Edited, memorised or added to reading queue
on 17-Sep-2024 (Tue)
Do you want BuboFlash to help you learning these things? Click here to log in or create user.
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itAnticipating future customer behavior and making individual-level predictions for a firm’s customer base is crucial to any organization that wants to manage its customer portfolio proactively. <span>More precisely, firms following a customer-centric business approach need to know how their clientele will behave on different future time scales and levels of behavioral complexity (Gupta & Lehmann, 2005; Fader, 2020): What are they going to do in the immediate future and when do they make their next transaction with the focal company, if any? Are some of them at risk of stopping doing business with the firm? How exactly do seasonality and other time-based events influence the propensity of customers to buy? <span>
Original toplevel document (pdf)
cannot see any pdfsFlashcard 7626535079180
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itLSTMs work by learning a function ( f(...) ) that maps input sequence values ( X ) onto output sequence values (y)
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itlso accurately predicts periods of elevated transaction activity and captures other forms of purchase dynamics that can be leveraged in simulations of future sequences of customer transactions. <span>We highlight our model’s flexibility and performance on two groups of valuable customers: those who keep making more and more transactions with the firm (denoted as ”opportunity” customers) and those who are at risk of defection. We demonstrate that the model also excels at automatically capturing seasonal trends in customer activity, such as the shopping period leading up to the December holidays. In Appendix Section F we provide a further characterization of scenarios where our model performs particularly well and where it does not do so relative to the used benchmark methods. </sp
Original toplevel document (pdf)
cannot see any pdfsFlashcard 7626546089228
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itEpoch : One pass through all samples in the training dataset and updating the network weights. LSTMs may be trained for tens, hundreds, or thousands of epochs.
Original toplevel document (pdf)
cannot see any pdfsFlashcard 7626603236620
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itYou can specify the input shape argument that expects a tuple containing the number of time steps and the number of features
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
TfC 01 regression
ing of a model predictions ## The 3 sets (or actually 2 sets: training and test set) tf.random.set_seed(999) X_train, X_test = tf.split(tf.random.shuffle(X, seed=42), num_or_size_splits=[40, 10]<span>) def plot_predictions(train_data = X_train, train_labels = y_train, test_data = X_test, test_labels = y_test, predictions = y_pred): """ Plots training data, testing_data """ plt.figure(figsize=(10, 7)) plt.scatter(train_data, train_labels, c="blue", label='Training data') plt.scatter(test_data, test_labels, c="green", label="Testing data") plt.scatter(test_data, predictions, c="red", label="Predictions") plt.legend(); Common regression evaluation metrics keyboard_arrow_down Introduction For regression problems: MAE tf.keras.losses.MAE() tf.metrics.mean_absolute_error() great starter metrics for any reg
Flashcard 7628320804108
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itSince customer transactions occur sequentially, they can be modeled as a sequence prediction task using an RNN as well, where all firm actions and customer responses are represented by elements in a vector.
Original toplevel document (pdf)
cannot see any pdfsFlashcard 7628323949836
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itHMM == Hidden Markov Model
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itAnzahl von Schnittstellen bzw. Zyklen eingeteilt. Ein Taktzyklus ist die kleinstmöglich verarbeitbare Einheit. Somit benötigt ein Befehl zur Ausführung im Allgemeinen mehr als einen Taktzyklus. <span>Was ist Mikroprogrammierung? Durch Einsatz von Matrix-Speichertechnologie ist es möglich Steuersignalkombinationen in je einer Zeile dieser Speichermatrix abzulegen. Somit können Zeile für Zeile Maschinenzustande auf dem Prozessor hinterlegt werden. Das sogenannte Mikroprogramm. Die interne Logik ist eher zufällig optimiert. Daher der Begriff "Random Logic". Was sind Complex Instruction Set Computer (CISC)? Durch Einführung von mnemonischen Kodierungen von Mikrobefehlen, welche von Mikrobefehls-Assemblern verarbeitet werden, sind weitaus ko
Original toplevel document
Grundprinzipien der Rechnerarchitekturon Kapitel 8 - Superskalarität Kapitel 9 - Parallelrechner Zurück zur Übersicht Rechnerarchitektur Grundprinzipien der Rechnerarchitektur. D.h. Themen wie RISC, Branch Prediction oder Tomasulo. <span>Kapitel 1 - Prinzipien und Architekturen In welche sieben Ebenen kann man ein Rechnersystem einteilen? Anwendungsebene (Anwendersoftware) Assemblerebene (Beschreibung von Algorithmen, Link & Bind) Betriebssystem (Speichermanagment, Prozesskommunikation) Instruction Set Architecture (ISA,Adressierungsarten) Microarchitektur (Risc,Cisc,Branch Prediction..) Logische Ebene (Register,Schieber, Latches..) Transistorebene (Transistoren, MOS ) nach Tanenbaum Computerarchitektur Wie lassen sich Architekturen klassifizieren? Nach ihrem Rechenprinzip Von Neumann (Steuerfluss) Datenfluß (Zündregel) Reduktion (Funktionsaufruf) Objektorientiert (Methodenaufruf) Nach dem Architektur-Grundkonzept Vektorrechner (Pipeline) Array-Computer (Data-Array) Assoziativ-Rechner (Assoziativ-Speicher) Wie kann die Leistung erhöht werden? Über die Architektur Pipelines, Superskalarität, Spekulative Ausführung, Caches, Busbreite Über Optimierung von Software Compileroptimierung Über die Siliziumbasis Transistordichte und Taktraten Was sind die vier Hauptbestandteile eines typischen Rechners? Was unterscheidet eine Schnittstelle von einem Bus? Ein Bus verbindet mehr als zwei Teilnehmer. John von Neumann mit ENIAC Welche Bestandteile definieren einen von Neumann-Rechner? Der von Neumann-Rechner arbeitet sequentiell, Befehl für Befehl wird abgeholt, interpretiert, ausgeführt und das Resultat abgespeichert. Steuerwerk (Taktgeber und Befehlszähler) Speicher Rechenwerk (CPU) I/O-Einheit Datenbreite, Adressierungsbreite, Registeranzahl und Befehlssatz können als Parameter verstanden werden. Wie arbeitet die zentrale Befehlsschleife eines Von-Neumann-Rechners? Was heißt Havard-Architektur? Daten- und Befehlsspeicher sind getrennt. So ist es möglich Daten und Befehle Zeitgleich aus dem Speicher zu holen. Da dies aber einen extrem hohen Aufwand bedeutet, wird dies nur bei Echtzeitanwendungen implementiert. Was ist ein Taktzyklus? Die Interpretation und Ausführung eines Befehles erfolgt in vier Phasen. Holen Dekodieren (inklusive Operandenadressen berechnen) Daten holen (bzw. Operanden) Ausführen Jede der vier Phasen wird in eine Anzahl von Schnittstellen bzw. Zyklen eingeteilt. Ein Taktzyklus ist die kleinstmöglich verarbeitbare Einheit. Somit benötigt ein Befehl zur Ausführung im Allgemeinen mehr als einen Taktzyklus. Was ist Mikroprogrammierung? Durch Einsatz von Matrix-Speichertechnologie ist es möglich Steuersignalkombinationen in je einer Zeile dieser Speichermatrix abzulegen. Somit können Zeile für Zeile Maschinenzustande auf dem Prozessor hinterlegt werden. Das sogenannte Mikroprogramm. Die interne Logik ist eher zufällig optimiert. Daher der Begriff "Random Logic". Was sind Complex Instruction Set Computer (CISC)? Durch Einführung von mnemonischen Kodierungen von Mikrobefehlen, welche von Mikrobefehls-Assemblern verarbeitet werden, sind weitaus komplexere Befehle möglich. CISC bietet einen sehr großen Befehlssatz mit sich start unterscheidenden Befehlen in Ausführungszeit und Parameterliste. Gegenüberstellung der Architektur von CISC und RISC Worin unterscheiden sich RISC und CISC besonders? Eigenschaften CISC RISC Register Wenige Register( ca. 20) Viele Register (bis zu 200) und Registerfenster Befehlssatz ca. 300 Befehle und mehr als 50 Befehlstypen Nur rund 100 meist registerorientierte Befehle (außer LOAD / STORE) Adressierungsarten ca. 12 verschiedene Nur 3 bis 5 Arten und nur LOAD/STORE zum Speicher Caches Gemeinsame Caches, aber später auch Getrennte Getrennte Daten- und Befehlscaches nach Harvard CPI 1 bis 20 - Durchschnittlich 4 1 bei Basisoperationen - im Schnitt 1,5 Befehlssteuerung Mikrocode im Speicher, aber auch hartverdrahtet Meistens hartverdrahtete Mikroprogramme ohne Mikroprogrammspeicher Beispielprozessoren Intel x86, AMD, Cyrix Sun UltraSparc, PowerPC Welche Befehlssatz-Architekturen kennen Sie? Stack-Architektur? Diese Form benötigt keine Adressen für Operanden und ist somit eine Nulladressmaschine. Quell und Ergebnisoperanden liegen auf einem Operanden-Stack. Vorteil dieser Architektur ist daher die Speicherplatzeinsparung durch die nicht notwendigen Adressen. Akkumulator-Architektur? Um Verknüpfungsoperationen durchzuführen, liegt ein Operand in einem Register und ein Operand typischerweise im Hauptspeicher (Einadressmaschine) . Vorteil ist die einfache Implementierung, da nur ein internes Register benötigt wird. Nachteil ist aber die hohe Speicherlast. Universalregister-Architektur? Ein Satz von gleichberechtigten Registern kann zum Ablegen von Daten genutzt werden. Deshalb sind im Op-Code mehrere Operanden anzugeben (Zwei-, Dreiadressmaschine etc.) Vorteil ist die freie Benutzbarkeit durch Compiler. Ausdrucksberechnungen können somit in beliebiger Reihenfolge erfolgen, was Pipelining möglich macht. Dazu kommt, daß die Speichertransferlast sinkt, die Geschwindigkeit steigt und Superskalartechniken sind effizient einsetzbar. Der Nachteil dieser Architektur sind die teilweise großen Registersets, welche bei jedem Kontextwechsel auszutauschen sind. Außerdem müssen die Operanden Adressiert werden, was zu langen Befehlen führt. Welche Register-Architekturen gibt es? Register-Register ohne Speicheradressen (Sparc,Mips) Verknüpfungsoperationen verwenden nur Register. Nur in Lade- und Speicherbefehlen werden Adressen verwendet. (Load / Store - Architektur). Vorteil ist, dass die Verknüpfungen immer mit Registern geschehen und somit eine Befehlsdekodierung mit fester Länge möglich ist. Vorteile Einheitliche Taktzyklen pro Befehl Pipeline-Prinzip wird dadurch unterstützt Nachteile Code wird größer, da Speichertransfers nur durch zusätzliche Befehle Register-Speicher mit der Möglichkeit von Speicheradressen (Motorola 68000) Vorteile Daten können auch im Speicher referenziert werden, ohne diese vorher Explizit laden zu müssen. Nachteile Durch die variierenden Adressierungen variieren Befehlslänge und Taktzyklen pro Befehl, was äußerst negativ für Verfahren wie Pipelining ist. Speicher-Speicher mit nur Speicheradressen (DEC-VAX) Vorteile Der Programmierer braucht sich nicht um Register kümmern. Deshalb wird die Programmierung transparenter. Nachteile Es entsteht ein hoher Speicherverkehr, was sich Nachteilig auf die Performance auswirkt. Falls doch Register erlaubt werden (Orthogonaler Befehlssatz / CISC), variieren auch hier Befehlslänge und Taktanzahl pro Befehl. Orthogonale Befehlssätze sind solche, welche eine beliebige Kombination von Befehlscode, Adressierungsart und Datentyp zulassen. Was ist Byte-Ordering und Word-Alignment? Alle konventionellen Rechner sind Byte-Adressiert. D.h. das Worte (egal ob 8, 16 oder mehr Bit) bestehen aus einer Folge (aufsteigender) Bytes. Dabei gilt das erste Byte als die Adresse des Wortes. Nimmt die Wertigkeit mit aufsteigender Adresse zu, ist es das Litte-Endian-Format, umgekehrt das Big-Endian-Format. Falls Worte so in den Speicher passen, das keine Verschiebungen auftreten, heißt der Speicher aligned. Prüfen kann man dies durch die Formel Adresse mod Wortlänge = 0? Kapitel 2 - Interrupts und DMA Klassifizieren Sie die verschiedenen Unterbrechungen! Wenn in der Literatur von Interrupts gesprochen wird, so werden oft externe, asynchrone Interrupts g
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itWarum wird DMA oft Interrupts vorgezogen? Zwar befreien Interrupts die Prozessoren vom Warten auf E/A Ereignisse, aber vektorisierte Interrupts benötigen viele Taktzyklen zu ihrer Abarbeitung. Dieser Overhead steigt natürlich, um so weniger Datenmengen bei einer Interruptauslösung übertragen werden. Interrupts werden erst nach der Befehlsabarbeitung erkannt und ausgeführt. Dies ist ein Problem bei Echtzeitanwendungen, da sich diese Verzögerung negativ auswirken kann. Außerdem kommt es durch Interrupts bei Instruction-Set-Parallismus oft zu Pipeline-Neustarts. Die Lösung dieser Probleme wäre ein direkter Speicherzugriff eines Devices, da so der Prozessor komplett umgangen werden kann. Wie kann DMA implementiert werden? Zentral Ein zentraler DMA-Controller steht allen Geräten zu Verfügung. Dezentral: Jede E/A-Einheit hat ihren eigenen DMA-Controller implementiert und
Original toplevel document
Grundprinzipien der Rechnerarchitekturrt das Big-Endian-Format. Falls Worte so in den Speicher passen, das keine Verschiebungen auftreten, heißt der Speicher aligned. Prüfen kann man dies durch die Formel Adresse mod Wortlänge = 0? <span>Kapitel 2 - Interrupts und DMA Klassifizieren Sie die verschiedenen Unterbrechungen! Wenn in der Literatur von Interrupts gesprochen wird, so werden oft externe, asynchrone Interrupts gemeint, welche meistens in Zusammenhang mit E/A-Geräten auftreten. Wie arbeiten Traps (Fangstellen?) Traps sind eine Art automatische Prozeduraufrufe, welche durch eine vom Programm verursachte Bedingung eingeleitet werden. Solch eine Bedingung kann z.B. Gleitkommaüberlauf, Schutzverletzung oder Stapelüberlauf. Findet ein Überlauf statt, so stoppt die Ablaufsteuerung die Ausführung und holt von einer bestimmten Stelle im Speicher die Adresse des Trap-Handlers (Prozedur), mit der dann der Programmcounter überschrieben wird. Wesentliches Merkmal eines Traps ist, daß es durch Ausnahmebedingungen ausgelöst wird, welche durch Hardware oder Mikroprogramme erkannt werden. Wie arbeiten Interrupts Interrupts sind Unterbrechungen der Ablaufsteuerung. Wie es für Traps Trap-Handler gibt, gibt es für Interrupts Interrupt-Handler. Nach Abarbeitung des Interrupt-Handlers wird die Kontrolle wieder an das Programm zurückgegeben. Der interne Zustand des Prozessors (IP, Register, ...) muss nun exakt wiederhergestellt werden. Der Unterschied zwischen Traps und Interrupts ist nun, daß Traps synchron mit dem ausgeführten Programm laufen. Deshalb werden sie auch erst nach der Befehlsausführung erkannt und ausgeführt. Asynchrone Interrupts sind dagegen unabhängig vom gerade ausgeführten Programm. Interrupt’s stammen von echten physikalischen INT-Quellen wie z.B. IRQ3 von COM1 kommt. Diese springen über ein Interrupt-Gate. Interrupt’s die per Software mit INT-Befehl ausgelöst werden, springen über Trap-Gates! Wenn ein Interrupt ein Interrupt-Gate durchläuft, wird das IF=0 automatisch gesetzt, d.h. es gehen überhaupt keine Interrupts mehr durch. Asynchrone Interrupts können also nicht unterbrochen werden. Trap-Gates dürfen unterbrochen werden, da sie nicht zeitkritisch sind. Interrupt- und Trap-Gates führen nicht zu Taskwechsel über ein TSS. Das retten der Register ist dem INT-Handler überlassen. Was sind Software Interrupts? Software-Interrupts werden von Programmen mit Hilfe von speziellen Maschinenbefehlen aufgerufen. Dabei müssen diese nur eine Nummer für das benötigte Interrupt kennen. Über diese Nummer wird in der Interrupt-Vektor-Tabelle die Adresse des Interrupt-Unterprogrammes (ISR) referenziert und ausgeführt. Was versteht man unter internen und externen Interrupts? Externe Interrupts sind asynchron, wie nichtvektorisierte und vektorisierte Interrupts. Interne sind synchron, wie Software Interrupts oder Exection-Traps (Reaktionen auf interne Fehler wie FPU-Errors oder Page-Faults). Was ist Polling? Polling ist das zyklische Abfragen von einen oder mehreren E/A-Devices zur Feststellung der Kommunikationsbereitschaft bzw. zum Einholen von Kommunikationswünschen. Vorteile des Pollings Nachteile des Pollings Einfach zu Implementieren Hoher Programm-Overhead Kommunikationsanforderungen erfolgen synchron zum Programmablauf Die meisten Anfragen an die Geräte sind unnötig Je mehr Geräte am Bus hängen, um so mehr steigt Reaktionszeit. Priorisierung bei zeitgleichen Anfragen erfordert zusätzlichen Zeitaufwand Aufgrund der vielen Nachteile sollte besser eine asynchrone Kommunikation mit den Geräten durch die Hardware unterstützt werden (Interrupts). Das Interrupt-Prinzip Es kann auch über eine Art "hardware-gestütztes Polling" über spezielle Interrupt-Signalleitungen eine Kommunikationsanforderung festgestellt werden. Dazu muss aber die Befehlsverarbeitungschleife um eine Unterbrechungsanfrage erweitert werden. Erklären Sie den Unterschied zwischen vektorisierten und nichtvektorisierten Interrupts! Man unterscheidet vektorisierten und nichtvektorisierten Interrupt. Bei nichtvektorisierten Interrupts wird dem Interruptsignal eine feste Adresse zugeordnet. Bei vektorisierten Interrupts wird dynamisch eine wahlfreie Adresse zugeordnet, welche durch die CPU über ein definiertes Protokoll vom Datenbus gelesen wird. Was passiert beim Auftreten eines Interrupts? 1. Sperren weiterer Unterbrechungen mit gleicher oder geringerer Priotität Unterbrechungen mit höherer Wichtigkeit dürfen normalerweise solche mit geringerer Wichtigkeit wieder unterbrechen 2. Rettung wichtiger Register-Informationen(Prozessorstatus) alle Prozessor-Register retten, die durch die Interruptbehandlung überschrieben würden heute gibt es dafür spezielle Maschinenbefehle 3. Bestimmen der Interruptquelle (durch Hardware realisiert) 4. Laden des zugehörigen Interruptvektors d.h. das Herstellen des Anfangszustandes für gewählte Interruptroutine 5. Abarbeitung der Interruptroutine Retten weiterer Zustandsinformationen, sofern nicht durch Hardware realisiert meistens Übernahme weiterer Parameter von definierten Stellen (bei Systemaufruf Ruf-Nr. und weitere Parameter oder bei Geräte-Interrupt Gerätestatusbits wie E/A Fortschritt, Fehler etc.) eigentliche Behandlung des Interrupts, z.B. Setzen eines Flags (z.B. bei Gleitkommaüberlauf oder Aufruf zum Rückpositionieren und erneutem Lesen bei Lesefehler bei Magnetbandkassette (komplizierterer Fall) 6. Rückkehr zur unterbrochenen Aufgabe entweder Rückspeichern der geretteten Registerinformationen, d.h. Wiederherstellen des Prozessorzustandes oder Bearbeitung einer neuen Aufgabe, z.B. bei Uhrinterrupt nach Ablauf einer Zeitscheibe oder Zustand "HALT" nach schwerem Fehler, z.B. Spannungsausfall (abort) Welche beiden Zustandssicherungskonzepte gibt es totale Sicherung aller bislang nicht automatisch gesicherten Register der CPU-Status des unterbrochenen Programms wird komplett eingefroren auch die invarianten Anteile werden gesichert, der Programmzustand ist damit leicht zugreifbar weit verbreitet bei Allzweckbetriebssystemen (z.B. UNIX & Co.) partielle Sicherung der im weiteren Verlauf nicht gesicherten Register der CPU-Status des unterbrochenen Programms wird teilweise eingefroren es wird nur der wirklich von Änderungen betroffene Anteil gesichert der Programmzustand ist damit nicht leicht zugreifbar weit verbreitet bei Spezialzweckbetriebssystemen Was stellt das Hauptproblem bei Interrupts dar Interrupts verhalten sich nicht deterministisch. D.h. ihre Abarbeitungszeit variiert. Sie sollte trotzdem so gering wie möglich gehalten werden. Warum wird DMA oft Interrupts vorgezogen? Zwar befreien Interrupts die Prozessoren vom Warten auf E/A Ereignisse, aber vektorisierte Interrupts benötigen viele Taktzyklen zu ihrer Abarbeitung. Dieser Overhead steigt natürlich, um so weniger Datenmengen bei einer Interruptauslösung übertragen werden. Interrupts werden erst nach der Befehlsabarbeitung erkannt und ausgeführt. Dies ist ein Problem bei Echtzeitanwendungen, da sich diese Verzögerung negativ auswirken kann. Außerdem kommt es durch Interrupts bei Instruction-Set-Parallismus oft zu Pipeline-Neustarts. Die Lösung dieser Probleme wäre ein direkter Speicherzugriff eines Devices, da so der Prozessor komplett umgangen werden kann. Wie kann DMA implementiert werden? Zentral Ein zentraler DMA-Controller steht allen Geräten zu Verfügung. Dezentral: Jede E/A-Einheit hat ihren eigenen DMA-Controller implementiert und kann selbst Busmaster werden Probleme bei DMA treten vor allem durch ihre Unabhängigkeit und die dadurch notwendigen Schutzmaßnahmen auf. Ein DMA-Controller wirkt wie ein weiterer Prozessor am Bus. Um Inkonsistenzen im Speicher zu vermeiden, muss ein DMA-Controller eng mit dem Speichermanagment des Systems zusammenarbeiten. Was ist Memory-Mapped I/O? Ein I/O Controller besteht aus einer Vielzahl von Registern, welche auf zwei Varianten adressiert werden können: Memory-Mapped I/O, um den konventionellen Adr
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itWas ist Forwarding? Beim Forwarding wird ein Bypass eingerichtet, welcher ein Ergebniss einer Operation schon einem Folgebefehl zur Verfügung stellt, bevor es überhaupt in ein Register geschrieben wurde. Aber trotz Load-Forwarding hat ein Ladebefehl eine Verzögerung, welche nicht gänzlich eliminiert werden kann. In diesem Fall kann die Delayed-Load Technik oder auch eine Befehlsumordnun
Original toplevel document
Grundprinzipien der Rechnerarchitektureinen Verweis auf die Nächste enthalten. Sprünge sind einfach möglich. Angewandt wird dies in Form von Opcodes, welche nichts anderes als Adressen auf Mikroinstruktionen im Steuerspeicher sind. <span>Kapitel 6 - Pipelining Wozu dient Pipelining? Pipelining soll es ermöglichen Befehle überlappt auszuführen. Dazu sind ein einheitliches Befehlsformat fester Länge Grundlage. Deshalb werden werden nur auf Register getätigt. Für Speicheroperationen wird die LOAD / STORE Philosophie verfolgt, um langsame Hauptspeicherzugriffe zu minimieren. Was ist Voraussetzung für Pipelining? Die Befehlsverarbeitungsphase muss sich in mehrere voneinander unabhängige Phasen unterteilen lassen. Die einfachste Form einer Pipeline ist die 5-stufige mit folgenden Phasen: Befehl holen Befehl dekodieren Befehl ausführen Auf Speicher zugreifen Ergebnis in Register schreiben Moderene CPU's haben weitaus komplexere Pipelines, in denen die einzelnen Stufen wiederrum in mehrere sich überlappende Phasen aufgeteilt werden. Der allgemeine Aufbau einer (fünfstufigen) Pipeline Um Parallelität in der Befehlsausführungsphase zu erreichen, wird der Datenpfad so konstruiert, daß folgende (hier fünf) Phasen unabhänig voneinander arbeiten können. Nur so ist es möglich eine verzahnte Abarbeitung mehrerer Befehle zu erreichen. Abb.: Die Piplelinestufen Somit wird ,nachdem eine Pipeline gefüllt ist, im Optimalfall pro Takt ein Befehl fertig. (CPI = 1) Welche Pipeline-Konflikte müssen behandelt werden? Datenabhängigkeiten (Data Hazards) Sind logische Abhängigkeiten, welche eine verzögerte Abarbeitung erfordern, weil z.B. ein Folgebefehl auf ein Ergebnis eines anderen Befehles warten muss. Jump- / Branchverzögerungen (Control Hazards) Bei Sprungbefehlen liegt oft das Sprungziel nach der Dekodieung noch nicht fest. Somit müssen Techniken eingesetzt werden um diese Wartezeiten zu minimieren. (Branch Prediction) Ressourcenkonflikte (Structural Hazards) Bei bestimmten Befehlskombinationen ist es unter Umständen möglich, daß ein Teilwerk seine Arbeit wiederholen muss. Solche Ressourcenkonflikte treten dann auf, wenn nicht jeder Teilphase völlig unabhängige Teilwerke zugeordnet sind. Ein Beispiel ist z.B. ein zeitgleicher Lesezugriff eines LOAD/STORE Befehles, welcher sich zwangsweise mit einem eventuellen MEM ACCESS eines anderen Befehles überschneidet. Abhilfe können hier Dual-Port RAM, Havard-Architektur oder getrennte Code- und Datencaches schaffen. Welche drei verschiedenen Datenabhängigkeiten gibt es? RAW, WAW und WAR-Konflikte sind Datenabnhänigkeiten, welche in Pipelines auftreten können. Dabei ist das RAW-Problem für Pipelines typisch. WAR Konflikte treten eher bei Out-Of-Order Execution auf. Um Read-After-Write Konflikte aufzulösen, gibt es verschiedene Ansätze wie Softwarelösungen ( Compileroptimierung), Scoreboarding (zentrale Steuerlogik) und Forwarding (zusätzlicher Datenpfad). Was ist Forwarding? Beim Forwarding wird ein Bypass eingerichtet, welcher ein Ergebniss einer Operation schon einem Folgebefehl zur Verfügung stellt, bevor es überhaupt in ein Register geschrieben wurde. Aber trotz Load-Forwarding hat ein Ladebefehl eine Verzögerung, welche nicht gänzlich eliminiert werden kann. In diesem Fall kann die Delayed-Load Technik oder auch eine Befehlsumordnung Anhilfe schaffen. Was ist die Delayed Load-Technik? Bei der Delayed Load-Technik wird die Verzögerung nach einem LOAD Befehl als architektonisches Merkmal angesehn und den Compilerbauern offengelegt. Diese können nun durch Befehlsumordnungen versuchen, nach einem LOAD-Befehl einen datenunabhängigen Befehl einzufügen, um den Slot zu füllen. Zusammenfassung Pipelining Pipelines werden in allen modernen CPUs benutzt. Die UltraSparc2 hat neun und der P2 zwölf Stufen. Der Intel Pentium Itanium weißt eine 20 stufige Superpinepline (pipeline in der sich einzelne Stufen überlappen können) auf! Pipes werden heutzutage in Kombination mit der Superskalartechnik verwendet, um höchste Effizienz und Parallelverarbeitung gewährleisten zu können. Die fünf grundlegenden Stufen einer einfachen Pipeline sind IF,ID,EX,MEM und WB. Takte T = Befehle + (Pipestufen - 1) Folgende Abhängigkeiten verhindern, dass die CPI auf eins gehen: Strucual Hazards bzw. Ressourcenkonflikte IF und MEM wollen gleichzeitig auf Speicher lesend oder schreibend zugreifen. Das geht nicht, außer bei Dual-Port-RAM, welcher aber sehr teuer ist. Dieses Problem tritt aber bei modernen CPU's kaum noch auf, da eh intern eine Havard-ähnliche Architektur mit getrenntem Befehls- und Datencache gearbeitet wird. Data Hazards bzw. Datenabhängigkeiten Ein Folgebefehl wartet auf das Writeback der darüber liegenden Pipe, da er von diesem Befehl abhängig ist. Dies kann durch Nops bzw. Stalls ineffizient gelöst werden. Besser der Programmierer oder der Compiler löst diese Abhängigkeiten durch eine clevere Umordnung der Befehlsfolge auf. Es gibt aber noch eine andere Möglichkeit, welche aber hardwareseitig unterstützt werden muss. (VLIW, Superskalar) Forwarding Beim Forwarding werden Ergebnisse, sobald sie vorliegen an die nächste Stufe weitergereicht und nicht erst auf das Write Back gewartet. In anderen Worten: Das Ergebnis der ALU wird dieser sofort wieder eingespeist. Control Hazards bzw. Sprungverzögerungen Sprungergebnisse stehen erst in der Write Back Phase an. Moderne Prozessoren haben aber schon in der Fetch/Decode-Einheit eine Logik, welche die Zieladresse des Sprunges berechnet. Eine andere Möglichkeit ist die des spekulativen Ausführens. Hier tritt aber das Problem auf, dass viel Aufwand bei falscher Spekulation getrieben werden muss. Was ist der Unterschied zwischen echten und unechten Datenabhängigkeiten? Echte Datenabhängigkeiten sind RAW-Konflikte, bei dem ein Befehl auf die Beendigung eines Anderen warten muss, da er das Ergebnis als Operand benötigt. Unechte Datenabhängigkeit sind Abhängigkeiten, welche nur durch Namensabhängigkeit entstehen. Es gibt zwei Arten unechter Datenabhängigkeit: Antidependence sind WAR-Konflikte, welche entstehen, wenn ein Folgebefehl auf ein Register schreiben möchte, das noch von einem Anderen benutzt wird. Output Dependece sind WAW-Konflikte, welche entstehen, wenn mehrere Befehle auf ein und das selbe Register schreiben. Hier muss sichergestellt werden, daß die Schreibreihenfolge der der Befehle entspricht. Beide Abhängigkeiten können durch Register Renaming vermindert werden! Kapitel 7 - Branch Prediction Control Hazards (Jump / Branch Problematik) Sprungbefehle stellen einen Dorn im Auge einer jeden Pipeline dar, da diese besondere Vorkehrungen erfordern. D
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itDas Scoreboard Ein Scoreboard ist eine zusätzliche Steuereinheit, welche die Verantwortung für das Befehlsaussenden und das Erkennen von Konflikten trägt. Das Scoreboard wählt aus einem Pool potentiel ausführbarer Befehle (Instruction Window) einen Satz von Befehlen aus. Ein Register wird als ungültig markiert, wenn die Dekodiereinheit erkannt hat, dass ein Befehl sein Ergebnis in dieses Register schreiben möchte. So wird verhindert, dass ein anderer Befehl dieses Register liest, solange es ungültig ist. Nachteil ist, daß keine Ressourcen- und auch keine Datenabhängigkeiten auftreten dürfen. Eine bessere Variante ist die Tomasulo-Methode, welche eine Auflösung von WAR- und WAW-Konflikten ermöglicht. Zusammenfassend gesagt, besteht ein Scoreboard aus einer Vielzahl von Zählern (wie oft wurde gelesen und geschrieben) für die verwendeten Register und Funktionseinheiten. Ein Scoreboard, welches auch WAR und WAW Konflikte lösen kann, wäre zwar extrem aufwendig aber möglich. Wann können Befehle mit der Scoreboard Technik nicht ausgesandt werden? Wenn ein aktueller Operand geschrieben wird (RAW) Wenn das Ergebnisregister gelesen wird (WAR) Wenn das Ergebnisregister geschrieben wird (WAW) WAR und WAW sind weniger schwerwiegend als RAW Abhängigkeiten, da diese nur Ressourcenkonflikte darstellen. RAW Konflikte logische Abhängigkeiten und können nicht so einfach aufgelöst werden. Mit der Scoreboard Methode muss gewartet werden, bis der abhängige Vorgängerbefehl sein Ergebnis geschrieben hat. Erst dann kann der Folgebefehl das benötigte Datum lesen und mit der Abarbeitung fortsetzen. Lösen lassen sich alle Probleme mit Out-Of-Order Execution und Register Renaming Technik. Dazu muss das Scoreboard erweitert werden. Die Tomasulo-Methode Hauptidee sind hier sogenannte Reservation Stations, welche eine Art Zwischenpuffer für Operanden darstellen. Die Reservation Stations besitzen eine eindeutige ID,
Original toplevel document
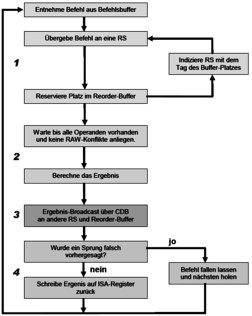
Grundprinzipien der Rechnerarchitekturen parallel ausführbar sind, ist nun nicht mehr so viel Chipfläche zum Auflösen von Hazards notwendig und kann z.B. für mehr Register verwendet werden. Abb.: Prinzip VLIW mit drei Superbefehlen <span>Das Scoreboard Ein Scoreboard ist eine zusätzliche Steuereinheit, welche die Verantwortung für das Befehlsaussenden und das Erkennen von Konflikten trägt. Das Scoreboard wählt aus einem Pool potentiel ausführbarer Befehle (Instruction Window) einen Satz von Befehlen aus. Ein Register wird als ungültig markiert, wenn die Dekodiereinheit erkannt hat, dass ein Befehl sein Ergebnis in dieses Register schreiben möchte. So wird verhindert, dass ein anderer Befehl dieses Register liest, solange es ungültig ist. Nachteil ist, daß keine Ressourcen- und auch keine Datenabhängigkeiten auftreten dürfen. Eine bessere Variante ist die Tomasulo-Methode, welche eine Auflösung von WAR- und WAW-Konflikten ermöglicht. Zusammenfassend gesagt, besteht ein Scoreboard aus einer Vielzahl von Zählern (wie oft wurde gelesen und geschrieben) für die verwendeten Register und Funktionseinheiten. Ein Scoreboard, welches auch WAR und WAW Konflikte lösen kann, wäre zwar extrem aufwendig aber möglich. Wann können Befehle mit der Scoreboard Technik nicht ausgesandt werden? Wenn ein aktueller Operand geschrieben wird (RAW) Wenn das Ergebnisregister gelesen wird (WAR) Wenn das Ergebnisregister geschrieben wird (WAW) WAR und WAW sind weniger schwerwiegend als RAW Abhängigkeiten, da diese nur Ressourcenkonflikte darstellen. RAW Konflikte logische Abhängigkeiten und können nicht so einfach aufgelöst werden. Mit der Scoreboard Methode muss gewartet werden, bis der abhängige Vorgängerbefehl sein Ergebnis geschrieben hat. Erst dann kann der Folgebefehl das benötigte Datum lesen und mit der Abarbeitung fortsetzen. Lösen lassen sich alle Probleme mit Out-Of-Order Execution und Register Renaming Technik. Dazu muss das Scoreboard erweitert werden. Die Tomasulo-Methode Hauptidee sind hier sogenannte Reservation Stations, welche eine Art Zwischenpuffer für Operanden darstellen. Die Reservation Stations besitzen eine eindeutige ID, welche jedem Befehl mitgegeben wird. So kann die richtige Reihenfolge beibehalten werden. Wird ein Befehl ausgeführt, arbeitet dieser nicht auf den eigentlichen Registern, sondern auf den assoziierten Reservation Stations, was das Prinzip des schon erwähnten Register Renamings ist. Über einen Common Data Bus werden die Ergebnisse zu allen beteiligten Einheiten gebroadcaset. Reservation Stations erkennen Hazards und können selbst entscheiden, wann sie den dazugehörigen Befehl ausführen. Nämlich erst dann, wenn alle Operanden vorliegen. Um controll stalls komplett vermeiden zu können, wird die Tomasulo-Methode mit der spekulativen Befehlsausführung kombiniert. Wie arbeitet die spekulative Befehlsausführung? Sprungziel-Befehle werden schon ausgeführt, wenn das Ergebnis des Sprungtests noch gar nicht vorliegt. Somit muss es die Möglichkeit geben, bei falscher Vorhersage alle Änderungen zu Verwerfen (Rollback-Fähigkeit). Die Hauptsächliche Hardware-Erweiterung liegt in der Aufspaltung der Ergebnisschreibphase in eine Bereitstellungsphase mit Zwischenspeicherung im Reorder Buffer und eine Phase in der ein Befehl commited, d.h. gänzlich der Ausführung übergeben wird. Ein commit bedeutet, daß eine eventuelle Sprungvorhersage richtig war! Somit stellt dies eine Kombination von out-of-order-execution via Tomasulo mit einem erzwungenen in-order-commit dar. Der Reorder-Buffer stellt in der Welt des Tomasulo weitere Register zur Verfügung, welche auch die Funktion von Store Buffern übernehmen könnten, so daß dieser als Teil des Tomasulo nicht direkt mehr erkennbar wäre. (Store Buffer enthalten Informationen darüber, welche Reservation Stations, welches Ergebnis erwartet) Aus welchen Feldern setzt sich ein Reorder-Buffer-Eintrag zusammen? Befehlstyp (Branch, Store oder Registeroperaton) Zielfeld (Registernummer oder Speicheradresse) Datenfeld (Ergebnis der Operation) Die Phasen des Tomasulo Fetch und Decode Holt Instruktionen in einen Befehlscache. Die Decode-Unit holt sich einen Teil der Befehle und versucht mehrere gleichzeitig zu decodieren (In-Order). Dabei wird versucht Sprünge vorherzusagen. Übergibt dekodierten Befehle in der richtigen Reihenfolge an die Dispatch (Issue) Unit. Dispatch / Issue Holt dekodierte Befehle aus Befehlspuffer und übergibt sie In-Order an die Reservation Stations der Execute Units, sobald alle Operanden verfügbar sind (Issue). Solange im Reorder Buffer Platz ist, reserviert sie ein Feld für diesen Befehl mit Hilfe des Tags und gibt dieses an die RS weiter. Wenn nicht wartet sie, bis ein Platz frei wird. (Dispatch Phase) Execution Führt Befehle auf den Schattenregistern aus, um Data Hazards zu meiden. Befehle werden in den Reorder-Buffer geschrieben und Out-Of-Order ausgeführt, solange es keine RAW-Konflikte gibt. Nach Beenden eines Befehls wird Ergebnis an alle RS gebroadcastet, so dass wartende Befehle fortfahren können. (Write result) Commit Die Commit/Completion oder Retire Einheit schreibt die Ergebnisse aus den Renaming Registern in die echten ISA Register zurück, nachdem sie geprüft hat, ob abhängige vorangehende Befehle ihre Ergebnisse geliefert haben und keine falsche Sprungvorhersage eingetreten war. Erklären Sie die Phasen Issue, Execute, Write Result und Commit! Die Issue-Phase entnimmt einen Befehl aus dem Befehlsbuffer und versucht diesen an eine freie Reservation Station zu übergeben. Dabei reserviert sie einen Platz im Reorder-Buffer und gibt den dazugehörigen Tag an die Reservation Station. So kann beim Ergebnis-Broadcasting das Ergebnis mit diesem Tag gekennzeichnet werden. (1) Sind nun alle notwendigen Operanden vorhanden und keine weiteren RAW-Abhängigkeiten bestehen, kann der Befehl ausgeführt werden. (Execute-Phase). (2) Ist das Ergebniss berechnet, wird es auf den CDB gelegt und in den Reorder-Buffer geschrieben (Write Result). (3) Der Reorder-Buffer ist als Ringbuffer angelegt, bei dem die Reihenfolge der Befehle, durch die der erwarteten Ergebnisse (über das verliehene Tag) definiert wird. Nun werden in der Commit-Phase falsch vorhergesagte Sprünge zurückgesetzt und es wird bei dem richtigen Nachfolgebefehl fortgesetzt. Das Ergeniss wird in die ISA Register zurückgeschrieben. (4) Abb.: abstrahierter RIST-Kern eines Pentium Pro / Power PC Muliple Issue am Beispiel Instruktionen werden in eine oder mehrere Mikrooperationen dekodiert und in eine Warteschlange gestellt. Sprungerkennung erfolgt erst statisch und dann dynamis
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itas benötigte Datum lesen und mit der Abarbeitung fortsetzen. Lösen lassen sich alle Probleme mit Out-Of-Order Execution und Register Renaming Technik. Dazu muss das Scoreboard erweitert werden. <span>Die Tomasulo-Methode Hauptidee sind hier sogenannte Reservation Stations, welche eine Art Zwischenpuffer für Operanden darstellen. Die Reservation Stations besitzen eine eindeutige ID, welche jedem Befehl mitgegeben wird. So kann die richtige Reihenfolge beibehalten werden. Wird ein Befehl ausgeführt, arbeitet dieser nicht auf den eigentlichen Registern, sondern auf den assoziierten Reservation Stations, was das Prinzip des schon erwähnten Register Renamings ist. Über einen Common Data Bus werden die Ergebnisse zu allen beteiligten Einheiten gebroadcaset. Reservation Stations erkennen Hazards und können selbst entscheiden, wann sie den dazugehörigen Befehl ausführen. Nämlich erst dann, wenn alle Operanden vorliegen. Um controll stalls komplett vermeiden zu können, wird die Tomasulo-Methode mit der spekulativen Befehlsausführung kombiniert. Wie arbeitet die spekulative Befehlsausführung? Sprungziel-Befehle werden schon ausgeführt, wenn das Ergebnis des Sprungtests noch gar nicht vorliegt. Somit muss es die Möglichkeit geben, bei falscher Vorhersage alle Änderungen zu Verwerfen (Rollback-Fähigkeit). Die Hauptsächliche Hardware-Erweiterung liegt in der Aufspaltung der Ergebnisschreibphase in eine Bereitstellungsphase mit Zwischenspeicherung im Reorder Buffer und eine Phase in der ein Befehl commited, d.h. gänzlich der Ausführung übergeben wird. Ein commit bedeutet, daß eine eventuelle Sprungvorhersage richtig war! Somit stellt dies eine Kombination von out-of-order-execution via Tomasulo mit einem erzwungenen in-order-commit dar. Der Reorder-Buffer stellt in der Welt des Tomasulo weitere Register zur Verfügung, welche auch die Funktion von Store Buffern übernehmen könnten, so daß dieser als Teil des Tomasulo nicht direkt mehr erkennbar wäre. (Store Buffer enthalten Informationen darüber, welche Reservation Stations, welches Ergebnis erwartet) Aus welchen Feldern setzt sich ein Reorder-Buffer-Eintrag zusammen? Befehlstyp (Branch, Store oder Registeroperaton) Zielfeld (Registernummer oder Speicheradresse) Datenfeld (Ergebnis der Operation) Die Phasen des Tomasulo Fetch und Decode Holt Instruktionen in einen Befehlscache. Die Decode-Unit holt sich einen Teil der Befehle und versucht mehrere gleichzeitig zu decodieren (In-Order). Dabei wird versucht Sprünge vorherzusagen. Übergibt dekodierten Befehle in der richtigen Reihenfolge an die Dispatch (Issue) Unit. Dispatch / Issue Holt dekodierte Befehle aus Befehlspuffer und übergibt sie In-Order an die Reservation Stations der Execute Units, sobald alle Operanden verfügbar sind (Issue). Solange im Reorder Buffer Platz ist, reserviert sie ein Feld für diesen Befehl mit Hilfe des Tags und gibt dieses an die RS weiter. Wenn nicht wartet sie, bis ein Platz frei wird. (Dispatch Phase) Execution Führt Befehle auf den Schattenregistern aus, um Data Hazards zu meiden. Befehle werden in den Reorder-Buffer geschrieben und Out-Of-Order ausgeführt, solange es keine RAW-Konflikte gibt. Nach Beenden eines Befehls wird Ergebnis an alle RS gebroadcastet, so dass wartende Befehle fortfahren können. (Write result) Commit Die Commit/Completion oder Retire Einheit schreibt die Ergebnisse aus den Renaming Registern in die echten ISA Register zurück, nachdem sie geprüft hat, ob abhängige vorangehende Befehle ihre Ergebnisse geliefert haben und keine falsche Sprungvorhersage eingetreten war. Erklären Sie die Phasen Issue, Execute, Write Result und Commit! Die Issue-Phase entnimmt einen Befehl aus dem Befehlsbuffer und versucht diesen an eine freie Reservation Station zu übergeben. Dabei reserviert sie einen Platz im Reorder-Buffer und gibt den dazugehörigen Tag an die Reservation Station. So kann beim Ergebnis-Broadcasting das Ergebnis mit diesem Tag gekennzeichnet werden. (1) Sind nun alle notwendigen Operanden vorhanden und keine weiteren RAW-Abhängigkeiten bestehen, kann der Befehl ausgeführt werden. (Execute-Phase). (2) Ist das Ergebniss berechnet, wird es auf den CDB gelegt und in den Reorder-Buffer geschrieben (Write Result). (3) Der Reorder-Buffer ist als Ringbuffer angelegt, bei dem die Reihenfolge der Befehle, durch die der erwarteten Ergebnisse (über das verliehene Tag) definiert wird. Nun werden in der Commit-Phase falsch vorhergesagte Sprünge zurückgesetzt und es wird bei dem richtigen Nachfolgebefehl fortgesetzt. Das Ergeniss wird in die ISA Register zurückgeschrieben. (4) Abb.: abstrahierter RIST-Kern eines Pentium Pro / Power PC <span>
Original toplevel document
Grundprinzipien der Rechnerarchitekturen parallel ausführbar sind, ist nun nicht mehr so viel Chipfläche zum Auflösen von Hazards notwendig und kann z.B. für mehr Register verwendet werden. Abb.: Prinzip VLIW mit drei Superbefehlen <span>Das Scoreboard Ein Scoreboard ist eine zusätzliche Steuereinheit, welche die Verantwortung für das Befehlsaussenden und das Erkennen von Konflikten trägt. Das Scoreboard wählt aus einem Pool potentiel ausführbarer Befehle (Instruction Window) einen Satz von Befehlen aus. Ein Register wird als ungültig markiert, wenn die Dekodiereinheit erkannt hat, dass ein Befehl sein Ergebnis in dieses Register schreiben möchte. So wird verhindert, dass ein anderer Befehl dieses Register liest, solange es ungültig ist. Nachteil ist, daß keine Ressourcen- und auch keine Datenabhängigkeiten auftreten dürfen. Eine bessere Variante ist die Tomasulo-Methode, welche eine Auflösung von WAR- und WAW-Konflikten ermöglicht. Zusammenfassend gesagt, besteht ein Scoreboard aus einer Vielzahl von Zählern (wie oft wurde gelesen und geschrieben) für die verwendeten Register und Funktionseinheiten. Ein Scoreboard, welches auch WAR und WAW Konflikte lösen kann, wäre zwar extrem aufwendig aber möglich. Wann können Befehle mit der Scoreboard Technik nicht ausgesandt werden? Wenn ein aktueller Operand geschrieben wird (RAW) Wenn das Ergebnisregister gelesen wird (WAR) Wenn das Ergebnisregister geschrieben wird (WAW) WAR und WAW sind weniger schwerwiegend als RAW Abhängigkeiten, da diese nur Ressourcenkonflikte darstellen. RAW Konflikte logische Abhängigkeiten und können nicht so einfach aufgelöst werden. Mit der Scoreboard Methode muss gewartet werden, bis der abhängige Vorgängerbefehl sein Ergebnis geschrieben hat. Erst dann kann der Folgebefehl das benötigte Datum lesen und mit der Abarbeitung fortsetzen. Lösen lassen sich alle Probleme mit Out-Of-Order Execution und Register Renaming Technik. Dazu muss das Scoreboard erweitert werden. Die Tomasulo-Methode Hauptidee sind hier sogenannte Reservation Stations, welche eine Art Zwischenpuffer für Operanden darstellen. Die Reservation Stations besitzen eine eindeutige ID, welche jedem Befehl mitgegeben wird. So kann die richtige Reihenfolge beibehalten werden. Wird ein Befehl ausgeführt, arbeitet dieser nicht auf den eigentlichen Registern, sondern auf den assoziierten Reservation Stations, was das Prinzip des schon erwähnten Register Renamings ist. Über einen Common Data Bus werden die Ergebnisse zu allen beteiligten Einheiten gebroadcaset. Reservation Stations erkennen Hazards und können selbst entscheiden, wann sie den dazugehörigen Befehl ausführen. Nämlich erst dann, wenn alle Operanden vorliegen. Um controll stalls komplett vermeiden zu können, wird die Tomasulo-Methode mit der spekulativen Befehlsausführung kombiniert. Wie arbeitet die spekulative Befehlsausführung? Sprungziel-Befehle werden schon ausgeführt, wenn das Ergebnis des Sprungtests noch gar nicht vorliegt. Somit muss es die Möglichkeit geben, bei falscher Vorhersage alle Änderungen zu Verwerfen (Rollback-Fähigkeit). Die Hauptsächliche Hardware-Erweiterung liegt in der Aufspaltung der Ergebnisschreibphase in eine Bereitstellungsphase mit Zwischenspeicherung im Reorder Buffer und eine Phase in der ein Befehl commited, d.h. gänzlich der Ausführung übergeben wird. Ein commit bedeutet, daß eine eventuelle Sprungvorhersage richtig war! Somit stellt dies eine Kombination von out-of-order-execution via Tomasulo mit einem erzwungenen in-order-commit dar. Der Reorder-Buffer stellt in der Welt des Tomasulo weitere Register zur Verfügung, welche auch die Funktion von Store Buffern übernehmen könnten, so daß dieser als Teil des Tomasulo nicht direkt mehr erkennbar wäre. (Store Buffer enthalten Informationen darüber, welche Reservation Stations, welches Ergebnis erwartet) Aus welchen Feldern setzt sich ein Reorder-Buffer-Eintrag zusammen? Befehlstyp (Branch, Store oder Registeroperaton) Zielfeld (Registernummer oder Speicheradresse) Datenfeld (Ergebnis der Operation) Die Phasen des Tomasulo Fetch und Decode Holt Instruktionen in einen Befehlscache. Die Decode-Unit holt sich einen Teil der Befehle und versucht mehrere gleichzeitig zu decodieren (In-Order). Dabei wird versucht Sprünge vorherzusagen. Übergibt dekodierten Befehle in der richtigen Reihenfolge an die Dispatch (Issue) Unit. Dispatch / Issue Holt dekodierte Befehle aus Befehlspuffer und übergibt sie In-Order an die Reservation Stations der Execute Units, sobald alle Operanden verfügbar sind (Issue). Solange im Reorder Buffer Platz ist, reserviert sie ein Feld für diesen Befehl mit Hilfe des Tags und gibt dieses an die RS weiter. Wenn nicht wartet sie, bis ein Platz frei wird. (Dispatch Phase) Execution Führt Befehle auf den Schattenregistern aus, um Data Hazards zu meiden. Befehle werden in den Reorder-Buffer geschrieben und Out-Of-Order ausgeführt, solange es keine RAW-Konflikte gibt. Nach Beenden eines Befehls wird Ergebnis an alle RS gebroadcastet, so dass wartende Befehle fortfahren können. (Write result) Commit Die Commit/Completion oder Retire Einheit schreibt die Ergebnisse aus den Renaming Registern in die echten ISA Register zurück, nachdem sie geprüft hat, ob abhängige vorangehende Befehle ihre Ergebnisse geliefert haben und keine falsche Sprungvorhersage eingetreten war. Erklären Sie die Phasen Issue, Execute, Write Result und Commit! Die Issue-Phase entnimmt einen Befehl aus dem Befehlsbuffer und versucht diesen an eine freie Reservation Station zu übergeben. Dabei reserviert sie einen Platz im Reorder-Buffer und gibt den dazugehörigen Tag an die Reservation Station. So kann beim Ergebnis-Broadcasting das Ergebnis mit diesem Tag gekennzeichnet werden. (1) Sind nun alle notwendigen Operanden vorhanden und keine weiteren RAW-Abhängigkeiten bestehen, kann der Befehl ausgeführt werden. (Execute-Phase). (2) Ist das Ergebniss berechnet, wird es auf den CDB gelegt und in den Reorder-Buffer geschrieben (Write Result). (3) Der Reorder-Buffer ist als Ringbuffer angelegt, bei dem die Reihenfolge der Befehle, durch die der erwarteten Ergebnisse (über das verliehene Tag) definiert wird. Nun werden in der Commit-Phase falsch vorhergesagte Sprünge zurückgesetzt und es wird bei dem richtigen Nachfolgebefehl fortgesetzt. Das Ergeniss wird in die ISA Register zurückgeschrieben. (4) Abb.: abstrahierter RIST-Kern eines Pentium Pro / Power PC Muliple Issue am Beispiel Instruktionen werden in eine oder mehrere Mikrooperationen dekodiert und in eine Warteschlange gestellt. Sprungerkennung erfolgt erst statisch und dann dynamis
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itKeras provides flexibility to decouple the resetting of internal state from updates to network weights by defining an LSTM layer as stateful. This can be done by setting the stateful argument on the LSTM layer to True . When stateful LSTM layers are used, you must also define the batch size as part of the input shape in the definition of the network by setting the batch input shape argument and the b
Original toplevel document (pdf)
cannot see any pdfsFlashcard 7656630783244
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itbe used to approximate most functions. Increasing the depth of the network provides an alternate solution that requires fewer neurons and trains faster. Ultimately, adding depth it is a type of <span>representational optimization. <span>
Original toplevel document (pdf)
cannot see any pdfsFlashcard 7656632618252
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itif you are using a stateful LSTM, you must reset state after evaluating the network on a validation dataset or after making predictions
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itTo achieve better explainability, in many e-commerce applications consumer behavior can be viewed on the level of sessions. A session is a well-defined visit of a consumer to a web- shop: a subsequence of events within the consumer’s history that lay no further apart than a predefined time difference.
Original toplevel document (pdf)
cannot see any pdfsFlashcard 7656636288268
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itDuring the Experience phase agents make random decisions and add new entries to the database consisting of a vector with all their sensory input, the randomly chosen action and the result, i.e. if the score
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itwn in Fig. 2. The structure of the model begins with its input layers for (i) the input variable (i.e., transaction counts) and (ii) optional covariates (time-invariant or time-varying inputs). <span>These variable inputs enter the model through dedicated input layers at the top of the model’s architecture and are combined by simply concatenating them into a single long vector. This input signal then propagates through a series of intermediate layers including a specialized LSTM, or Long Short-Term Memory RNN neural network component. <span>
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itFor event-stream RNNs, history inputs xt ∈ R20 consist of a one-hot encoding of the action type and the time difference. For session-stream RNNs, history inputs st ∈ R23 represent sessions with binary indicators which action types occurred, the time difference to the previous session and the characteristics described in Sec. 3.2. Time differences and, in case of session-stream RNNs, the total session event counts are logarithmized.
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open it. Overcomes the technical problems of training an RNN, namely vanishing and exploding gradients. 2. Possesses memory to overcome the issues of long-term temporal dependency with input sequences <span>3. Process input sequences and output sequences time step by time step, allowing variable length inputs and outputs <span>
Original toplevel document (pdf)
cannot see any pdfsFlashcard 7656668794124
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itThe LSTM neural network would be well-suited for modeling online customer behavior across multiple websites since it can naturally capture inter-sequence and inter-temporal interactions from multiple streams of clickstream data without growing exponentially in complexity. </sp
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itTechnically, in time series forecasting terminology the current time ( t ) and future times ( t+1 , t+n ) are forecast times and past observations ( t-1 , t-n ) are used to make forecasts. We can see how positive and negative shifts can be used to create a new DataFrame from a time series with sequences of input and output patterns for a supervised learning problem. This permits not only classical X -> y prediction, but also X -> Y where both input and output can be sequences. Further, the shift function also works on so-called multivariate
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Deep Learning Has Reinvented Quality Control in Manufacturing—but It Hasn’t Gone Far Enough AI systems that make use of “lifelong learning” techniques are more flexible and faster to train
These so-called continual or lifelong learning systems, and in particular lifelong deep neural networks (L-DNN), were inspired by brain neurophysiology. These deep learning algorithms separate feature training and rule training and are able to add new rule information on the fly. While they still
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itthe clickstream data from a panel of customers and use the history of customers' browsing behavior to make predictions about browsing behaviors, purchasing propensities, or consumer interests. <span>Marketing academics have leveraged the clickstream data of a single website to model the evolution of website-visit behavior (Moe & Fader, 2004a) and purchase-conversion behavior (Moe & Fader, 2004b). <span>
Original toplevel document (pdf)
cannot see any pdfsFlashcard 7656679804172
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itToth, Tan, Di Fabbrizio, and Datta (2017) have shown that a mixture of RNNs can approximate several complex functions simultaneously.
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open its the same or higher prediction accuracy than vector-based methods like logistic regression. Unlike the latter, the application of RNNs comes without the need for extensive feature engineering. <span>In addition, we show that RNNs help us link individual actions directly to predictions in an intuitive way. This allows us to understand the implications consumer actions have on predicted probabilities over the course of the consumer’s history. <span>
Original toplevel document (pdf)
cannot see any pdfsFlashcard 7656685047052
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itsits at the core of BTYD models – while ”alive”, customers make purchases until they drop out – gives these models robust predictive power, especially on the aggregate cohort level, and over a <span>long time horizon. <span>
Original toplevel document (pdf)
cannot see any pdfsFlashcard 7656686357772
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itEach prediction is generated by drawing a sample from the multinomial output distribution calculated by the bottom network layer; our model therefore does not produce point or interval estimates, each output is a simulated draw
Original toplevel document (pdf)
cannot see any pdfsFlashcard 7656690552076
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itWhile an RNN can carry forward useful information from one timestep to the next, however, it is much less effective at capturing long-term dependencies (Bengio, Simard, & Frasconi, 1994; Pascanu, Mikolov, & Bengio, 2013). This limitation turns out to be a c
Original toplevel document (pdf)
cannot see any pdfsFlashcard 7656692387084
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itYou can specify the input shape argument that expects a tuple containing the number of time steps and the number of features
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itome understanding of customer’s behaviour and try to answer the following questions: “How recently did the customer purchase?”, “How often do they purchase?”, and “How much do they spend?” [2]. <span>RFM variables are sufficient statistics for customer behaviour modelling and are a mainstay of the industry because of their ease of implementation in practice [6], [3]. <span>
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itfigure have the same seniority (date of first purchase), recency (date of last purchase), and frequency (number of purchases). However, each of them has a visibly different transaction pattern. <span>A response model relying exclusively on seniority, recency, and frequency would not be able to distinguish between customers who have similar features but different behavioral sequence. <span>
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itMost retail/e-retail brands, plan their short-term inventory (2-4 weeks ahead) based on consumer purchase pattern. Also, certain sales and marketing strategies like Offer Personalization and personalized item recommendations are made leveraging results of consumer purchase predictions for the near future. Given that every demand planner works on a narrow segment of item portfolio, there is a high variability in choices that different planners recommend. Additionally, the demand planners
Original toplevel document (pdf)
cannot see any pdfsFlashcard 7656699202828
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open it> The CLV models use different strategies for customer behaviour modelling. One of the most reliable ones is using the recency (R), frequency (F), and monetary value (M) variables, called RFM [3], [4], [5] <span>
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Open it
Beware of float return values! 0.1 + 0.1 + 0.1 == 0.3 Sometimes false assert 0.1 + 0.1 + 0.1 == 0.3, "Usual way to compare does not always work with floats!" Instead use: assert 0.1 + 0.1 + 0.1 == pytest.approx(0.3)
Flashcard 7656703134988
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itCareful choice must be given to the number of time steps specified when preparing your input data for sequence prediction problems in Keras
Original toplevel document (pdf)
cannot see any pdfsFlashcard 7656705756428
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open it) def plot_predictions(train_data = X_train, train_labels = y_train, test_data = X_test, test_labels = y_test, predictions = y_pred): """ Plots training data, testing_data """ plt.figure(figsize=(10, 7)) plt.scatter(train_data, train_labels, c="blue", label='Training data') plt.scatter(test_data, test_labels, c="green", label="Testing data") plt.scatter(test_data, predictions,
Original toplevel document
TfC 01 regressioning of a model predictions ## The 3 sets (or actually 2 sets: training and test set) tf.random.set_seed(999) X_train, X_test = tf.split(tf.random.shuffle(X, seed=42), num_or_size_splits=[40, 10]<span>) def plot_predictions(train_data = X_train, train_labels = y_train, test_data = X_test, test_labels = y_test, predictions = y_pred): """ Plots training data, testing_data """ plt.figure(figsize=(10, 7)) plt.scatter(train_data, train_labels, c="blue", label='Training data') plt.scatter(test_data, test_labels, c="green", label="Testing data") plt.scatter(test_data, predictions, c="red", label="Predictions") plt.legend(); Common regression evaluation metrics keyboard_arrow_down Introduction For regression problems: MAE tf.keras.losses.MAE() tf.metrics.mean_absolute_error() great starter metrics for any reg
Flashcard 7656707591436
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itDeep Learning mantras: ;) Building model: experiment Evaluation model: visualize
Original toplevel document
TfC 01 regressionmore epochs, more data ### How? # from smaller model to larger model Evaluating models Typical workflow: build a model -> fit it -> evaulate -> tweak -> fit > evaluate -> .... <span>Building model: experiment Evaluation model: visualize What can visualize? the data model itself the training of a model predictions ## The 3 sets (or actually 2 sets: training and test set) tf.random.set_seed(999) X_train, X_test = tf.spli
Flashcard 7656708902156
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itF1-score Combination of precision and recall, ususally a good overall metric for classification models.
Original toplevel document
TfC_02_classification-PART_2anced classes Precision For imbalanced class problems. Higher precision leads to less false positives. Recall Higher recall leads to less false negatives. Tradeoff between recall and precision. <span>F1-score Combination of precision and recall, ususally a good overall metric for classification models. keyboard_arrow_down Confusion matrix Can be hard to use whith large numbers of classes. y-axis -> true label x-axis -> predicted label # Create confusion metrics from sklearn.metr
Flashcard 7656710212876
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itGetting dataset ready for tensorflow Converting non-numerical columns For example: Use pandas get_dummies() function insurance_one_hot = pd.get_dummies(insurance,dtype="int32") #to avoid bool which generate problem with model fitting in TensorFlow insurance_one_hot <span>
Original toplevel document
TfC_01_FINAL_EXAMPLE.ipynbGetting dataset ready for tensorflow Converting non-numerical columns For example: Use pandas get_dummies() function insurance_one_hot = pd.get_dummies(insurance,dtype="int32") #to avoid bool which generate problem with model fitting in TensorFlow insurance_one_hot # Create X and y values (features and labels) y = insurance_one_hot['charges'] X = insurance_one_hot.drop('charges', axis=1) #y = y.values # This is not necessary #X = X.values #X, y, X
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itimportant: This time there is a problem with loss function. In case of categorical_crossentropy the labels have to be one-hot encoded In case of labels as integeres use SparseCategoricalCrossentropy
Original toplevel document
TfC_02_classification-PART_2y-axis -> true label x-axis -> predicted label # Create confusion metrics from sklearn.metrics import confusion_matrix y_preds = model_8.predict(X_test) confusion_matrix(y_test, y_preds) <span>important: This time there is a problem with loss function. In case of categorical_crossentropy the labels have to be one-hot encoded In case of labels as integeres use SparseCategoricalCrossentropy # Get the patterns of a layer in our network weights, biases = model_35.layers[1].get_weights() <span>
Flashcard 7656713882892
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itloss function: In case of categorical_crossentropy the labels have to be one-hot encoded
Original toplevel document
TfC_02_classification-PART_2y-axis -> true label x-axis -> predicted label # Create confusion metrics from sklearn.metrics import confusion_matrix y_preds = model_8.predict(X_test) confusion_matrix(y_test, y_preds) <span>important: This time there is a problem with loss function. In case of categorical_crossentropy the labels have to be one-hot encoded In case of labels as integeres use SparseCategoricalCrossentropy # Get the patterns of a layer in our network weights, biases = model_35.layers[1].get_weights() <span>
Flashcard 7656715717900
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itMultilabel classification - a sample can be assigned to more than one label from more than 2 label options
Original toplevel document
TfC_02_classification-PART_1Types of classification problems Three types of classification problems: binary classification multiclass multilabel Multilabel classification - a sample can be assigned to more than one label from more than 2 label options Multiclass classification - a sample can be assigned to one label but from more than 2 label options Multiclass image classificaton: pizza, steak, sushi Input_shape = [None, 224, 224, 3
Flashcard 7656718863628
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Calculate MSE "by hand" in steps - identify functions
= tf.abs(tf.subtract(tf.cast(y_test, dtype=tf.float32), tf.squeeze(y_pred))) sq_abs_err = tf.multiply(abs_err, abs_err) sq_abs_err tf.math.reduce_mean(sq_abs_err) <tf.Tensor: shape=(), dtype=<span>float32, numpy=155.11417> <span>
Flashcard 7656720698636
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itHow we can improve model (in the particular stage of the process)? # 3. Fitting: more epochs, more data
Original toplevel document
TfC 01 regression#### How we can improve model # 1. Creating model: add more layers, increase numbers of hidden neurons, change activation functions # 2. Compiling: change optimizer or its parameters (eg. learning rate) # 3. Fitting: more epochs, more data ### How? # from smaller model to larger model Evaluating models Typical workflow: build a model -> fit it -> evaulate -> tweak -> fit > evaluate -> .... Building model: experiment Evaluation model: visualize What
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itSheil, Rana, and Reilly (2018) take this one step further by allowing the neural network to derive its own internal representation of transaction histories. The authors demonstrate the performance of several RNN architectures and benchmark them against more conventional machine learning approaches for predicting purchasing intent. </