Edited, memorised or added to reading queue
on 14-Apr-2022 (Thu)
Do you want BuboFlash to help you learning these things? Click here to log in or create user.
Flashcard 7070716923148

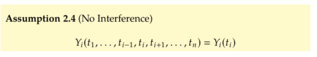
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Flashcard 7070725573900
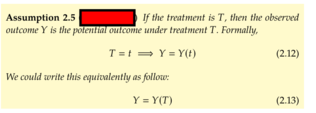
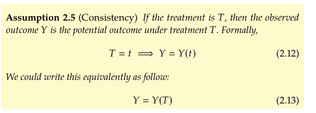
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |

| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |

| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Flashcard 7070758604044
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |

| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
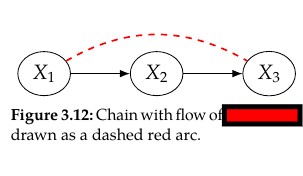
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |