polling? Polling ist das zyklische Abfragen von einen oder mehreren E/A-Devices zur Feststellung der Kommunikationsbereitschaft bzw. zum Einholen von Kommunikationswünschen. Vorteile des Pollings Nachteile des Pollings Einfach zu Implementieren Hoher Programm-Overhead Kommunikationsanforderungen erfolgen synchron zum Programmablauf Die meisten Anfragen an die Geräte sind unnötig Je mehr Geräte am Bus hängen, um so mehr steigt Reaktionszeit. Priorisierung bei zeitgleichen Anfragen erfordert zusätzlichen Zeitaufwand Aufgrund der vielen Nachteile sollte besser eine asynchrone Kommunikation mit den Geräten durch die Hardware unterstützt werden (Interrupts). Das Interrupt-Prinzip Es kann auch über eine Art "hardware-gestütztes Polling" über spezielle Interrupt-Signalleitungen eine Kommunikationsanforderung festgestellt werden. Dazu muss aber die Befehlsverarbeitungschleife um eine Unterbrechungsanfrage erweitert werden. Erklären Sie den Unterschied zwischen vektorisierten und nichtvektorisierten Interrupts! Man unterscheidet vektorisierten und nichtvektorisierten Interrupt. Bei nichtvektorisierten Interrupts wird dem Interruptsignal eine feste Adresse zugeordnet. Bei vektorisierten Interrupts wird dynamisch eine wahlfreie Adresse zugeordnet, welche durch die CPU über ein definiertes Protokoll vom Datenbus gelesen wird. Was passiert beim Auftreten eines Interrupts? 1. Sperren weiterer Unterbrechungen mit gleicher oder geringerer Priotität Unterbrechungen mit höherer Wichtigkeit dürfen normalerweise solche mit geringerer Wichtigkeit wieder unterbrechen 2. Rettung wichtiger Register-Informationen(Prozessorstatus) alle Prozessor-Register retten, die durch die Interruptbehandlung überschrieben würden heute gibt es dafür spezielle Maschinenbefehle 3. Bestimmen der Interruptquelle (durch Hardware realisiert) 4. Laden des zugehörigen Interruptvektors d.h. das Herstellen des Anfangszustandes für gewählte Interruptroutine 5. Abarbeitung der Interruptroutine Retten weiterer Zustandsinformationen, sofern nicht durch Hardware realisiert meistens Übernahme weiterer Parameter von definierten Stellen (bei Systemaufruf Ruf-Nr. und weitere Parameter oder bei Geräte-Interrupt Gerätestatusbits wie E/A Fortschritt, Fehler etc.) eigentliche Behandlung des Interrupts, z.B. Setzen eines Flags (z.B. bei Gleitkommaüberlauf oder Aufruf zum Rückpositionieren und erneutem Lesen bei Lesefehler bei Magnetbandkassette (komplizierterer Fall) 6. Rückkehr zur unterbrochenen Aufgabe entweder Rückspeichern der geretteten Registerinformationen, d.h. Wiederherstellen des Prozessorzustandes oder Bearbeitung einer neuen Aufgabe, z.B. bei Uhrinterrupt nach Ablauf einer Zeitscheibe oder Zustand "HALT" nach schwerem Fehler, z.B. Spannungsausfall (abort) Welche beiden Zustandssicherungskonzepte gibt es totale Sicherung aller bislang nicht automatisch gesicherten Register der CPU-Status des unterbrochenen Programms wird komplett eingefroren auch die invarianten Anteile werden gesichert, der Programmzustand ist damit leicht zugreifbar weit verbreitet bei Allzweckbetriebssystemen (z.B. UNIX & Co.) partielle Sicherung der im weiteren Verlauf nicht gesicherten Register der CPU-Status des unterbrochenen Programms wird teilweise eingefroren es wird nur der wirklich von Änderungen betroffene Anteil gesichert der Programmzustand ist damit nicht leicht zugreifbar weit verbreitet bei Spezialzweckbetriebssystemen Was stellt das Hauptproblem bei Interrupts dar Interrupts verhalten sich nicht deterministisch. D.h. ihre Abarbeitungszeit variiert. Sie sollte trotzdem so gering wie möglich gehalten werden. Warum wird DMA oft Interrupts vorgezogen? Zwar befreien Interrupts die Prozessoren vom Warten auf E/A Ereignisse, aber vektorisierte Interrupts benötigen viele Taktzyklen zu ihrer Abarbeitung. Dieser Overhead steigt natürlich, um so weniger Datenmengen bei einer Interruptauslösung übertragen werden. Interrupts werden erst nach der Befehlsabarbeitung erkannt und ausgeführt. Dies ist ein Problem bei Echtzeitanwendungen, da sich diese Verzögerung negativ auswirken kann. Außerdem kommt es durch Interrupts bei Instruction-Set-Parallismus oft zu Pipeline-Neustarts. Die Lösung dieser Probleme wäre ein direkter Speicherzugriff eines Devices, da so der Prozessor komplett umgangen werden kann. Wie kann DMA implementiert werden? Zentral Ein zentraler DMA-Controller steht allen Geräten zu Verfügung. Dezentral: Jede E/A-Einheit hat ihren eigenen DMA-Controller implementiert und kann selbst Busmaster werden Probleme bei DMA treten vor allem durch ihre Unabhängigkeit und die dadurch notwendigen Schutzmaßnahmen auf. Ein DMA-Controller wirkt wie ein weiterer Prozessor am Bus. Um Inkonsistenzen im Speicher zu vermeiden, muss ein DMA-Controller eng mit dem Speichermanagment des Systems zusammenarbeiten. Was ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adr
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itWelchen Nachteil hat die 1-Bit Sprungvorhersage? Es wird nicht nur bei einem Schleifenaustritt der Sprung falsch vorhergesagt, sondern auch die erste Vorhersage bei erneuter Verwendung der Schleife. Wie arbeitet die 2-Bit-Sprungvorhersage mit BHT? Durch einen einfachen Zähler kann man den Nachteil der 1-Bit-Vorhersage minimieren. Hier wird die Vorhersage erst geändert, wenn sie zwe
Original toplevel document
Grundprinzipien der Rechnerarchitekturund das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! <span>Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. Da das Ziel eines Sprungbefehles oft erst festgestellt werden muss, liegt diese Adresse erst ab der MEM ACCESS Phase bereit. Somit kann das erneute Laden des Programmcounters auch erst in dieser Phase geschehen. So verzögert sich das Holen des nächsten Befehles um einige Takte. Durch eine Optimierung der Pipeline kann zwar die stall-Phase verkleinert, aber nicht ausgeschlossen werden. (durch Verlegung des Sprungbedingungstests in die Decode-Phase) Welche Methoden gibt es zur Reduzierung von Sprungverlusten? Predict Not Taken / Predict-Taken (fixed prediction) Objektcode basiert (statisch) dynamisch Brach-Prediction mit History Buffern (correlating / non-correlating) Delayed-Branch Wie funktioniert die Predict-Not-Taken bzw. Predict-Taken Methodik? Hier wird nichts weiter gemacht als entweder alle Sprünge voreingestellt abzulehnen oder alle Sprünge ersteinmal ohne Gewähr duchzuführen. Allgemeine Programmstatistiken sagen aus, dass mehr bedingte Sprünge ausgeführt als abgewiesen werden. Wie funktioniert die Delayed-Branch Methode? Hier wird ein sprungunabhängiger Befehl in den Delay Slot eingeschleust. Dies muss somit schon von den Compilerbauern berücksichtigt werden. Um diese Bedingung zu Umgehen wird die "Cancelling Branches"-Technik eingesetzt. Im Mittel werden dann trotzdem die Branch-Verluste verringert. Durch ein zusätzliches Bit im Befehlscode gibt der Compiler die wahrscheinlichste Sprungrichtung an. Nun kann entsprechend dieser Annahme ein Befehl in den Delay Slot eingefügt werden, der nur gültig ist, wenn der Sprung richtig vorhergesagt war. Falls nicht wird der Delay-Slot-Befehl abgebrochen (gecancelt). Dynamische Branch-Prediction Um Wartezeiten durch bedingte Sprünge zu vermeiden, sollte das Sprungziel schon mit dem Ende der Fetch-Phase zur Verfügung stehen. Es gibt zwei Ansätze Sprungzielspeicher (branch-target-buffer = BTB) Sprungvorhersage-Puffer (Branch History Table = BHT) Wie arbeitet eine Branch History Table? In dieser Tabelle wird im Grunde nur durch ein Bit (oder mehr) vermerkt, ob ein Sprung durchgeführt wurde oder nicht. Als Index der Tabelle dient der niederwertige Teil der Adresse des dazugehörigen Sprungbefehls. Nun kann die Pipeline in der Fetchphase nach einem eventuell vorhandenen Eintrag schauen und diesen als Entscheidungsgrundlage nehmen. Welchen Nachteil hat die 1-Bit Sprungvorhersage? Es wird nicht nur bei einem Schleifenaustritt der Sprung falsch vorhergesagt, sondern auch die erste Vorhersage bei erneuter Verwendung der Schleife. Wie arbeitet die 2-Bit-Sprungvorhersage mit BHT? Durch einen einfachen Zähler kann man den Nachteil der 1-Bit-Vorhersage minimieren. Hier wird die Vorhersage erst geändert, wenn sie zweimal falsch war. Es hat sich gezeigt, daß durch Zähler mit mehr als 2 Bit sich die Performance nicht weiter signifikant erhöhen läßt. Abb.: 2-Bit-Sprungvorhersagenautomat Wie arbeitet der Branch-Target-Buffer? Hier wird die Zieladresse eines gemachten Sprungs direkt gespeichert, um diese gegebenfalls ohne Verzögerung wiederzuverwenden. So kann bei einem Hit (Index stimmt mit Befehlsadresse überein) sofort der Instruction Counter mit der dazugehörigen Sprungadresse geladen werden). Exeptions Exeptions unterbrechen den Programmablauf Aufgrund verschiedenster Fehler oder Anforderungen, wie Softwareinterrupts, Page Faults oder anderen Verletzungen. Bei synchronen Exeptions treten die Fehler stehts an der gleichen Programmstelle auf. Asynchrone werden durch externe Geräte ausgelöst und können nach dem laufenden Befehl ausgeführt werden. Was sind Precice Exeptions? Sind Exeptions, welche garantieren, dass die Exeptions direkt nach oder während des Befehles ausgeführt werden und kein Folgebefehl vorher abgearbeitet wird. Zusammenfassung der Sprungvorhersage Sprungvorhersage ist extrem wichtig für Pipelining und Superskalarität, um stalls und Verzögerungen zu minimieren. Bei statischer Vorhersage werden Rückwärtssprünge meist erst durchgeführt und Vorwärtssprünge nicht. Wurde ein Sprung falsch vorhergesagt, muss die angefangene Instruktion rückgängig gemacht werden, was aufwendig ist. Deshalb gibt es ausgeklügelte Verfahren für die Branch Prediction. Statische Sprungvorhersage Es werden Compiler benutzt, die spezielle Sprungbefehle mitführen, welche ein Bit für die Sprungvorhersage enthalten. Da der Compiler ja weiß, wie oft eine Schleife durchlaufen wird, ist das sehr effizient. Dies muss aber architektonisch von der Hardware unterstützt werden. Des Weiteren ist kein Speicher für die History Table notwendig, was es kostengünstiger macht. Statische Verfahren erreichen eine Trefferrate von 65 bis 85%, was für moderne CPU's mit Superpipelines zu wenig ist. Dynamische Verfahren erreichen Trefferraten bei der Vorhersage von 98% und mehr! Dynamische Sprungvorhersage Es gibt zwei grundlegende Methoden. BHT und BTB. Die Branch History Table (Branch Predicion Buffer) ist ein Cache, in der alle bedingten Sprünge protokolliert werden. ( bis zu mehereren Tausend) Einfachste Version enthält ein Valid-Bit (Branch taken oder nicht), welches durch den niederwertigen Teil der Sprungadresse adressiert wird. Kompliziere Implementationen arbeiten nach dem n-Wege Prinzip. Durch Second Chance kann dieses Verfahren noch verbessert werden. Der Branch Target Buffer speichert nicht nur die taken-Bits, sondern auch die Sprungzieladresse, um null Verluste bei wiederholtem Aufruf zu haben. Das setzt voraus, dass nur taken branches aufgenommen werden. Bei einem Hit in der BTB kann somit während der Fetch Phase der Program Counter überschrieben werden. Werden keine History Bits mitgeführt spricht man vom BTAB. Wie arbeitet Second Chance? Nach Beenden einer Schleife wird ein Sprung logischerweise falsch vorhergesagt. Um zu vermeiden, dass nun fälschlicherweise das Sprungbit falsch gesetzt wird (da ja die gleiche Schleife noch mal durchlaufen werden kann), ändert man dieses erst nach der zweiten falschen Vorhersage. Leicht zu implementieren als Finite State Machine mit vier Zuständen. Nachteil der dynamischen Vorhersage ist die notwendige teuere und komplexere Hardware. Was ist der Vorteil von BHT gegenüber BTB? Branch Target Buffer loggen nur, ob ein Sprung genommen wurde oder nicht. Daher gibt es bei MIPS-Architekturen die BTB verwenden immernoch die sogenannten Branch Delay Slots, da die Sprungadresse trotzdem neu ermittelt werden muss. BHT beseitigen diesen Nachteil, da sie die Sprungadresse mit abspeichern und diese dann sofort in den IP geladen werden kann. Was sind Correlating Predictors? Betrachten wir folgendes Codefragment, fällt uns auf, daß ein Branch Predictor, der nur einen Sprung als Entscheidungsgrundlage einbezieht, den Zusammenhang der drei Sprünge nicht erkennen kann. if (a==10) //1. Sprung a=0; if (b=0) //2. Sprung b=0; if (a!=b){ //3. Sprung ... //abhängig von 1. und 2. Sprung } Um diese Abhängigkeiten in eine Sprungvorhersage einbeziehen zu können, sind Correlating Predictors notwendig. Solche Einheiten werden oft als (m,n)-Predictors bezeichnet. protokolliert wird das Verhalten der letzten m Sprünge je mit einem n-Bit Predictor (z.B. 2-Bit Second Chance) somit wird aus 2^m*n-Bit Preticors ausgewählt, um Vorhersage für den jeweiligen Sprung zu treffen Wie werden Correlating Predictors hardwaremäßig implementiert? Das Implementieren dieser Predictors ist weitaus einfacher, als man es annehmen würde. Es wird einfach für die History-Bits ein m-Bit-Shift Register verwendet, um die letzten m Sprünge zu speichern. Welche Performancesteigerung ist durch Correlating Predictors erreichbar? Eqntott ist ein Benchmark, welches speziell mehrere voneinander abhängige Sprünge simuliert. Hier sinkt die Fehlvorhersage von 20% auf unter 8%! Beim GCC-Compiler sind dagegen keine Unterschiede zwischen Correlating Predictors und normaler 2-Bit Sprungvorhersage erkennbar. Kapitel 8 - Superskalarität Was bedeutet superskalar? Mit normalen Pipelines (Überlappen von Instruktionen) ist nur eine maximale Performance von einem Befehl / Takt technisch und theor
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open iten Nachteil hat die 1-Bit Sprungvorhersage? Es wird nicht nur bei einem Schleifenaustritt der Sprung falsch vorhergesagt, sondern auch die erste Vorhersage bei erneuter Verwendung der Schleife. <span>Wie arbeitet die 2-Bit-Sprungvorhersage mit BHT? Durch einen einfachen Zähler kann man den Nachteil der 1-Bit-Vorhersage minimieren. Hier wird die Vorhersage erst geändert, wenn sie zweimal falsch war. Es hat sich gezeigt, daß durch Zähler mit mehr als 2 Bit sich die Performance nicht weiter signifikant erhöhen läßt. Abb.: 2-Bit-Sprungvorhersagenautomat <span>
Original toplevel document
Grundprinzipien der Rechnerarchitekturund das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! <span>Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. Da das Ziel eines Sprungbefehles oft erst festgestellt werden muss, liegt diese Adresse erst ab der MEM ACCESS Phase bereit. Somit kann das erneute Laden des Programmcounters auch erst in dieser Phase geschehen. So verzögert sich das Holen des nächsten Befehles um einige Takte. Durch eine Optimierung der Pipeline kann zwar die stall-Phase verkleinert, aber nicht ausgeschlossen werden. (durch Verlegung des Sprungbedingungstests in die Decode-Phase) Welche Methoden gibt es zur Reduzierung von Sprungverlusten? Predict Not Taken / Predict-Taken (fixed prediction) Objektcode basiert (statisch) dynamisch Brach-Prediction mit History Buffern (correlating / non-correlating) Delayed-Branch Wie funktioniert die Predict-Not-Taken bzw. Predict-Taken Methodik? Hier wird nichts weiter gemacht als entweder alle Sprünge voreingestellt abzulehnen oder alle Sprünge ersteinmal ohne Gewähr duchzuführen. Allgemeine Programmstatistiken sagen aus, dass mehr bedingte Sprünge ausgeführt als abgewiesen werden. Wie funktioniert die Delayed-Branch Methode? Hier wird ein sprungunabhängiger Befehl in den Delay Slot eingeschleust. Dies muss somit schon von den Compilerbauern berücksichtigt werden. Um diese Bedingung zu Umgehen wird die "Cancelling Branches"-Technik eingesetzt. Im Mittel werden dann trotzdem die Branch-Verluste verringert. Durch ein zusätzliches Bit im Befehlscode gibt der Compiler die wahrscheinlichste Sprungrichtung an. Nun kann entsprechend dieser Annahme ein Befehl in den Delay Slot eingefügt werden, der nur gültig ist, wenn der Sprung richtig vorhergesagt war. Falls nicht wird der Delay-Slot-Befehl abgebrochen (gecancelt). Dynamische Branch-Prediction Um Wartezeiten durch bedingte Sprünge zu vermeiden, sollte das Sprungziel schon mit dem Ende der Fetch-Phase zur Verfügung stehen. Es gibt zwei Ansätze Sprungzielspeicher (branch-target-buffer = BTB) Sprungvorhersage-Puffer (Branch History Table = BHT) Wie arbeitet eine Branch History Table? In dieser Tabelle wird im Grunde nur durch ein Bit (oder mehr) vermerkt, ob ein Sprung durchgeführt wurde oder nicht. Als Index der Tabelle dient der niederwertige Teil der Adresse des dazugehörigen Sprungbefehls. Nun kann die Pipeline in der Fetchphase nach einem eventuell vorhandenen Eintrag schauen und diesen als Entscheidungsgrundlage nehmen. Welchen Nachteil hat die 1-Bit Sprungvorhersage? Es wird nicht nur bei einem Schleifenaustritt der Sprung falsch vorhergesagt, sondern auch die erste Vorhersage bei erneuter Verwendung der Schleife. Wie arbeitet die 2-Bit-Sprungvorhersage mit BHT? Durch einen einfachen Zähler kann man den Nachteil der 1-Bit-Vorhersage minimieren. Hier wird die Vorhersage erst geändert, wenn sie zweimal falsch war. Es hat sich gezeigt, daß durch Zähler mit mehr als 2 Bit sich die Performance nicht weiter signifikant erhöhen läßt. Abb.: 2-Bit-Sprungvorhersagenautomat Wie arbeitet der Branch-Target-Buffer? Hier wird die Zieladresse eines gemachten Sprungs direkt gespeichert, um diese gegebenfalls ohne Verzögerung wiederzuverwenden. So kann bei einem Hit (Index stimmt mit Befehlsadresse überein) sofort der Instruction Counter mit der dazugehörigen Sprungadresse geladen werden). Exeptions Exeptions unterbrechen den Programmablauf Aufgrund verschiedenster Fehler oder Anforderungen, wie Softwareinterrupts, Page Faults oder anderen Verletzungen. Bei synchronen Exeptions treten die Fehler stehts an der gleichen Programmstelle auf. Asynchrone werden durch externe Geräte ausgelöst und können nach dem laufenden Befehl ausgeführt werden. Was sind Precice Exeptions? Sind Exeptions, welche garantieren, dass die Exeptions direkt nach oder während des Befehles ausgeführt werden und kein Folgebefehl vorher abgearbeitet wird. Zusammenfassung der Sprungvorhersage Sprungvorhersage ist extrem wichtig für Pipelining und Superskalarität, um stalls und Verzögerungen zu minimieren. Bei statischer Vorhersage werden Rückwärtssprünge meist erst durchgeführt und Vorwärtssprünge nicht. Wurde ein Sprung falsch vorhergesagt, muss die angefangene Instruktion rückgängig gemacht werden, was aufwendig ist. Deshalb gibt es ausgeklügelte Verfahren für die Branch Prediction. Statische Sprungvorhersage Es werden Compiler benutzt, die spezielle Sprungbefehle mitführen, welche ein Bit für die Sprungvorhersage enthalten. Da der Compiler ja weiß, wie oft eine Schleife durchlaufen wird, ist das sehr effizient. Dies muss aber architektonisch von der Hardware unterstützt werden. Des Weiteren ist kein Speicher für die History Table notwendig, was es kostengünstiger macht. Statische Verfahren erreichen eine Trefferrate von 65 bis 85%, was für moderne CPU's mit Superpipelines zu wenig ist. Dynamische Verfahren erreichen Trefferraten bei der Vorhersage von 98% und mehr! Dynamische Sprungvorhersage Es gibt zwei grundlegende Methoden. BHT und BTB. Die Branch History Table (Branch Predicion Buffer) ist ein Cache, in der alle bedingten Sprünge protokolliert werden. ( bis zu mehereren Tausend) Einfachste Version enthält ein Valid-Bit (Branch taken oder nicht), welches durch den niederwertigen Teil der Sprungadresse adressiert wird. Kompliziere Implementationen arbeiten nach dem n-Wege Prinzip. Durch Second Chance kann dieses Verfahren noch verbessert werden. Der Branch Target Buffer speichert nicht nur die taken-Bits, sondern auch die Sprungzieladresse, um null Verluste bei wiederholtem Aufruf zu haben. Das setzt voraus, dass nur taken branches aufgenommen werden. Bei einem Hit in der BTB kann somit während der Fetch Phase der Program Counter überschrieben werden. Werden keine History Bits mitgeführt spricht man vom BTAB. Wie arbeitet Second Chance? Nach Beenden einer Schleife wird ein Sprung logischerweise falsch vorhergesagt. Um zu vermeiden, dass nun fälschlicherweise das Sprungbit falsch gesetzt wird (da ja die gleiche Schleife noch mal durchlaufen werden kann), ändert man dieses erst nach der zweiten falschen Vorhersage. Leicht zu implementieren als Finite State Machine mit vier Zuständen. Nachteil der dynamischen Vorhersage ist die notwendige teuere und komplexere Hardware. Was ist der Vorteil von BHT gegenüber BTB? Branch Target Buffer loggen nur, ob ein Sprung genommen wurde oder nicht. Daher gibt es bei MIPS-Architekturen die BTB verwenden immernoch die sogenannten Branch Delay Slots, da die Sprungadresse trotzdem neu ermittelt werden muss. BHT beseitigen diesen Nachteil, da sie die Sprungadresse mit abspeichern und diese dann sofort in den IP geladen werden kann. Was sind Correlating Predictors? Betrachten wir folgendes Codefragment, fällt uns auf, daß ein Branch Predictor, der nur einen Sprung als Entscheidungsgrundlage einbezieht, den Zusammenhang der drei Sprünge nicht erkennen kann. if (a==10) //1. Sprung a=0; if (b=0) //2. Sprung b=0; if (a!=b){ //3. Sprung ... //abhängig von 1. und 2. Sprung } Um diese Abhängigkeiten in eine Sprungvorhersage einbeziehen zu können, sind Correlating Predictors notwendig. Solche Einheiten werden oft als (m,n)-Predictors bezeichnet. protokolliert wird das Verhalten der letzten m Sprünge je mit einem n-Bit Predictor (z.B. 2-Bit Second Chance) somit wird aus 2^m*n-Bit Preticors ausgewählt, um Vorhersage für den jeweiligen Sprung zu treffen Wie werden Correlating Predictors hardwaremäßig implementiert? Das Implementieren dieser Predictors ist weitaus einfacher, als man es annehmen würde. Es wird einfach für die History-Bits ein m-Bit-Shift Register verwendet, um die letzten m Sprünge zu speichern. Welche Performancesteigerung ist durch Correlating Predictors erreichbar? Eqntott ist ein Benchmark, welches speziell mehrere voneinander abhängige Sprünge simuliert. Hier sinkt die Fehlvorhersage von 20% auf unter 8%! Beim GCC-Compiler sind dagegen keine Unterschiede zwischen Correlating Predictors und normaler 2-Bit Sprungvorhersage erkennbar. Kapitel 8 - Superskalarität Was bedeutet superskalar? Mit normalen Pipelines (Überlappen von Instruktionen) ist nur eine maximale Performance von einem Befehl / Takt technisch und theor
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |