Edited, memorised or added to reading queue
on 19-Sep-2024 (Thu)
Do you want BuboFlash to help you learning these things? Click here to log in or create user.
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |

| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itSC), variieren auch hier Befehlslänge und Taktanzahl pro Befehl. Orthogonale Befehlssätze sind solche, welche eine beliebige Kombination von Befehlscode, Adressierungsart und Datentyp zulassen. <span>Was ist Byte-Ordering und Word-Alignment? Alle konventionellen Rechner sind Byte-Adressiert. D.h. das Worte (egal ob 8, 16 oder mehr Bit) bestehen aus einer Folge (aufsteigender) Bytes. Dabei gilt das erste Byte als die Adresse des Wortes. Nimmt die Wertigkeit mit aufsteigender Adresse zu, ist es das Litte-Endian-Format, umgekehrt das Big-Endian-Format. Falls Worte so in den Speicher passen, das keine Verschiebungen auftreten, heißt der Speicher aligned. Prüfen kann man dies durch die Formel Adresse mod Wortlänge = 0? <span>
Original toplevel document
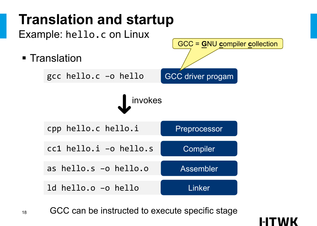
Grundprinzipien der Rechnerarchitekturon Kapitel 8 - Superskalarität Kapitel 9 - Parallelrechner Zurück zur Übersicht Rechnerarchitektur Grundprinzipien der Rechnerarchitektur. D.h. Themen wie RISC, Branch Prediction oder Tomasulo. <span>Kapitel 1 - Prinzipien und Architekturen In welche sieben Ebenen kann man ein Rechnersystem einteilen? Anwendungsebene (Anwendersoftware) Assemblerebene (Beschreibung von Algorithmen, Link & Bind) Betriebssystem (Speichermanagment, Prozesskommunikation) Instruction Set Architecture (ISA,Adressierungsarten) Microarchitektur (Risc,Cisc,Branch Prediction..) Logische Ebene (Register,Schieber, Latches..) Transistorebene (Transistoren, MOS ) nach Tanenbaum Computerarchitektur Wie lassen sich Architekturen klassifizieren? Nach ihrem Rechenprinzip Von Neumann (Steuerfluss) Datenfluß (Zündregel) Reduktion (Funktionsaufruf) Objektorientiert (Methodenaufruf) Nach dem Architektur-Grundkonzept Vektorrechner (Pipeline) Array-Computer (Data-Array) Assoziativ-Rechner (Assoziativ-Speicher) Wie kann die Leistung erhöht werden? Über die Architektur Pipelines, Superskalarität, Spekulative Ausführung, Caches, Busbreite Über Optimierung von Software Compileroptimierung Über die Siliziumbasis Transistordichte und Taktraten Was sind die vier Hauptbestandteile eines typischen Rechners? Was unterscheidet eine Schnittstelle von einem Bus? Ein Bus verbindet mehr als zwei Teilnehmer. John von Neumann mit ENIAC Welche Bestandteile definieren einen von Neumann-Rechner? Der von Neumann-Rechner arbeitet sequentiell, Befehl für Befehl wird abgeholt, interpretiert, ausgeführt und das Resultat abgespeichert. Steuerwerk (Taktgeber und Befehlszähler) Speicher Rechenwerk (CPU) I/O-Einheit Datenbreite, Adressierungsbreite, Registeranzahl und Befehlssatz können als Parameter verstanden werden. Wie arbeitet die zentrale Befehlsschleife eines Von-Neumann-Rechners? Was heißt Havard-Architektur? Daten- und Befehlsspeicher sind getrennt. So ist es möglich Daten und Befehle Zeitgleich aus dem Speicher zu holen. Da dies aber einen extrem hohen Aufwand bedeutet, wird dies nur bei Echtzeitanwendungen implementiert. Was ist ein Taktzyklus? Die Interpretation und Ausführung eines Befehles erfolgt in vier Phasen. Holen Dekodieren (inklusive Operandenadressen berechnen) Daten holen (bzw. Operanden) Ausführen Jede der vier Phasen wird in eine Anzahl von Schnittstellen bzw. Zyklen eingeteilt. Ein Taktzyklus ist die kleinstmöglich verarbeitbare Einheit. Somit benötigt ein Befehl zur Ausführung im Allgemeinen mehr als einen Taktzyklus. Was ist Mikroprogrammierung? Durch Einsatz von Matrix-Speichertechnologie ist es möglich Steuersignalkombinationen in je einer Zeile dieser Speichermatrix abzulegen. Somit können Zeile für Zeile Maschinenzustande auf dem Prozessor hinterlegt werden. Das sogenannte Mikroprogramm. Die interne Logik ist eher zufällig optimiert. Daher der Begriff "Random Logic". Was sind Complex Instruction Set Computer (CISC)? Durch Einführung von mnemonischen Kodierungen von Mikrobefehlen, welche von Mikrobefehls-Assemblern verarbeitet werden, sind weitaus komplexere Befehle möglich. CISC bietet einen sehr großen Befehlssatz mit sich start unterscheidenden Befehlen in Ausführungszeit und Parameterliste. Gegenüberstellung der Architektur von CISC und RISC Worin unterscheiden sich RISC und CISC besonders? Eigenschaften CISC RISC Register Wenige Register( ca. 20) Viele Register (bis zu 200) und Registerfenster Befehlssatz ca. 300 Befehle und mehr als 50 Befehlstypen Nur rund 100 meist registerorientierte Befehle (außer LOAD / STORE) Adressierungsarten ca. 12 verschiedene Nur 3 bis 5 Arten und nur LOAD/STORE zum Speicher Caches Gemeinsame Caches, aber später auch Getrennte Getrennte Daten- und Befehlscaches nach Harvard CPI 1 bis 20 - Durchschnittlich 4 1 bei Basisoperationen - im Schnitt 1,5 Befehlssteuerung Mikrocode im Speicher, aber auch hartverdrahtet Meistens hartverdrahtete Mikroprogramme ohne Mikroprogrammspeicher Beispielprozessoren Intel x86, AMD, Cyrix Sun UltraSparc, PowerPC Welche Befehlssatz-Architekturen kennen Sie? Stack-Architektur? Diese Form benötigt keine Adressen für Operanden und ist somit eine Nulladressmaschine. Quell und Ergebnisoperanden liegen auf einem Operanden-Stack. Vorteil dieser Architektur ist daher die Speicherplatzeinsparung durch die nicht notwendigen Adressen. Akkumulator-Architektur? Um Verknüpfungsoperationen durchzuführen, liegt ein Operand in einem Register und ein Operand typischerweise im Hauptspeicher (Einadressmaschine) . Vorteil ist die einfache Implementierung, da nur ein internes Register benötigt wird. Nachteil ist aber die hohe Speicherlast. Universalregister-Architektur? Ein Satz von gleichberechtigten Registern kann zum Ablegen von Daten genutzt werden. Deshalb sind im Op-Code mehrere Operanden anzugeben (Zwei-, Dreiadressmaschine etc.) Vorteil ist die freie Benutzbarkeit durch Compiler. Ausdrucksberechnungen können somit in beliebiger Reihenfolge erfolgen, was Pipelining möglich macht. Dazu kommt, daß die Speichertransferlast sinkt, die Geschwindigkeit steigt und Superskalartechniken sind effizient einsetzbar. Der Nachteil dieser Architektur sind die teilweise großen Registersets, welche bei jedem Kontextwechsel auszutauschen sind. Außerdem müssen die Operanden Adressiert werden, was zu langen Befehlen führt. Welche Register-Architekturen gibt es? Register-Register ohne Speicheradressen (Sparc,Mips) Verknüpfungsoperationen verwenden nur Register. Nur in Lade- und Speicherbefehlen werden Adressen verwendet. (Load / Store - Architektur). Vorteil ist, dass die Verknüpfungen immer mit Registern geschehen und somit eine Befehlsdekodierung mit fester Länge möglich ist. Vorteile Einheitliche Taktzyklen pro Befehl Pipeline-Prinzip wird dadurch unterstützt Nachteile Code wird größer, da Speichertransfers nur durch zusätzliche Befehle Register-Speicher mit der Möglichkeit von Speicheradressen (Motorola 68000) Vorteile Daten können auch im Speicher referenziert werden, ohne diese vorher Explizit laden zu müssen. Nachteile Durch die variierenden Adressierungen variieren Befehlslänge und Taktzyklen pro Befehl, was äußerst negativ für Verfahren wie Pipelining ist. Speicher-Speicher mit nur Speicheradressen (DEC-VAX) Vorteile Der Programmierer braucht sich nicht um Register kümmern. Deshalb wird die Programmierung transparenter. Nachteile Es entsteht ein hoher Speicherverkehr, was sich Nachteilig auf die Performance auswirkt. Falls doch Register erlaubt werden (Orthogonaler Befehlssatz / CISC), variieren auch hier Befehlslänge und Taktanzahl pro Befehl. Orthogonale Befehlssätze sind solche, welche eine beliebige Kombination von Befehlscode, Adressierungsart und Datentyp zulassen. Was ist Byte-Ordering und Word-Alignment? Alle konventionellen Rechner sind Byte-Adressiert. D.h. das Worte (egal ob 8, 16 oder mehr Bit) bestehen aus einer Folge (aufsteigender) Bytes. Dabei gilt das erste Byte als die Adresse des Wortes. Nimmt die Wertigkeit mit aufsteigender Adresse zu, ist es das Litte-Endian-Format, umgekehrt das Big-Endian-Format. Falls Worte so in den Speicher passen, das keine Verschiebungen auftreten, heißt der Speicher aligned. Prüfen kann man dies durch die Formel Adresse mod Wortlänge = 0? Kapitel 2 - Interrupts und DMA Klassifizieren Sie die verschiedenen Unterbrechungen! Wenn in der Literatur von Interrupts gesprochen wird, so werden oft externe, asynchrone Interrupts g
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itType definitions for structures Defining struct point and type Point for it typedef struct point Point; struct point { int x; int y; }; Same definitions in one statement typedef struct point { int x; int y; } Point; Defining type Point for unnamed struct typedef struct { int x; int y; } Point;
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Flashcard 7657154809100
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itHow we can improve model (in the particular stage of the process)? # 1. Creating model: add more layers, increase numbers of hidden neurons, change activation functions
Original toplevel document
TfC 01 regression#### How we can improve model # 1. Creating model: add more layers, increase numbers of hidden neurons, change activation functions # 2. Compiling: change optimizer or its parameters (eg. learning rate) # 3. Fitting: more epochs, more data ### How? # from smaller model to larger model Evaluating models Typical workflow: build a model -> fit it -> evaulate -> tweak -> fit > evaluate -> .... Building model: experiment Evaluation model: visualize What
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itConfusion matrix Can be hard to use whith large numbers of classes. y-axis -> true label x-axis -> predicted label # Create confusion metrics from sklearn.metrics import confusion_matrix y_preds = model_8.predict(X_test) confusion_matrix(y_test, y_preds)
Original toplevel document
TfC_02_classification-PART_2leads to less false negatives. Tradeoff between recall and precision. F1-score Combination of precision and recall, ususally a good overall metric for classification models. keyboard_arrow_down <span>Confusion matrix Can be hard to use whith large numbers of classes. y-axis -> true label x-axis -> predicted label # Create confusion metrics from sklearn.metrics import confusion_matrix y_preds = model_8.predict(X_test) confusion_matrix(y_test, y_preds) important: This time there is a problem with loss function. In case of categorical_crossentropy the labels have to be one-hot encoded In case of labels as integeres use SparseCategorica
Flashcard 7657159265548
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itConfusion matrix y-axis -> true label
Original toplevel document
TfC_02_classification-PART_2leads to less false negatives. Tradeoff between recall and precision. F1-score Combination of precision and recall, ususally a good overall metric for classification models. keyboard_arrow_down <span>Confusion matrix Can be hard to use whith large numbers of classes. y-axis -> true label x-axis -> predicted label # Create confusion metrics from sklearn.metrics import confusion_matrix y_preds = model_8.predict(X_test) confusion_matrix(y_test, y_preds) important: This time there is a problem with loss function. In case of categorical_crossentropy the labels have to be one-hot encoded In case of labels as integeres use SparseCategorica
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itConfusion matrix Can be hard to use whith large numbers of classes. y-axis -> true label x-axis -> predicted label # Create confusion metrics from sklearn.metrics import confusion_matrix y_preds = model_8.predict(X_test) confusion_matrix(y_test, y_preds)
Original toplevel document
TfC_02_classification-PART_2leads to less false negatives. Tradeoff between recall and precision. F1-score Combination of precision and recall, ususally a good overall metric for classification models. keyboard_arrow_down <span>Confusion matrix Can be hard to use whith large numbers of classes. y-axis -> true label x-axis -> predicted label # Create confusion metrics from sklearn.metrics import confusion_matrix y_preds = model_8.predict(X_test) confusion_matrix(y_test, y_preds) important: This time there is a problem with loss function. In case of categorical_crossentropy the labels have to be one-hot encoded In case of labels as integeres use SparseCategorica
Flashcard 7657163984140
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open it## The 3 sets (or actually 2 sets: training and test set) - USING ONLY TensorFlow tf.random.set_seed(999) X_train, X_test = tf.split(tf.random.shuffle(X, seed=42), num_or_size_splits=[40, 10])
Original toplevel document
TfC 01 regression> evaulate -> tweak -> fit > evaluate -> .... Building model: experiment Evaluation model: visualize What can visualize? the data model itself the training of a model predictions <span>## The 3 sets (or actually 2 sets: training and test set) tf.random.set_seed(999) X_train, X_test = tf.split(tf.random.shuffle(X, seed=42), num_or_size_splits=[40, 10]) def plot_predictions(train_data = X_train, train_labels = y_train, test_data = X_test, test_labels = y_test, predictions = y_pred): """ Plots training data, testing_data """ plt.figure(
Flashcard 7657166081292
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itNote that the model is completely agnostic about further extensions: all individual-level, cohort-level, time-varying, or time-invariant covariates are simply encoded as categorical input variables, and are handled equally by the model
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itPreprocessing data (normalization and standardization) Preprocessing steps: Turn all data into numbers Make sure your tensors are in the right shape Scale features (normalize or standardize) Neural networks tend to prefer normalization. Normalization - adjusting values measured on different scales to a notionally common scale
Original toplevel document
TfC_01_FINAL_EXAMPLE.ipynbape # Create training and test datasets #my way: from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state=42) <span>Preprocessing data (normalization and standardization) Preprocessing steps: Turn all data into numbers Make sure your tensors are in the right shape Scale features (normalize or standardize) Neural networks tend to prefer normalization. Normalization - adjusting values measured on different scales to a notionally common scale Normalization # Start from scratch import pandas as pd import matplotlib.pyplot as plt import tensorflow as tf ## Borrow a few classes from sci-kit learn from sklearn.compose import mak
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itPreprocessing data (normalization and standardization) Preprocessing steps: Turn all data into numbers Make sure your tensors are in the right shape Scale features (normalize or standardize) Neural networks tend to prefer normalization. Normalization - adjusting values measured on different scales to a notionally common scale
Original toplevel document
TfC_01_FINAL_EXAMPLE.ipynbape # Create training and test datasets #my way: from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state=42) <span>Preprocessing data (normalization and standardization) Preprocessing steps: Turn all data into numbers Make sure your tensors are in the right shape Scale features (normalize or standardize) Neural networks tend to prefer normalization. Normalization - adjusting values measured on different scales to a notionally common scale Normalization # Start from scratch import pandas as pd import matplotlib.pyplot as plt import tensorflow as tf ## Borrow a few classes from sci-kit learn from sklearn.compose import mak
Flashcard 7657171324172
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itWhat can visualize? the data model itself the training of a model predictions
Original toplevel document
TfC 01 regressionlarger model Evaluating models Typical workflow: build a model -> fit it -> evaulate -> tweak -> fit > evaluate -> .... Building model: experiment Evaluation model: visualize <span>What can visualize? the data model itself the training of a model predictions ## The 3 sets (or actually 2 sets: training and test set) tf.random.set_seed(999) X_train, X_test = tf.split(tf.random.shuffle(X, seed=42), num_or_size_splits=[40, 10]) def plot_predict
Flashcard 7657173945612
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itHow we can improve model (in the particular stage of the process)? # 2. Compiling: change optimizer or its parameters (eg. learning rate)
Original toplevel document
TfC 01 regression#### How we can improve model # 1. Creating model: add more layers, increase numbers of hidden neurons, change activation functions # 2. Compiling: change optimizer or its parameters (eg. learning rate) # 3. Fitting: more epochs, more data ### How? # from smaller model to larger model Evaluating models Typical workflow: build a model -> fit it -> evaulate -> tweak -> fit > evaluate -> .... Building model: experiment Evaluation model: visualize What
Flashcard 7657176304908
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itMulticlass classification - a sample can be assigned to one label but from more than 2 label options
Original toplevel document
TfC_02_classification-PART_1ms Three types of classification problems: binary classification multiclass multilabel Multilabel classification - a sample can be assigned to more than one label from more than 2 label options <span>Multiclass classification - a sample can be assigned to one label but from more than 2 label options Multiclass image classificaton: pizza, steak, sushi Input_shape = [None, 224, 224, 3] - single image Input shape = [32, 224, 224, 3] - common batch size of images 32 is a common batch s
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itBag of tricks to improve model Create model - more layers, more neurons, different activation Compile mode - other loss, other optimizer, change optimizer parameters Fit the model - more epochs, more data examples
Original toplevel document
TfC_02_classification-PART_1nse(10, activation='relu'), tf.keras.layers.Dense(1, activation='sigmoid') ]) model.compile(optimizer=tf.keras.optimizers.Adam(), loss=tf.keras.losses.binary_crossentropy, metrics=['accuracy']) <span>Bag of tricks to improve model Create model - more layers, more neurons, different activation Compile mode - other loss, other optimizer, change optimizer parameters Fit the model - more epochs, more data examples # plots model predictions agains true data import numpy as np def plot_decision_boundry(model, X, y): """ Take in a trained model, features and labels and create numpy.meshgrid of the d
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itBag of tricks to improve model Create model - more layers, more neurons, different activation Compile mode - other loss, other optimizer, change optimizer parameters Fit the model - more epochs, more data examples
Original toplevel document
TfC_02_classification-PART_1nse(10, activation='relu'), tf.keras.layers.Dense(1, activation='sigmoid') ]) model.compile(optimizer=tf.keras.optimizers.Adam(), loss=tf.keras.losses.binary_crossentropy, metrics=['accuracy']) <span>Bag of tricks to improve model Create model - more layers, more neurons, different activation Compile mode - other loss, other optimizer, change optimizer parameters Fit the model - more epochs, more data examples # plots model predictions agains true data import numpy as np def plot_decision_boundry(model, X, y): """ Take in a trained model, features and labels and create numpy.meshgrid of the d
Flashcard 7657238433036
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Convolution Neural Network - introduction
ata() training_images=training_images.reshape(60000, 28, 28, 1) training_images=training_images / 255.0 model = tf.keras.models.Sequential([ tf.keras.layers.Conv2D(64, (3,3), activation='relu', <span>input_shape=(28, 28, 1)), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(64, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Flatten(), tf.keras.layers.De