Edited, memorised or added to reading queue
on 10-Sep-2024 (Tue)
Do you want BuboFlash to help you learning these things? Click here to log in or create user.
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
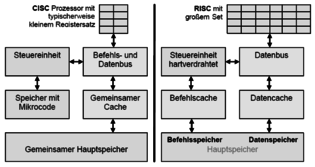
Open itAssemblern verarbeitet werden, sind weitaus komplexere Befehle möglich. CISC bietet einen sehr großen Befehlssatz mit sich start unterscheidenden Befehlen in Ausführungszeit und Parameterliste. <span>Gegenüberstellung der Architektur von CISC und RISC Worin unterscheiden sich RISC und CISC besonders? Eigenschaften CISC RISC Register Wenige Register( ca. 20) Viele Register (bis zu 200) und Registerfenster Befehlssatz ca. 300 Befehle u
Original toplevel document
Grundprinzipien der Rechnerarchitekturon Kapitel 8 - Superskalarität Kapitel 9 - Parallelrechner Zurück zur Übersicht Rechnerarchitektur Grundprinzipien der Rechnerarchitektur. D.h. Themen wie RISC, Branch Prediction oder Tomasulo. <span>Kapitel 1 - Prinzipien und Architekturen In welche sieben Ebenen kann man ein Rechnersystem einteilen? Anwendungsebene (Anwendersoftware) Assemblerebene (Beschreibung von Algorithmen, Link & Bind) Betriebssystem (Speichermanagment, Prozesskommunikation) Instruction Set Architecture (ISA,Adressierungsarten) Microarchitektur (Risc,Cisc,Branch Prediction..) Logische Ebene (Register,Schieber, Latches..) Transistorebene (Transistoren, MOS ) nach Tanenbaum Computerarchitektur Wie lassen sich Architekturen klassifizieren? Nach ihrem Rechenprinzip Von Neumann (Steuerfluss) Datenfluß (Zündregel) Reduktion (Funktionsaufruf) Objektorientiert (Methodenaufruf) Nach dem Architektur-Grundkonzept Vektorrechner (Pipeline) Array-Computer (Data-Array) Assoziativ-Rechner (Assoziativ-Speicher) Wie kann die Leistung erhöht werden? Über die Architektur Pipelines, Superskalarität, Spekulative Ausführung, Caches, Busbreite Über Optimierung von Software Compileroptimierung Über die Siliziumbasis Transistordichte und Taktraten Was sind die vier Hauptbestandteile eines typischen Rechners? Was unterscheidet eine Schnittstelle von einem Bus? Ein Bus verbindet mehr als zwei Teilnehmer. John von Neumann mit ENIAC Welche Bestandteile definieren einen von Neumann-Rechner? Der von Neumann-Rechner arbeitet sequentiell, Befehl für Befehl wird abgeholt, interpretiert, ausgeführt und das Resultat abgespeichert. Steuerwerk (Taktgeber und Befehlszähler) Speicher Rechenwerk (CPU) I/O-Einheit Datenbreite, Adressierungsbreite, Registeranzahl und Befehlssatz können als Parameter verstanden werden. Wie arbeitet die zentrale Befehlsschleife eines Von-Neumann-Rechners? Was heißt Havard-Architektur? Daten- und Befehlsspeicher sind getrennt. So ist es möglich Daten und Befehle Zeitgleich aus dem Speicher zu holen. Da dies aber einen extrem hohen Aufwand bedeutet, wird dies nur bei Echtzeitanwendungen implementiert. Was ist ein Taktzyklus? Die Interpretation und Ausführung eines Befehles erfolgt in vier Phasen. Holen Dekodieren (inklusive Operandenadressen berechnen) Daten holen (bzw. Operanden) Ausführen Jede der vier Phasen wird in eine Anzahl von Schnittstellen bzw. Zyklen eingeteilt. Ein Taktzyklus ist die kleinstmöglich verarbeitbare Einheit. Somit benötigt ein Befehl zur Ausführung im Allgemeinen mehr als einen Taktzyklus. Was ist Mikroprogrammierung? Durch Einsatz von Matrix-Speichertechnologie ist es möglich Steuersignalkombinationen in je einer Zeile dieser Speichermatrix abzulegen. Somit können Zeile für Zeile Maschinenzustande auf dem Prozessor hinterlegt werden. Das sogenannte Mikroprogramm. Die interne Logik ist eher zufällig optimiert. Daher der Begriff "Random Logic". Was sind Complex Instruction Set Computer (CISC)? Durch Einführung von mnemonischen Kodierungen von Mikrobefehlen, welche von Mikrobefehls-Assemblern verarbeitet werden, sind weitaus komplexere Befehle möglich. CISC bietet einen sehr großen Befehlssatz mit sich start unterscheidenden Befehlen in Ausführungszeit und Parameterliste. Gegenüberstellung der Architektur von CISC und RISC Worin unterscheiden sich RISC und CISC besonders? Eigenschaften CISC RISC Register Wenige Register( ca. 20) Viele Register (bis zu 200) und Registerfenster Befehlssatz ca. 300 Befehle und mehr als 50 Befehlstypen Nur rund 100 meist registerorientierte Befehle (außer LOAD / STORE) Adressierungsarten ca. 12 verschiedene Nur 3 bis 5 Arten und nur LOAD/STORE zum Speicher Caches Gemeinsame Caches, aber später auch Getrennte Getrennte Daten- und Befehlscaches nach Harvard CPI 1 bis 20 - Durchschnittlich 4 1 bei Basisoperationen - im Schnitt 1,5 Befehlssteuerung Mikrocode im Speicher, aber auch hartverdrahtet Meistens hartverdrahtete Mikroprogramme ohne Mikroprogrammspeicher Beispielprozessoren Intel x86, AMD, Cyrix Sun UltraSparc, PowerPC Welche Befehlssatz-Architekturen kennen Sie? Stack-Architektur? Diese Form benötigt keine Adressen für Operanden und ist somit eine Nulladressmaschine. Quell und Ergebnisoperanden liegen auf einem Operanden-Stack. Vorteil dieser Architektur ist daher die Speicherplatzeinsparung durch die nicht notwendigen Adressen. Akkumulator-Architektur? Um Verknüpfungsoperationen durchzuführen, liegt ein Operand in einem Register und ein Operand typischerweise im Hauptspeicher (Einadressmaschine) . Vorteil ist die einfache Implementierung, da nur ein internes Register benötigt wird. Nachteil ist aber die hohe Speicherlast. Universalregister-Architektur? Ein Satz von gleichberechtigten Registern kann zum Ablegen von Daten genutzt werden. Deshalb sind im Op-Code mehrere Operanden anzugeben (Zwei-, Dreiadressmaschine etc.) Vorteil ist die freie Benutzbarkeit durch Compiler. Ausdrucksberechnungen können somit in beliebiger Reihenfolge erfolgen, was Pipelining möglich macht. Dazu kommt, daß die Speichertransferlast sinkt, die Geschwindigkeit steigt und Superskalartechniken sind effizient einsetzbar. Der Nachteil dieser Architektur sind die teilweise großen Registersets, welche bei jedem Kontextwechsel auszutauschen sind. Außerdem müssen die Operanden Adressiert werden, was zu langen Befehlen führt. Welche Register-Architekturen gibt es? Register-Register ohne Speicheradressen (Sparc,Mips) Verknüpfungsoperationen verwenden nur Register. Nur in Lade- und Speicherbefehlen werden Adressen verwendet. (Load / Store - Architektur). Vorteil ist, dass die Verknüpfungen immer mit Registern geschehen und somit eine Befehlsdekodierung mit fester Länge möglich ist. Vorteile Einheitliche Taktzyklen pro Befehl Pipeline-Prinzip wird dadurch unterstützt Nachteile Code wird größer, da Speichertransfers nur durch zusätzliche Befehle Register-Speicher mit der Möglichkeit von Speicheradressen (Motorola 68000) Vorteile Daten können auch im Speicher referenziert werden, ohne diese vorher Explizit laden zu müssen. Nachteile Durch die variierenden Adressierungen variieren Befehlslänge und Taktzyklen pro Befehl, was äußerst negativ für Verfahren wie Pipelining ist. Speicher-Speicher mit nur Speicheradressen (DEC-VAX) Vorteile Der Programmierer braucht sich nicht um Register kümmern. Deshalb wird die Programmierung transparenter. Nachteile Es entsteht ein hoher Speicherverkehr, was sich Nachteilig auf die Performance auswirkt. Falls doch Register erlaubt werden (Orthogonaler Befehlssatz / CISC), variieren auch hier Befehlslänge und Taktanzahl pro Befehl. Orthogonale Befehlssätze sind solche, welche eine beliebige Kombination von Befehlscode, Adressierungsart und Datentyp zulassen. Was ist Byte-Ordering und Word-Alignment? Alle konventionellen Rechner sind Byte-Adressiert. D.h. das Worte (egal ob 8, 16 oder mehr Bit) bestehen aus einer Folge (aufsteigender) Bytes. Dabei gilt das erste Byte als die Adresse des Wortes. Nimmt die Wertigkeit mit aufsteigender Adresse zu, ist es das Litte-Endian-Format, umgekehrt das Big-Endian-Format. Falls Worte so in den Speicher passen, das keine Verschiebungen auftreten, heißt der Speicher aligned. Prüfen kann man dies durch die Formel Adresse mod Wortlänge = 0? Kapitel 2 - Interrupts und DMA Klassifizieren Sie die verschiedenen Unterbrechungen! Wenn in der Literatur von Interrupts gesprochen wird, so werden oft externe, asynchrone Interrupts g
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itObjekt, welches eindeutig über einen Deskriptor mit Basisadresse, Zugriffsrechten und Limit beschieben wird. Auf Basis dieser Segmente arbeitet die komplette Speicherverwaltung eines Rechners. <span>Wie wird auf Segmente zugegriffen? Segmente werden über eine Deskriptortabelle indiziert. Die Tabellen enthalten Pointer auf die Speicherbereiche der jeweiligen Segmente. Was ist das besondere am segmentierten Adreßraum? Adressen auf Basis von Segmenten sind im unterschied zu linearen Adressen zweidimensional. Sie bestehen aus Segment und Offset. Berechn
Original toplevel document
Grundprinzipien der Rechnerarchitekturs den Index Stapeladressierung Hier ist gar keine Adressangabe notwendig Somit sind die Instruktionen sehr kurz Die Stapeladressierung arbeitet mit der umgekehrten polnischen Notation (Postfix) <span>Kapitel 3 - Speicherschutz und Multitasking Um unberechtigte Zugriffe, Datenaufrufe oder Systemprozedurecalls zu vermeiden und Task-Isolation zu gewährleisten, ist ein ausgeklügeltes Speicherschutzsystem notwendig. Segmente zum schützen von Speicherbereichen Segmente sind logische Speicherbereiche variabler Länge (Pages sind normalerweise gleich groß und ergeben zusammengesetzt ein Segment). In einem Segment ist wiederum eine Aufteilung in Code-, Daten- und Speichersegment zu finden. Jedes Segment definiert ein Objekt, welches eindeutig über einen Deskriptor mit Basisadresse, Zugriffsrechten und Limit beschieben wird. Auf Basis dieser Segmente arbeitet die komplette Speicherverwaltung eines Rechners. Wie wird auf Segmente zugegriffen? Segmente werden über eine Deskriptortabelle indiziert. Die Tabellen enthalten Pointer auf die Speicherbereiche der jeweiligen Segmente. Was ist das besondere am segmentierten Adreßraum? Adressen auf Basis von Segmenten sind im unterschied zu linearen Adressen zweidimensional. Sie bestehen aus Segment und Offset. Berechnet werden sie durch einfache Addition von Segment und Offset. Vor der Addition ist das Segment um 4 Stellen nach links zu verschieben. 0002 : 000F berechnet sich also aus 0020 + 000F = 0001F Was sind die Nachteile des Realmodes? Begrenzung eines Segments auf maximal 64 KB, da Offsetadresse nur 16 Bit groß ist Es nur das erste MByte durch das Betriebssystem adressierbar kein Schutz des Speichers vor anderen Programmen Einträge aus der Interruptvektor-Tabelle sind leicht veränderbar nur ein Programm kann ausgeführt werden Was hat Multitasking mit Protected Mode zu tun? Multitasking kann nur durch Protected Mode arbeiten. Er ist sozusagen Grundlage für alle multitaskingfähigen Betriebssysteme. nsbesondere geht es um gegenseitigen Schutz der laufenden Tasks Taskwechselunterstützung durch das Betriebssystem Privilegierungsmechanismen Betriebssystemfunktionen zur Verwaltung von virtuellen Speicher Getrennte Stacks für Parameterübergabe Lösung des "Trojanischen Pferd" Problems Privilegebenen Im Protected Mode werden Anwendungen und Betriebssystem strikt getrennt. Es gibt vier Privilegstufen (null bis drei), welche über die Ausführung verschiedener Maschinensprachebefehle entscheiden. Befehle der Ebene Null sind z.B. das Laden der globalen Deskriptorentabelle oder des Maschinenstatuswortes. Aus welchen beiden Teilen besteht eine Virtuelle Adresse? Eine virtuelle Adresse beinhaltet den Segmentselektor, welcher auf einen Eintrag in der Deskriptortabelle zeigt. Das Segment-Offset zeigt auf die dazugehörige Adresse in dem selektierten Segment. Aus welchen drei Teilen setzt sich ein Segmentselektor zusammen? Aus dem Index, der den Eintrag in der Deskriptortabelle referenziert, dem Table Indicator, welcher über globalem oder lokalem Adressraum entscheidet und den Privelege Level. TI - Table Indicator 0 = GDT (Global Deskriptor Table für den globalen Adreßraum) 1 = LDT (Local Deskriptor Table für den lokalen Adreßraum) RPL Requestor's Privilege Level Privilegstufe des Segments, auf welches der Selektor verweist Was ist ein Deskriptor? Deskriptoren sind Abbildungen zwischen der virtuellen bzw. logischen Adresse (Segmentselektor:Offset) und der linearen Adresse (Basisadresse und Offset). Aus der linearen Adresse wird dann die physikalische Adresse berechnet. (bei i286 war die lineare Adresse noch gleich der physikalischen Adresse, da es noch keine Paging-Einheit gab) Was steht alles in so einem Eintrag in der Deskriptortabelle? Die "normalen" Deskriptoren, welche einen normalen Adressraum (Daten-, Code- oder Stacksegment) beschreiben, enthalten die Basisadresse des Segmentes im Speicher die Zugriffsrechte die Länge des Segmentes Eine andere Klasse von Deskriptoren sind System-Segment-Deskriptoren und zur Ablaufsteuerung notwendige Deskriptoren. Erstere definieren Einsprungpunkte in spezielle System-Unterroutinen oder Gates. Letztere sind Deskriptoren für Task-State-Segmente oder Local-Deskriptor-Tables. Aktiv sind aber immer nur eine globale, eine lokale Interrupt-Beschreibertabelle und eine Interrupt-Beschreibertabelle. Was ist ein Gate? Gates sind spezielle Eintritts-Deskriptoren in Segmente höherer Privilegstufe. (Interrupt- oder Trap-Gate-Deskriptoren) Worin unterscheiden sich GDT und LDT? Die Global Descriptor Table einhält Segmente des globalen Adressraums, welcher für alle Tasks zur Verfügung steht. Dagegen sind mit Local Descriptor Table allokierte Segmente nur von den Host-Tasks selbst adressierbar. (privater Adressraum) Lokale Deskriptortabellen sind Grundlage für die Task-Isolation und daher extrem wichtig für Sicherheit und Segmentschutz. Beschreiben Sie den Aufbau einer Globalen Deskriptortabelle ... ... Globale C/D2 Globale Code-/Daten-Deskriptoren Globale C/D1 Globale Code-/Daten-Deskriptoren ... ... System D2 Gates bzw. TSS-Deskriptoren System D1 Gates bzw. TSS-Deskriptoren ... ... ... ... LDT 2 Lokale Deskriptoren für individuellen Task LDT 1 Lokale Deskriptoren für individuellen Task ... ... ... ... IDT 2 Interrupt/Exeption Gates bzw. Deskriptoren IDT 1 Interrupt/Exeption Gates bzw. Deskriptoren GTD_alias ermöglicht dynamischen Zugriff auf die GDT 0-Selektor Zugriff auf 0-Selektor führt zu Exeption Was unterscheidet Real-Mode und Protected-Mode? Im Real-Mode gibt es keine Deskriptoren und somit ist auch kein Segmentschutz möglich. Die Basisadresse berechnet sich einfach aus dem Segment-Register, welches maximal 1 MByte adressieren kann, da es nur 20 Bit breit ist. Im Protected-Mode werden die Basisadressen mittels Deskriptoren bestimmt. Auf Grund dieser Unterschiede sind folgende Merkmale für den Protected-Mode signifikant: Virtuelle Speicherverwaltung Speicherschutzmechanismen durch Segmentation (über Deskriptoren) Paging möglich echtes Multitasking möglich I/O-Privilegierung und privilegierte Befehle Was ist Paging und wie funktioniert es? Paging wird ab i386 vom Prozessor unterstützt und ist nichts weiter als eine Einteilung des Speichers in gleich große Seiten. Vorteil des virtuellen Speichers, welcher durch Mapping oder Paging erst möglich ist, sind für Anwendungen theoretisch unendlich großen Arbeitsspeicher. Grund dafür ist, dass der Tertiärspeicher als Zwischenspeicher für schlafende oder temporär nicht notwendige Seiten ausgenutzt wird. Es gibt ausgeklügelte Seitenerstetzungsalgorithmen, welche das Austauschen von Seiten übernehmen. Ein weiteres Problem was beim Paging gelöst werden muss, ist die eventuell entstehende Inkonsistenz. D ieses Problem wird wie bekanntermaßen üblich durch Dirty-Bits in den Pages gelöst. Verwirrend ist anfangs der Zusammenhang von Segmentierung und Paging. Letztendlich laufen beide Technologien gleichzeitig auf einem modernen System und ergänzen sich gegenseitig. Paging ist hinter den Segmentierungsvorgang geschalten, um Transparenz zu gewährleisten. Die durch die Segmentierung berechnete bzw. übergebene lineare Adresse entspricht ohne Paging der physikalischen. Falls Paging aktiv ist, muss noch etwas mehr getan werden. Die Umsetzung von Linearer in Physikalischer Adresse hängt vom verwendeten Paging ab. Normalerweise wird über die ersten Bits die Page-Table referenziert und über die folgenden der Pagetable-Eintrag, aus dem die Basisadresse geholt wird. Der Offset wird normalerweise beibehalten. Beschreiben Sie was bei einem Page-Fault intern alles abläuft? Während Abarbeitung einer Befehlssequenz erfolgen mehrere Seitenzugriffe Es erfolgt ein Zugriff auf eine Seite. Prozessor prüft die Seite (ist sie im Speicher?). Seite gibt Page Not Present State zurück (d.h. Seite nicht im Speicher) CPU löst Page Fault Exception aus (Siehe System-Aufruf-Deskriptoren) Betriebssystem gibt in Auftrag die Seite von Platte zu holen Prozessor aktiviert Festplattenhardware und positioniert Leseköpfe Seite wird über DMA-Transfer von Disk-To-free Memory übertragen Betriebssystem aktualisiert Pagetable einschließlich des TLB (flush TLB) Betriebssystem startet den unterbrochenen Befehl neu Nennen Sie Vorteile und Nachteile des Pagings gegenüber Segmentation-Only! Performanceerhöhung eines Multitasking-Betriebssystems Verwaltung der Swap-Datei wird durch die Verwendung konstanter Speicherblöcke einfacher nur die 4-KByte werden eingelagert, die tatsächlich benötigt werden und nicht das gesamte Segment Nachteile: Ausführung verzögert sich, weil die Adresse erst dekodiert werden muß bei Zugriff auf eine Seite/Page evtl. erst Einlagerung dieser vom Sekundärspeicher notwendig (Present-Bit) Wie kann man die Adressdekodierung beim Paging umgehen? Durch Translation Lookaside Buffer. Ein TLB ist ein assoziativer Vierwege-Cache, welcher die 32 Page-Table-Einträge aufnimmt, auf die der Prozessor zuletzt zugegriffen hat (LRU-Strategie). Ein TLB Eintrag besteht aus drei logischen Blöcken: Datenblock mit Page-Attributen und physikalische Basisadresse einer Page Tagblock enthält die oberen 17 Bit einer linearen Adresse und Schutz-Bits LRU-Block (Least Recently Used) zeigt letzten Zugriff an Page- und Segmentschutz Zuerst wirkt der Segmentschutz und danach Pageschutz. Pageschutz ist nur 2-stufig. Die inneren drei Privilegebenen sind beim Paging als Supervisor-Code geschützt. Die äußere Ebene ist User-Code. Ein Zugriffsversuch einer User-Page auf eine Supervisor-Page löst eine Exception aus. Was unterscheidet kooperatives und preemtives Multitasking? Beim kooperativen Multitasking entscheiden die Tasks selbst über die Umschaltung der Prozessorleistung. (Naives und Gutgläubiges Verfahren, daß an die Vernunft aller Tasks und somit aller Programmierer glaubt : ) Preemptives Multitasking ist echtes Multitasking. Ein externer Timer steuert die Umschaltung der Tasks. Die Tasks können somit keinen Einfluss auf die Betriebsmittelumschaltung nehmen. Kapitel 4 - Speicherhierarchie und Caches Was bedeutet die Eigenschaft Lokalität? Aus programmtechnischer Sicht wiederholen sich oft Befehle und ganze Programmteile. Somit werden Daten
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itktor (einer Pro Task) welche die Segment-Deskriptoren des Prozesses enthält Stack-Segment-Pointer Verwaltungsinformation Adresse der Paging-Tabellen I/O-Map Base Adresse Busy-Bit, definiert den <span>aktuell rechnenden Task (genau einer im System) <span>
Original toplevel document
Grundprinzipien der Rechnerarchitekturauf. Ein DMA-Controller wirkt wie ein weiterer Prozessor am Bus. Um Inkonsistenzen im Speicher zu vermeiden, muss ein DMA-Controller eng mit dem Speichermanagment des Systems zusammenarbeiten. <span>Was ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adressraum verschiedenen I/O-Devices zuzuordnen oder Getrennten I/O Adressraum, bei dem auf einer speziellen Adressleitung die E/A-Adresse auf den Bus gelegt wird. (veraltete Variante) Was ist eine Task? Ein Task ist ein eigenständiges Programm / Prozess von vielen im Multitasksystem. Es wird von einem TSS (Task State Segment) beschrieben. Bei einem Taskwechsel werden alle Informationen in diesem TSS gespeichert. Jeder TSS-Deskriptor steht in der GDT. Die GDT hat beim i486 8192 Einträge, jedoch ist der 0. Eintrag immer leer. Somit sind maximal 8191 verschiedene Prozesse möglich (inclusive des Betriebssystems). Wie werden Task-Wechsel realisiert? Ein Taskwechsel geschieht durch Auswahl eines Task-Gates aus Globaler Deskriptor Tabelle (Task State Segment = TSS). Ein TSS Enthält alle Informationen, die einen Task ausmachen: verwendete Prozessor-Register LDT-Selektor (einer Pro Task) welche die Segment-Deskriptoren des Prozesses enthält Stack-Segment-Pointer Verwaltungsinformation Adresse der Paging-Tabellen I/O-Map Base Adresse Busy-Bit, definiert den aktuell rechnenden Task (genau einer im System) TR (Task Register) enthält den aktuellen TSS (Selektor des Descriptors des aktuellen TSS) TSS-Descriptoren nur in GDT! Bsp: Scheduler als Task ( Umschalter ) Umschalten durch jeweiligen Austausch des Back-Link, IRETD zum anderen Task, z.B. Timer-Interrupt-Task. Welche Möglichkeiten für Privilegwechsel gibt es? CALL in eine Prozedur mit anderen Privilegde-Level (CALL-Gate) JMP in eine Prozedur mit anderen Privi legde-Level (TASK-Gate) INT (TRAP-Gate) TASK-Gate durch erzwungenen Prozeßwechsel IRET Rücksprung aus INT-Handler Was ist der Unterschied zwischen einem Selektor und einem Deskriptor? Ein Selektor Segment-Register wählt einen Deskriptor in (GLI)DT aus, ein Deskriptor Eintrag in (GLI)DT, beschreibt das Segment. Weshalb ist es sinnvoll, dass ein TSS-Descriptor nur in der GDT stehen darf? Es soll verhindert werden, daß ein USER-Programm in einen anderen Task springt. Da Taskwechsel nur über TASK-Gates erfolgen (dieses zeigt auf einen TSS-Deskriptor) muß der CurrentPrivilegdeLevel (CPL vom CS:) numerisch kleiner sein, als das des geforderten TSS-Deskriptor (DPL) bzw. kleiner als der (RPL) des Segments wo sich der TSS-Deskriptor aufhält. Damit wird sichergestellt, daß der Taskwechsel nur von "höherem" Code (OS) aus ausgeführt werden kann. Würde ein TSS-Deskriptor in der LDT stehen, könnte es dort mit einem höheren RPL versehen werden, und der USER-Code könnte sich zum OS-CODE etablieren! Welche Grundtypen von Deskriptoren gibt es? IDT LDT GDT CODE-Segment DATA-Segment STACK-Segment CODE-Segment DATA-Segment STACK-Segment INT-Gate TRAP-Gate TASK-Gate TASK-Gate TASK-Gate CALL-Gate Welche grundlegenden Adressierungsarten gibt es? Unmittelbare Adressierung Direktadressierung (Direct Adressing) Registeradressierung Indirekte Registeradressierung Indizierte Adressierung Basisindizierte Adressierung Stapeladressierung Unmittelbare Adressierung Der Adressteil der Instruktion enthält den Operanden selbst, anstatt eines Verweises. Solche Operanden werden als Direktoperanden (Immediate) bezeichnet Bsp: MOV R4, 5H (5H wird direkt in R4 gespeichert) Direktadressierung (Direct Adressing) Es wird eine volle Adresse des Operanden angegeben Deshalb nur für globale Variablen anwendbar, da Instruktion immer auf gleiche Speicehrzeile zugreift Registeradressierung Das gleiche Prinzip wie Direct Adressing, nur das Register anstelle von