Edited, memorised or added to reading queue
on 18-Jun-2024 (Tue)
Do you want BuboFlash to help you learning these things? Click here to log in or create user.
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itWas ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adressraum verschiedenen I/O-Devices zuzuordnen oder Getrennten I/O Adressraum, bei dem auf einer speziellen Adressleitung die E/A-Adresse auf den Bus gelegt wird. (veraltete Variante) Was ist eine Task? Ein Task ist ein eigenständiges Programm / Prozess von vielen im Multitasksystem. Es wird von einem TSS (Task State Segment) beschrieben. Bei einem Taskwechsel werden
Original toplevel document
Grundprinzipien der Rechnerarchitekturauf. Ein DMA-Controller wirkt wie ein weiterer Prozessor am Bus. Um Inkonsistenzen im Speicher zu vermeiden, muss ein DMA-Controller eng mit dem Speichermanagment des Systems zusammenarbeiten. <span>Was ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adressraum verschiedenen I/O-Devices zuzuordnen oder Getrennten I/O Adressraum, bei dem auf einer speziellen Adressleitung die E/A-Adresse auf den Bus gelegt wird. (veraltete Variante) Was ist eine Task? Ein Task ist ein eigenständiges Programm / Prozess von vielen im Multitasksystem. Es wird von einem TSS (Task State Segment) beschrieben. Bei einem Taskwechsel werden alle Informationen in diesem TSS gespeichert. Jeder TSS-Deskriptor steht in der GDT. Die GDT hat beim i486 8192 Einträge, jedoch ist der 0. Eintrag immer leer. Somit sind maximal 8191 verschiedene Prozesse möglich (inclusive des Betriebssystems). Wie werden Task-Wechsel realisiert? Ein Taskwechsel geschieht durch Auswahl eines Task-Gates aus Globaler Deskriptor Tabelle (Task State Segment = TSS). Ein TSS Enthält alle Informationen, die einen Task ausmachen: verwendete Prozessor-Register LDT-Selektor (einer Pro Task) welche die Segment-Deskriptoren des Prozesses enthält Stack-Segment-Pointer Verwaltungsinformation Adresse der Paging-Tabellen I/O-Map Base Adresse Busy-Bit, definiert den aktuell rechnenden Task (genau einer im System) TR (Task Register) enthält den aktuellen TSS (Selektor des Descriptors des aktuellen TSS) TSS-Descriptoren nur in GDT! Bsp: Scheduler als Task ( Umschalter ) Umschalten durch jeweiligen Austausch des Back-Link, IRETD zum anderen Task, z.B. Timer-Interrupt-Task. Welche Möglichkeiten für Privilegwechsel gibt es? CALL in eine Prozedur mit anderen Privilegde-Level (CALL-Gate) JMP in eine Prozedur mit anderen Privi legde-Level (TASK-Gate) INT (TRAP-Gate) TASK-Gate durch erzwungenen Prozeßwechsel IRET Rücksprung aus INT-Handler Was ist der Unterschied zwischen einem Selektor und einem Deskriptor? Ein Selektor Segment-Register wählt einen Deskriptor in (GLI)DT aus, ein Deskriptor Eintrag in (GLI)DT, beschreibt das Segment. Weshalb ist es sinnvoll, dass ein TSS-Descriptor nur in der GDT stehen darf? Es soll verhindert werden, daß ein USER-Programm in einen anderen Task springt. Da Taskwechsel nur über TASK-Gates erfolgen (dieses zeigt auf einen TSS-Deskriptor) muß der CurrentPrivilegdeLevel (CPL vom CS:) numerisch kleiner sein, als das des geforderten TSS-Deskriptor (DPL) bzw. kleiner als der (RPL) des Segments wo sich der TSS-Deskriptor aufhält. Damit wird sichergestellt, daß der Taskwechsel nur von "höherem" Code (OS) aus ausgeführt werden kann. Würde ein TSS-Deskriptor in der LDT stehen, könnte es dort mit einem höheren RPL versehen werden, und der USER-Code könnte sich zum OS-CODE etablieren! Welche Grundtypen von Deskriptoren gibt es? IDT LDT GDT CODE-Segment DATA-Segment STACK-Segment CODE-Segment DATA-Segment STACK-Segment INT-Gate TRAP-Gate TASK-Gate TASK-Gate TASK-Gate CALL-Gate Welche grundlegenden Adressierungsarten gibt es? Unmittelbare Adressierung Direktadressierung (Direct Adressing) Registeradressierung Indirekte Registeradressierung Indizierte Adressierung Basisindizierte Adressierung Stapeladressierung Unmittelbare Adressierung Der Adressteil der Instruktion enthält den Operanden selbst, anstatt eines Verweises. Solche Operanden werden als Direktoperanden (Immediate) bezeichnet Bsp: MOV R4, 5H (5H wird direkt in R4 gespeichert) Direktadressierung (Direct Adressing) Es wird eine volle Adresse des Operanden angegeben Deshalb nur für globale Variablen anwendbar, da Instruktion immer auf gleiche Speicehrzeile zugreift Registeradressierung Das gleiche Prinzip wie Direct Adressing, nur das Register anstelle von Speicherzellen verwendet werden In Registern sollten die am häufigsten verwendeten Variablen abgelegt werden, da Register vielfach schneller als Hauptspeicher sind Load/Store-Architekturen nutzen fast nur diesen Registermode (außer es muss vom oder zum Speicher transferiert werden) Indirekte Registeradressierung Die Adresse wird nicht direkt angegeben, sondern indirekt über ein Register Das Register enthält somit einen Pointer auf eine Speicherzelle Vorteil ist, daß auf Speicher referenziert werden kann, aber keine volle Speicheradresse notwendig wird Indizierte Adressierung Der Speicher wird durch Angabe eines Registers und eines konstanten Offsets adressiert Häufig benutzt bei Arrayzugriffen, wie A = B[i] (MOV R1, B[R2]) Basisindizierte Adressierung Speicheradresse wird hier durch Addition zweier Register und einen optionalen Offset berechnet Eines der Register stellt die Basis dar und ein anderes den Index Stapeladressierung Hier ist gar keine Adressangabe notwendig Somit sind die Instruktionen sehr kurz Die Stapeladressierung arbeitet mit der umgekehrten polnischen Notation (Postfix) Kapitel 3 - Speicherschutz und Multitasking Um unberechtigte Zugriffe, Datenaufrufe oder Systemprozedurecalls zu vermeiden und Task-Isolation zu gewährleisten, ist ein ausgeklügeltes Sp
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itionellen Adressraum verschiedenen I/O-Devices zuzuordnen oder Getrennten I/O Adressraum, bei dem auf einer speziellen Adressleitung die E/A-Adresse auf den Bus gelegt wird. (veraltete Variante) <span>Was ist eine Task? Ein Task ist ein eigenständiges Programm / Prozess von vielen im Multitasksystem. Es wird von einem TSS (Task State Segment) beschrieben. Bei einem Taskwechsel werden alle Informationen in diesem TSS gespeichert. Jeder TSS-Deskriptor steht in der GDT. Die GDT hat beim i486 8192 Einträge, jedoch ist der 0. Eintrag immer leer. Somit sind maximal 8191 verschiedene Prozesse möglich (inclusive des Betriebssystems). Wie werden Task-Wechsel realisiert? Ein Taskwechsel geschieht durch Auswahl eines Task-Gates aus Globaler Deskriptor Tabelle (Task State Segment = TSS). Ein TSS Enthält alle Information
Original toplevel document
Grundprinzipien der Rechnerarchitekturauf. Ein DMA-Controller wirkt wie ein weiterer Prozessor am Bus. Um Inkonsistenzen im Speicher zu vermeiden, muss ein DMA-Controller eng mit dem Speichermanagment des Systems zusammenarbeiten. <span>Was ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adressraum verschiedenen I/O-Devices zuzuordnen oder Getrennten I/O Adressraum, bei dem auf einer speziellen Adressleitung die E/A-Adresse auf den Bus gelegt wird. (veraltete Variante) Was ist eine Task? Ein Task ist ein eigenständiges Programm / Prozess von vielen im Multitasksystem. Es wird von einem TSS (Task State Segment) beschrieben. Bei einem Taskwechsel werden alle Informationen in diesem TSS gespeichert. Jeder TSS-Deskriptor steht in der GDT. Die GDT hat beim i486 8192 Einträge, jedoch ist der 0. Eintrag immer leer. Somit sind maximal 8191 verschiedene Prozesse möglich (inclusive des Betriebssystems). Wie werden Task-Wechsel realisiert? Ein Taskwechsel geschieht durch Auswahl eines Task-Gates aus Globaler Deskriptor Tabelle (Task State Segment = TSS). Ein TSS Enthält alle Informationen, die einen Task ausmachen: verwendete Prozessor-Register LDT-Selektor (einer Pro Task) welche die Segment-Deskriptoren des Prozesses enthält Stack-Segment-Pointer Verwaltungsinformation Adresse der Paging-Tabellen I/O-Map Base Adresse Busy-Bit, definiert den aktuell rechnenden Task (genau einer im System) TR (Task Register) enthält den aktuellen TSS (Selektor des Descriptors des aktuellen TSS) TSS-Descriptoren nur in GDT! Bsp: Scheduler als Task ( Umschalter ) Umschalten durch jeweiligen Austausch des Back-Link, IRETD zum anderen Task, z.B. Timer-Interrupt-Task. Welche Möglichkeiten für Privilegwechsel gibt es? CALL in eine Prozedur mit anderen Privilegde-Level (CALL-Gate) JMP in eine Prozedur mit anderen Privi legde-Level (TASK-Gate) INT (TRAP-Gate) TASK-Gate durch erzwungenen Prozeßwechsel IRET Rücksprung aus INT-Handler Was ist der Unterschied zwischen einem Selektor und einem Deskriptor? Ein Selektor Segment-Register wählt einen Deskriptor in (GLI)DT aus, ein Deskriptor Eintrag in (GLI)DT, beschreibt das Segment. Weshalb ist es sinnvoll, dass ein TSS-Descriptor nur in der GDT stehen darf? Es soll verhindert werden, daß ein USER-Programm in einen anderen Task springt. Da Taskwechsel nur über TASK-Gates erfolgen (dieses zeigt auf einen TSS-Deskriptor) muß der CurrentPrivilegdeLevel (CPL vom CS:) numerisch kleiner sein, als das des geforderten TSS-Deskriptor (DPL) bzw. kleiner als der (RPL) des Segments wo sich der TSS-Deskriptor aufhält. Damit wird sichergestellt, daß der Taskwechsel nur von "höherem" Code (OS) aus ausgeführt werden kann. Würde ein TSS-Deskriptor in der LDT stehen, könnte es dort mit einem höheren RPL versehen werden, und der USER-Code könnte sich zum OS-CODE etablieren! Welche Grundtypen von Deskriptoren gibt es? IDT LDT GDT CODE-Segment DATA-Segment STACK-Segment CODE-Segment DATA-Segment STACK-Segment INT-Gate TRAP-Gate TASK-Gate TASK-Gate TASK-Gate CALL-Gate Welche grundlegenden Adressierungsarten gibt es? Unmittelbare Adressierung Direktadressierung (Direct Adressing) Registeradressierung Indirekte Registeradressierung Indizierte Adressierung Basisindizierte Adressierung Stapeladressierung Unmittelbare Adressierung Der Adressteil der Instruktion enthält den Operanden selbst, anstatt eines Verweises. Solche Operanden werden als Direktoperanden (Immediate) bezeichnet Bsp: MOV R4, 5H (5H wird direkt in R4 gespeichert) Direktadressierung (Direct Adressing) Es wird eine volle Adresse des Operanden angegeben Deshalb nur für globale Variablen anwendbar, da Instruktion immer auf gleiche Speicehrzeile zugreift Registeradressierung Das gleiche Prinzip wie Direct Adressing, nur das Register anstelle von Speicherzellen verwendet werden In Registern sollten die am häufigsten verwendeten Variablen abgelegt werden, da Register vielfach schneller als Hauptspeicher sind Load/Store-Architekturen nutzen fast nur diesen Registermode (außer es muss vom oder zum Speicher transferiert werden) Indirekte Registeradressierung Die Adresse wird nicht direkt angegeben, sondern indirekt über ein Register Das Register enthält somit einen Pointer auf eine Speicherzelle Vorteil ist, daß auf Speicher referenziert werden kann, aber keine volle Speicheradresse notwendig wird Indizierte Adressierung Der Speicher wird durch Angabe eines Registers und eines konstanten Offsets adressiert Häufig benutzt bei Arrayzugriffen, wie A = B[i] (MOV R1, B[R2]) Basisindizierte Adressierung Speicheradresse wird hier durch Addition zweier Register und einen optionalen Offset berechnet Eines der Register stellt die Basis dar und ein anderes den Index Stapeladressierung Hier ist gar keine Adressangabe notwendig Somit sind die Instruktionen sehr kurz Die Stapeladressierung arbeitet mit der umgekehrten polnischen Notation (Postfix) Kapitel 3 - Speicherschutz und Multitasking Um unberechtigte Zugriffe, Datenaufrufe oder Systemprozedurecalls zu vermeiden und Task-Isolation zu gewährleisten, ist ein ausgeklügeltes Sp
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itSS-Deskriptor steht in der GDT. Die GDT hat beim i486 8192 Einträge, jedoch ist der 0. Eintrag immer leer. Somit sind maximal 8191 verschiedene Prozesse möglich (inclusive des Betriebssystems). <span>Wie werden Task-Wechsel realisiert? Ein Taskwechsel geschieht durch Auswahl eines Task-Gates aus Globaler Deskriptor Tabelle (Task State Segment = TSS). Ein TSS Enthält alle Informationen, die einen Task ausmachen: verwendete Prozessor-Register LDT-Selektor (einer Pro Task) welche die Segment-Deskriptoren des Prozesses enthält Stack-Segment-Pointer Verwaltungsinformation Adresse der Paging-Tabellen I/O-Map Base Adresse Busy-Bit, definiert den aktuell rechnenden Task (genau einer im System) TR (Task Register) enthält den aktuellen TSS (Selektor des Descriptors des aktuellen TSS) TSS-Descriptoren nur in GDT! Bsp: Scheduler als Task ( Umschalter ) Umschalten durch jeweiligen Austausch des Back-Link, IRETD zum anderen Task, z.B. Timer-Interrupt-Task. Welche Möglichkeiten für Privilegwechsel gibt es? CALL in eine Prozedur mit anderen Privilegde-Level (CALL-Gate) JMP in eine Prozedur mit anderen Privi legde-Level (TASK-Gate) INT (TRAP
Original toplevel document
Grundprinzipien der Rechnerarchitekturauf. Ein DMA-Controller wirkt wie ein weiterer Prozessor am Bus. Um Inkonsistenzen im Speicher zu vermeiden, muss ein DMA-Controller eng mit dem Speichermanagment des Systems zusammenarbeiten. <span>Was ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adressraum verschiedenen I/O-Devices zuzuordnen oder Getrennten I/O Adressraum, bei dem auf einer speziellen Adressleitung die E/A-Adresse auf den Bus gelegt wird. (veraltete Variante) Was ist eine Task? Ein Task ist ein eigenständiges Programm / Prozess von vielen im Multitasksystem. Es wird von einem TSS (Task State Segment) beschrieben. Bei einem Taskwechsel werden alle Informationen in diesem TSS gespeichert. Jeder TSS-Deskriptor steht in der GDT. Die GDT hat beim i486 8192 Einträge, jedoch ist der 0. Eintrag immer leer. Somit sind maximal 8191 verschiedene Prozesse möglich (inclusive des Betriebssystems). Wie werden Task-Wechsel realisiert? Ein Taskwechsel geschieht durch Auswahl eines Task-Gates aus Globaler Deskriptor Tabelle (Task State Segment = TSS). Ein TSS Enthält alle Informationen, die einen Task ausmachen: verwendete Prozessor-Register LDT-Selektor (einer Pro Task) welche die Segment-Deskriptoren des Prozesses enthält Stack-Segment-Pointer Verwaltungsinformation Adresse der Paging-Tabellen I/O-Map Base Adresse Busy-Bit, definiert den aktuell rechnenden Task (genau einer im System) TR (Task Register) enthält den aktuellen TSS (Selektor des Descriptors des aktuellen TSS) TSS-Descriptoren nur in GDT! Bsp: Scheduler als Task ( Umschalter ) Umschalten durch jeweiligen Austausch des Back-Link, IRETD zum anderen Task, z.B. Timer-Interrupt-Task. Welche Möglichkeiten für Privilegwechsel gibt es? CALL in eine Prozedur mit anderen Privilegde-Level (CALL-Gate) JMP in eine Prozedur mit anderen Privi legde-Level (TASK-Gate) INT (TRAP-Gate) TASK-Gate durch erzwungenen Prozeßwechsel IRET Rücksprung aus INT-Handler Was ist der Unterschied zwischen einem Selektor und einem Deskriptor? Ein Selektor Segment-Register wählt einen Deskriptor in (GLI)DT aus, ein Deskriptor Eintrag in (GLI)DT, beschreibt das Segment. Weshalb ist es sinnvoll, dass ein TSS-Descriptor nur in der GDT stehen darf? Es soll verhindert werden, daß ein USER-Programm in einen anderen Task springt. Da Taskwechsel nur über TASK-Gates erfolgen (dieses zeigt auf einen TSS-Deskriptor) muß der CurrentPrivilegdeLevel (CPL vom CS:) numerisch kleiner sein, als das des geforderten TSS-Deskriptor (DPL) bzw. kleiner als der (RPL) des Segments wo sich der TSS-Deskriptor aufhält. Damit wird sichergestellt, daß der Taskwechsel nur von "höherem" Code (OS) aus ausgeführt werden kann. Würde ein TSS-Deskriptor in der LDT stehen, könnte es dort mit einem höheren RPL versehen werden, und der USER-Code könnte sich zum OS-CODE etablieren! Welche Grundtypen von Deskriptoren gibt es? IDT LDT GDT CODE-Segment DATA-Segment STACK-Segment CODE-Segment DATA-Segment STACK-Segment INT-Gate TRAP-Gate TASK-Gate TASK-Gate TASK-Gate CALL-Gate Welche grundlegenden Adressierungsarten gibt es? Unmittelbare Adressierung Direktadressierung (Direct Adressing) Registeradressierung Indirekte Registeradressierung Indizierte Adressierung Basisindizierte Adressierung Stapeladressierung Unmittelbare Adressierung Der Adressteil der Instruktion enthält den Operanden selbst, anstatt eines Verweises. Solche Operanden werden als Direktoperanden (Immediate) bezeichnet Bsp: MOV R4, 5H (5H wird direkt in R4 gespeichert) Direktadressierung (Direct Adressing) Es wird eine volle Adresse des Operanden angegeben Deshalb nur für globale Variablen anwendbar, da Instruktion immer auf gleiche Speicehrzeile zugreift Registeradressierung Das gleiche Prinzip wie Direct Adressing, nur das Register anstelle von Speicherzellen verwendet werden In Registern sollten die am häufigsten verwendeten Variablen abgelegt werden, da Register vielfach schneller als Hauptspeicher sind Load/Store-Architekturen nutzen fast nur diesen Registermode (außer es muss vom oder zum Speicher transferiert werden) Indirekte Registeradressierung Die Adresse wird nicht direkt angegeben, sondern indirekt über ein Register Das Register enthält somit einen Pointer auf eine Speicherzelle Vorteil ist, daß auf Speicher referenziert werden kann, aber keine volle Speicheradresse notwendig wird Indizierte Adressierung Der Speicher wird durch Angabe eines Registers und eines konstanten Offsets adressiert Häufig benutzt bei Arrayzugriffen, wie A = B[i] (MOV R1, B[R2]) Basisindizierte Adressierung Speicheradresse wird hier durch Addition zweier Register und einen optionalen Offset berechnet Eines der Register stellt die Basis dar und ein anderes den Index Stapeladressierung Hier ist gar keine Adressangabe notwendig Somit sind die Instruktionen sehr kurz Die Stapeladressierung arbeitet mit der umgekehrten polnischen Notation (Postfix) Kapitel 3 - Speicherschutz und Multitasking Um unberechtigte Zugriffe, Datenaufrufe oder Systemprozedurecalls zu vermeiden und Task-Isolation zu gewährleisten, ist ein ausgeklügeltes Sp
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itrs des aktuellen TSS) TSS-Descriptoren nur in GDT! Bsp: Scheduler als Task ( Umschalter ) Umschalten durch jeweiligen Austausch des Back-Link, IRETD zum anderen Task, z.B. Timer-Interrupt-Task. <span>Welche Möglichkeiten für Privilegwechsel gibt es? CALL in eine Prozedur mit anderen Privilegde-Level (CALL-Gate) JMP in eine Prozedur mit anderen Privi legde-Level (TASK-Gate) INT (TRAP-Gate) TASK-Gate durch erzwungenen Prozeßwechsel IRET Rücksprung aus INT-Handler Was ist der Unterschied zwischen einem Selektor und einem Deskriptor? Ein Selektor Segment-Register wählt einen Deskriptor in (GLI)DT aus, ein Deskriptor Eintrag in (GLI)DT, beschreibt
Original toplevel document
Grundprinzipien der Rechnerarchitekturauf. Ein DMA-Controller wirkt wie ein weiterer Prozessor am Bus. Um Inkonsistenzen im Speicher zu vermeiden, muss ein DMA-Controller eng mit dem Speichermanagment des Systems zusammenarbeiten. <span>Was ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adressraum verschiedenen I/O-Devices zuzuordnen oder Getrennten I/O Adressraum, bei dem auf einer speziellen Adressleitung die E/A-Adresse auf den Bus gelegt wird. (veraltete Variante) Was ist eine Task? Ein Task ist ein eigenständiges Programm / Prozess von vielen im Multitasksystem. Es wird von einem TSS (Task State Segment) beschrieben. Bei einem Taskwechsel werden alle Informationen in diesem TSS gespeichert. Jeder TSS-Deskriptor steht in der GDT. Die GDT hat beim i486 8192 Einträge, jedoch ist der 0. Eintrag immer leer. Somit sind maximal 8191 verschiedene Prozesse möglich (inclusive des Betriebssystems). Wie werden Task-Wechsel realisiert? Ein Taskwechsel geschieht durch Auswahl eines Task-Gates aus Globaler Deskriptor Tabelle (Task State Segment = TSS). Ein TSS Enthält alle Informationen, die einen Task ausmachen: verwendete Prozessor-Register LDT-Selektor (einer Pro Task) welche die Segment-Deskriptoren des Prozesses enthält Stack-Segment-Pointer Verwaltungsinformation Adresse der Paging-Tabellen I/O-Map Base Adresse Busy-Bit, definiert den aktuell rechnenden Task (genau einer im System) TR (Task Register) enthält den aktuellen TSS (Selektor des Descriptors des aktuellen TSS) TSS-Descriptoren nur in GDT! Bsp: Scheduler als Task ( Umschalter ) Umschalten durch jeweiligen Austausch des Back-Link, IRETD zum anderen Task, z.B. Timer-Interrupt-Task. Welche Möglichkeiten für Privilegwechsel gibt es? CALL in eine Prozedur mit anderen Privilegde-Level (CALL-Gate) JMP in eine Prozedur mit anderen Privi legde-Level (TASK-Gate) INT (TRAP-Gate) TASK-Gate durch erzwungenen Prozeßwechsel IRET Rücksprung aus INT-Handler Was ist der Unterschied zwischen einem Selektor und einem Deskriptor? Ein Selektor Segment-Register wählt einen Deskriptor in (GLI)DT aus, ein Deskriptor Eintrag in (GLI)DT, beschreibt das Segment. Weshalb ist es sinnvoll, dass ein TSS-Descriptor nur in der GDT stehen darf? Es soll verhindert werden, daß ein USER-Programm in einen anderen Task springt. Da Taskwechsel nur über TASK-Gates erfolgen (dieses zeigt auf einen TSS-Deskriptor) muß der CurrentPrivilegdeLevel (CPL vom CS:) numerisch kleiner sein, als das des geforderten TSS-Deskriptor (DPL) bzw. kleiner als der (RPL) des Segments wo sich der TSS-Deskriptor aufhält. Damit wird sichergestellt, daß der Taskwechsel nur von "höherem" Code (OS) aus ausgeführt werden kann. Würde ein TSS-Deskriptor in der LDT stehen, könnte es dort mit einem höheren RPL versehen werden, und der USER-Code könnte sich zum OS-CODE etablieren! Welche Grundtypen von Deskriptoren gibt es? IDT LDT GDT CODE-Segment DATA-Segment STACK-Segment CODE-Segment DATA-Segment STACK-Segment INT-Gate TRAP-Gate TASK-Gate TASK-Gate TASK-Gate CALL-Gate Welche grundlegenden Adressierungsarten gibt es? Unmittelbare Adressierung Direktadressierung (Direct Adressing) Registeradressierung Indirekte Registeradressierung Indizierte Adressierung Basisindizierte Adressierung Stapeladressierung Unmittelbare Adressierung Der Adressteil der Instruktion enthält den Operanden selbst, anstatt eines Verweises. Solche Operanden werden als Direktoperanden (Immediate) bezeichnet Bsp: MOV R4, 5H (5H wird direkt in R4 gespeichert) Direktadressierung (Direct Adressing) Es wird eine volle Adresse des Operanden angegeben Deshalb nur für globale Variablen anwendbar, da Instruktion immer auf gleiche Speicehrzeile zugreift Registeradressierung Das gleiche Prinzip wie Direct Adressing, nur das Register anstelle von Speicherzellen verwendet werden In Registern sollten die am häufigsten verwendeten Variablen abgelegt werden, da Register vielfach schneller als Hauptspeicher sind Load/Store-Architekturen nutzen fast nur diesen Registermode (außer es muss vom oder zum Speicher transferiert werden) Indirekte Registeradressierung Die Adresse wird nicht direkt angegeben, sondern indirekt über ein Register Das Register enthält somit einen Pointer auf eine Speicherzelle Vorteil ist, daß auf Speicher referenziert werden kann, aber keine volle Speicheradresse notwendig wird Indizierte Adressierung Der Speicher wird durch Angabe eines Registers und eines konstanten Offsets adressiert Häufig benutzt bei Arrayzugriffen, wie A = B[i] (MOV R1, B[R2]) Basisindizierte Adressierung Speicheradresse wird hier durch Addition zweier Register und einen optionalen Offset berechnet Eines der Register stellt die Basis dar und ein anderes den Index Stapeladressierung Hier ist gar keine Adressangabe notwendig Somit sind die Instruktionen sehr kurz Die Stapeladressierung arbeitet mit der umgekehrten polnischen Notation (Postfix) Kapitel 3 - Speicherschutz und Multitasking Um unberechtigte Zugriffe, Datenaufrufe oder Systemprozedurecalls zu vermeiden und Task-Isolation zu gewährleisten, ist ein ausgeklügeltes Sp
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itmit anderen Privilegde-Level (CALL-Gate) JMP in eine Prozedur mit anderen Privi legde-Level (TASK-Gate) INT (TRAP-Gate) TASK-Gate durch erzwungenen Prozeßwechsel IRET Rücksprung aus INT-Handler <span>Was ist der Unterschied zwischen einem Selektor und einem Deskriptor? Ein Selektor Segment-Register wählt einen Deskriptor in (GLI)DT aus, ein Deskriptor Eintrag in (GLI)DT, beschreibt das Segment. Weshalb ist es sinnvoll, dass ein TSS-Descriptor nur in der GDT stehen darf? Es soll verhindert werden, daß ein USER-Programm in einen anderen Task springt. Da Taskwechsel nur über TASK
Original toplevel document
Grundprinzipien der Rechnerarchitekturauf. Ein DMA-Controller wirkt wie ein weiterer Prozessor am Bus. Um Inkonsistenzen im Speicher zu vermeiden, muss ein DMA-Controller eng mit dem Speichermanagment des Systems zusammenarbeiten. <span>Was ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adressraum verschiedenen I/O-Devices zuzuordnen oder Getrennten I/O Adressraum, bei dem auf einer speziellen Adressleitung die E/A-Adresse auf den Bus gelegt wird. (veraltete Variante) Was ist eine Task? Ein Task ist ein eigenständiges Programm / Prozess von vielen im Multitasksystem. Es wird von einem TSS (Task State Segment) beschrieben. Bei einem Taskwechsel werden alle Informationen in diesem TSS gespeichert. Jeder TSS-Deskriptor steht in der GDT. Die GDT hat beim i486 8192 Einträge, jedoch ist der 0. Eintrag immer leer. Somit sind maximal 8191 verschiedene Prozesse möglich (inclusive des Betriebssystems). Wie werden Task-Wechsel realisiert? Ein Taskwechsel geschieht durch Auswahl eines Task-Gates aus Globaler Deskriptor Tabelle (Task State Segment = TSS). Ein TSS Enthält alle Informationen, die einen Task ausmachen: verwendete Prozessor-Register LDT-Selektor (einer Pro Task) welche die Segment-Deskriptoren des Prozesses enthält Stack-Segment-Pointer Verwaltungsinformation Adresse der Paging-Tabellen I/O-Map Base Adresse Busy-Bit, definiert den aktuell rechnenden Task (genau einer im System) TR (Task Register) enthält den aktuellen TSS (Selektor des Descriptors des aktuellen TSS) TSS-Descriptoren nur in GDT! Bsp: Scheduler als Task ( Umschalter ) Umschalten durch jeweiligen Austausch des Back-Link, IRETD zum anderen Task, z.B. Timer-Interrupt-Task. Welche Möglichkeiten für Privilegwechsel gibt es? CALL in eine Prozedur mit anderen Privilegde-Level (CALL-Gate) JMP in eine Prozedur mit anderen Privi legde-Level (TASK-Gate) INT (TRAP-Gate) TASK-Gate durch erzwungenen Prozeßwechsel IRET Rücksprung aus INT-Handler Was ist der Unterschied zwischen einem Selektor und einem Deskriptor? Ein Selektor Segment-Register wählt einen Deskriptor in (GLI)DT aus, ein Deskriptor Eintrag in (GLI)DT, beschreibt das Segment. Weshalb ist es sinnvoll, dass ein TSS-Descriptor nur in der GDT stehen darf? Es soll verhindert werden, daß ein USER-Programm in einen anderen Task springt. Da Taskwechsel nur über TASK-Gates erfolgen (dieses zeigt auf einen TSS-Deskriptor) muß der CurrentPrivilegdeLevel (CPL vom CS:) numerisch kleiner sein, als das des geforderten TSS-Deskriptor (DPL) bzw. kleiner als der (RPL) des Segments wo sich der TSS-Deskriptor aufhält. Damit wird sichergestellt, daß der Taskwechsel nur von "höherem" Code (OS) aus ausgeführt werden kann. Würde ein TSS-Deskriptor in der LDT stehen, könnte es dort mit einem höheren RPL versehen werden, und der USER-Code könnte sich zum OS-CODE etablieren! Welche Grundtypen von Deskriptoren gibt es? IDT LDT GDT CODE-Segment DATA-Segment STACK-Segment CODE-Segment DATA-Segment STACK-Segment INT-Gate TRAP-Gate TASK-Gate TASK-Gate TASK-Gate CALL-Gate Welche grundlegenden Adressierungsarten gibt es? Unmittelbare Adressierung Direktadressierung (Direct Adressing) Registeradressierung Indirekte Registeradressierung Indizierte Adressierung Basisindizierte Adressierung Stapeladressierung Unmittelbare Adressierung Der Adressteil der Instruktion enthält den Operanden selbst, anstatt eines Verweises. Solche Operanden werden als Direktoperanden (Immediate) bezeichnet Bsp: MOV R4, 5H (5H wird direkt in R4 gespeichert) Direktadressierung (Direct Adressing) Es wird eine volle Adresse des Operanden angegeben Deshalb nur für globale Variablen anwendbar, da Instruktion immer auf gleiche Speicehrzeile zugreift Registeradressierung Das gleiche Prinzip wie Direct Adressing, nur das Register anstelle von Speicherzellen verwendet werden In Registern sollten die am häufigsten verwendeten Variablen abgelegt werden, da Register vielfach schneller als Hauptspeicher sind Load/Store-Architekturen nutzen fast nur diesen Registermode (außer es muss vom oder zum Speicher transferiert werden) Indirekte Registeradressierung Die Adresse wird nicht direkt angegeben, sondern indirekt über ein Register Das Register enthält somit einen Pointer auf eine Speicherzelle Vorteil ist, daß auf Speicher referenziert werden kann, aber keine volle Speicheradresse notwendig wird Indizierte Adressierung Der Speicher wird durch Angabe eines Registers und eines konstanten Offsets adressiert Häufig benutzt bei Arrayzugriffen, wie A = B[i] (MOV R1, B[R2]) Basisindizierte Adressierung Speicheradresse wird hier durch Addition zweier Register und einen optionalen Offset berechnet Eines der Register stellt die Basis dar und ein anderes den Index Stapeladressierung Hier ist gar keine Adressangabe notwendig Somit sind die Instruktionen sehr kurz Die Stapeladressierung arbeitet mit der umgekehrten polnischen Notation (Postfix) Kapitel 3 - Speicherschutz und Multitasking Um unberechtigte Zugriffe, Datenaufrufe oder Systemprozedurecalls zu vermeiden und Task-Isolation zu gewährleisten, ist ein ausgeklügeltes Sp
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itist der Unterschied zwischen einem Selektor und einem Deskriptor? Ein Selektor Segment-Register wählt einen Deskriptor in (GLI)DT aus, ein Deskriptor Eintrag in (GLI)DT, beschreibt das Segment. <span>Weshalb ist es sinnvoll, dass ein TSS-Descriptor nur in der GDT stehen darf? Es soll verhindert werden, daß ein USER-Programm in einen anderen Task springt. Da Taskwechsel nur über TASK-Gates erfolgen (dieses zeigt auf einen TSS-Deskriptor) muß der CurrentPrivilegdeLevel (CPL vom CS:) numerisch kleiner sein, als das des geforderten TSS-Deskriptor (DPL) bzw. kleiner als der (RPL) des Segments wo sich der TSS-Deskriptor aufhält. Damit wird sichergestellt, daß der Taskwechsel nur von "höherem" Code (OS) aus ausgeführt werden kann. Würde ein TSS-Deskriptor in der LDT stehen, könnte es dort mit einem höheren RPL versehen werden, und der USER-Code könnte sich zum OS-CODE etablieren! Welche Grundtypen von Deskriptoren gibt es? IDT LDT GDT CODE-Segment DATA-Segment STACK-Segment CODE-Segment DATA-Segment STACK-Segment INT-Gate TRAP-Gate TASK-Gate TASK-Gate TASK-Gate
Original toplevel document
Grundprinzipien der Rechnerarchitekturauf. Ein DMA-Controller wirkt wie ein weiterer Prozessor am Bus. Um Inkonsistenzen im Speicher zu vermeiden, muss ein DMA-Controller eng mit dem Speichermanagment des Systems zusammenarbeiten. <span>Was ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adressraum verschiedenen I/O-Devices zuzuordnen oder Getrennten I/O Adressraum, bei dem auf einer speziellen Adressleitung die E/A-Adresse auf den Bus gelegt wird. (veraltete Variante) Was ist eine Task? Ein Task ist ein eigenständiges Programm / Prozess von vielen im Multitasksystem. Es wird von einem TSS (Task State Segment) beschrieben. Bei einem Taskwechsel werden alle Informationen in diesem TSS gespeichert. Jeder TSS-Deskriptor steht in der GDT. Die GDT hat beim i486 8192 Einträge, jedoch ist der 0. Eintrag immer leer. Somit sind maximal 8191 verschiedene Prozesse möglich (inclusive des Betriebssystems). Wie werden Task-Wechsel realisiert? Ein Taskwechsel geschieht durch Auswahl eines Task-Gates aus Globaler Deskriptor Tabelle (Task State Segment = TSS). Ein TSS Enthält alle Informationen, die einen Task ausmachen: verwendete Prozessor-Register LDT-Selektor (einer Pro Task) welche die Segment-Deskriptoren des Prozesses enthält Stack-Segment-Pointer Verwaltungsinformation Adresse der Paging-Tabellen I/O-Map Base Adresse Busy-Bit, definiert den aktuell rechnenden Task (genau einer im System) TR (Task Register) enthält den aktuellen TSS (Selektor des Descriptors des aktuellen TSS) TSS-Descriptoren nur in GDT! Bsp: Scheduler als Task ( Umschalter ) Umschalten durch jeweiligen Austausch des Back-Link, IRETD zum anderen Task, z.B. Timer-Interrupt-Task. Welche Möglichkeiten für Privilegwechsel gibt es? CALL in eine Prozedur mit anderen Privilegde-Level (CALL-Gate) JMP in eine Prozedur mit anderen Privi legde-Level (TASK-Gate) INT (TRAP-Gate) TASK-Gate durch erzwungenen Prozeßwechsel IRET Rücksprung aus INT-Handler Was ist der Unterschied zwischen einem Selektor und einem Deskriptor? Ein Selektor Segment-Register wählt einen Deskriptor in (GLI)DT aus, ein Deskriptor Eintrag in (GLI)DT, beschreibt das Segment. Weshalb ist es sinnvoll, dass ein TSS-Descriptor nur in der GDT stehen darf? Es soll verhindert werden, daß ein USER-Programm in einen anderen Task springt. Da Taskwechsel nur über TASK-Gates erfolgen (dieses zeigt auf einen TSS-Deskriptor) muß der CurrentPrivilegdeLevel (CPL vom CS:) numerisch kleiner sein, als das des geforderten TSS-Deskriptor (DPL) bzw. kleiner als der (RPL) des Segments wo sich der TSS-Deskriptor aufhält. Damit wird sichergestellt, daß der Taskwechsel nur von "höherem" Code (OS) aus ausgeführt werden kann. Würde ein TSS-Deskriptor in der LDT stehen, könnte es dort mit einem höheren RPL versehen werden, und der USER-Code könnte sich zum OS-CODE etablieren! Welche Grundtypen von Deskriptoren gibt es? IDT LDT GDT CODE-Segment DATA-Segment STACK-Segment CODE-Segment DATA-Segment STACK-Segment INT-Gate TRAP-Gate TASK-Gate TASK-Gate TASK-Gate CALL-Gate Welche grundlegenden Adressierungsarten gibt es? Unmittelbare Adressierung Direktadressierung (Direct Adressing) Registeradressierung Indirekte Registeradressierung Indizierte Adressierung Basisindizierte Adressierung Stapeladressierung Unmittelbare Adressierung Der Adressteil der Instruktion enthält den Operanden selbst, anstatt eines Verweises. Solche Operanden werden als Direktoperanden (Immediate) bezeichnet Bsp: MOV R4, 5H (5H wird direkt in R4 gespeichert) Direktadressierung (Direct Adressing) Es wird eine volle Adresse des Operanden angegeben Deshalb nur für globale Variablen anwendbar, da Instruktion immer auf gleiche Speicehrzeile zugreift Registeradressierung Das gleiche Prinzip wie Direct Adressing, nur das Register anstelle von Speicherzellen verwendet werden In Registern sollten die am häufigsten verwendeten Variablen abgelegt werden, da Register vielfach schneller als Hauptspeicher sind Load/Store-Architekturen nutzen fast nur diesen Registermode (außer es muss vom oder zum Speicher transferiert werden) Indirekte Registeradressierung Die Adresse wird nicht direkt angegeben, sondern indirekt über ein Register Das Register enthält somit einen Pointer auf eine Speicherzelle Vorteil ist, daß auf Speicher referenziert werden kann, aber keine volle Speicheradresse notwendig wird Indizierte Adressierung Der Speicher wird durch Angabe eines Registers und eines konstanten Offsets adressiert Häufig benutzt bei Arrayzugriffen, wie A = B[i] (MOV R1, B[R2]) Basisindizierte Adressierung Speicheradresse wird hier durch Addition zweier Register und einen optionalen Offset berechnet Eines der Register stellt die Basis dar und ein anderes den Index Stapeladressierung Hier ist gar keine Adressangabe notwendig Somit sind die Instruktionen sehr kurz Die Stapeladressierung arbeitet mit der umgekehrten polnischen Notation (Postfix) Kapitel 3 - Speicherschutz und Multitasking Um unberechtigte Zugriffe, Datenaufrufe oder Systemprozedurecalls zu vermeiden und Task-Isolation zu gewährleisten, ist ein ausgeklügeltes Sp
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
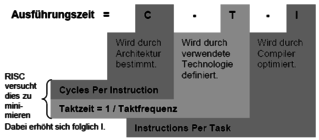
Open itKapitel 5 - Risc Wie berechnet sich die Prozessorleistung? Die Prozessorleistung ist umgekehrt proportional zur Ausführungszeit eines Algorithmus und wird aus folgenden drei Parametern ermittelt: Worum geht es im Besonderen bei einer Risc-Architektur? RISC Architekturen sind darauf aus, die Cycles Per Instruction zu minimieren. Das heißt, es wird versucht alle Befehle mit so wenig wie möglich Takten auszuführen. Welche architektonischen Möglichkeiten gibt es zur Veringerung der CPI? Piplining ergibt eine CPI > 1, andere Techniken wie Superskalarität und VLIW's haben Ausführungszeiten von kle
Original toplevel document
Grundprinzipien der Rechnerarchitekturer liegen, werden in kontinuierlicher Folge abgespeichert. Gepaart mit multiple branch prediction können mehrere zusammenhängende Basisblöcke parallel gefetched werden. (ergibt hohe issue rate) <span>Kapitel 5 - Risc Wie berechnet sich die Prozessorleistung? Die Prozessorleistung ist umgekehrt proportional zur Ausführungszeit eines Algorithmus und wird aus folgenden drei Parametern ermittelt: Worum geht es im Besonderen bei einer Risc-Architektur? RISC Architekturen sind darauf aus, die Cycles Per Instruction zu minimieren. Das heißt, es wird versucht alle Befehle mit so wenig wie möglich Takten auszuführen. Welche architektonischen Möglichkeiten gibt es zur Veringerung der CPI? Piplining ergibt eine CPI > 1, andere Techniken wie Superskalarität und VLIW's haben Ausführungszeiten von kleiner als eins. Kombiniert ergeben beide Ansätze eine nahezuhe Ausführung von einem Befehl pro Takt. Desweiteren ermöglicht der kleine Befehlssatz von RISC eine festverdrahtete Steuereinheit, anstatt von Mikroprogrammen, welche höhere Taktzahlen pro Befehl mit sich bringen. Desweiteren muss bei einem Risc-Befehl nicht der Op-Code dekodiert werden, um herauszufinden, wie der Befehl zu entschlüsseln ist, da alle Befehle die gleiche Struktur besitzen. Auf welche vier Merkmale wird beim RISC-Design-Entwurf besonders geachtet? einfache Maschinenbefehle und Adressierungsarten mit einheitlichen Befehlsformat große und universelle Registersätze, für schnelle Variablenverarbeitung und größere Optimiermöglichkeiten für Compiler Verzahnung von Compiler und Architektur zur Bereitstellung von optimierenden Compilern Optimierte VLSI-Chipfläche durch platzsparende Steuerwerke schafft mehr Platz für Optimiertechniken wie Pipelining,Branch-Prediction oder Superskalarität Techniken zur Ablaufparallelisierung für RISC-Kerne Parallelität von einzelnen Befehlsphasen durch Pipelining Parallelität von ganzen Befehlen durch Superskalartechnik und VLIW Parallelität von Kodefäden durch Multithreading (programmierte Parallelität) oder Multiskalarität (Hardwarethreaderkennung) Parallelität von Befehlen unabhängiger Algorithmen (Multiprozessorsysteme) Pentium 4 Prozessor Kern Load / Store Architektur und Lokalhalten von Daten Da Speicherzugriffe in Pipelines starke Konflikte hervorrufen, gibt es bei RISC-Befehlssätzen nur eine einzige Möglichkeit mit LOAD bzw. STORE auf den Speicher zuzugreifen. So werden Registerzugriffe von Speicherzugriffen getrennt. Da Speicherzugriffe bekanntermaßen immer sehr viel Zeit kosten, versucht man diese so weit wie möglich zu vermeiden. Dies Erreicht man durch Lokalhalten von Daten, bzw. das Arbeiten auf den Registern. Was sind Registerfenster? Registerfenster sollen das Lokalhalten von Daten unterstützen. Typische RISC Prozessoren wie die Berkeley RISC besitzen weit über 100 Register, von denen aber immer nur 32 für sichtbar sind: R0...R9 globale Register R10...R15 Ausgaberegister R16...R25 lokale Register R26...R31 Eingaberegister Die Idee ist nun, daß die ersten 10 Register von allen Prozeduren gesehen werden. Die Restlichen von R10 bis R31 sind jeweils nur einer Prozedur zugeordnet. Falls nun eine Prozedur eine andere aufruft, wird nur das "Fenster" auf einen freien Registerbereich umgeschaltet. So müssen die Register nicht neu aus dem Speicher geladen werden und es wird dadurch viel Zeit gespart. Normalerweise überlappen sich die einzelnen Fenster um einige Register, um somit gleich eine effiziente Möglichkeit der Parameterweitergabe zu bieten. Was passiert wenn alle Registerfenster voll sind? Bei unserem Beispiel mit 138 Registern sind nach sieben Prozeduraufrufen alle Register gefüllt. Um ein Überlaufen zu vermeiden, wird das Register als Ringregister organisiert. Sind alle Registerfenster voll, wird das Älteste in den Speicher ausgelagert, was von sogenannten Trap-Routinen erledigt wird. Was sind Superpipelines? Superpipes vereinen Arithmetisches und Befehlspipelining. Arithmetisches Pipelining ist sogenanntes Funktionspipelining, bei dem einzelne Phasen eines Befehles in einer Pipeline-Form organisiert werden. Bei Instruction Pipelining wird die Abarbeitung eines gesamten Befehls in einer Pipeline organisiert. Zusammenfassung Risc Einfachere Befehlssätze mit ca. 40-80 Befehlstypen Einfachere Steuerung durch die Hardware ohne Mikroprogramme Effizientere Pipelines durch gleichlange, eintaktige Stufen Befehle können meist in einem Takt ausgeführt werden Datenzugriffe nur durch Load und Store um Speicherzugriffe zu vermeiden Mehr Register und Optimierung des Befehlssatzes durch Compiler Typische Riscsysteme haben eine hartverdrahtete Steuereinheit und somit keinen Mikrocodespeicher. Der Pentium ist ein "hybrid"-System mit RISC Kern. Dabei werden komplexe CISC Befehle durch ein Mikroprogramm in RISC zerlegt und im Kern ausgeführt. Die einfachen Befehle werden direkt im RISC Kern in einem einzigen Datenzyklus ausgeführt. Alle wichtigen elementaren (Risc) Befehle werden direkt von Level 0 ( der Hardware ) ausgeführt und somit nicht via Mikroinstruktionen interpretiert. Dies ist ein Vorteil von reinen RISC Systemen, welche diese Interpretationsebene zwischen Hardware und ISA (Instruction Set Architecture) Ebene nicht durchlaufen müssen. Mikroinstruktionen steuern den Datenweg für einen Zyklus. Sie enthält alle notwendigen Bit-Belegungen für ALU, MEM, Register etc., um einen Zyklus abarbeiten lassen zu können. Die Adresse der nächsten Mikroinstruktion wird ebenso mit codiert, wie die Art und Weise des Aufrufes. Die Mikroinstruktionen werden in einem Steuerspeicher gehalten, welcher das jeweilige Mikroprogramm enthält. Der Steuerspeicher muss die Mikroinstruktionen nicht in geordneter oder sequentieller Folge enthalten, wie es beim Hauptspeicher der Fall ist. Es kann jede Instruktion einen Verweis auf die Nächste enthalten. Sprünge sind einfach möglich. Angewandt wird dies in Form von Opcodes, welche nichts anderes als Adressen auf Mikroinstruktionen im Steuerspeicher sind. Kapitel 6 - Pipelining Wozu dient Pipelining? Pipelining soll es ermöglichen Befehle überlappt auszuführen. Dazu sind ein einheitliches Befehlsformat fester Länge Grundlage. Deshalb wer

| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itn bei einer Risc-Architektur? RISC Architekturen sind darauf aus, die Cycles Per Instruction zu minimieren. Das heißt, es wird versucht alle Befehle mit so wenig wie möglich Takten auszuführen. <span>Welche architektonischen Möglichkeiten gibt es zur Veringerung der CPI? Piplining ergibt eine CPI > 1, andere Techniken wie Superskalarität und VLIW's haben Ausführungszeiten von kleiner als eins. Kombiniert ergeben beide Ansätze eine nahezuhe Ausführung von einem Befehl pro Takt. Desweiteren ermöglicht der kleine Befehlssatz von RISC eine festverdrahtete Steuereinheit, anstatt von Mikroprogrammen, welche höhere Taktzahlen pro Befehl mit sich bringen. Desweiteren muss bei einem Risc-Befehl nicht der Op-Code dekodiert werden, um herauszufinden, wie der Befehl zu entschlüsseln ist, da alle Befehle die gleiche Struktur besitzen. Auf welche vier Merkmale wird beim RISC-Design-Entwurf besonders geachtet? einfache Maschinenbefehle und Adressierungsarten mit einheitlichen Befehlsformat große und universelle Registersätze, für schnelle Variablenverarbeitung und größere Optimiermöglichkeiten für Compiler Verzahnung von Compiler und Architektur zur Bereitstellung von optimierenden Compilern Optimierte VLSI-Chipfläche durch platzsparende Steuerwerke schafft mehr Platz für Optimiertechniken wie Pipelining,Branch-Prediction oder Superskalarität Techniken zur Ablaufparallelisierung für RISC-Kerne Parallelität von einzelnen Befehlsphasen durch Pipelining Parallelität von ganzen Befehlen durch Superskalartechnik und VLIW Parallelität von Kodefäden durch Multithreading (programmierte Parallelität) oder Multiskalarität (Hardwarethreaderkennung) Parallelität von Befehlen unabhängiger Algorithmen (Multiprozessorsysteme) Pentium 4 Prozessor Kern Load / Store Architektur und Lokalhalten von Daten Da Speicherzugriffe in Pipelines starke Konflikte hervorrufen, gibt es bei RISC-Befehlssätzen nur eine einzige Möglichkeit mit LOAD bz
Original toplevel document
Grundprinzipien der Rechnerarchitekturer liegen, werden in kontinuierlicher Folge abgespeichert. Gepaart mit multiple branch prediction können mehrere zusammenhängende Basisblöcke parallel gefetched werden. (ergibt hohe issue rate) <span>Kapitel 5 - Risc Wie berechnet sich die Prozessorleistung? Die Prozessorleistung ist umgekehrt proportional zur Ausführungszeit eines Algorithmus und wird aus folgenden drei Parametern ermittelt: Worum geht es im Besonderen bei einer Risc-Architektur? RISC Architekturen sind darauf aus, die Cycles Per Instruction zu minimieren. Das heißt, es wird versucht alle Befehle mit so wenig wie möglich Takten auszuführen. Welche architektonischen Möglichkeiten gibt es zur Veringerung der CPI? Piplining ergibt eine CPI > 1, andere Techniken wie Superskalarität und VLIW's haben Ausführungszeiten von kleiner als eins. Kombiniert ergeben beide Ansätze eine nahezuhe Ausführung von einem Befehl pro Takt. Desweiteren ermöglicht der kleine Befehlssatz von RISC eine festverdrahtete Steuereinheit, anstatt von Mikroprogrammen, welche höhere Taktzahlen pro Befehl mit sich bringen. Desweiteren muss bei einem Risc-Befehl nicht der Op-Code dekodiert werden, um herauszufinden, wie der Befehl zu entschlüsseln ist, da alle Befehle die gleiche Struktur besitzen. Auf welche vier Merkmale wird beim RISC-Design-Entwurf besonders geachtet? einfache Maschinenbefehle und Adressierungsarten mit einheitlichen Befehlsformat große und universelle Registersätze, für schnelle Variablenverarbeitung und größere Optimiermöglichkeiten für Compiler Verzahnung von Compiler und Architektur zur Bereitstellung von optimierenden Compilern Optimierte VLSI-Chipfläche durch platzsparende Steuerwerke schafft mehr Platz für Optimiertechniken wie Pipelining,Branch-Prediction oder Superskalarität Techniken zur Ablaufparallelisierung für RISC-Kerne Parallelität von einzelnen Befehlsphasen durch Pipelining Parallelität von ganzen Befehlen durch Superskalartechnik und VLIW Parallelität von Kodefäden durch Multithreading (programmierte Parallelität) oder Multiskalarität (Hardwarethreaderkennung) Parallelität von Befehlen unabhängiger Algorithmen (Multiprozessorsysteme) Pentium 4 Prozessor Kern Load / Store Architektur und Lokalhalten von Daten Da Speicherzugriffe in Pipelines starke Konflikte hervorrufen, gibt es bei RISC-Befehlssätzen nur eine einzige Möglichkeit mit LOAD bzw. STORE auf den Speicher zuzugreifen. So werden Registerzugriffe von Speicherzugriffen getrennt. Da Speicherzugriffe bekanntermaßen immer sehr viel Zeit kosten, versucht man diese so weit wie möglich zu vermeiden. Dies Erreicht man durch Lokalhalten von Daten, bzw. das Arbeiten auf den Registern. Was sind Registerfenster? Registerfenster sollen das Lokalhalten von Daten unterstützen. Typische RISC Prozessoren wie die Berkeley RISC besitzen weit über 100 Register, von denen aber immer nur 32 für sichtbar sind: R0...R9 globale Register R10...R15 Ausgaberegister R16...R25 lokale Register R26...R31 Eingaberegister Die Idee ist nun, daß die ersten 10 Register von allen Prozeduren gesehen werden. Die Restlichen von R10 bis R31 sind jeweils nur einer Prozedur zugeordnet. Falls nun eine Prozedur eine andere aufruft, wird nur das "Fenster" auf einen freien Registerbereich umgeschaltet. So müssen die Register nicht neu aus dem Speicher geladen werden und es wird dadurch viel Zeit gespart. Normalerweise überlappen sich die einzelnen Fenster um einige Register, um somit gleich eine effiziente Möglichkeit der Parameterweitergabe zu bieten. Was passiert wenn alle Registerfenster voll sind? Bei unserem Beispiel mit 138 Registern sind nach sieben Prozeduraufrufen alle Register gefüllt. Um ein Überlaufen zu vermeiden, wird das Register als Ringregister organisiert. Sind alle Registerfenster voll, wird das Älteste in den Speicher ausgelagert, was von sogenannten Trap-Routinen erledigt wird. Was sind Superpipelines? Superpipes vereinen Arithmetisches und Befehlspipelining. Arithmetisches Pipelining ist sogenanntes Funktionspipelining, bei dem einzelne Phasen eines Befehles in einer Pipeline-Form organisiert werden. Bei Instruction Pipelining wird die Abarbeitung eines gesamten Befehls in einer Pipeline organisiert. Zusammenfassung Risc Einfachere Befehlssätze mit ca. 40-80 Befehlstypen Einfachere Steuerung durch die Hardware ohne Mikroprogramme Effizientere Pipelines durch gleichlange, eintaktige Stufen Befehle können meist in einem Takt ausgeführt werden Datenzugriffe nur durch Load und Store um Speicherzugriffe zu vermeiden Mehr Register und Optimierung des Befehlssatzes durch Compiler Typische Riscsysteme haben eine hartverdrahtete Steuereinheit und somit keinen Mikrocodespeicher. Der Pentium ist ein "hybrid"-System mit RISC Kern. Dabei werden komplexe CISC Befehle durch ein Mikroprogramm in RISC zerlegt und im Kern ausgeführt. Die einfachen Befehle werden direkt im RISC Kern in einem einzigen Datenzyklus ausgeführt. Alle wichtigen elementaren (Risc) Befehle werden direkt von Level 0 ( der Hardware ) ausgeführt und somit nicht via Mikroinstruktionen interpretiert. Dies ist ein Vorteil von reinen RISC Systemen, welche diese Interpretationsebene zwischen Hardware und ISA (Instruction Set Architecture) Ebene nicht durchlaufen müssen. Mikroinstruktionen steuern den Datenweg für einen Zyklus. Sie enthält alle notwendigen Bit-Belegungen für ALU, MEM, Register etc., um einen Zyklus abarbeiten lassen zu können. Die Adresse der nächsten Mikroinstruktion wird ebenso mit codiert, wie die Art und Weise des Aufrufes. Die Mikroinstruktionen werden in einem Steuerspeicher gehalten, welcher das jeweilige Mikroprogramm enthält. Der Steuerspeicher muss die Mikroinstruktionen nicht in geordneter oder sequentieller Folge enthalten, wie es beim Hauptspeicher der Fall ist. Es kann jede Instruktion einen Verweis auf die Nächste enthalten. Sprünge sind einfach möglich. Angewandt wird dies in Form von Opcodes, welche nichts anderes als Adressen auf Mikroinstruktionen im Steuerspeicher sind. Kapitel 6 - Pipelining Wozu dient Pipelining? Pipelining soll es ermöglichen Befehle überlappt auszuführen. Dazu sind ein einheitliches Befehlsformat fester Länge Grundlage. Deshalb wer
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itpelining, bei dem einzelne Phasen eines Befehles in einer Pipeline-Form organisiert werden. Bei Instruction Pipelining wird die Abarbeitung eines gesamten Befehls in einer Pipeline organisiert. <span>Zusammenfassung Risc Einfachere Befehlssätze mit ca. 40-80 Befehlstypen Einfachere Steuerung durch die Hardware ohne Mikroprogramme Effizientere Pipelines durch gleichlange, eintaktige Stufen Befehle können meist in einem Takt ausgeführt werden Datenzugriffe nur durch Load und Store um Speicherzugriffe zu vermeiden Mehr Register und Optimierung des Befehlssatzes durch Compiler Typische Riscsysteme haben eine hartverdrahtete Steuereinheit und somit keinen Mikrocodespeicher. Der Pentium ist ein "hybrid"-System mit RISC Kern. Dabei werden komplexe CISC Befehle durch ein Mikroprogramm in RISC zerlegt und im Kern ausgeführt. Die einfachen Befehle werden direkt im RISC Kern in einem einzigen Datenzyklus ausgeführt. Alle wichtigen elementaren (Risc) Befehle werden direkt von Level 0 ( der Hardware ) ausgeführt und somit nicht via Mikroinstruktionen interpretiert. Dies ist ein Vorteil von reinen RISC Systemen, welche diese Interpretationsebene zwischen Hardware und ISA (Instruction Set Architecture) Ebene nicht durchlaufen müssen. Mikroinstruktionen steuern den Datenweg für einen Zyklus. Sie enthält alle notwendigen Bit-Belegungen für ALU, MEM, Register etc., um einen Zyklus abarbeiten lassen zu können. Die Adresse der nächsten Mikroinstruktion wird ebenso mit codiert, wie die Art und Weise des Aufrufes. Die Mikroinstruktionen werden in einem Steuerspeicher gehalten, welcher das jeweilige Mikroprogramm enthält. Der Steuerspeicher muss die Mikroinstruktionen nicht in geordneter oder sequentieller Folge enthalten, wie es beim Hauptspeicher der Fall ist. Es kann jede Instruktion einen Verweis auf die Nächste enthalten. Sprünge sind einfach möglich. Angewandt wird dies in Form von Opcodes, welche nichts anderes als Adressen auf Mikroinstruktionen im Steuerspeicher sind. <span>
Original toplevel document
Grundprinzipien der Rechnerarchitekturer liegen, werden in kontinuierlicher Folge abgespeichert. Gepaart mit multiple branch prediction können mehrere zusammenhängende Basisblöcke parallel gefetched werden. (ergibt hohe issue rate) <span>Kapitel 5 - Risc Wie berechnet sich die Prozessorleistung? Die Prozessorleistung ist umgekehrt proportional zur Ausführungszeit eines Algorithmus und wird aus folgenden drei Parametern ermittelt: Worum geht es im Besonderen bei einer Risc-Architektur? RISC Architekturen sind darauf aus, die Cycles Per Instruction zu minimieren. Das heißt, es wird versucht alle Befehle mit so wenig wie möglich Takten auszuführen. Welche architektonischen Möglichkeiten gibt es zur Veringerung der CPI? Piplining ergibt eine CPI > 1, andere Techniken wie Superskalarität und VLIW's haben Ausführungszeiten von kleiner als eins. Kombiniert ergeben beide Ansätze eine nahezuhe Ausführung von einem Befehl pro Takt. Desweiteren ermöglicht der kleine Befehlssatz von RISC eine festverdrahtete Steuereinheit, anstatt von Mikroprogrammen, welche höhere Taktzahlen pro Befehl mit sich bringen. Desweiteren muss bei einem Risc-Befehl nicht der Op-Code dekodiert werden, um herauszufinden, wie der Befehl zu entschlüsseln ist, da alle Befehle die gleiche Struktur besitzen. Auf welche vier Merkmale wird beim RISC-Design-Entwurf besonders geachtet? einfache Maschinenbefehle und Adressierungsarten mit einheitlichen Befehlsformat große und universelle Registersätze, für schnelle Variablenverarbeitung und größere Optimiermöglichkeiten für Compiler Verzahnung von Compiler und Architektur zur Bereitstellung von optimierenden Compilern Optimierte VLSI-Chipfläche durch platzsparende Steuerwerke schafft mehr Platz für Optimiertechniken wie Pipelining,Branch-Prediction oder Superskalarität Techniken zur Ablaufparallelisierung für RISC-Kerne Parallelität von einzelnen Befehlsphasen durch Pipelining Parallelität von ganzen Befehlen durch Superskalartechnik und VLIW Parallelität von Kodefäden durch Multithreading (programmierte Parallelität) oder Multiskalarität (Hardwarethreaderkennung) Parallelität von Befehlen unabhängiger Algorithmen (Multiprozessorsysteme) Pentium 4 Prozessor Kern Load / Store Architektur und Lokalhalten von Daten Da Speicherzugriffe in Pipelines starke Konflikte hervorrufen, gibt es bei RISC-Befehlssätzen nur eine einzige Möglichkeit mit LOAD bzw. STORE auf den Speicher zuzugreifen. So werden Registerzugriffe von Speicherzugriffen getrennt. Da Speicherzugriffe bekanntermaßen immer sehr viel Zeit kosten, versucht man diese so weit wie möglich zu vermeiden. Dies Erreicht man durch Lokalhalten von Daten, bzw. das Arbeiten auf den Registern. Was sind Registerfenster? Registerfenster sollen das Lokalhalten von Daten unterstützen. Typische RISC Prozessoren wie die Berkeley RISC besitzen weit über 100 Register, von denen aber immer nur 32 für sichtbar sind: R0...R9 globale Register R10...R15 Ausgaberegister R16...R25 lokale Register R26...R31 Eingaberegister Die Idee ist nun, daß die ersten 10 Register von allen Prozeduren gesehen werden. Die Restlichen von R10 bis R31 sind jeweils nur einer Prozedur zugeordnet. Falls nun eine Prozedur eine andere aufruft, wird nur das "Fenster" auf einen freien Registerbereich umgeschaltet. So müssen die Register nicht neu aus dem Speicher geladen werden und es wird dadurch viel Zeit gespart. Normalerweise überlappen sich die einzelnen Fenster um einige Register, um somit gleich eine effiziente Möglichkeit der Parameterweitergabe zu bieten. Was passiert wenn alle Registerfenster voll sind? Bei unserem Beispiel mit 138 Registern sind nach sieben Prozeduraufrufen alle Register gefüllt. Um ein Überlaufen zu vermeiden, wird das Register als Ringregister organisiert. Sind alle Registerfenster voll, wird das Älteste in den Speicher ausgelagert, was von sogenannten Trap-Routinen erledigt wird. Was sind Superpipelines? Superpipes vereinen Arithmetisches und Befehlspipelining. Arithmetisches Pipelining ist sogenanntes Funktionspipelining, bei dem einzelne Phasen eines Befehles in einer Pipeline-Form organisiert werden. Bei Instruction Pipelining wird die Abarbeitung eines gesamten Befehls in einer Pipeline organisiert. Zusammenfassung Risc Einfachere Befehlssätze mit ca. 40-80 Befehlstypen Einfachere Steuerung durch die Hardware ohne Mikroprogramme Effizientere Pipelines durch gleichlange, eintaktige Stufen Befehle können meist in einem Takt ausgeführt werden Datenzugriffe nur durch Load und Store um Speicherzugriffe zu vermeiden Mehr Register und Optimierung des Befehlssatzes durch Compiler Typische Riscsysteme haben eine hartverdrahtete Steuereinheit und somit keinen Mikrocodespeicher. Der Pentium ist ein "hybrid"-System mit RISC Kern. Dabei werden komplexe CISC Befehle durch ein Mikroprogramm in RISC zerlegt und im Kern ausgeführt. Die einfachen Befehle werden direkt im RISC Kern in einem einzigen Datenzyklus ausgeführt. Alle wichtigen elementaren (Risc) Befehle werden direkt von Level 0 ( der Hardware ) ausgeführt und somit nicht via Mikroinstruktionen interpretiert. Dies ist ein Vorteil von reinen RISC Systemen, welche diese Interpretationsebene zwischen Hardware und ISA (Instruction Set Architecture) Ebene nicht durchlaufen müssen. Mikroinstruktionen steuern den Datenweg für einen Zyklus. Sie enthält alle notwendigen Bit-Belegungen für ALU, MEM, Register etc., um einen Zyklus abarbeiten lassen zu können. Die Adresse der nächsten Mikroinstruktion wird ebenso mit codiert, wie die Art und Weise des Aufrufes. Die Mikroinstruktionen werden in einem Steuerspeicher gehalten, welcher das jeweilige Mikroprogramm enthält. Der Steuerspeicher muss die Mikroinstruktionen nicht in geordneter oder sequentieller Folge enthalten, wie es beim Hauptspeicher der Fall ist. Es kann jede Instruktion einen Verweis auf die Nächste enthalten. Sprünge sind einfach möglich. Angewandt wird dies in Form von Opcodes, welche nichts anderes als Adressen auf Mikroinstruktionen im Steuerspeicher sind. Kapitel 6 - Pipelining Wozu dient Pipelining? Pipelining soll es ermöglichen Befehle überlappt auszuführen. Dazu sind ein einheitliches Befehlsformat fester Länge Grundlage. Deshalb wer
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itch Multithreading (programmierte Parallelität) oder Multiskalarität (Hardwarethreaderkennung) Parallelität von Befehlen unabhängiger Algorithmen (Multiprozessorsysteme) Pentium 4 Prozessor Kern <span>Load / Store Architektur und Lokalhalten von Daten Da Speicherzugriffe in Pipelines starke Konflikte hervorrufen, gibt es bei RISC-Befehlssätzen nur eine einzige Möglichkeit mit LOAD bzw. STORE auf den Speicher zuzugreifen. So werden Registerzugriffe von Speicherzugriffen getrennt. Da Speicherzugriffe bekanntermaßen immer sehr viel Zeit kosten, versucht man diese so weit wie möglich zu vermeiden. Dies Erreicht man durch Lokalhalten von Daten, bzw. das Arbeiten auf den Registern. Was sind Registerfenster? Registerfenster sollen das Lokalhalten von Daten unterstützen. Typische RISC Prozessoren wie die Berkeley RISC besitzen weit über 100 Register, von denen aber immer nur 32 für sichtbar sind: R0...R9 globale Register R10...R15 Ausgaberegister R16...R25 lokale Register R26...R31 Eingaberegister Die Idee ist nun, daß die ersten 10 Register von allen Prozeduren gesehen werden. Die Restlichen von R10 bis R31 sind jeweils nur einer Prozedur zugeordnet. Falls nun eine Prozedur eine andere aufruft, wird nur das "Fenster" auf einen freien Registerbereich umgeschaltet. So müssen die Register nicht neu aus dem Speicher geladen werden und es wird dadurch viel Zeit gespart. Normalerweise überlappen sich die einzelnen Fenster um einige Register, um somit gleich eine effiziente Möglichkeit der Parameterweitergabe zu bieten. Was passiert wenn alle Registerfenster voll sind? Bei unserem Beispiel mit 138 Registern sind nach sieben Prozeduraufrufen alle Register gefüllt. Um ein Überlaufen zu vermeiden, wird das Register als Ringregister organisiert. Sind alle Registerfenster voll, wird das Älteste in den Speicher ausgelagert, was von sogenannten Trap-Routinen erledigt wird. Was sind Superpipelines? Superpipes vereinen Arithmetisches und Befehlspipelining. Arithmetisches Pipelining ist sogenanntes Funktionspipelining, bei dem einzelne Phasen eines Befehles in einer Pipeline-Form organisiert werden. Bei Instruction Pipelining wird die Abarbeitung eines gesamten Befehls in einer Pipeline organisiert. Zusammenfassung Risc Einfachere Befehlssätze mit ca. 40-80 Befehlstypen Einfachere Steuerung durch die Hardware ohne Mikroprogramme Effizientere Pipelines durch gleichlange, eintaktige
Original toplevel document
Grundprinzipien der Rechnerarchitekturer liegen, werden in kontinuierlicher Folge abgespeichert. Gepaart mit multiple branch prediction können mehrere zusammenhängende Basisblöcke parallel gefetched werden. (ergibt hohe issue rate) <span>Kapitel 5 - Risc Wie berechnet sich die Prozessorleistung? Die Prozessorleistung ist umgekehrt proportional zur Ausführungszeit eines Algorithmus und wird aus folgenden drei Parametern ermittelt: Worum geht es im Besonderen bei einer Risc-Architektur? RISC Architekturen sind darauf aus, die Cycles Per Instruction zu minimieren. Das heißt, es wird versucht alle Befehle mit so wenig wie möglich Takten auszuführen. Welche architektonischen Möglichkeiten gibt es zur Veringerung der CPI? Piplining ergibt eine CPI > 1, andere Techniken wie Superskalarität und VLIW's haben Ausführungszeiten von kleiner als eins. Kombiniert ergeben beide Ansätze eine nahezuhe Ausführung von einem Befehl pro Takt. Desweiteren ermöglicht der kleine Befehlssatz von RISC eine festverdrahtete Steuereinheit, anstatt von Mikroprogrammen, welche höhere Taktzahlen pro Befehl mit sich bringen. Desweiteren muss bei einem Risc-Befehl nicht der Op-Code dekodiert werden, um herauszufinden, wie der Befehl zu entschlüsseln ist, da alle Befehle die gleiche Struktur besitzen. Auf welche vier Merkmale wird beim RISC-Design-Entwurf besonders geachtet? einfache Maschinenbefehle und Adressierungsarten mit einheitlichen Befehlsformat große und universelle Registersätze, für schnelle Variablenverarbeitung und größere Optimiermöglichkeiten für Compiler Verzahnung von Compiler und Architektur zur Bereitstellung von optimierenden Compilern Optimierte VLSI-Chipfläche durch platzsparende Steuerwerke schafft mehr Platz für Optimiertechniken wie Pipelining,Branch-Prediction oder Superskalarität Techniken zur Ablaufparallelisierung für RISC-Kerne Parallelität von einzelnen Befehlsphasen durch Pipelining Parallelität von ganzen Befehlen durch Superskalartechnik und VLIW Parallelität von Kodefäden durch Multithreading (programmierte Parallelität) oder Multiskalarität (Hardwarethreaderkennung) Parallelität von Befehlen unabhängiger Algorithmen (Multiprozessorsysteme) Pentium 4 Prozessor Kern Load / Store Architektur und Lokalhalten von Daten Da Speicherzugriffe in Pipelines starke Konflikte hervorrufen, gibt es bei RISC-Befehlssätzen nur eine einzige Möglichkeit mit LOAD bzw. STORE auf den Speicher zuzugreifen. So werden Registerzugriffe von Speicherzugriffen getrennt. Da Speicherzugriffe bekanntermaßen immer sehr viel Zeit kosten, versucht man diese so weit wie möglich zu vermeiden. Dies Erreicht man durch Lokalhalten von Daten, bzw. das Arbeiten auf den Registern. Was sind Registerfenster? Registerfenster sollen das Lokalhalten von Daten unterstützen. Typische RISC Prozessoren wie die Berkeley RISC besitzen weit über 100 Register, von denen aber immer nur 32 für sichtbar sind: R0...R9 globale Register R10...R15 Ausgaberegister R16...R25 lokale Register R26...R31 Eingaberegister Die Idee ist nun, daß die ersten 10 Register von allen Prozeduren gesehen werden. Die Restlichen von R10 bis R31 sind jeweils nur einer Prozedur zugeordnet. Falls nun eine Prozedur eine andere aufruft, wird nur das "Fenster" auf einen freien Registerbereich umgeschaltet. So müssen die Register nicht neu aus dem Speicher geladen werden und es wird dadurch viel Zeit gespart. Normalerweise überlappen sich die einzelnen Fenster um einige Register, um somit gleich eine effiziente Möglichkeit der Parameterweitergabe zu bieten. Was passiert wenn alle Registerfenster voll sind? Bei unserem Beispiel mit 138 Registern sind nach sieben Prozeduraufrufen alle Register gefüllt. Um ein Überlaufen zu vermeiden, wird das Register als Ringregister organisiert. Sind alle Registerfenster voll, wird das Älteste in den Speicher ausgelagert, was von sogenannten Trap-Routinen erledigt wird. Was sind Superpipelines? Superpipes vereinen Arithmetisches und Befehlspipelining. Arithmetisches Pipelining ist sogenanntes Funktionspipelining, bei dem einzelne Phasen eines Befehles in einer Pipeline-Form organisiert werden. Bei Instruction Pipelining wird die Abarbeitung eines gesamten Befehls in einer Pipeline organisiert. Zusammenfassung Risc Einfachere Befehlssätze mit ca. 40-80 Befehlstypen Einfachere Steuerung durch die Hardware ohne Mikroprogramme Effizientere Pipelines durch gleichlange, eintaktige Stufen Befehle können meist in einem Takt ausgeführt werden Datenzugriffe nur durch Load und Store um Speicherzugriffe zu vermeiden Mehr Register und Optimierung des Befehlssatzes durch Compiler Typische Riscsysteme haben eine hartverdrahtete Steuereinheit und somit keinen Mikrocodespeicher. Der Pentium ist ein "hybrid"-System mit RISC Kern. Dabei werden komplexe CISC Befehle durch ein Mikroprogramm in RISC zerlegt und im Kern ausgeführt. Die einfachen Befehle werden direkt im RISC Kern in einem einzigen Datenzyklus ausgeführt. Alle wichtigen elementaren (Risc) Befehle werden direkt von Level 0 ( der Hardware ) ausgeführt und somit nicht via Mikroinstruktionen interpretiert. Dies ist ein Vorteil von reinen RISC Systemen, welche diese Interpretationsebene zwischen Hardware und ISA (Instruction Set Architecture) Ebene nicht durchlaufen müssen. Mikroinstruktionen steuern den Datenweg für einen Zyklus. Sie enthält alle notwendigen Bit-Belegungen für ALU, MEM, Register etc., um einen Zyklus abarbeiten lassen zu können. Die Adresse der nächsten Mikroinstruktion wird ebenso mit codiert, wie die Art und Weise des Aufrufes. Die Mikroinstruktionen werden in einem Steuerspeicher gehalten, welcher das jeweilige Mikroprogramm enthält. Der Steuerspeicher muss die Mikroinstruktionen nicht in geordneter oder sequentieller Folge enthalten, wie es beim Hauptspeicher der Fall ist. Es kann jede Instruktion einen Verweis auf die Nächste enthalten. Sprünge sind einfach möglich. Angewandt wird dies in Form von Opcodes, welche nichts anderes als Adressen auf Mikroinstruktionen im Steuerspeicher sind. Kapitel 6 - Pipelining Wozu dient Pipelining? Pipelining soll es ermöglichen Befehle überlappt auszuführen. Dazu sind ein einheitliches Befehlsformat fester Länge Grundlage. Deshalb wer
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itThe LSTM network is different to a classical MLP. Like an MLP, the network is comprised of layers of neurons. Input data is propagated through the network in order to make a prediction. Like RNNs, the LSTMs have recurrent connections so that the state from previous activations of the neuron from the previous time step is used as context for formulating an output. But
Original toplevel document (pdf)
cannot see any pdfsFlashcard 7640933338380
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itWe get the average treatment effect (ATE) by taking an average over the ITEs: 𝜏 , 𝔼[𝑌 𝑖 (1) − 𝑌 𝑖 (0)] = 𝔼[𝑌(1) − 𝑌(0)] , where the average is over the individuals 𝑖 if 𝑌 𝑖 (𝑡) is deterministic. If 𝑌 𝑖 (𝑡) is random, the avera
Original toplevel document (pdf)
cannot see any pdfsFlashcard 7640936484108
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open ite of satisfying unconfoundedness, it can lead to a higher chance of violating positivity. As we increase the dimension of the covariates, we make the subgroups for any level 𝑥 of the covariates <span>smaller. <span>