Edited, memorised or added to reading queue
on 06-Jul-2024 (Sat)
Do you want BuboFlash to help you learning these things? Click here to log in or create user.
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itdet, um höchste Effizienz und Parallelverarbeitung gewährleisten zu können. Die fünf grundlegenden Stufen einer einfachen Pipeline sind IF,ID,EX,MEM und WB. Takte T = Befehle + (Pipestufen - 1) <span>Folgende Abhängigkeiten verhindern, dass die CPI auf eins gehen: Strucual Hazards bzw. Ressourcenkonflikte IF und MEM wollen gleichzeitig auf Speicher lesend oder schreibend zugreifen. Das geht nicht, außer bei Dual-Port-RAM, welcher aber sehr teuer ist. Dieses Problem tritt aber bei modernen CPU's kaum noch auf, da eh intern eine Havard-ähnliche Architektur mit getrenntem Befehls- und Datencache gearbeitet wird. Data Hazards bzw. Datenabhängigkeiten Ein Folgebefehl wartet auf das Writeback der darüber liegenden Pipe, da er von diesem Befehl abhängig ist. Dies kann durch Nops bzw. Stalls ineffizient gelöst werden. Besser der Programmierer oder der Compiler löst diese Abhängigkeiten durch eine clevere Umordnung der Befehlsfolge auf. Es gibt aber noch eine andere Möglichkeit, welche aber hardwareseitig unterstützt werden muss. (VLIW, Superskalar) Forwarding Beim Forwarding werden Ergebnisse, sobald sie vorliegen an die nächste Stufe weitergereicht und nicht erst auf das Write Back gewartet. In anderen Worten: Das Ergebnis der ALU wird dieser sofort wieder eingespeist. Control Hazards bzw. Sprungverzögerungen Sprungergebnisse stehen erst in der Write Back Phase an. Moderne Prozessoren haben aber schon in der Fetch/Decode-Einheit eine Logik, welche die Zieladresse des Sprunges berechnet. Eine andere Möglichkeit ist die des spekulativen Ausführens. Hier tritt aber das Problem auf, dass viel Aufwand bei falscher Spekulation getrieben werden muss. Was ist der Unterschied zwischen echten und unechten Datenabhängigkeiten? Echte Datenabhängigkeiten sind RAW-Konflikte, bei dem ein Befehl auf die Beendigung eines Anderen warten muss,
Original toplevel document
Grundprinzipien der Rechnerarchitektureinen Verweis auf die Nächste enthalten. Sprünge sind einfach möglich. Angewandt wird dies in Form von Opcodes, welche nichts anderes als Adressen auf Mikroinstruktionen im Steuerspeicher sind. <span>Kapitel 6 - Pipelining Wozu dient Pipelining? Pipelining soll es ermöglichen Befehle überlappt auszuführen. Dazu sind ein einheitliches Befehlsformat fester Länge Grundlage. Deshalb werden werden nur auf Register getätigt. Für Speicheroperationen wird die LOAD / STORE Philosophie verfolgt, um langsame Hauptspeicherzugriffe zu minimieren. Was ist Voraussetzung für Pipelining? Die Befehlsverarbeitungsphase muss sich in mehrere voneinander unabhängige Phasen unterteilen lassen. Die einfachste Form einer Pipeline ist die 5-stufige mit folgenden Phasen: Befehl holen Befehl dekodieren Befehl ausführen Auf Speicher zugreifen Ergebnis in Register schreiben Moderene CPU's haben weitaus komplexere Pipelines, in denen die einzelnen Stufen wiederrum in mehrere sich überlappende Phasen aufgeteilt werden. Der allgemeine Aufbau einer (fünfstufigen) Pipeline Um Parallelität in der Befehlsausführungsphase zu erreichen, wird der Datenpfad so konstruiert, daß folgende (hier fünf) Phasen unabhänig voneinander arbeiten können. Nur so ist es möglich eine verzahnte Abarbeitung mehrerer Befehle zu erreichen. Abb.: Die Piplelinestufen Somit wird ,nachdem eine Pipeline gefüllt ist, im Optimalfall pro Takt ein Befehl fertig. (CPI = 1) Welche Pipeline-Konflikte müssen behandelt werden? Datenabhängigkeiten (Data Hazards) Sind logische Abhängigkeiten, welche eine verzögerte Abarbeitung erfordern, weil z.B. ein Folgebefehl auf ein Ergebnis eines anderen Befehles warten muss. Jump- / Branchverzögerungen (Control Hazards) Bei Sprungbefehlen liegt oft das Sprungziel nach der Dekodieung noch nicht fest. Somit müssen Techniken eingesetzt werden um diese Wartezeiten zu minimieren. (Branch Prediction) Ressourcenkonflikte (Structural Hazards) Bei bestimmten Befehlskombinationen ist es unter Umständen möglich, daß ein Teilwerk seine Arbeit wiederholen muss. Solche Ressourcenkonflikte treten dann auf, wenn nicht jeder Teilphase völlig unabhängige Teilwerke zugeordnet sind. Ein Beispiel ist z.B. ein zeitgleicher Lesezugriff eines LOAD/STORE Befehles, welcher sich zwangsweise mit einem eventuellen MEM ACCESS eines anderen Befehles überschneidet. Abhilfe können hier Dual-Port RAM, Havard-Architektur oder getrennte Code- und Datencaches schaffen. Welche drei verschiedenen Datenabhängigkeiten gibt es? RAW, WAW und WAR-Konflikte sind Datenabnhänigkeiten, welche in Pipelines auftreten können. Dabei ist das RAW-Problem für Pipelines typisch. WAR Konflikte treten eher bei Out-Of-Order Execution auf. Um Read-After-Write Konflikte aufzulösen, gibt es verschiedene Ansätze wie Softwarelösungen ( Compileroptimierung), Scoreboarding (zentrale Steuerlogik) und Forwarding (zusätzlicher Datenpfad). Was ist Forwarding? Beim Forwarding wird ein Bypass eingerichtet, welcher ein Ergebniss einer Operation schon einem Folgebefehl zur Verfügung stellt, bevor es überhaupt in ein Register geschrieben wurde. Aber trotz Load-Forwarding hat ein Ladebefehl eine Verzögerung, welche nicht gänzlich eliminiert werden kann. In diesem Fall kann die Delayed-Load Technik oder auch eine Befehlsumordnung Anhilfe schaffen. Was ist die Delayed Load-Technik? Bei der Delayed Load-Technik wird die Verzögerung nach einem LOAD Befehl als architektonisches Merkmal angesehn und den Compilerbauern offengelegt. Diese können nun durch Befehlsumordnungen versuchen, nach einem LOAD-Befehl einen datenunabhängigen Befehl einzufügen, um den Slot zu füllen. Zusammenfassung Pipelining Pipelines werden in allen modernen CPUs benutzt. Die UltraSparc2 hat neun und der P2 zwölf Stufen. Der Intel Pentium Itanium weißt eine 20 stufige Superpinepline (pipeline in der sich einzelne Stufen überlappen können) auf! Pipes werden heutzutage in Kombination mit der Superskalartechnik verwendet, um höchste Effizienz und Parallelverarbeitung gewährleisten zu können. Die fünf grundlegenden Stufen einer einfachen Pipeline sind IF,ID,EX,MEM und WB. Takte T = Befehle + (Pipestufen - 1) Folgende Abhängigkeiten verhindern, dass die CPI auf eins gehen: Strucual Hazards bzw. Ressourcenkonflikte IF und MEM wollen gleichzeitig auf Speicher lesend oder schreibend zugreifen. Das geht nicht, außer bei Dual-Port-RAM, welcher aber sehr teuer ist. Dieses Problem tritt aber bei modernen CPU's kaum noch auf, da eh intern eine Havard-ähnliche Architektur mit getrenntem Befehls- und Datencache gearbeitet wird. Data Hazards bzw. Datenabhängigkeiten Ein Folgebefehl wartet auf das Writeback der darüber liegenden Pipe, da er von diesem Befehl abhängig ist. Dies kann durch Nops bzw. Stalls ineffizient gelöst werden. Besser der Programmierer oder der Compiler löst diese Abhängigkeiten durch eine clevere Umordnung der Befehlsfolge auf. Es gibt aber noch eine andere Möglichkeit, welche aber hardwareseitig unterstützt werden muss. (VLIW, Superskalar) Forwarding Beim Forwarding werden Ergebnisse, sobald sie vorliegen an die nächste Stufe weitergereicht und nicht erst auf das Write Back gewartet. In anderen Worten: Das Ergebnis der ALU wird dieser sofort wieder eingespeist. Control Hazards bzw. Sprungverzögerungen Sprungergebnisse stehen erst in der Write Back Phase an. Moderne Prozessoren haben aber schon in der Fetch/Decode-Einheit eine Logik, welche die Zieladresse des Sprunges berechnet. Eine andere Möglichkeit ist die des spekulativen Ausführens. Hier tritt aber das Problem auf, dass viel Aufwand bei falscher Spekulation getrieben werden muss. Was ist der Unterschied zwischen echten und unechten Datenabhängigkeiten? Echte Datenabhängigkeiten sind RAW-Konflikte, bei dem ein Befehl auf die Beendigung eines Anderen warten muss, da er das Ergebnis als Operand benötigt. Unechte Datenabhängigkeit sind Abhängigkeiten, welche nur durch Namensabhängigkeit entstehen. Es gibt zwei Arten unechter Datenabhängigkeit: Antidependence sind WAR-Konflikte, welche entstehen, wenn ein Folgebefehl auf ein Register schreiben möchte, das noch von einem Anderen benutzt wird. Output Dependece sind WAW-Konflikte, welche entstehen, wenn mehrere Befehle auf ein und das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. D
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
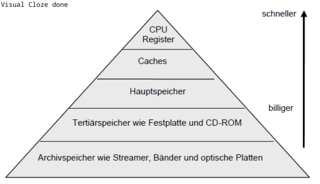
Open itNach welchen Merkmalen lassen sich Caches klassifizieren? Cache-Größe (damit verbundener Hardware-Aufwand) Größe einer Cachezeile (Verschmutzungseffekt) Cache-Organisation (Vollassoziativ/Direct Mapped/Satz-Assoziativ) Schreibstrategie (Write-Through /-Allocate oder -Back) Split-Cache-Design (Transfer-Bandbreiten) Multi-level Cache-Hierarchien (Workingssetgrößen) Effective Working Set (Overflow-, Victim-, Trace Cache) Innere Cache-Parallelität (Streaming) Kohärenz-Verfahren (Snooping, MESI) Wie ist ein Cache aufgebaut? Zeile 1 Adress-Tag Datenblock Control(Bits) Zeile 2 Adress-Tag Datenblock Control(Bits) Zeile 3 Adress-Tag Datenblock Control(Bits) ... Adress-Tag Datenbloc
Original toplevel document
Grundprinzipien der Rechnerarchitekturaubt : ) Preemptives Multitasking ist echtes Multitasking. Ein externer Timer steuert die Umschaltung der Tasks. Die Tasks können somit keinen Einfluss auf die Betriebsmittelumschaltung nehmen. <span>Kapitel 4 - Speicherhierarchie und Caches Was bedeutet die Eigenschaft Lokalität? Aus programmtechnischer Sicht wiederholen sich oft Befehle und ganze Programmteile. Somit werden Daten oft wiederholt angefordert. Es gibt nun zwei Arten von Lokalität: Was ist Zeitliche Lokalität? Auf ein gerade zugegriffenes Datum wird sicher bald wieder zugegriffen. Was ist Räumliche Lokalität? Auf Daten, deren Adressen benachbart sind, wird mit hoher Wahrscheinlichkeit auch zugegriffen. Anzumerken ist, daß Datenzugriffe eine geringere Lokalität zeigen als Befehlszugriffe. Nach welchen Merkmalen lassen sich Caches klassifizieren? Cache-Größe (damit verbundener Hardware-Aufwand) Größe einer Cachezeile (Verschmutzungseffekt) Cache-Organisation (Vollassoziativ/Direct Mapped/Satz-Assoziativ) Schreibstrategie (Write-Through /-Allocate oder -Back) Split-Cache-Design (Transfer-Bandbreiten) Multi-level Cache-Hierarchien (Workingssetgrößen) Effective Working Set (Overflow-, Victim-, Trace Cache) Innere Cache-Parallelität (Streaming) Kohärenz-Verfahren (Snooping, MESI) Wie ist ein Cache aufgebaut? Zeile 1 Adress-Tag Datenblock Control(Bits) Zeile 2 Adress-Tag Datenblock Control(Bits) Zeile 3 Adress-Tag Datenblock Control(Bits) ... Adress-Tag Datenblock Control(Bits) Zeile n Adress-Tag Datenblock Control(Bits) Control-Bits sind z.B. Valid-Bits, Dirty-Bits und Prozess-ID. Das Adress-Tag ist nichts weiter als ein Teil der Adresse, welche bei einem Zugriff als Index gilt. Ein Datenblock ist in der Praxis meistens zwischen 16 und 64 KByte groß. Welche Cache-Arten kennen Sie? Ein Cache-Eintrag besteht aus einem Tag (Identifikator) und den Daten. Die Implementierung unterscheidet sich. Es gibt voll-, einfach assoziative und Satzassoziative Caches . Wie arbeitet ein vollassoziativer Cache? Das Tag Feld ist hier die assoziierende Adresse des Datums im Speicher. Die Hardware ist bei vollassoziativen Caches aufwendig, da diese bei einem Cache Zugriff alle Tags gleichzeitig mit der anliegenden Adresse vergleicht. Dies ist zwar extrem schnell, aber sehr teuer. Außerdem wird er sehr langsam wenn die Anzahl der Cachezeilen hinreichend groß wird. Da bei vollassoziativen Cachen ein Datum an jede Stelle des Caches platziert werden kann, muss eine Logik her, welche eine Entscheidung trifft. Als Plazierungsstrategie wird oft LRU verwendet. Dies ist seht aufwendig! Wie arbeitet ein Direct-Mapped-Cache (einfach assoziativer Cache)? Beim Direct-Mapped-Cache entscheidet eine Map-Funktion, welche Zeile im Cache mit der anliegenden Adresse referenziert wird (somit ist kein LRU o.ä. notwendig). Dabei wird einem Hauptspeicherblock genau ein Cache-Block zugeordnet (n:1 Beziehung). Oft wird eine Funktion wie (A mod Cachesize / Zeilengröße) zur Berechnung der Cachezeile aus der anliegenden Adresse benutzt, da bei diesem Verfahren dann nur (A / Cachesize) als Tag in jeder Cachezeile gespeichert werden muss. Vorteil dieser Variante ist die einfache, kostengünstige Integration (nur Komperator notwendig) und die hohe Geschwindigkeit. Leider neigt ein Direct-Mapped-Cache zu vielen Konflikten (ähnlich den Kollisionen bei Hash-Tables), welche zusätzliche Cache-Misses bildet, da mehrere Adressen auf die gleiche Cachezeile verweisen. Wie arbeitet ein n-Wege-Satz Cache (Satzassoziativer Cache)? Diese Variante ist nichts anderes als eine Implementation mehrerer parallel verknüpfter Direct-Mapped-Caches. Sie stellt quasi einen Kompromiss zwischen Cache-Effizienz und Aufwand dar. Die Arbeitsweise ist die gleiche, nur das die Map-Funktion nicht nur auf eine Zeile im Speicher zeigt, sondern auf n. Die Hardware des Caches vergleicht alle n Tags gleichzeitig, mit dem anliegenden Index. Ist eine der Tags gleich dem Index, ist dies ein Cache-Hit. Diese Technik reduziert die hohe Anfälligkeit von Direct-Mapped-Caches für Konflikte, benötigt aber mehr Chipfläche. Welche Schreibstrategien für Caches gibt es? Write-Back,Write-Throug und Write-Allocate. Write-Back-Strategie? Ein zu lesendes Datum wird entweder bei einem Hit aus dem Cache gelesen oder im Falle eines Misses, aus dem Hauptspeicher geholt und parallel in den Cache eingetragen. Im Falle der Aktualisierung, muss erst das Dirty-Bit der zu überschreibenden Cache-Line geprüft werden, um diese gegebenenfalls in den Hauptspeicher zurückzuschreiben. (Write-Back) Vorteil dieser Strategie ist das bei Hits kein Hauptspeicherverkehr oder Busbelastung auftritt. Alle Operationen können schnell innerhalb der Working-Sets mit Cache-Speed erfolgen. Somit arbeitet die CPU ungebremst. Problematisch wird dies, wenn mehrere Bus-Master am Bus hängen. Um Inkonsistenzen zu vermeiden sind dann spezielle Synchronisationsprotololle wie MESI notwendig. Concurrent Write-Back? Bei einfachen Write-Back-Caches muss die CPU im Falle eines Cache-Misses warten, bis die neue Cache-Line aus dem Speicher geholt wurde. Um diese Wartezeit im Mittel zu eliminieren, wird die alte Zeile zunächst in einen Writebuffer zwischengespeichert und später, parallel zu nachfolgenden Cache-Referenzen in den Hauptspeicher übernommen. (Sonderform: Buffered Line Refill) Wenn auch beim Lesen ein Line-(Read)-Buffer verwendet wird, spricht man von einem Streaming Cache. Write-Through-Strategie? Write-Through schreibt immer in den Hauptspeicher und falls sich eine Kopie auch im Cache befindet, so wird diese aktualisiert. Genau aus diesem Grund ist kein Rückschreiben eines Dirty-Datums notwendig, da es zu keinen Inkonsistenzen zwischen RAM und Cache kommen kann. Nachteil ist aber, dass nur bei Leseoperationen ein Geschwindigkeitsvorteil erzielt werden kann Buffered Write-Through Im Mittel erfolgen nach jeder Write-Operation zwei Read-Operationen. Deshalb kann ein Geschwindigkeitsgewinn erzielt werden, wenn ein schneller Zwischenbuffer (FiFo) vor dem Speicher plaziert wird, welcher einige Write-Operationen aufnehmen kann. Wird nun eine Leseoperation ausgeführt, so kann das Datum falls es noch in dem schnellen Buffer steht, direkt aus diesem gelesen werden. Write Allocate Hier wird immer in den Hauptspeicher und in den Cache geschrieben - auch wenn das Datum sich noch nicht im Cache befand. Zusammenspiel bei Cache-Misses Write-Allocate wird meistens mit Write-Back Strategie gemeinsam verwendet. Write-Allocate bedeutet dabei nichts weiter, als das der Hauptspeicher-Block in den Cache geladen wird. Beim No-write-Allocate (Write-Around) wird das Datum direkt im Hauptspeicher modifiziert, weshalb Write Around meist mit Write-Through verbunden wird. Zusammenfassung Caches Write-Back wird üblicherweise mit Write-Allocate kombiniert. Beim Write Allocate (fetch-on-write) wird ein Block gelesen und in Cache gespeichert. Beim No-write-allocate (write-around) wird der Block in der unteren Ebene der Speicherhierarchie modifiziert und nicht nicht im Cache geladen. No-write-allocate wird deshalb meist bei Write-through verwendet. Was ist der Unterschied zwischen einen logischen und einen physischen Cache? Physische Caches liegen vor der MMU und speichern somit nur physikalische Adressen. Ein logischer Cache liegt zwischen CPU und MMU und speichert logische Adressen. Vorteil von logischen Caches ist daher, dass die Adressumrechnung bei einem Hit entfällt. Ein großer Nachteil sind aber die Synonym-Probleme bei Multiprozessorsystemen. Des weiteren wird bei Taskwechsel ein Cache-Flush notwendig. Multi-Level-Caches und Split-Caches Durch Hintereinanderlegen von verschiedenen Caches kann ein gleitender Übergang zu immer größeren und langsameren Speichern erreicht werden. First Level Caches sind meist n-Wege-Satzassoziativ und folgende Direct-Mapped. Split-Caches trennen Code und Daten und sind somit viel flexibler und besser an das Zugriffsverhalten in Bezug auf Strategie oder Assoziativität zu optimieren. Dabei unterscheidet man eine Havard-Architektur von der multiplexed Havard-Architektur (von Neumann Prinzip). Die reine Harvard trennt nicht nur Cache sondern auch den Hauptspeicher in Daten und Codebereich. Bei von Neumann liegen Daten und Code zusammen im Hauptspeicher und werden nur im Cache getrennt. Durch Trennung von Code und Daten verdoppelt sich die Bandbreite, da zeitgleich zugegriffen werden kann. Was geschieht wenn kein Platz mehr im Cache vorhanden ist? Es muss eine Cache-Line ausgewählt werden, die mit den neuen benötigten Daten überschrieben werden kann. Die Auswahl erfolgt meistens mit LRU - Last Recently Used. D.h. die am längsten nicht genutzte Cache-Line fliegt raus. Was ist ein Burst-Cache? Burst Caches schreiben nicht nur eine Zeile in den Speicher zurück, sondern gleich mehrere, um die Bandbreite auszunutzen und somit Zeit zu sparen. Zusammenhänge zwischen Caches, TLB's und Page Tables Folgende vier Fragen stellen sich bei Caches, TLB's und auch bei Page Tables: Wo kann ein Block eingelagert werden? (Direct Mapped also nur an einem Ort, Set Assoziativ an mehreren Orten oder Voll Assoziativ, also überall) Wie kann ein Block gefunden werden? (indexiert, limitierte Suche, komplette Suche oder lookup table wie Page Tables) Wie wird ein Block bei einem Miss aktualisiert? (normalerweise über LRU oder random Methoden) Wie wird mit Schreiboperationen umgegangen? (Write Through oder Write Back) Ein TLB ist ein Translation Lookaside Buffer und ist ein kleiner Cache für die Page Table, um Seitenzugriffe zu beschleunigen. Was ist ein Trace-Cache Ein Trace Cache ist ein spezieller Befehlscache, der "Traces" des aktuellen Programmlauf protokolliert. Dabei speichert jede Zeile einen Trace, welcher typisch mehrere taken branches enthalten kann. Befehlsfolgen, die aufgrund von taken branches (weit) auseinander liegen, werden in kontinuierlicher Folge abgespeichert. Gepaart mit multiple branch prediction können mehrere zusammenhängende Basisblöcke parallel gefetched werden. (ergibt hohe issue rate) Kapitel 5 - Risc Wie berechnet sich die Prozessorleistung? Die Prozessorleistung ist umgekehrt proportional zur Ausführungszeit eines Algorithmus und wird aus folgenden drei Parametern
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open it-Bandbreiten) Multi-level Cache-Hierarchien (Workingssetgrößen) Effective Working Set (Overflow-, Victim-, Trace Cache) Innere Cache-Parallelität (Streaming) Kohärenz-Verfahren (Snooping, MESI) <span>Wie ist ein Cache aufgebaut? Zeile 1 Adress-Tag Datenblock Control(Bits) Zeile 2 Adress-Tag Datenblock Control(Bits) Zeile 3 Adress-Tag Datenblock Control(Bits) ... Adress-Tag Datenblock Control(Bits) Zeile n Adress-Tag Datenblock Control(Bits) Control-Bits sind z.B. Valid-Bits, Dirty-Bits und Prozess-ID. Das Adress-Tag ist nichts weiter als ein Teil der Adresse, welche bei einem Zugriff als Index gilt. Ein Datenblock ist in der Praxis meistens zwischen 16 und 64 KByte groß. <span>
Original toplevel document
Grundprinzipien der Rechnerarchitekturaubt : ) Preemptives Multitasking ist echtes Multitasking. Ein externer Timer steuert die Umschaltung der Tasks. Die Tasks können somit keinen Einfluss auf die Betriebsmittelumschaltung nehmen. <span>Kapitel 4 - Speicherhierarchie und Caches Was bedeutet die Eigenschaft Lokalität? Aus programmtechnischer Sicht wiederholen sich oft Befehle und ganze Programmteile. Somit werden Daten oft wiederholt angefordert. Es gibt nun zwei Arten von Lokalität: Was ist Zeitliche Lokalität? Auf ein gerade zugegriffenes Datum wird sicher bald wieder zugegriffen. Was ist Räumliche Lokalität? Auf Daten, deren Adressen benachbart sind, wird mit hoher Wahrscheinlichkeit auch zugegriffen. Anzumerken ist, daß Datenzugriffe eine geringere Lokalität zeigen als Befehlszugriffe. Nach welchen Merkmalen lassen sich Caches klassifizieren? Cache-Größe (damit verbundener Hardware-Aufwand) Größe einer Cachezeile (Verschmutzungseffekt) Cache-Organisation (Vollassoziativ/Direct Mapped/Satz-Assoziativ) Schreibstrategie (Write-Through /-Allocate oder -Back) Split-Cache-Design (Transfer-Bandbreiten) Multi-level Cache-Hierarchien (Workingssetgrößen) Effective Working Set (Overflow-, Victim-, Trace Cache) Innere Cache-Parallelität (Streaming) Kohärenz-Verfahren (Snooping, MESI) Wie ist ein Cache aufgebaut? Zeile 1 Adress-Tag Datenblock Control(Bits) Zeile 2 Adress-Tag Datenblock Control(Bits) Zeile 3 Adress-Tag Datenblock Control(Bits) ... Adress-Tag Datenblock Control(Bits) Zeile n Adress-Tag Datenblock Control(Bits) Control-Bits sind z.B. Valid-Bits, Dirty-Bits und Prozess-ID. Das Adress-Tag ist nichts weiter als ein Teil der Adresse, welche bei einem Zugriff als Index gilt. Ein Datenblock ist in der Praxis meistens zwischen 16 und 64 KByte groß. Welche Cache-Arten kennen Sie? Ein Cache-Eintrag besteht aus einem Tag (Identifikator) und den Daten. Die Implementierung unterscheidet sich. Es gibt voll-, einfach assoziative und Satzassoziative Caches . Wie arbeitet ein vollassoziativer Cache? Das Tag Feld ist hier die assoziierende Adresse des Datums im Speicher. Die Hardware ist bei vollassoziativen Caches aufwendig, da diese bei einem Cache Zugriff alle Tags gleichzeitig mit der anliegenden Adresse vergleicht. Dies ist zwar extrem schnell, aber sehr teuer. Außerdem wird er sehr langsam wenn die Anzahl der Cachezeilen hinreichend groß wird. Da bei vollassoziativen Cachen ein Datum an jede Stelle des Caches platziert werden kann, muss eine Logik her, welche eine Entscheidung trifft. Als Plazierungsstrategie wird oft LRU verwendet. Dies ist seht aufwendig! Wie arbeitet ein Direct-Mapped-Cache (einfach assoziativer Cache)? Beim Direct-Mapped-Cache entscheidet eine Map-Funktion, welche Zeile im Cache mit der anliegenden Adresse referenziert wird (somit ist kein LRU o.ä. notwendig). Dabei wird einem Hauptspeicherblock genau ein Cache-Block zugeordnet (n:1 Beziehung). Oft wird eine Funktion wie (A mod Cachesize / Zeilengröße) zur Berechnung der Cachezeile aus der anliegenden Adresse benutzt, da bei diesem Verfahren dann nur (A / Cachesize) als Tag in jeder Cachezeile gespeichert werden muss. Vorteil dieser Variante ist die einfache, kostengünstige Integration (nur Komperator notwendig) und die hohe Geschwindigkeit. Leider neigt ein Direct-Mapped-Cache zu vielen Konflikten (ähnlich den Kollisionen bei Hash-Tables), welche zusätzliche Cache-Misses bildet, da mehrere Adressen auf die gleiche Cachezeile verweisen. Wie arbeitet ein n-Wege-Satz Cache (Satzassoziativer Cache)? Diese Variante ist nichts anderes als eine Implementation mehrerer parallel verknüpfter Direct-Mapped-Caches. Sie stellt quasi einen Kompromiss zwischen Cache-Effizienz und Aufwand dar. Die Arbeitsweise ist die gleiche, nur das die Map-Funktion nicht nur auf eine Zeile im Speicher zeigt, sondern auf n. Die Hardware des Caches vergleicht alle n Tags gleichzeitig, mit dem anliegenden Index. Ist eine der Tags gleich dem Index, ist dies ein Cache-Hit. Diese Technik reduziert die hohe Anfälligkeit von Direct-Mapped-Caches für Konflikte, benötigt aber mehr Chipfläche. Welche Schreibstrategien für Caches gibt es? Write-Back,Write-Throug und Write-Allocate. Write-Back-Strategie? Ein zu lesendes Datum wird entweder bei einem Hit aus dem Cache gelesen oder im Falle eines Misses, aus dem Hauptspeicher geholt und parallel in den Cache eingetragen. Im Falle der Aktualisierung, muss erst das Dirty-Bit der zu überschreibenden Cache-Line geprüft werden, um diese gegebenenfalls in den Hauptspeicher zurückzuschreiben. (Write-Back) Vorteil dieser Strategie ist das bei Hits kein Hauptspeicherverkehr oder Busbelastung auftritt. Alle Operationen können schnell innerhalb der Working-Sets mit Cache-Speed erfolgen. Somit arbeitet die CPU ungebremst. Problematisch wird dies, wenn mehrere Bus-Master am Bus hängen. Um Inkonsistenzen zu vermeiden sind dann spezielle Synchronisationsprotololle wie MESI notwendig. Concurrent Write-Back? Bei einfachen Write-Back-Caches muss die CPU im Falle eines Cache-Misses warten, bis die neue Cache-Line aus dem Speicher geholt wurde. Um diese Wartezeit im Mittel zu eliminieren, wird die alte Zeile zunächst in einen Writebuffer zwischengespeichert und später, parallel zu nachfolgenden Cache-Referenzen in den Hauptspeicher übernommen. (Sonderform: Buffered Line Refill) Wenn auch beim Lesen ein Line-(Read)-Buffer verwendet wird, spricht man von einem Streaming Cache. Write-Through-Strategie? Write-Through schreibt immer in den Hauptspeicher und falls sich eine Kopie auch im Cache befindet, so wird diese aktualisiert. Genau aus diesem Grund ist kein Rückschreiben eines Dirty-Datums notwendig, da es zu keinen Inkonsistenzen zwischen RAM und Cache kommen kann. Nachteil ist aber, dass nur bei Leseoperationen ein Geschwindigkeitsvorteil erzielt werden kann Buffered Write-Through Im Mittel erfolgen nach jeder Write-Operation zwei Read-Operationen. Deshalb kann ein Geschwindigkeitsgewinn erzielt werden, wenn ein schneller Zwischenbuffer (FiFo) vor dem Speicher plaziert wird, welcher einige Write-Operationen aufnehmen kann. Wird nun eine Leseoperation ausgeführt, so kann das Datum falls es noch in dem schnellen Buffer steht, direkt aus diesem gelesen werden. Write Allocate Hier wird immer in den Hauptspeicher und in den Cache geschrieben - auch wenn das Datum sich noch nicht im Cache befand. Zusammenspiel bei Cache-Misses Write-Allocate wird meistens mit Write-Back Strategie gemeinsam verwendet. Write-Allocate bedeutet dabei nichts weiter, als das der Hauptspeicher-Block in den Cache geladen wird. Beim No-write-Allocate (Write-Around) wird das Datum direkt im Hauptspeicher modifiziert, weshalb Write Around meist mit Write-Through verbunden wird. Zusammenfassung Caches Write-Back wird üblicherweise mit Write-Allocate kombiniert. Beim Write Allocate (fetch-on-write) wird ein Block gelesen und in Cache gespeichert. Beim No-write-allocate (write-around) wird der Block in der unteren Ebene der Speicherhierarchie modifiziert und nicht nicht im Cache geladen. No-write-allocate wird deshalb meist bei Write-through verwendet. Was ist der Unterschied zwischen einen logischen und einen physischen Cache? Physische Caches liegen vor der MMU und speichern somit nur physikalische Adressen. Ein logischer Cache liegt zwischen CPU und MMU und speichert logische Adressen. Vorteil von logischen Caches ist daher, dass die Adressumrechnung bei einem Hit entfällt. Ein großer Nachteil sind aber die Synonym-Probleme bei Multiprozessorsystemen. Des weiteren wird bei Taskwechsel ein Cache-Flush notwendig. Multi-Level-Caches und Split-Caches Durch Hintereinanderlegen von verschiedenen Caches kann ein gleitender Übergang zu immer größeren und langsameren Speichern erreicht werden. First Level Caches sind meist n-Wege-Satzassoziativ und folgende Direct-Mapped. Split-Caches trennen Code und Daten und sind somit viel flexibler und besser an das Zugriffsverhalten in Bezug auf Strategie oder Assoziativität zu optimieren. Dabei unterscheidet man eine Havard-Architektur von der multiplexed Havard-Architektur (von Neumann Prinzip). Die reine Harvard trennt nicht nur Cache sondern auch den Hauptspeicher in Daten und Codebereich. Bei von Neumann liegen Daten und Code zusammen im Hauptspeicher und werden nur im Cache getrennt. Durch Trennung von Code und Daten verdoppelt sich die Bandbreite, da zeitgleich zugegriffen werden kann. Was geschieht wenn kein Platz mehr im Cache vorhanden ist? Es muss eine Cache-Line ausgewählt werden, die mit den neuen benötigten Daten überschrieben werden kann. Die Auswahl erfolgt meistens mit LRU - Last Recently Used. D.h. die am längsten nicht genutzte Cache-Line fliegt raus. Was ist ein Burst-Cache? Burst Caches schreiben nicht nur eine Zeile in den Speicher zurück, sondern gleich mehrere, um die Bandbreite auszunutzen und somit Zeit zu sparen. Zusammenhänge zwischen Caches, TLB's und Page Tables Folgende vier Fragen stellen sich bei Caches, TLB's und auch bei Page Tables: Wo kann ein Block eingelagert werden? (Direct Mapped also nur an einem Ort, Set Assoziativ an mehreren Orten oder Voll Assoziativ, also überall) Wie kann ein Block gefunden werden? (indexiert, limitierte Suche, komplette Suche oder lookup table wie Page Tables) Wie wird ein Block bei einem Miss aktualisiert? (normalerweise über LRU oder random Methoden) Wie wird mit Schreiboperationen umgegangen? (Write Through oder Write Back) Ein TLB ist ein Translation Lookaside Buffer und ist ein kleiner Cache für die Page Table, um Seitenzugriffe zu beschleunigen. Was ist ein Trace-Cache Ein Trace Cache ist ein spezieller Befehlscache, der "Traces" des aktuellen Programmlauf protokolliert. Dabei speichert jede Zeile einen Trace, welcher typisch mehrere taken branches enthalten kann. Befehlsfolgen, die aufgrund von taken branches (weit) auseinander liegen, werden in kontinuierlicher Folge abgespeichert. Gepaart mit multiple branch prediction können mehrere zusammenhängende Basisblöcke parallel gefetched werden. (ergibt hohe issue rate) Kapitel 5 - Risc Wie berechnet sich die Prozessorleistung? Die Prozessorleistung ist umgekehrt proportional zur Ausführungszeit eines Algorithmus und wird aus folgenden drei Parametern
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itFolgende Abhängigkeiten verhindern, dass die CPI auf eins gehen: Strucual Hazards bzw. Ressourcenkonflikte IF und MEM wollen gleichzeitig auf Speicher lesend oder schreibend zugreifen. Das geht nicht, außer bei Dual-Port-RAM, welcher aber sehr teuer ist. Dieses Problem tritt aber bei modernen CPU's kaum noch auf, da eh intern eine Havard-ähnliche Architektur mit getrenntem Befehls- und Datencache gearbeitet wird. Folgende Abhängigkeiten verhindern, dass die CPI auf eins gehen: Data Hazards bzw. Datenabhängigkeiten Ein Folgebefehl wartet auf das Writeback der darüber liegenden Pipe, da er von die
Original toplevel document
Grundprinzipien der Rechnerarchitektureinen Verweis auf die Nächste enthalten. Sprünge sind einfach möglich. Angewandt wird dies in Form von Opcodes, welche nichts anderes als Adressen auf Mikroinstruktionen im Steuerspeicher sind. <span>Kapitel 6 - Pipelining Wozu dient Pipelining? Pipelining soll es ermöglichen Befehle überlappt auszuführen. Dazu sind ein einheitliches Befehlsformat fester Länge Grundlage. Deshalb werden werden nur auf Register getätigt. Für Speicheroperationen wird die LOAD / STORE Philosophie verfolgt, um langsame Hauptspeicherzugriffe zu minimieren. Was ist Voraussetzung für Pipelining? Die Befehlsverarbeitungsphase muss sich in mehrere voneinander unabhängige Phasen unterteilen lassen. Die einfachste Form einer Pipeline ist die 5-stufige mit folgenden Phasen: Befehl holen Befehl dekodieren Befehl ausführen Auf Speicher zugreifen Ergebnis in Register schreiben Moderene CPU's haben weitaus komplexere Pipelines, in denen die einzelnen Stufen wiederrum in mehrere sich überlappende Phasen aufgeteilt werden. Der allgemeine Aufbau einer (fünfstufigen) Pipeline Um Parallelität in der Befehlsausführungsphase zu erreichen, wird der Datenpfad so konstruiert, daß folgende (hier fünf) Phasen unabhänig voneinander arbeiten können. Nur so ist es möglich eine verzahnte Abarbeitung mehrerer Befehle zu erreichen. Abb.: Die Piplelinestufen Somit wird ,nachdem eine Pipeline gefüllt ist, im Optimalfall pro Takt ein Befehl fertig. (CPI = 1) Welche Pipeline-Konflikte müssen behandelt werden? Datenabhängigkeiten (Data Hazards) Sind logische Abhängigkeiten, welche eine verzögerte Abarbeitung erfordern, weil z.B. ein Folgebefehl auf ein Ergebnis eines anderen Befehles warten muss. Jump- / Branchverzögerungen (Control Hazards) Bei Sprungbefehlen liegt oft das Sprungziel nach der Dekodieung noch nicht fest. Somit müssen Techniken eingesetzt werden um diese Wartezeiten zu minimieren. (Branch Prediction) Ressourcenkonflikte (Structural Hazards) Bei bestimmten Befehlskombinationen ist es unter Umständen möglich, daß ein Teilwerk seine Arbeit wiederholen muss. Solche Ressourcenkonflikte treten dann auf, wenn nicht jeder Teilphase völlig unabhängige Teilwerke zugeordnet sind. Ein Beispiel ist z.B. ein zeitgleicher Lesezugriff eines LOAD/STORE Befehles, welcher sich zwangsweise mit einem eventuellen MEM ACCESS eines anderen Befehles überschneidet. Abhilfe können hier Dual-Port RAM, Havard-Architektur oder getrennte Code- und Datencaches schaffen. Welche drei verschiedenen Datenabhängigkeiten gibt es? RAW, WAW und WAR-Konflikte sind Datenabnhänigkeiten, welche in Pipelines auftreten können. Dabei ist das RAW-Problem für Pipelines typisch. WAR Konflikte treten eher bei Out-Of-Order Execution auf. Um Read-After-Write Konflikte aufzulösen, gibt es verschiedene Ansätze wie Softwarelösungen ( Compileroptimierung), Scoreboarding (zentrale Steuerlogik) und Forwarding (zusätzlicher Datenpfad). Was ist Forwarding? Beim Forwarding wird ein Bypass eingerichtet, welcher ein Ergebniss einer Operation schon einem Folgebefehl zur Verfügung stellt, bevor es überhaupt in ein Register geschrieben wurde. Aber trotz Load-Forwarding hat ein Ladebefehl eine Verzögerung, welche nicht gänzlich eliminiert werden kann. In diesem Fall kann die Delayed-Load Technik oder auch eine Befehlsumordnung Anhilfe schaffen. Was ist die Delayed Load-Technik? Bei der Delayed Load-Technik wird die Verzögerung nach einem LOAD Befehl als architektonisches Merkmal angesehn und den Compilerbauern offengelegt. Diese können nun durch Befehlsumordnungen versuchen, nach einem LOAD-Befehl einen datenunabhängigen Befehl einzufügen, um den Slot zu füllen. Zusammenfassung Pipelining Pipelines werden in allen modernen CPUs benutzt. Die UltraSparc2 hat neun und der P2 zwölf Stufen. Der Intel Pentium Itanium weißt eine 20 stufige Superpinepline (pipeline in der sich einzelne Stufen überlappen können) auf! Pipes werden heutzutage in Kombination mit der Superskalartechnik verwendet, um höchste Effizienz und Parallelverarbeitung gewährleisten zu können. Die fünf grundlegenden Stufen einer einfachen Pipeline sind IF,ID,EX,MEM und WB. Takte T = Befehle + (Pipestufen - 1) Folgende Abhängigkeiten verhindern, dass die CPI auf eins gehen: Strucual Hazards bzw. Ressourcenkonflikte IF und MEM wollen gleichzeitig auf Speicher lesend oder schreibend zugreifen. Das geht nicht, außer bei Dual-Port-RAM, welcher aber sehr teuer ist. Dieses Problem tritt aber bei modernen CPU's kaum noch auf, da eh intern eine Havard-ähnliche Architektur mit getrenntem Befehls- und Datencache gearbeitet wird. Data Hazards bzw. Datenabhängigkeiten Ein Folgebefehl wartet auf das Writeback der darüber liegenden Pipe, da er von diesem Befehl abhängig ist. Dies kann durch Nops bzw. Stalls ineffizient gelöst werden. Besser der Programmierer oder der Compiler löst diese Abhängigkeiten durch eine clevere Umordnung der Befehlsfolge auf. Es gibt aber noch eine andere Möglichkeit, welche aber hardwareseitig unterstützt werden muss. (VLIW, Superskalar) Forwarding Beim Forwarding werden Ergebnisse, sobald sie vorliegen an die nächste Stufe weitergereicht und nicht erst auf das Write Back gewartet. In anderen Worten: Das Ergebnis der ALU wird dieser sofort wieder eingespeist. Control Hazards bzw. Sprungverzögerungen Sprungergebnisse stehen erst in der Write Back Phase an. Moderne Prozessoren haben aber schon in der Fetch/Decode-Einheit eine Logik, welche die Zieladresse des Sprunges berechnet. Eine andere Möglichkeit ist die des spekulativen Ausführens. Hier tritt aber das Problem auf, dass viel Aufwand bei falscher Spekulation getrieben werden muss. Was ist der Unterschied zwischen echten und unechten Datenabhängigkeiten? Echte Datenabhängigkeiten sind RAW-Konflikte, bei dem ein Befehl auf die Beendigung eines Anderen warten muss, da er das Ergebnis als Operand benötigt. Unechte Datenabhängigkeit sind Abhängigkeiten, welche nur durch Namensabhängigkeit entstehen. Es gibt zwei Arten unechter Datenabhängigkeit: Antidependence sind WAR-Konflikte, welche entstehen, wenn ein Folgebefehl auf ein Register schreiben möchte, das noch von einem Anderen benutzt wird. Output Dependece sind WAW-Konflikte, welche entstehen, wenn mehrere Befehle auf ein und das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. D
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itM, welcher aber sehr teuer ist. Dieses Problem tritt aber bei modernen CPU's kaum noch auf, da eh intern eine Havard-ähnliche Architektur mit getrenntem Befehls- und Datencache gearbeitet wird. <span>Folgende Abhängigkeiten verhindern, dass die CPI auf eins gehen: Data Hazards bzw. Datenabhängigkeiten Ein Folgebefehl wartet auf das Writeback der darüber liegenden Pipe, da er von diesem Befehl abhängig ist. Dies kann durch Nops bzw. Stalls ineffizient gelöst werden. Besser der Programmierer oder der Compiler löst diese Abhängigkeiten durch eine clevere Umordnung der Befehlsfolge auf. Es gibt aber noch eine andere Möglichkeit, welche aber hardwareseitig unterstützt werden muss. (VLIW, Superskalar) Folgende Abhängigkeiten verhindern, dass die CPI auf eins gehen: Forwarding Beim Forwarding werden Ergebnisse, sobald sie vorliegen an die nächste Stufe weitergereicht und nicht erst au
Original toplevel document
Grundprinzipien der Rechnerarchitektureinen Verweis auf die Nächste enthalten. Sprünge sind einfach möglich. Angewandt wird dies in Form von Opcodes, welche nichts anderes als Adressen auf Mikroinstruktionen im Steuerspeicher sind. <span>Kapitel 6 - Pipelining Wozu dient Pipelining? Pipelining soll es ermöglichen Befehle überlappt auszuführen. Dazu sind ein einheitliches Befehlsformat fester Länge Grundlage. Deshalb werden werden nur auf Register getätigt. Für Speicheroperationen wird die LOAD / STORE Philosophie verfolgt, um langsame Hauptspeicherzugriffe zu minimieren. Was ist Voraussetzung für Pipelining? Die Befehlsverarbeitungsphase muss sich in mehrere voneinander unabhängige Phasen unterteilen lassen. Die einfachste Form einer Pipeline ist die 5-stufige mit folgenden Phasen: Befehl holen Befehl dekodieren Befehl ausführen Auf Speicher zugreifen Ergebnis in Register schreiben Moderene CPU's haben weitaus komplexere Pipelines, in denen die einzelnen Stufen wiederrum in mehrere sich überlappende Phasen aufgeteilt werden. Der allgemeine Aufbau einer (fünfstufigen) Pipeline Um Parallelität in der Befehlsausführungsphase zu erreichen, wird der Datenpfad so konstruiert, daß folgende (hier fünf) Phasen unabhänig voneinander arbeiten können. Nur so ist es möglich eine verzahnte Abarbeitung mehrerer Befehle zu erreichen. Abb.: Die Piplelinestufen Somit wird ,nachdem eine Pipeline gefüllt ist, im Optimalfall pro Takt ein Befehl fertig. (CPI = 1) Welche Pipeline-Konflikte müssen behandelt werden? Datenabhängigkeiten (Data Hazards) Sind logische Abhängigkeiten, welche eine verzögerte Abarbeitung erfordern, weil z.B. ein Folgebefehl auf ein Ergebnis eines anderen Befehles warten muss. Jump- / Branchverzögerungen (Control Hazards) Bei Sprungbefehlen liegt oft das Sprungziel nach der Dekodieung noch nicht fest. Somit müssen Techniken eingesetzt werden um diese Wartezeiten zu minimieren. (Branch Prediction) Ressourcenkonflikte (Structural Hazards) Bei bestimmten Befehlskombinationen ist es unter Umständen möglich, daß ein Teilwerk seine Arbeit wiederholen muss. Solche Ressourcenkonflikte treten dann auf, wenn nicht jeder Teilphase völlig unabhängige Teilwerke zugeordnet sind. Ein Beispiel ist z.B. ein zeitgleicher Lesezugriff eines LOAD/STORE Befehles, welcher sich zwangsweise mit einem eventuellen MEM ACCESS eines anderen Befehles überschneidet. Abhilfe können hier Dual-Port RAM, Havard-Architektur oder getrennte Code- und Datencaches schaffen. Welche drei verschiedenen Datenabhängigkeiten gibt es? RAW, WAW und WAR-Konflikte sind Datenabnhänigkeiten, welche in Pipelines auftreten können. Dabei ist das RAW-Problem für Pipelines typisch. WAR Konflikte treten eher bei Out-Of-Order Execution auf. Um Read-After-Write Konflikte aufzulösen, gibt es verschiedene Ansätze wie Softwarelösungen ( Compileroptimierung), Scoreboarding (zentrale Steuerlogik) und Forwarding (zusätzlicher Datenpfad). Was ist Forwarding? Beim Forwarding wird ein Bypass eingerichtet, welcher ein Ergebniss einer Operation schon einem Folgebefehl zur Verfügung stellt, bevor es überhaupt in ein Register geschrieben wurde. Aber trotz Load-Forwarding hat ein Ladebefehl eine Verzögerung, welche nicht gänzlich eliminiert werden kann. In diesem Fall kann die Delayed-Load Technik oder auch eine Befehlsumordnung Anhilfe schaffen. Was ist die Delayed Load-Technik? Bei der Delayed Load-Technik wird die Verzögerung nach einem LOAD Befehl als architektonisches Merkmal angesehn und den Compilerbauern offengelegt. Diese können nun durch Befehlsumordnungen versuchen, nach einem LOAD-Befehl einen datenunabhängigen Befehl einzufügen, um den Slot zu füllen. Zusammenfassung Pipelining Pipelines werden in allen modernen CPUs benutzt. Die UltraSparc2 hat neun und der P2 zwölf Stufen. Der Intel Pentium Itanium weißt eine 20 stufige Superpinepline (pipeline in der sich einzelne Stufen überlappen können) auf! Pipes werden heutzutage in Kombination mit der Superskalartechnik verwendet, um höchste Effizienz und Parallelverarbeitung gewährleisten zu können. Die fünf grundlegenden Stufen einer einfachen Pipeline sind IF,ID,EX,MEM und WB. Takte T = Befehle + (Pipestufen - 1) Folgende Abhängigkeiten verhindern, dass die CPI auf eins gehen: Strucual Hazards bzw. Ressourcenkonflikte IF und MEM wollen gleichzeitig auf Speicher lesend oder schreibend zugreifen. Das geht nicht, außer bei Dual-Port-RAM, welcher aber sehr teuer ist. Dieses Problem tritt aber bei modernen CPU's kaum noch auf, da eh intern eine Havard-ähnliche Architektur mit getrenntem Befehls- und Datencache gearbeitet wird. Data Hazards bzw. Datenabhängigkeiten Ein Folgebefehl wartet auf das Writeback der darüber liegenden Pipe, da er von diesem Befehl abhängig ist. Dies kann durch Nops bzw. Stalls ineffizient gelöst werden. Besser der Programmierer oder der Compiler löst diese Abhängigkeiten durch eine clevere Umordnung der Befehlsfolge auf. Es gibt aber noch eine andere Möglichkeit, welche aber hardwareseitig unterstützt werden muss. (VLIW, Superskalar) Forwarding Beim Forwarding werden Ergebnisse, sobald sie vorliegen an die nächste Stufe weitergereicht und nicht erst auf das Write Back gewartet. In anderen Worten: Das Ergebnis der ALU wird dieser sofort wieder eingespeist. Control Hazards bzw. Sprungverzögerungen Sprungergebnisse stehen erst in der Write Back Phase an. Moderne Prozessoren haben aber schon in der Fetch/Decode-Einheit eine Logik, welche die Zieladresse des Sprunges berechnet. Eine andere Möglichkeit ist die des spekulativen Ausführens. Hier tritt aber das Problem auf, dass viel Aufwand bei falscher Spekulation getrieben werden muss. Was ist der Unterschied zwischen echten und unechten Datenabhängigkeiten? Echte Datenabhängigkeiten sind RAW-Konflikte, bei dem ein Befehl auf die Beendigung eines Anderen warten muss, da er das Ergebnis als Operand benötigt. Unechte Datenabhängigkeit sind Abhängigkeiten, welche nur durch Namensabhängigkeit entstehen. Es gibt zwei Arten unechter Datenabhängigkeit: Antidependence sind WAR-Konflikte, welche entstehen, wenn ein Folgebefehl auf ein Register schreiben möchte, das noch von einem Anderen benutzt wird. Output Dependece sind WAW-Konflikte, welche entstehen, wenn mehrere Befehle auf ein und das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. D
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itr löst diese Abhängigkeiten durch eine clevere Umordnung der Befehlsfolge auf. Es gibt aber noch eine andere Möglichkeit, welche aber hardwareseitig unterstützt werden muss. (VLIW, Superskalar) <span>Folgende Abhängigkeiten verhindern, dass die CPI auf eins gehen: Forwarding Beim Forwarding werden Ergebnisse, sobald sie vorliegen an die nächste Stufe weitergereicht und nicht erst auf das Write Back gewartet. In anderen Worten: Das Ergebnis der ALU wird dieser sofort wieder eingespeist. Folgende Abhängigkeiten verhindern, dass die CPI auf eins gehen: Control Hazards bzw. Sprungverzögerungen Sprungergebnisse stehen erst in der Write Back Phase an. Moderne Prozessoren ha
Original toplevel document
Grundprinzipien der Rechnerarchitektureinen Verweis auf die Nächste enthalten. Sprünge sind einfach möglich. Angewandt wird dies in Form von Opcodes, welche nichts anderes als Adressen auf Mikroinstruktionen im Steuerspeicher sind. <span>Kapitel 6 - Pipelining Wozu dient Pipelining? Pipelining soll es ermöglichen Befehle überlappt auszuführen. Dazu sind ein einheitliches Befehlsformat fester Länge Grundlage. Deshalb werden werden nur auf Register getätigt. Für Speicheroperationen wird die LOAD / STORE Philosophie verfolgt, um langsame Hauptspeicherzugriffe zu minimieren. Was ist Voraussetzung für Pipelining? Die Befehlsverarbeitungsphase muss sich in mehrere voneinander unabhängige Phasen unterteilen lassen. Die einfachste Form einer Pipeline ist die 5-stufige mit folgenden Phasen: Befehl holen Befehl dekodieren Befehl ausführen Auf Speicher zugreifen Ergebnis in Register schreiben Moderene CPU's haben weitaus komplexere Pipelines, in denen die einzelnen Stufen wiederrum in mehrere sich überlappende Phasen aufgeteilt werden. Der allgemeine Aufbau einer (fünfstufigen) Pipeline Um Parallelität in der Befehlsausführungsphase zu erreichen, wird der Datenpfad so konstruiert, daß folgende (hier fünf) Phasen unabhänig voneinander arbeiten können. Nur so ist es möglich eine verzahnte Abarbeitung mehrerer Befehle zu erreichen. Abb.: Die Piplelinestufen Somit wird ,nachdem eine Pipeline gefüllt ist, im Optimalfall pro Takt ein Befehl fertig. (CPI = 1) Welche Pipeline-Konflikte müssen behandelt werden? Datenabhängigkeiten (Data Hazards) Sind logische Abhängigkeiten, welche eine verzögerte Abarbeitung erfordern, weil z.B. ein Folgebefehl auf ein Ergebnis eines anderen Befehles warten muss. Jump- / Branchverzögerungen (Control Hazards) Bei Sprungbefehlen liegt oft das Sprungziel nach der Dekodieung noch nicht fest. Somit müssen Techniken eingesetzt werden um diese Wartezeiten zu minimieren. (Branch Prediction) Ressourcenkonflikte (Structural Hazards) Bei bestimmten Befehlskombinationen ist es unter Umständen möglich, daß ein Teilwerk seine Arbeit wiederholen muss. Solche Ressourcenkonflikte treten dann auf, wenn nicht jeder Teilphase völlig unabhängige Teilwerke zugeordnet sind. Ein Beispiel ist z.B. ein zeitgleicher Lesezugriff eines LOAD/STORE Befehles, welcher sich zwangsweise mit einem eventuellen MEM ACCESS eines anderen Befehles überschneidet. Abhilfe können hier Dual-Port RAM, Havard-Architektur oder getrennte Code- und Datencaches schaffen. Welche drei verschiedenen Datenabhängigkeiten gibt es? RAW, WAW und WAR-Konflikte sind Datenabnhänigkeiten, welche in Pipelines auftreten können. Dabei ist das RAW-Problem für Pipelines typisch. WAR Konflikte treten eher bei Out-Of-Order Execution auf. Um Read-After-Write Konflikte aufzulösen, gibt es verschiedene Ansätze wie Softwarelösungen ( Compileroptimierung), Scoreboarding (zentrale Steuerlogik) und Forwarding (zusätzlicher Datenpfad). Was ist Forwarding? Beim Forwarding wird ein Bypass eingerichtet, welcher ein Ergebniss einer Operation schon einem Folgebefehl zur Verfügung stellt, bevor es überhaupt in ein Register geschrieben wurde. Aber trotz Load-Forwarding hat ein Ladebefehl eine Verzögerung, welche nicht gänzlich eliminiert werden kann. In diesem Fall kann die Delayed-Load Technik oder auch eine Befehlsumordnung Anhilfe schaffen. Was ist die Delayed Load-Technik? Bei der Delayed Load-Technik wird die Verzögerung nach einem LOAD Befehl als architektonisches Merkmal angesehn und den Compilerbauern offengelegt. Diese können nun durch Befehlsumordnungen versuchen, nach einem LOAD-Befehl einen datenunabhängigen Befehl einzufügen, um den Slot zu füllen. Zusammenfassung Pipelining Pipelines werden in allen modernen CPUs benutzt. Die UltraSparc2 hat neun und der P2 zwölf Stufen. Der Intel Pentium Itanium weißt eine 20 stufige Superpinepline (pipeline in der sich einzelne Stufen überlappen können) auf! Pipes werden heutzutage in Kombination mit der Superskalartechnik verwendet, um höchste Effizienz und Parallelverarbeitung gewährleisten zu können. Die fünf grundlegenden Stufen einer einfachen Pipeline sind IF,ID,EX,MEM und WB. Takte T = Befehle + (Pipestufen - 1) Folgende Abhängigkeiten verhindern, dass die CPI auf eins gehen: Strucual Hazards bzw. Ressourcenkonflikte IF und MEM wollen gleichzeitig auf Speicher lesend oder schreibend zugreifen. Das geht nicht, außer bei Dual-Port-RAM, welcher aber sehr teuer ist. Dieses Problem tritt aber bei modernen CPU's kaum noch auf, da eh intern eine Havard-ähnliche Architektur mit getrenntem Befehls- und Datencache gearbeitet wird. Data Hazards bzw. Datenabhängigkeiten Ein Folgebefehl wartet auf das Writeback der darüber liegenden Pipe, da er von diesem Befehl abhängig ist. Dies kann durch Nops bzw. Stalls ineffizient gelöst werden. Besser der Programmierer oder der Compiler löst diese Abhängigkeiten durch eine clevere Umordnung der Befehlsfolge auf. Es gibt aber noch eine andere Möglichkeit, welche aber hardwareseitig unterstützt werden muss. (VLIW, Superskalar) Forwarding Beim Forwarding werden Ergebnisse, sobald sie vorliegen an die nächste Stufe weitergereicht und nicht erst auf das Write Back gewartet. In anderen Worten: Das Ergebnis der ALU wird dieser sofort wieder eingespeist. Control Hazards bzw. Sprungverzögerungen Sprungergebnisse stehen erst in der Write Back Phase an. Moderne Prozessoren haben aber schon in der Fetch/Decode-Einheit eine Logik, welche die Zieladresse des Sprunges berechnet. Eine andere Möglichkeit ist die des spekulativen Ausführens. Hier tritt aber das Problem auf, dass viel Aufwand bei falscher Spekulation getrieben werden muss. Was ist der Unterschied zwischen echten und unechten Datenabhängigkeiten? Echte Datenabhängigkeiten sind RAW-Konflikte, bei dem ein Befehl auf die Beendigung eines Anderen warten muss, da er das Ergebnis als Operand benötigt. Unechte Datenabhängigkeit sind Abhängigkeiten, welche nur durch Namensabhängigkeit entstehen. Es gibt zwei Arten unechter Datenabhängigkeit: Antidependence sind WAR-Konflikte, welche entstehen, wenn ein Folgebefehl auf ein Register schreiben möchte, das noch von einem Anderen benutzt wird. Output Dependece sind WAW-Konflikte, welche entstehen, wenn mehrere Befehle auf ein und das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. D
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itn Ergebnisse, sobald sie vorliegen an die nächste Stufe weitergereicht und nicht erst auf das Write Back gewartet. In anderen Worten: Das Ergebnis der ALU wird dieser sofort wieder eingespeist. <span>Folgende Abhängigkeiten verhindern, dass die CPI auf eins gehen: Control Hazards bzw. Sprungverzögerungen Sprungergebnisse stehen erst in der Write Back Phase an. Moderne Prozessoren haben aber schon in der Fetch/Decode-Einheit eine Logik, welche die Zieladresse des Sprunges berechnet. Eine andere Möglichkeit ist die des spekulativen Ausführens. Hier tritt aber das Problem auf, dass viel Aufwand bei falscher Spekulation getrieben werden muss. <span>
Original toplevel document
Grundprinzipien der Rechnerarchitektureinen Verweis auf die Nächste enthalten. Sprünge sind einfach möglich. Angewandt wird dies in Form von Opcodes, welche nichts anderes als Adressen auf Mikroinstruktionen im Steuerspeicher sind. <span>Kapitel 6 - Pipelining Wozu dient Pipelining? Pipelining soll es ermöglichen Befehle überlappt auszuführen. Dazu sind ein einheitliches Befehlsformat fester Länge Grundlage. Deshalb werden werden nur auf Register getätigt. Für Speicheroperationen wird die LOAD / STORE Philosophie verfolgt, um langsame Hauptspeicherzugriffe zu minimieren. Was ist Voraussetzung für Pipelining? Die Befehlsverarbeitungsphase muss sich in mehrere voneinander unabhängige Phasen unterteilen lassen. Die einfachste Form einer Pipeline ist die 5-stufige mit folgenden Phasen: Befehl holen Befehl dekodieren Befehl ausführen Auf Speicher zugreifen Ergebnis in Register schreiben Moderene CPU's haben weitaus komplexere Pipelines, in denen die einzelnen Stufen wiederrum in mehrere sich überlappende Phasen aufgeteilt werden. Der allgemeine Aufbau einer (fünfstufigen) Pipeline Um Parallelität in der Befehlsausführungsphase zu erreichen, wird der Datenpfad so konstruiert, daß folgende (hier fünf) Phasen unabhänig voneinander arbeiten können. Nur so ist es möglich eine verzahnte Abarbeitung mehrerer Befehle zu erreichen. Abb.: Die Piplelinestufen Somit wird ,nachdem eine Pipeline gefüllt ist, im Optimalfall pro Takt ein Befehl fertig. (CPI = 1) Welche Pipeline-Konflikte müssen behandelt werden? Datenabhängigkeiten (Data Hazards) Sind logische Abhängigkeiten, welche eine verzögerte Abarbeitung erfordern, weil z.B. ein Folgebefehl auf ein Ergebnis eines anderen Befehles warten muss. Jump- / Branchverzögerungen (Control Hazards) Bei Sprungbefehlen liegt oft das Sprungziel nach der Dekodieung noch nicht fest. Somit müssen Techniken eingesetzt werden um diese Wartezeiten zu minimieren. (Branch Prediction) Ressourcenkonflikte (Structural Hazards) Bei bestimmten Befehlskombinationen ist es unter Umständen möglich, daß ein Teilwerk seine Arbeit wiederholen muss. Solche Ressourcenkonflikte treten dann auf, wenn nicht jeder Teilphase völlig unabhängige Teilwerke zugeordnet sind. Ein Beispiel ist z.B. ein zeitgleicher Lesezugriff eines LOAD/STORE Befehles, welcher sich zwangsweise mit einem eventuellen MEM ACCESS eines anderen Befehles überschneidet. Abhilfe können hier Dual-Port RAM, Havard-Architektur oder getrennte Code- und Datencaches schaffen. Welche drei verschiedenen Datenabhängigkeiten gibt es? RAW, WAW und WAR-Konflikte sind Datenabnhänigkeiten, welche in Pipelines auftreten können. Dabei ist das RAW-Problem für Pipelines typisch. WAR Konflikte treten eher bei Out-Of-Order Execution auf. Um Read-After-Write Konflikte aufzulösen, gibt es verschiedene Ansätze wie Softwarelösungen ( Compileroptimierung), Scoreboarding (zentrale Steuerlogik) und Forwarding (zusätzlicher Datenpfad). Was ist Forwarding? Beim Forwarding wird ein Bypass eingerichtet, welcher ein Ergebniss einer Operation schon einem Folgebefehl zur Verfügung stellt, bevor es überhaupt in ein Register geschrieben wurde. Aber trotz Load-Forwarding hat ein Ladebefehl eine Verzögerung, welche nicht gänzlich eliminiert werden kann. In diesem Fall kann die Delayed-Load Technik oder auch eine Befehlsumordnung Anhilfe schaffen. Was ist die Delayed Load-Technik? Bei der Delayed Load-Technik wird die Verzögerung nach einem LOAD Befehl als architektonisches Merkmal angesehn und den Compilerbauern offengelegt. Diese können nun durch Befehlsumordnungen versuchen, nach einem LOAD-Befehl einen datenunabhängigen Befehl einzufügen, um den Slot zu füllen. Zusammenfassung Pipelining Pipelines werden in allen modernen CPUs benutzt. Die UltraSparc2 hat neun und der P2 zwölf Stufen. Der Intel Pentium Itanium weißt eine 20 stufige Superpinepline (pipeline in der sich einzelne Stufen überlappen können) auf! Pipes werden heutzutage in Kombination mit der Superskalartechnik verwendet, um höchste Effizienz und Parallelverarbeitung gewährleisten zu können. Die fünf grundlegenden Stufen einer einfachen Pipeline sind IF,ID,EX,MEM und WB. Takte T = Befehle + (Pipestufen - 1) Folgende Abhängigkeiten verhindern, dass die CPI auf eins gehen: Strucual Hazards bzw. Ressourcenkonflikte IF und MEM wollen gleichzeitig auf Speicher lesend oder schreibend zugreifen. Das geht nicht, außer bei Dual-Port-RAM, welcher aber sehr teuer ist. Dieses Problem tritt aber bei modernen CPU's kaum noch auf, da eh intern eine Havard-ähnliche Architektur mit getrenntem Befehls- und Datencache gearbeitet wird. Data Hazards bzw. Datenabhängigkeiten Ein Folgebefehl wartet auf das Writeback der darüber liegenden Pipe, da er von diesem Befehl abhängig ist. Dies kann durch Nops bzw. Stalls ineffizient gelöst werden. Besser der Programmierer oder der Compiler löst diese Abhängigkeiten durch eine clevere Umordnung der Befehlsfolge auf. Es gibt aber noch eine andere Möglichkeit, welche aber hardwareseitig unterstützt werden muss. (VLIW, Superskalar) Forwarding Beim Forwarding werden Ergebnisse, sobald sie vorliegen an die nächste Stufe weitergereicht und nicht erst auf das Write Back gewartet. In anderen Worten: Das Ergebnis der ALU wird dieser sofort wieder eingespeist. Control Hazards bzw. Sprungverzögerungen Sprungergebnisse stehen erst in der Write Back Phase an. Moderne Prozessoren haben aber schon in der Fetch/Decode-Einheit eine Logik, welche die Zieladresse des Sprunges berechnet. Eine andere Möglichkeit ist die des spekulativen Ausführens. Hier tritt aber das Problem auf, dass viel Aufwand bei falscher Spekulation getrieben werden muss. Was ist der Unterschied zwischen echten und unechten Datenabhängigkeiten? Echte Datenabhängigkeiten sind RAW-Konflikte, bei dem ein Befehl auf die Beendigung eines Anderen warten muss, da er das Ergebnis als Operand benötigt. Unechte Datenabhängigkeit sind Abhängigkeiten, welche nur durch Namensabhängigkeit entstehen. Es gibt zwei Arten unechter Datenabhängigkeit: Antidependence sind WAR-Konflikte, welche entstehen, wenn ein Folgebefehl auf ein Register schreiben möchte, das noch von einem Anderen benutzt wird. Output Dependece sind WAW-Konflikte, welche entstehen, wenn mehrere Befehle auf ein und das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. D