Speicherzellen verwendet werden In Registern sollten die am häufigsten verwendeten Variablen abgelegt werden, da Register vielfach schneller als Hauptspeicher sind Load/Store-Architekturen nutzen fast nur diesen Registermode (außer es muss vom oder zum Speicher transferiert werden) Indirekte Registeradressierung Die Adresse wird nicht direkt angegeben, sondern indirekt über ein Register Das Register enthält somit einen Pointer auf eine Speicherzelle Vorteil ist, daß auf Speicher referenziert werden kann, aber keine volle Speicheradresse notwendig wird Indizierte Adressierung Der Speicher wird durch Angabe eines Registers und eines konstanten Offsets adressiert Häufig benutzt bei Arrayzugriffen, wie A = B[i] (MOV R1, B[R2]) Basisindizierte Adressierung Speicheradresse wird hier durch Addition zweier Register und einen optionalen Offset berechnet Eines der Register stellt die Basis dar und ein anderes den Index Stapeladressierung Hier ist gar keine Adressangabe notwendig Somit sind die Instruktionen sehr kurz Die Stapeladressierung arbeitet mit der umgekehrten polnischen Notation (Postfix) Kapitel 3 - Speicherschutz und Multitasking Um unberechtigte Zugriffe, Datenaufrufe oder Systemprozedurecalls zu vermeiden und Task-Isolation zu gewährleisten, ist ein ausgeklügeltes Sp
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itEin TSS Enthält alle Informationen, die einen Task ausmachen: verwendete Prozessor-Register LDT-Selektor (einer Pro Task) welche die Segment-Deskriptoren des Prozesses enthält Stack-Segment-Pointer Verwaltungsinformation Adresse der Paging-Tabellen I/O-Map Base Adresse Busy-Bit, definiert
Original toplevel document
Grundprinzipien der Rechnerarchitekturauf. Ein DMA-Controller wirkt wie ein weiterer Prozessor am Bus. Um Inkonsistenzen im Speicher zu vermeiden, muss ein DMA-Controller eng mit dem Speichermanagment des Systems zusammenarbeiten. <span>Was ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adressraum verschiedenen I/O-Devices zuzuordnen oder Getrennten I/O Adressraum, bei dem auf einer speziellen Adressleitung die E/A-Adresse auf den Bus gelegt wird. (veraltete Variante) Was ist eine Task? Ein Task ist ein eigenständiges Programm / Prozess von vielen im Multitasksystem. Es wird von einem TSS (Task State Segment) beschrieben. Bei einem Taskwechsel werden alle Informationen in diesem TSS gespeichert. Jeder TSS-Deskriptor steht in der GDT. Die GDT hat beim i486 8192 Einträge, jedoch ist der 0. Eintrag immer leer. Somit sind maximal 8191 verschiedene Prozesse möglich (inclusive des Betriebssystems). Wie werden Task-Wechsel realisiert? Ein Taskwechsel geschieht durch Auswahl eines Task-Gates aus Globaler Deskriptor Tabelle (Task State Segment = TSS). Ein TSS Enthält alle Informationen, die einen Task ausmachen: verwendete Prozessor-Register LDT-Selektor (einer Pro Task) welche die Segment-Deskriptoren des Prozesses enthält Stack-Segment-Pointer Verwaltungsinformation Adresse der Paging-Tabellen I/O-Map Base Adresse Busy-Bit, definiert den aktuell rechnenden Task (genau einer im System) TR (Task Register) enthält den aktuellen TSS (Selektor des Descriptors des aktuellen TSS) TSS-Descriptoren nur in GDT! Bsp: Scheduler als Task ( Umschalter ) Umschalten durch jeweiligen Austausch des Back-Link, IRETD zum anderen Task, z.B. Timer-Interrupt-Task. Welche Möglichkeiten für Privilegwechsel gibt es? CALL in eine Prozedur mit anderen Privilegde-Level (CALL-Gate) JMP in eine Prozedur mit anderen Privi legde-Level (TASK-Gate) INT (TRAP-Gate) TASK-Gate durch erzwungenen Prozeßwechsel IRET Rücksprung aus INT-Handler Was ist der Unterschied zwischen einem Selektor und einem Deskriptor? Ein Selektor Segment-Register wählt einen Deskriptor in (GLI)DT aus, ein Deskriptor Eintrag in (GLI)DT, beschreibt das Segment. Weshalb ist es sinnvoll, dass ein TSS-Descriptor nur in der GDT stehen darf? Es soll verhindert werden, daß ein USER-Programm in einen anderen Task springt. Da Taskwechsel nur über TASK-Gates erfolgen (dieses zeigt auf einen TSS-Deskriptor) muß der CurrentPrivilegdeLevel (CPL vom CS:) numerisch kleiner sein, als das des geforderten TSS-Deskriptor (DPL) bzw. kleiner als der (RPL) des Segments wo sich der TSS-Deskriptor aufhält. Damit wird sichergestellt, daß der Taskwechsel nur von "höherem" Code (OS) aus ausgeführt werden kann. Würde ein TSS-Deskriptor in der LDT stehen, könnte es dort mit einem höheren RPL versehen werden, und der USER-Code könnte sich zum OS-CODE etablieren! Welche Grundtypen von Deskriptoren gibt es? IDT LDT GDT CODE-Segment DATA-Segment STACK-Segment CODE-Segment DATA-Segment STACK-Segment INT-Gate TRAP-Gate TASK-Gate TASK-Gate TASK-Gate CALL-Gate Welche grundlegenden Adressierungsarten gibt es? Unmittelbare Adressierung Direktadressierung (Direct Adressing) Registeradressierung Indirekte Registeradressierung Indizierte Adressierung Basisindizierte Adressierung Stapeladressierung Unmittelbare Adressierung Der Adressteil der Instruktion enthält den Operanden selbst, anstatt eines Verweises. Solche Operanden werden als Direktoperanden (Immediate) bezeichnet Bsp: MOV R4, 5H (5H wird direkt in R4 gespeichert) Direktadressierung (Direct Adressing) Es wird eine volle Adresse des Operanden angegeben Deshalb nur für globale Variablen anwendbar, da Instruktion immer auf gleiche Speicehrzeile zugreift Registeradressierung Das gleiche Prinzip wie Direct Adressing, nur das Register anstelle von Speicherzellen verwendet werden In Registern sollten die am häufigsten verwendeten Variablen abgelegt werden, da Register vielfach schneller als Hauptspeicher sind Load/Store-Architekturen nutzen fast nur diesen Registermode (außer es muss vom oder zum Speicher transferiert werden) Indirekte Registeradressierung Die Adresse wird nicht direkt angegeben, sondern indirekt über ein Register Das Register enthält somit einen Pointer auf eine Speicherzelle Vorteil ist, daß auf Speicher referenziert werden kann, aber keine volle Speicheradresse notwendig wird Indizierte Adressierung Der Speicher wird durch Angabe eines Registers und eines konstanten Offsets adressiert Häufig benutzt bei Arrayzugriffen, wie A = B[i] (MOV R1, B[R2]) Basisindizierte Adressierung Speicheradresse wird hier durch Addition zweier Register und einen optionalen Offset berechnet Eines der Register stellt die Basis dar und ein anderes den Index Stapeladressierung Hier ist gar keine Adressangabe notwendig Somit sind die Instruktionen sehr kurz Die Stapeladressierung arbeitet mit der umgekehrten polnischen Notation (Postfix) Kapitel 3 - Speicherschutz und Multitasking Um unberechtigte Zugriffe, Datenaufrufe oder Systemprozedurecalls zu vermeiden und Task-Isolation zu gewährleisten, ist ein ausgeklügeltes Sp
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itEin TSS Enthält alle Informationen, die einen Task ausmachen: verwendete Prozessor-Register LDT-Selektor (einer Pro Task) welche die Segment-Deskriptoren des Prozesses enthält Stack-Segment-Pointer Verwaltungsinformation Adresse der Paging-Tabellen I/O-Map Base Adresse Busy-Bit, definiert den aktuell rechn
Original toplevel document
Grundprinzipien der Rechnerarchitekturauf. Ein DMA-Controller wirkt wie ein weiterer Prozessor am Bus. Um Inkonsistenzen im Speicher zu vermeiden, muss ein DMA-Controller eng mit dem Speichermanagment des Systems zusammenarbeiten. <span>Was ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adressraum verschiedenen I/O-Devices zuzuordnen oder Getrennten I/O Adressraum, bei dem auf einer speziellen Adressleitung die E/A-Adresse auf den Bus gelegt wird. (veraltete Variante) Was ist eine Task? Ein Task ist ein eigenständiges Programm / Prozess von vielen im Multitasksystem. Es wird von einem TSS (Task State Segment) beschrieben. Bei einem Taskwechsel werden alle Informationen in diesem TSS gespeichert. Jeder TSS-Deskriptor steht in der GDT. Die GDT hat beim i486 8192 Einträge, jedoch ist der 0. Eintrag immer leer. Somit sind maximal 8191 verschiedene Prozesse möglich (inclusive des Betriebssystems). Wie werden Task-Wechsel realisiert? Ein Taskwechsel geschieht durch Auswahl eines Task-Gates aus Globaler Deskriptor Tabelle (Task State Segment = TSS). Ein TSS Enthält alle Informationen, die einen Task ausmachen: verwendete Prozessor-Register LDT-Selektor (einer Pro Task) welche die Segment-Deskriptoren des Prozesses enthält Stack-Segment-Pointer Verwaltungsinformation Adresse der Paging-Tabellen I/O-Map Base Adresse Busy-Bit, definiert den aktuell rechnenden Task (genau einer im System) TR (Task Register) enthält den aktuellen TSS (Selektor des Descriptors des aktuellen TSS) TSS-Descriptoren nur in GDT! Bsp: Scheduler als Task ( Umschalter ) Umschalten durch jeweiligen Austausch des Back-Link, IRETD zum anderen Task, z.B. Timer-Interrupt-Task. Welche Möglichkeiten für Privilegwechsel gibt es? CALL in eine Prozedur mit anderen Privilegde-Level (CALL-Gate) JMP in eine Prozedur mit anderen Privi legde-Level (TASK-Gate) INT (TRAP-Gate) TASK-Gate durch erzwungenen Prozeßwechsel IRET Rücksprung aus INT-Handler Was ist der Unterschied zwischen einem Selektor und einem Deskriptor? Ein Selektor Segment-Register wählt einen Deskriptor in (GLI)DT aus, ein Deskriptor Eintrag in (GLI)DT, beschreibt das Segment. Weshalb ist es sinnvoll, dass ein TSS-Descriptor nur in der GDT stehen darf? Es soll verhindert werden, daß ein USER-Programm in einen anderen Task springt. Da Taskwechsel nur über TASK-Gates erfolgen (dieses zeigt auf einen TSS-Deskriptor) muß der CurrentPrivilegdeLevel (CPL vom CS:) numerisch kleiner sein, als das des geforderten TSS-Deskriptor (DPL) bzw. kleiner als der (RPL) des Segments wo sich der TSS-Deskriptor aufhält. Damit wird sichergestellt, daß der Taskwechsel nur von "höherem" Code (OS) aus ausgeführt werden kann. Würde ein TSS-Deskriptor in der LDT stehen, könnte es dort mit einem höheren RPL versehen werden, und der USER-Code könnte sich zum OS-CODE etablieren! Welche Grundtypen von Deskriptoren gibt es? IDT LDT GDT CODE-Segment DATA-Segment STACK-Segment CODE-Segment DATA-Segment STACK-Segment INT-Gate TRAP-Gate TASK-Gate TASK-Gate TASK-Gate CALL-Gate Welche grundlegenden Adressierungsarten gibt es? Unmittelbare Adressierung Direktadressierung (Direct Adressing) Registeradressierung Indirekte Registeradressierung Indizierte Adressierung Basisindizierte Adressierung Stapeladressierung Unmittelbare Adressierung Der Adressteil der Instruktion enthält den Operanden selbst, anstatt eines Verweises. Solche Operanden werden als Direktoperanden (Immediate) bezeichnet Bsp: MOV R4, 5H (5H wird direkt in R4 gespeichert) Direktadressierung (Direct Adressing) Es wird eine volle Adresse des Operanden angegeben Deshalb nur für globale Variablen anwendbar, da Instruktion immer auf gleiche Speicehrzeile zugreift Registeradressierung Das gleiche Prinzip wie Direct Adressing, nur das Register anstelle von Speicherzellen verwendet werden In Registern sollten die am häufigsten verwendeten Variablen abgelegt werden, da Register vielfach schneller als Hauptspeicher sind Load/Store-Architekturen nutzen fast nur diesen Registermode (außer es muss vom oder zum Speicher transferiert werden) Indirekte Registeradressierung Die Adresse wird nicht direkt angegeben, sondern indirekt über ein Register Das Register enthält somit einen Pointer auf eine Speicherzelle Vorteil ist, daß auf Speicher referenziert werden kann, aber keine volle Speicheradresse notwendig wird Indizierte Adressierung Der Speicher wird durch Angabe eines Registers und eines konstanten Offsets adressiert Häufig benutzt bei Arrayzugriffen, wie A = B[i] (MOV R1, B[R2]) Basisindizierte Adressierung Speicheradresse wird hier durch Addition zweier Register und einen optionalen Offset berechnet Eines der Register stellt die Basis dar und ein anderes den Index Stapeladressierung Hier ist gar keine Adressangabe notwendig Somit sind die Instruktionen sehr kurz Die Stapeladressierung arbeitet mit der umgekehrten polnischen Notation (Postfix) Kapitel 3 - Speicherschutz und Multitasking Um unberechtigte Zugriffe, Datenaufrufe oder Systemprozedurecalls zu vermeiden und Task-Isolation zu gewährleisten, ist ein ausgeklügeltes Sp
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itEin TSS Enthält alle Informationen, die einen Task ausmachen: verwendete Prozessor-Register LDT-Selektor (einer Pro Task) welche die Segment-Deskriptoren des Prozesses enthält Stack-Segment-Pointer Verwaltungsinformation Adresse der Paging-Tabellen I/O-Map Base Adresse Busy-Bit, definiert den aktuell rechnenden Task (genau einer im System)
Original toplevel document
Grundprinzipien der Rechnerarchitekturauf. Ein DMA-Controller wirkt wie ein weiterer Prozessor am Bus. Um Inkonsistenzen im Speicher zu vermeiden, muss ein DMA-Controller eng mit dem Speichermanagment des Systems zusammenarbeiten. <span>Was ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adressraum verschiedenen I/O-Devices zuzuordnen oder Getrennten I/O Adressraum, bei dem auf einer speziellen Adressleitung die E/A-Adresse auf den Bus gelegt wird. (veraltete Variante) Was ist eine Task? Ein Task ist ein eigenständiges Programm / Prozess von vielen im Multitasksystem. Es wird von einem TSS (Task State Segment) beschrieben. Bei einem Taskwechsel werden alle Informationen in diesem TSS gespeichert. Jeder TSS-Deskriptor steht in der GDT. Die GDT hat beim i486 8192 Einträge, jedoch ist der 0. Eintrag immer leer. Somit sind maximal 8191 verschiedene Prozesse möglich (inclusive des Betriebssystems). Wie werden Task-Wechsel realisiert? Ein Taskwechsel geschieht durch Auswahl eines Task-Gates aus Globaler Deskriptor Tabelle (Task State Segment = TSS). Ein TSS Enthält alle Informationen, die einen Task ausmachen: verwendete Prozessor-Register LDT-Selektor (einer Pro Task) welche die Segment-Deskriptoren des Prozesses enthält Stack-Segment-Pointer Verwaltungsinformation Adresse der Paging-Tabellen I/O-Map Base Adresse Busy-Bit, definiert den aktuell rechnenden Task (genau einer im System) TR (Task Register) enthält den aktuellen TSS (Selektor des Descriptors des aktuellen TSS) TSS-Descriptoren nur in GDT! Bsp: Scheduler als Task ( Umschalter ) Umschalten durch jeweiligen Austausch des Back-Link, IRETD zum anderen Task, z.B. Timer-Interrupt-Task. Welche Möglichkeiten für Privilegwechsel gibt es? CALL in eine Prozedur mit anderen Privilegde-Level (CALL-Gate) JMP in eine Prozedur mit anderen Privi legde-Level (TASK-Gate) INT (TRAP-Gate) TASK-Gate durch erzwungenen Prozeßwechsel IRET Rücksprung aus INT-Handler Was ist der Unterschied zwischen einem Selektor und einem Deskriptor? Ein Selektor Segment-Register wählt einen Deskriptor in (GLI)DT aus, ein Deskriptor Eintrag in (GLI)DT, beschreibt das Segment. Weshalb ist es sinnvoll, dass ein TSS-Descriptor nur in der GDT stehen darf? Es soll verhindert werden, daß ein USER-Programm in einen anderen Task springt. Da Taskwechsel nur über TASK-Gates erfolgen (dieses zeigt auf einen TSS-Deskriptor) muß der CurrentPrivilegdeLevel (CPL vom CS:) numerisch kleiner sein, als das des geforderten TSS-Deskriptor (DPL) bzw. kleiner als der (RPL) des Segments wo sich der TSS-Deskriptor aufhält. Damit wird sichergestellt, daß der Taskwechsel nur von "höherem" Code (OS) aus ausgeführt werden kann. Würde ein TSS-Deskriptor in der LDT stehen, könnte es dort mit einem höheren RPL versehen werden, und der USER-Code könnte sich zum OS-CODE etablieren! Welche Grundtypen von Deskriptoren gibt es? IDT LDT GDT CODE-Segment DATA-Segment STACK-Segment CODE-Segment DATA-Segment STACK-Segment INT-Gate TRAP-Gate TASK-Gate TASK-Gate TASK-Gate CALL-Gate Welche grundlegenden Adressierungsarten gibt es? Unmittelbare Adressierung Direktadressierung (Direct Adressing) Registeradressierung Indirekte Registeradressierung Indizierte Adressierung Basisindizierte Adressierung Stapeladressierung Unmittelbare Adressierung Der Adressteil der Instruktion enthält den Operanden selbst, anstatt eines Verweises. Solche Operanden werden als Direktoperanden (Immediate) bezeichnet Bsp: MOV R4, 5H (5H wird direkt in R4 gespeichert) Direktadressierung (Direct Adressing) Es wird eine volle Adresse des Operanden angegeben Deshalb nur für globale Variablen anwendbar, da Instruktion immer auf gleiche Speicehrzeile zugreift Registeradressierung Das gleiche Prinzip wie Direct Adressing, nur das Register anstelle von Speicherzellen verwendet werden In Registern sollten die am häufigsten verwendeten Variablen abgelegt werden, da Register vielfach schneller als Hauptspeicher sind Load/Store-Architekturen nutzen fast nur diesen Registermode (außer es muss vom oder zum Speicher transferiert werden) Indirekte Registeradressierung Die Adresse wird nicht direkt angegeben, sondern indirekt über ein Register Das Register enthält somit einen Pointer auf eine Speicherzelle Vorteil ist, daß auf Speicher referenziert werden kann, aber keine volle Speicheradresse notwendig wird Indizierte Adressierung Der Speicher wird durch Angabe eines Registers und eines konstanten Offsets adressiert Häufig benutzt bei Arrayzugriffen, wie A = B[i] (MOV R1, B[R2]) Basisindizierte Adressierung Speicheradresse wird hier durch Addition zweier Register und einen optionalen Offset berechnet Eines der Register stellt die Basis dar und ein anderes den Index Stapeladressierung Hier ist gar keine Adressangabe notwendig Somit sind die Instruktionen sehr kurz Die Stapeladressierung arbeitet mit der umgekehrten polnischen Notation (Postfix) Kapitel 3 - Speicherschutz und Multitasking Um unberechtigte Zugriffe, Datenaufrufe oder Systemprozedurecalls zu vermeiden und Task-Isolation zu gewährleisten, ist ein ausgeklügeltes Sp
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itzessor-Register LDT-Selektor (einer Pro Task) welche die Segment-Deskriptoren des Prozesses enthält Stack-Segment-Pointer Verwaltungsinformation Adresse der Paging-Tabellen I/O-Map Base Adresse <span>Busy-Bit, definiert den aktuell rechnenden Task (genau einer im System) <span>
Original toplevel document
Grundprinzipien der Rechnerarchitekturauf. Ein DMA-Controller wirkt wie ein weiterer Prozessor am Bus. Um Inkonsistenzen im Speicher zu vermeiden, muss ein DMA-Controller eng mit dem Speichermanagment des Systems zusammenarbeiten. <span>Was ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adressraum verschiedenen I/O-Devices zuzuordnen oder Getrennten I/O Adressraum, bei dem auf einer speziellen Adressleitung die E/A-Adresse auf den Bus gelegt wird. (veraltete Variante) Was ist eine Task? Ein Task ist ein eigenständiges Programm / Prozess von vielen im Multitasksystem. Es wird von einem TSS (Task State Segment) beschrieben. Bei einem Taskwechsel werden alle Informationen in diesem TSS gespeichert. Jeder TSS-Deskriptor steht in der GDT. Die GDT hat beim i486 8192 Einträge, jedoch ist der 0. Eintrag immer leer. Somit sind maximal 8191 verschiedene Prozesse möglich (inclusive des Betriebssystems). Wie werden Task-Wechsel realisiert? Ein Taskwechsel geschieht durch Auswahl eines Task-Gates aus Globaler Deskriptor Tabelle (Task State Segment = TSS). Ein TSS Enthält alle Informationen, die einen Task ausmachen: verwendete Prozessor-Register LDT-Selektor (einer Pro Task) welche die Segment-Deskriptoren des Prozesses enthält Stack-Segment-Pointer Verwaltungsinformation Adresse der Paging-Tabellen I/O-Map Base Adresse Busy-Bit, definiert den aktuell rechnenden Task (genau einer im System) TR (Task Register) enthält den aktuellen TSS (Selektor des Descriptors des aktuellen TSS) TSS-Descriptoren nur in GDT! Bsp: Scheduler als Task ( Umschalter ) Umschalten durch jeweiligen Austausch des Back-Link, IRETD zum anderen Task, z.B. Timer-Interrupt-Task. Welche Möglichkeiten für Privilegwechsel gibt es? CALL in eine Prozedur mit anderen Privilegde-Level (CALL-Gate) JMP in eine Prozedur mit anderen Privi legde-Level (TASK-Gate) INT (TRAP-Gate) TASK-Gate durch erzwungenen Prozeßwechsel IRET Rücksprung aus INT-Handler Was ist der Unterschied zwischen einem Selektor und einem Deskriptor? Ein Selektor Segment-Register wählt einen Deskriptor in (GLI)DT aus, ein Deskriptor Eintrag in (GLI)DT, beschreibt das Segment. Weshalb ist es sinnvoll, dass ein TSS-Descriptor nur in der GDT stehen darf? Es soll verhindert werden, daß ein USER-Programm in einen anderen Task springt. Da Taskwechsel nur über TASK-Gates erfolgen (dieses zeigt auf einen TSS-Deskriptor) muß der CurrentPrivilegdeLevel (CPL vom CS:) numerisch kleiner sein, als das des geforderten TSS-Deskriptor (DPL) bzw. kleiner als der (RPL) des Segments wo sich der TSS-Deskriptor aufhält. Damit wird sichergestellt, daß der Taskwechsel nur von "höherem" Code (OS) aus ausgeführt werden kann. Würde ein TSS-Deskriptor in der LDT stehen, könnte es dort mit einem höheren RPL versehen werden, und der USER-Code könnte sich zum OS-CODE etablieren! Welche Grundtypen von Deskriptoren gibt es? IDT LDT GDT CODE-Segment DATA-Segment STACK-Segment CODE-Segment DATA-Segment STACK-Segment INT-Gate TRAP-Gate TASK-Gate TASK-Gate TASK-Gate CALL-Gate Welche grundlegenden Adressierungsarten gibt es? Unmittelbare Adressierung Direktadressierung (Direct Adressing) Registeradressierung Indirekte Registeradressierung Indizierte Adressierung Basisindizierte Adressierung Stapeladressierung Unmittelbare Adressierung Der Adressteil der Instruktion enthält den Operanden selbst, anstatt eines Verweises. Solche Operanden werden als Direktoperanden (Immediate) bezeichnet Bsp: MOV R4, 5H (5H wird direkt in R4 gespeichert) Direktadressierung (Direct Adressing) Es wird eine volle Adresse des Operanden angegeben Deshalb nur für globale Variablen anwendbar, da Instruktion immer auf gleiche Speicehrzeile zugreift Registeradressierung Das gleiche Prinzip wie Direct Adressing, nur das Register anstelle von Speicherzellen verwendet werden In Registern sollten die am häufigsten verwendeten Variablen abgelegt werden, da Register vielfach schneller als Hauptspeicher sind Load/Store-Architekturen nutzen fast nur diesen Registermode (außer es muss vom oder zum Speicher transferiert werden) Indirekte Registeradressierung Die Adresse wird nicht direkt angegeben, sondern indirekt über ein Register Das Register enthält somit einen Pointer auf eine Speicherzelle Vorteil ist, daß auf Speicher referenziert werden kann, aber keine volle Speicheradresse notwendig wird Indizierte Adressierung Der Speicher wird durch Angabe eines Registers und eines konstanten Offsets adressiert Häufig benutzt bei Arrayzugriffen, wie A = B[i] (MOV R1, B[R2]) Basisindizierte Adressierung Speicheradresse wird hier durch Addition zweier Register und einen optionalen Offset berechnet Eines der Register stellt die Basis dar und ein anderes den Index Stapeladressierung Hier ist gar keine Adressangabe notwendig Somit sind die Instruktionen sehr kurz Die Stapeladressierung arbeitet mit der umgekehrten polnischen Notation (Postfix) Kapitel 3 - Speicherschutz und Multitasking Um unberechtigte Zugriffe, Datenaufrufe oder Systemprozedurecalls zu vermeiden und Task-Isolation zu gewährleisten, ist ein ausgeklügeltes Sp
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |