Edited, memorised or added to reading queue
on 26-Jul-2024 (Fri)
Do you want BuboFlash to help you learning these things? Click here to log in or create user.
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open ite sind Deskriptoren für Task-State-Segmente oder Local-Deskriptor-Tables. Aktiv sind aber immer nur eine globale, eine lokale Interrupt-Beschreibertabelle und eine Interrupt-Beschreibertabelle. <span>Was ist ein Gate? Gates sind spezielle Eintritts-Deskriptoren in Segmente höherer Privilegstufe. (Interrupt- oder Trap-Gate-Deskriptoren) Worin unterscheiden sich GDT und LDT? Die Global Descriptor Table einhält Segmente des globalen Adressraums, welcher für alle Tasks zur Verfügung steht. Dagegen sind mit Local Descripto
Original toplevel document
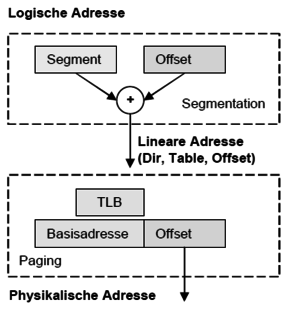
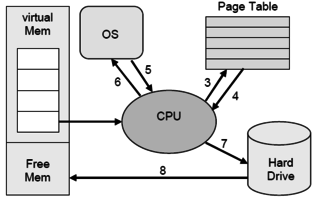
Grundprinzipien der Rechnerarchitekturs den Index Stapeladressierung Hier ist gar keine Adressangabe notwendig Somit sind die Instruktionen sehr kurz Die Stapeladressierung arbeitet mit der umgekehrten polnischen Notation (Postfix) <span>Kapitel 3 - Speicherschutz und Multitasking Um unberechtigte Zugriffe, Datenaufrufe oder Systemprozedurecalls zu vermeiden und Task-Isolation zu gewährleisten, ist ein ausgeklügeltes Speicherschutzsystem notwendig. Segmente zum schützen von Speicherbereichen Segmente sind logische Speicherbereiche variabler Länge (Pages sind normalerweise gleich groß und ergeben zusammengesetzt ein Segment). In einem Segment ist wiederum eine Aufteilung in Code-, Daten- und Speichersegment zu finden. Jedes Segment definiert ein Objekt, welches eindeutig über einen Deskriptor mit Basisadresse, Zugriffsrechten und Limit beschieben wird. Auf Basis dieser Segmente arbeitet die komplette Speicherverwaltung eines Rechners. Wie wird auf Segmente zugegriffen? Segmente werden über eine Deskriptortabelle indiziert. Die Tabellen enthalten Pointer auf die Speicherbereiche der jeweiligen Segmente. Was ist das besondere am segmentierten Adreßraum? Adressen auf Basis von Segmenten sind im unterschied zu linearen Adressen zweidimensional. Sie bestehen aus Segment und Offset. Berechnet werden sie durch einfache Addition von Segment und Offset. Vor der Addition ist das Segment um 4 Stellen nach links zu verschieben. 0002 : 000F berechnet sich also aus 0020 + 000F = 0001F Was sind die Nachteile des Realmodes? Begrenzung eines Segments auf maximal 64 KB, da Offsetadresse nur 16 Bit groß ist Es nur das erste MByte durch das Betriebssystem adressierbar kein Schutz des Speichers vor anderen Programmen Einträge aus der Interruptvektor-Tabelle sind leicht veränderbar nur ein Programm kann ausgeführt werden Was hat Multitasking mit Protected Mode zu tun? Multitasking kann nur durch Protected Mode arbeiten. Er ist sozusagen Grundlage für alle multitaskingfähigen Betriebssysteme. nsbesondere geht es um gegenseitigen Schutz der laufenden Tasks Taskwechselunterstützung durch das Betriebssystem Privilegierungsmechanismen Betriebssystemfunktionen zur Verwaltung von virtuellen Speicher Getrennte Stacks für Parameterübergabe Lösung des "Trojanischen Pferd" Problems Privilegebenen Im Protected Mode werden Anwendungen und Betriebssystem strikt getrennt. Es gibt vier Privilegstufen (null bis drei), welche über die Ausführung verschiedener Maschinensprachebefehle entscheiden. Befehle der Ebene Null sind z.B. das Laden der globalen Deskriptorentabelle oder des Maschinenstatuswortes. Aus welchen beiden Teilen besteht eine Virtuelle Adresse? Eine virtuelle Adresse beinhaltet den Segmentselektor, welcher auf einen Eintrag in der Deskriptortabelle zeigt. Das Segment-Offset zeigt auf die dazugehörige Adresse in dem selektierten Segment. Aus welchen drei Teilen setzt sich ein Segmentselektor zusammen? Aus dem Index, der den Eintrag in der Deskriptortabelle referenziert, dem Table Indicator, welcher über globalem oder lokalem Adressraum entscheidet und den Privelege Level. TI - Table Indicator 0 = GDT (Global Deskriptor Table für den globalen Adreßraum) 1 = LDT (Local Deskriptor Table für den lokalen Adreßraum) RPL Requestor's Privilege Level Privilegstufe des Segments, auf welches der Selektor verweist Was ist ein Deskriptor? Deskriptoren sind Abbildungen zwischen der virtuellen bzw. logischen Adresse (Segmentselektor:Offset) und der linearen Adresse (Basisadresse und Offset). Aus der linearen Adresse wird dann die physikalische Adresse berechnet. (bei i286 war die lineare Adresse noch gleich der physikalischen Adresse, da es noch keine Paging-Einheit gab) Was steht alles in so einem Eintrag in der Deskriptortabelle? Die "normalen" Deskriptoren, welche einen normalen Adressraum (Daten-, Code- oder Stacksegment) beschreiben, enthalten die Basisadresse des Segmentes im Speicher die Zugriffsrechte die Länge des Segmentes Eine andere Klasse von Deskriptoren sind System-Segment-Deskriptoren und zur Ablaufsteuerung notwendige Deskriptoren. Erstere definieren Einsprungpunkte in spezielle System-Unterroutinen oder Gates. Letztere sind Deskriptoren für Task-State-Segmente oder Local-Deskriptor-Tables. Aktiv sind aber immer nur eine globale, eine lokale Interrupt-Beschreibertabelle und eine Interrupt-Beschreibertabelle. Was ist ein Gate? Gates sind spezielle Eintritts-Deskriptoren in Segmente höherer Privilegstufe. (Interrupt- oder Trap-Gate-Deskriptoren) Worin unterscheiden sich GDT und LDT? Die Global Descriptor Table einhält Segmente des globalen Adressraums, welcher für alle Tasks zur Verfügung steht. Dagegen sind mit Local Descriptor Table allokierte Segmente nur von den Host-Tasks selbst adressierbar. (privater Adressraum) Lokale Deskriptortabellen sind Grundlage für die Task-Isolation und daher extrem wichtig für Sicherheit und Segmentschutz. Beschreiben Sie den Aufbau einer Globalen Deskriptortabelle ... ... Globale C/D2 Globale Code-/Daten-Deskriptoren Globale C/D1 Globale Code-/Daten-Deskriptoren ... ... System D2 Gates bzw. TSS-Deskriptoren System D1 Gates bzw. TSS-Deskriptoren ... ... ... ... LDT 2 Lokale Deskriptoren für individuellen Task LDT 1 Lokale Deskriptoren für individuellen Task ... ... ... ... IDT 2 Interrupt/Exeption Gates bzw. Deskriptoren IDT 1 Interrupt/Exeption Gates bzw. Deskriptoren GTD_alias ermöglicht dynamischen Zugriff auf die GDT 0-Selektor Zugriff auf 0-Selektor führt zu Exeption Was unterscheidet Real-Mode und Protected-Mode? Im Real-Mode gibt es keine Deskriptoren und somit ist auch kein Segmentschutz möglich. Die Basisadresse berechnet sich einfach aus dem Segment-Register, welches maximal 1 MByte adressieren kann, da es nur 20 Bit breit ist. Im Protected-Mode werden die Basisadressen mittels Deskriptoren bestimmt. Auf Grund dieser Unterschiede sind folgende Merkmale für den Protected-Mode signifikant: Virtuelle Speicherverwaltung Speicherschutzmechanismen durch Segmentation (über Deskriptoren) Paging möglich echtes Multitasking möglich I/O-Privilegierung und privilegierte Befehle Was ist Paging und wie funktioniert es? Paging wird ab i386 vom Prozessor unterstützt und ist nichts weiter als eine Einteilung des Speichers in gleich große Seiten. Vorteil des virtuellen Speichers, welcher durch Mapping oder Paging erst möglich ist, sind für Anwendungen theoretisch unendlich großen Arbeitsspeicher. Grund dafür ist, dass der Tertiärspeicher als Zwischenspeicher für schlafende oder temporär nicht notwendige Seiten ausgenutzt wird. Es gibt ausgeklügelte Seitenerstetzungsalgorithmen, welche das Austauschen von Seiten übernehmen. Ein weiteres Problem was beim Paging gelöst werden muss, ist die eventuell entstehende Inkonsistenz. D ieses Problem wird wie bekanntermaßen üblich durch Dirty-Bits in den Pages gelöst. Verwirrend ist anfangs der Zusammenhang von Segmentierung und Paging. Letztendlich laufen beide Technologien gleichzeitig auf einem modernen System und ergänzen sich gegenseitig. Paging ist hinter den Segmentierungsvorgang geschalten, um Transparenz zu gewährleisten. Die durch die Segmentierung berechnete bzw. übergebene lineare Adresse entspricht ohne Paging der physikalischen. Falls Paging aktiv ist, muss noch etwas mehr getan werden. Die Umsetzung von Linearer in Physikalischer Adresse hängt vom verwendeten Paging ab. Normalerweise wird über die ersten Bits die Page-Table referenziert und über die folgenden der Pagetable-Eintrag, aus dem die Basisadresse geholt wird. Der Offset wird normalerweise beibehalten. Beschreiben Sie was bei einem Page-Fault intern alles abläuft? Während Abarbeitung einer Befehlssequenz erfolgen mehrere Seitenzugriffe Es erfolgt ein Zugriff auf eine Seite. Prozessor prüft die Seite (ist sie im Speicher?). Seite gibt Page Not Present State zurück (d.h. Seite nicht im Speicher) CPU löst Page Fault Exception aus (Siehe System-Aufruf-Deskriptoren) Betriebssystem gibt in Auftrag die Seite von Platte zu holen Prozessor aktiviert Festplattenhardware und positioniert Leseköpfe Seite wird über DMA-Transfer von Disk-To-free Memory übertragen Betriebssystem aktualisiert Pagetable einschließlich des TLB (flush TLB) Betriebssystem startet den unterbrochenen Befehl neu Nennen Sie Vorteile und Nachteile des Pagings gegenüber Segmentation-Only! Performanceerhöhung eines Multitasking-Betriebssystems Verwaltung der Swap-Datei wird durch die Verwendung konstanter Speicherblöcke einfacher nur die 4-KByte werden eingelagert, die tatsächlich benötigt werden und nicht das gesamte Segment Nachteile: Ausführung verzögert sich, weil die Adresse erst dekodiert werden muß bei Zugriff auf eine Seite/Page evtl. erst Einlagerung dieser vom Sekundärspeicher notwendig (Present-Bit) Wie kann man die Adressdekodierung beim Paging umgehen? Durch Translation Lookaside Buffer. Ein TLB ist ein assoziativer Vierwege-Cache, welcher die 32 Page-Table-Einträge aufnimmt, auf die der Prozessor zuletzt zugegriffen hat (LRU-Strategie). Ein TLB Eintrag besteht aus drei logischen Blöcken: Datenblock mit Page-Attributen und physikalische Basisadresse einer Page Tagblock enthält die oberen 17 Bit einer linearen Adresse und Schutz-Bits LRU-Block (Least Recently Used) zeigt letzten Zugriff an Page- und Segmentschutz Zuerst wirkt der Segmentschutz und danach Pageschutz. Pageschutz ist nur 2-stufig. Die inneren drei Privilegebenen sind beim Paging als Supervisor-Code geschützt. Die äußere Ebene ist User-Code. Ein Zugriffsversuch einer User-Page auf eine Supervisor-Page löst eine Exception aus. Was unterscheidet kooperatives und preemtives Multitasking? Beim kooperativen Multitasking entscheiden die Tasks selbst über die Umschaltung der Prozessorleistung. (Naives und Gutgläubiges Verfahren, daß an die Vernunft aller Tasks und somit aller Programmierer glaubt : ) Preemptives Multitasking ist echtes Multitasking. Ein externer Timer steuert die Umschaltung der Tasks. Die Tasks können somit keinen Einfluss auf die Betriebsmittelumschaltung nehmen. Kapitel 4 - Speicherhierarchie und Caches Was bedeutet die Eigenschaft Lokalität? Aus programmtechnischer Sicht wiederholen sich oft Befehle und ganze Programmteile. Somit werden Daten
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itchreibertabelle und eine Interrupt-Beschreibertabelle. Was ist ein Gate? Gates sind spezielle Eintritts-Deskriptoren in Segmente höherer Privilegstufe. (Interrupt- oder Trap-Gate-Deskriptoren) <span>Worin unterscheiden sich GDT und LDT? Die Global Descriptor Table einhält Segmente des globalen Adressraums, welcher für alle Tasks zur Verfügung steht. Dagegen sind mit Local Descriptor Table allokierte Segmente nur von den Host-Tasks selbst adressierbar. (privater Adressraum) Lokale Deskriptortabellen sind Grundlage für die Task-Isolation und daher extrem wichtig für Sicherheit und Segmentschutz. Beschreiben Sie den Aufbau einer Globalen Deskriptortabelle ... ... Globale C/D2 Globale Code-/Daten-Deskriptoren Globale C/D1 Globale Code-/Daten-Deskriptoren ... ... System D2 Gates b
Original toplevel document
Grundprinzipien der Rechnerarchitekturs den Index Stapeladressierung Hier ist gar keine Adressangabe notwendig Somit sind die Instruktionen sehr kurz Die Stapeladressierung arbeitet mit der umgekehrten polnischen Notation (Postfix) <span>Kapitel 3 - Speicherschutz und Multitasking Um unberechtigte Zugriffe, Datenaufrufe oder Systemprozedurecalls zu vermeiden und Task-Isolation zu gewährleisten, ist ein ausgeklügeltes Speicherschutzsystem notwendig. Segmente zum schützen von Speicherbereichen Segmente sind logische Speicherbereiche variabler Länge (Pages sind normalerweise gleich groß und ergeben zusammengesetzt ein Segment). In einem Segment ist wiederum eine Aufteilung in Code-, Daten- und Speichersegment zu finden. Jedes Segment definiert ein Objekt, welches eindeutig über einen Deskriptor mit Basisadresse, Zugriffsrechten und Limit beschieben wird. Auf Basis dieser Segmente arbeitet die komplette Speicherverwaltung eines Rechners. Wie wird auf Segmente zugegriffen? Segmente werden über eine Deskriptortabelle indiziert. Die Tabellen enthalten Pointer auf die Speicherbereiche der jeweiligen Segmente. Was ist das besondere am segmentierten Adreßraum? Adressen auf Basis von Segmenten sind im unterschied zu linearen Adressen zweidimensional. Sie bestehen aus Segment und Offset. Berechnet werden sie durch einfache Addition von Segment und Offset. Vor der Addition ist das Segment um 4 Stellen nach links zu verschieben. 0002 : 000F berechnet sich also aus 0020 + 000F = 0001F Was sind die Nachteile des Realmodes? Begrenzung eines Segments auf maximal 64 KB, da Offsetadresse nur 16 Bit groß ist Es nur das erste MByte durch das Betriebssystem adressierbar kein Schutz des Speichers vor anderen Programmen Einträge aus der Interruptvektor-Tabelle sind leicht veränderbar nur ein Programm kann ausgeführt werden Was hat Multitasking mit Protected Mode zu tun? Multitasking kann nur durch Protected Mode arbeiten. Er ist sozusagen Grundlage für alle multitaskingfähigen Betriebssysteme. nsbesondere geht es um gegenseitigen Schutz der laufenden Tasks Taskwechselunterstützung durch das Betriebssystem Privilegierungsmechanismen Betriebssystemfunktionen zur Verwaltung von virtuellen Speicher Getrennte Stacks für Parameterübergabe Lösung des "Trojanischen Pferd" Problems Privilegebenen Im Protected Mode werden Anwendungen und Betriebssystem strikt getrennt. Es gibt vier Privilegstufen (null bis drei), welche über die Ausführung verschiedener Maschinensprachebefehle entscheiden. Befehle der Ebene Null sind z.B. das Laden der globalen Deskriptorentabelle oder des Maschinenstatuswortes. Aus welchen beiden Teilen besteht eine Virtuelle Adresse? Eine virtuelle Adresse beinhaltet den Segmentselektor, welcher auf einen Eintrag in der Deskriptortabelle zeigt. Das Segment-Offset zeigt auf die dazugehörige Adresse in dem selektierten Segment. Aus welchen drei Teilen setzt sich ein Segmentselektor zusammen? Aus dem Index, der den Eintrag in der Deskriptortabelle referenziert, dem Table Indicator, welcher über globalem oder lokalem Adressraum entscheidet und den Privelege Level. TI - Table Indicator 0 = GDT (Global Deskriptor Table für den globalen Adreßraum) 1 = LDT (Local Deskriptor Table für den lokalen Adreßraum) RPL Requestor's Privilege Level Privilegstufe des Segments, auf welches der Selektor verweist Was ist ein Deskriptor? Deskriptoren sind Abbildungen zwischen der virtuellen bzw. logischen Adresse (Segmentselektor:Offset) und der linearen Adresse (Basisadresse und Offset). Aus der linearen Adresse wird dann die physikalische Adresse berechnet. (bei i286 war die lineare Adresse noch gleich der physikalischen Adresse, da es noch keine Paging-Einheit gab) Was steht alles in so einem Eintrag in der Deskriptortabelle? Die "normalen" Deskriptoren, welche einen normalen Adressraum (Daten-, Code- oder Stacksegment) beschreiben, enthalten die Basisadresse des Segmentes im Speicher die Zugriffsrechte die Länge des Segmentes Eine andere Klasse von Deskriptoren sind System-Segment-Deskriptoren und zur Ablaufsteuerung notwendige Deskriptoren. Erstere definieren Einsprungpunkte in spezielle System-Unterroutinen oder Gates. Letztere sind Deskriptoren für Task-State-Segmente oder Local-Deskriptor-Tables. Aktiv sind aber immer nur eine globale, eine lokale Interrupt-Beschreibertabelle und eine Interrupt-Beschreibertabelle. Was ist ein Gate? Gates sind spezielle Eintritts-Deskriptoren in Segmente höherer Privilegstufe. (Interrupt- oder Trap-Gate-Deskriptoren) Worin unterscheiden sich GDT und LDT? Die Global Descriptor Table einhält Segmente des globalen Adressraums, welcher für alle Tasks zur Verfügung steht. Dagegen sind mit Local Descriptor Table allokierte Segmente nur von den Host-Tasks selbst adressierbar. (privater Adressraum) Lokale Deskriptortabellen sind Grundlage für die Task-Isolation und daher extrem wichtig für Sicherheit und Segmentschutz. Beschreiben Sie den Aufbau einer Globalen Deskriptortabelle ... ... Globale C/D2 Globale Code-/Daten-Deskriptoren Globale C/D1 Globale Code-/Daten-Deskriptoren ... ... System D2 Gates bzw. TSS-Deskriptoren System D1 Gates bzw. TSS-Deskriptoren ... ... ... ... LDT 2 Lokale Deskriptoren für individuellen Task LDT 1 Lokale Deskriptoren für individuellen Task ... ... ... ... IDT 2 Interrupt/Exeption Gates bzw. Deskriptoren IDT 1 Interrupt/Exeption Gates bzw. Deskriptoren GTD_alias ermöglicht dynamischen Zugriff auf die GDT 0-Selektor Zugriff auf 0-Selektor führt zu Exeption Was unterscheidet Real-Mode und Protected-Mode? Im Real-Mode gibt es keine Deskriptoren und somit ist auch kein Segmentschutz möglich. Die Basisadresse berechnet sich einfach aus dem Segment-Register, welches maximal 1 MByte adressieren kann, da es nur 20 Bit breit ist. Im Protected-Mode werden die Basisadressen mittels Deskriptoren bestimmt. Auf Grund dieser Unterschiede sind folgende Merkmale für den Protected-Mode signifikant: Virtuelle Speicherverwaltung Speicherschutzmechanismen durch Segmentation (über Deskriptoren) Paging möglich echtes Multitasking möglich I/O-Privilegierung und privilegierte Befehle Was ist Paging und wie funktioniert es? Paging wird ab i386 vom Prozessor unterstützt und ist nichts weiter als eine Einteilung des Speichers in gleich große Seiten. Vorteil des virtuellen Speichers, welcher durch Mapping oder Paging erst möglich ist, sind für Anwendungen theoretisch unendlich großen Arbeitsspeicher. Grund dafür ist, dass der Tertiärspeicher als Zwischenspeicher für schlafende oder temporär nicht notwendige Seiten ausgenutzt wird. Es gibt ausgeklügelte Seitenerstetzungsalgorithmen, welche das Austauschen von Seiten übernehmen. Ein weiteres Problem was beim Paging gelöst werden muss, ist die eventuell entstehende Inkonsistenz. D ieses Problem wird wie bekanntermaßen üblich durch Dirty-Bits in den Pages gelöst. Verwirrend ist anfangs der Zusammenhang von Segmentierung und Paging. Letztendlich laufen beide Technologien gleichzeitig auf einem modernen System und ergänzen sich gegenseitig. Paging ist hinter den Segmentierungsvorgang geschalten, um Transparenz zu gewährleisten. Die durch die Segmentierung berechnete bzw. übergebene lineare Adresse entspricht ohne Paging der physikalischen. Falls Paging aktiv ist, muss noch etwas mehr getan werden. Die Umsetzung von Linearer in Physikalischer Adresse hängt vom verwendeten Paging ab. Normalerweise wird über die ersten Bits die Page-Table referenziert und über die folgenden der Pagetable-Eintrag, aus dem die Basisadresse geholt wird. Der Offset wird normalerweise beibehalten. Beschreiben Sie was bei einem Page-Fault intern alles abläuft? Während Abarbeitung einer Befehlssequenz erfolgen mehrere Seitenzugriffe Es erfolgt ein Zugriff auf eine Seite. Prozessor prüft die Seite (ist sie im Speicher?). Seite gibt Page Not Present State zurück (d.h. Seite nicht im Speicher) CPU löst Page Fault Exception aus (Siehe System-Aufruf-Deskriptoren) Betriebssystem gibt in Auftrag die Seite von Platte zu holen Prozessor aktiviert Festplattenhardware und positioniert Leseköpfe Seite wird über DMA-Transfer von Disk-To-free Memory übertragen Betriebssystem aktualisiert Pagetable einschließlich des TLB (flush TLB) Betriebssystem startet den unterbrochenen Befehl neu Nennen Sie Vorteile und Nachteile des Pagings gegenüber Segmentation-Only! Performanceerhöhung eines Multitasking-Betriebssystems Verwaltung der Swap-Datei wird durch die Verwendung konstanter Speicherblöcke einfacher nur die 4-KByte werden eingelagert, die tatsächlich benötigt werden und nicht das gesamte Segment Nachteile: Ausführung verzögert sich, weil die Adresse erst dekodiert werden muß bei Zugriff auf eine Seite/Page evtl. erst Einlagerung dieser vom Sekundärspeicher notwendig (Present-Bit) Wie kann man die Adressdekodierung beim Paging umgehen? Durch Translation Lookaside Buffer. Ein TLB ist ein assoziativer Vierwege-Cache, welcher die 32 Page-Table-Einträge aufnimmt, auf die der Prozessor zuletzt zugegriffen hat (LRU-Strategie). Ein TLB Eintrag besteht aus drei logischen Blöcken: Datenblock mit Page-Attributen und physikalische Basisadresse einer Page Tagblock enthält die oberen 17 Bit einer linearen Adresse und Schutz-Bits LRU-Block (Least Recently Used) zeigt letzten Zugriff an Page- und Segmentschutz Zuerst wirkt der Segmentschutz und danach Pageschutz. Pageschutz ist nur 2-stufig. Die inneren drei Privilegebenen sind beim Paging als Supervisor-Code geschützt. Die äußere Ebene ist User-Code. Ein Zugriffsversuch einer User-Page auf eine Supervisor-Page löst eine Exception aus. Was unterscheidet kooperatives und preemtives Multitasking? Beim kooperativen Multitasking entscheiden die Tasks selbst über die Umschaltung der Prozessorleistung. (Naives und Gutgläubiges Verfahren, daß an die Vernunft aller Tasks und somit aller Programmierer glaubt : ) Preemptives Multitasking ist echtes Multitasking. Ein externer Timer steuert die Umschaltung der Tasks. Die Tasks können somit keinen Einfluss auf die Betriebsmittelumschaltung nehmen. Kapitel 4 - Speicherhierarchie und Caches Was bedeutet die Eigenschaft Lokalität? Aus programmtechnischer Sicht wiederholen sich oft Befehle und ganze Programmteile. Somit werden Daten
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itente nur von den Host-Tasks selbst adressierbar. (privater Adressraum) Lokale Deskriptortabellen sind Grundlage für die Task-Isolation und daher extrem wichtig für Sicherheit und Segmentschutz. <span>Beschreiben Sie den Aufbau einer Globalen Deskriptortabelle ... ... Globale C/D2 Globale Code-/Daten-Deskriptoren Globale C/D1 Globale Code-/Daten-Deskriptoren ... ... System D2 Gates bzw. TSS-Deskriptoren System D1 Gates bzw. TSS-Deskriptoren ... ... ... ... LDT 2 Lokale Deskriptoren für individuellen Task LDT 1 Lokale Deskriptoren für individuellen Task ... ... ... ... IDT 2 Interrupt/Exeption Gates bzw. Deskriptoren IDT 1 Interrupt/Exeption Gates bzw. Deskriptoren GTD_alias ermöglicht dynamischen Zugriff auf die GDT 0-Selektor Zugriff auf 0-Selektor führt zu Exeption Was unterscheidet Real-Mode und Protected-Mode? Im Real-Mode gibt es keine Deskriptoren und somit ist auch kein Segmentschutz möglich. Die Basisadresse berechnet sich einfach aus dem Se
Original toplevel document
Grundprinzipien der Rechnerarchitekturs den Index Stapeladressierung Hier ist gar keine Adressangabe notwendig Somit sind die Instruktionen sehr kurz Die Stapeladressierung arbeitet mit der umgekehrten polnischen Notation (Postfix) <span>Kapitel 3 - Speicherschutz und Multitasking Um unberechtigte Zugriffe, Datenaufrufe oder Systemprozedurecalls zu vermeiden und Task-Isolation zu gewährleisten, ist ein ausgeklügeltes Speicherschutzsystem notwendig. Segmente zum schützen von Speicherbereichen Segmente sind logische Speicherbereiche variabler Länge (Pages sind normalerweise gleich groß und ergeben zusammengesetzt ein Segment). In einem Segment ist wiederum eine Aufteilung in Code-, Daten- und Speichersegment zu finden. Jedes Segment definiert ein Objekt, welches eindeutig über einen Deskriptor mit Basisadresse, Zugriffsrechten und Limit beschieben wird. Auf Basis dieser Segmente arbeitet die komplette Speicherverwaltung eines Rechners. Wie wird auf Segmente zugegriffen? Segmente werden über eine Deskriptortabelle indiziert. Die Tabellen enthalten Pointer auf die Speicherbereiche der jeweiligen Segmente. Was ist das besondere am segmentierten Adreßraum? Adressen auf Basis von Segmenten sind im unterschied zu linearen Adressen zweidimensional. Sie bestehen aus Segment und Offset. Berechnet werden sie durch einfache Addition von Segment und Offset. Vor der Addition ist das Segment um 4 Stellen nach links zu verschieben. 0002 : 000F berechnet sich also aus 0020 + 000F = 0001F Was sind die Nachteile des Realmodes? Begrenzung eines Segments auf maximal 64 KB, da Offsetadresse nur 16 Bit groß ist Es nur das erste MByte durch das Betriebssystem adressierbar kein Schutz des Speichers vor anderen Programmen Einträge aus der Interruptvektor-Tabelle sind leicht veränderbar nur ein Programm kann ausgeführt werden Was hat Multitasking mit Protected Mode zu tun? Multitasking kann nur durch Protected Mode arbeiten. Er ist sozusagen Grundlage für alle multitaskingfähigen Betriebssysteme. nsbesondere geht es um gegenseitigen Schutz der laufenden Tasks Taskwechselunterstützung durch das Betriebssystem Privilegierungsmechanismen Betriebssystemfunktionen zur Verwaltung von virtuellen Speicher Getrennte Stacks für Parameterübergabe Lösung des "Trojanischen Pferd" Problems Privilegebenen Im Protected Mode werden Anwendungen und Betriebssystem strikt getrennt. Es gibt vier Privilegstufen (null bis drei), welche über die Ausführung verschiedener Maschinensprachebefehle entscheiden. Befehle der Ebene Null sind z.B. das Laden der globalen Deskriptorentabelle oder des Maschinenstatuswortes. Aus welchen beiden Teilen besteht eine Virtuelle Adresse? Eine virtuelle Adresse beinhaltet den Segmentselektor, welcher auf einen Eintrag in der Deskriptortabelle zeigt. Das Segment-Offset zeigt auf die dazugehörige Adresse in dem selektierten Segment. Aus welchen drei Teilen setzt sich ein Segmentselektor zusammen? Aus dem Index, der den Eintrag in der Deskriptortabelle referenziert, dem Table Indicator, welcher über globalem oder lokalem Adressraum entscheidet und den Privelege Level. TI - Table Indicator 0 = GDT (Global Deskriptor Table für den globalen Adreßraum) 1 = LDT (Local Deskriptor Table für den lokalen Adreßraum) RPL Requestor's Privilege Level Privilegstufe des Segments, auf welches der Selektor verweist Was ist ein Deskriptor? Deskriptoren sind Abbildungen zwischen der virtuellen bzw. logischen Adresse (Segmentselektor:Offset) und der linearen Adresse (Basisadresse und Offset). Aus der linearen Adresse wird dann die physikalische Adresse berechnet. (bei i286 war die lineare Adresse noch gleich der physikalischen Adresse, da es noch keine Paging-Einheit gab) Was steht alles in so einem Eintrag in der Deskriptortabelle? Die "normalen" Deskriptoren, welche einen normalen Adressraum (Daten-, Code- oder Stacksegment) beschreiben, enthalten die Basisadresse des Segmentes im Speicher die Zugriffsrechte die Länge des Segmentes Eine andere Klasse von Deskriptoren sind System-Segment-Deskriptoren und zur Ablaufsteuerung notwendige Deskriptoren. Erstere definieren Einsprungpunkte in spezielle System-Unterroutinen oder Gates. Letztere sind Deskriptoren für Task-State-Segmente oder Local-Deskriptor-Tables. Aktiv sind aber immer nur eine globale, eine lokale Interrupt-Beschreibertabelle und eine Interrupt-Beschreibertabelle. Was ist ein Gate? Gates sind spezielle Eintritts-Deskriptoren in Segmente höherer Privilegstufe. (Interrupt- oder Trap-Gate-Deskriptoren) Worin unterscheiden sich GDT und LDT? Die Global Descriptor Table einhält Segmente des globalen Adressraums, welcher für alle Tasks zur Verfügung steht. Dagegen sind mit Local Descriptor Table allokierte Segmente nur von den Host-Tasks selbst adressierbar. (privater Adressraum) Lokale Deskriptortabellen sind Grundlage für die Task-Isolation und daher extrem wichtig für Sicherheit und Segmentschutz. Beschreiben Sie den Aufbau einer Globalen Deskriptortabelle ... ... Globale C/D2 Globale Code-/Daten-Deskriptoren Globale C/D1 Globale Code-/Daten-Deskriptoren ... ... System D2 Gates bzw. TSS-Deskriptoren System D1 Gates bzw. TSS-Deskriptoren ... ... ... ... LDT 2 Lokale Deskriptoren für individuellen Task LDT 1 Lokale Deskriptoren für individuellen Task ... ... ... ... IDT 2 Interrupt/Exeption Gates bzw. Deskriptoren IDT 1 Interrupt/Exeption Gates bzw. Deskriptoren GTD_alias ermöglicht dynamischen Zugriff auf die GDT 0-Selektor Zugriff auf 0-Selektor führt zu Exeption Was unterscheidet Real-Mode und Protected-Mode? Im Real-Mode gibt es keine Deskriptoren und somit ist auch kein Segmentschutz möglich. Die Basisadresse berechnet sich einfach aus dem Segment-Register, welches maximal 1 MByte adressieren kann, da es nur 20 Bit breit ist. Im Protected-Mode werden die Basisadressen mittels Deskriptoren bestimmt. Auf Grund dieser Unterschiede sind folgende Merkmale für den Protected-Mode signifikant: Virtuelle Speicherverwaltung Speicherschutzmechanismen durch Segmentation (über Deskriptoren) Paging möglich echtes Multitasking möglich I/O-Privilegierung und privilegierte Befehle Was ist Paging und wie funktioniert es? Paging wird ab i386 vom Prozessor unterstützt und ist nichts weiter als eine Einteilung des Speichers in gleich große Seiten. Vorteil des virtuellen Speichers, welcher durch Mapping oder Paging erst möglich ist, sind für Anwendungen theoretisch unendlich großen Arbeitsspeicher. Grund dafür ist, dass der Tertiärspeicher als Zwischenspeicher für schlafende oder temporär nicht notwendige Seiten ausgenutzt wird. Es gibt ausgeklügelte Seitenerstetzungsalgorithmen, welche das Austauschen von Seiten übernehmen. Ein weiteres Problem was beim Paging gelöst werden muss, ist die eventuell entstehende Inkonsistenz. D ieses Problem wird wie bekanntermaßen üblich durch Dirty-Bits in den Pages gelöst. Verwirrend ist anfangs der Zusammenhang von Segmentierung und Paging. Letztendlich laufen beide Technologien gleichzeitig auf einem modernen System und ergänzen sich gegenseitig. Paging ist hinter den Segmentierungsvorgang geschalten, um Transparenz zu gewährleisten. Die durch die Segmentierung berechnete bzw. übergebene lineare Adresse entspricht ohne Paging der physikalischen. Falls Paging aktiv ist, muss noch etwas mehr getan werden. Die Umsetzung von Linearer in Physikalischer Adresse hängt vom verwendeten Paging ab. Normalerweise wird über die ersten Bits die Page-Table referenziert und über die folgenden der Pagetable-Eintrag, aus dem die Basisadresse geholt wird. Der Offset wird normalerweise beibehalten. Beschreiben Sie was bei einem Page-Fault intern alles abläuft? Während Abarbeitung einer Befehlssequenz erfolgen mehrere Seitenzugriffe Es erfolgt ein Zugriff auf eine Seite. Prozessor prüft die Seite (ist sie im Speicher?). Seite gibt Page Not Present State zurück (d.h. Seite nicht im Speicher) CPU löst Page Fault Exception aus (Siehe System-Aufruf-Deskriptoren) Betriebssystem gibt in Auftrag die Seite von Platte zu holen Prozessor aktiviert Festplattenhardware und positioniert Leseköpfe Seite wird über DMA-Transfer von Disk-To-free Memory übertragen Betriebssystem aktualisiert Pagetable einschließlich des TLB (flush TLB) Betriebssystem startet den unterbrochenen Befehl neu Nennen Sie Vorteile und Nachteile des Pagings gegenüber Segmentation-Only! Performanceerhöhung eines Multitasking-Betriebssystems Verwaltung der Swap-Datei wird durch die Verwendung konstanter Speicherblöcke einfacher nur die 4-KByte werden eingelagert, die tatsächlich benötigt werden und nicht das gesamte Segment Nachteile: Ausführung verzögert sich, weil die Adresse erst dekodiert werden muß bei Zugriff auf eine Seite/Page evtl. erst Einlagerung dieser vom Sekundärspeicher notwendig (Present-Bit) Wie kann man die Adressdekodierung beim Paging umgehen? Durch Translation Lookaside Buffer. Ein TLB ist ein assoziativer Vierwege-Cache, welcher die 32 Page-Table-Einträge aufnimmt, auf die der Prozessor zuletzt zugegriffen hat (LRU-Strategie). Ein TLB Eintrag besteht aus drei logischen Blöcken: Datenblock mit Page-Attributen und physikalische Basisadresse einer Page Tagblock enthält die oberen 17 Bit einer linearen Adresse und Schutz-Bits LRU-Block (Least Recently Used) zeigt letzten Zugriff an Page- und Segmentschutz Zuerst wirkt der Segmentschutz und danach Pageschutz. Pageschutz ist nur 2-stufig. Die inneren drei Privilegebenen sind beim Paging als Supervisor-Code geschützt. Die äußere Ebene ist User-Code. Ein Zugriffsversuch einer User-Page auf eine Supervisor-Page löst eine Exception aus. Was unterscheidet kooperatives und preemtives Multitasking? Beim kooperativen Multitasking entscheiden die Tasks selbst über die Umschaltung der Prozessorleistung. (Naives und Gutgläubiges Verfahren, daß an die Vernunft aller Tasks und somit aller Programmierer glaubt : ) Preemptives Multitasking ist echtes Multitasking. Ein externer Timer steuert die Umschaltung der Tasks. Die Tasks können somit keinen Einfluss auf die Betriebsmittelumschaltung nehmen. Kapitel 4 - Speicherhierarchie und Caches Was bedeutet die Eigenschaft Lokalität? Aus programmtechnischer Sicht wiederholen sich oft Befehle und ganze Programmteile. Somit werden Daten
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open iterrupt/Exeption Gates bzw. Deskriptoren IDT 1 Interrupt/Exeption Gates bzw. Deskriptoren GTD_alias ermöglicht dynamischen Zugriff auf die GDT 0-Selektor Zugriff auf 0-Selektor führt zu Exeption <span>Was unterscheidet Real-Mode und Protected-Mode? Im Real-Mode gibt es keine Deskriptoren und somit ist auch kein Segmentschutz möglich. Die Basisadresse berechnet sich einfach aus dem Segment-Register, welches maximal 1 MByte adressieren kann, da es nur 20 Bit breit ist. Im Protected-Mode werden die Basisadressen mittels Deskriptoren bestimmt. Auf Grund dieser Unterschiede sind folgende Merkmale für den Protected-Mode signifikant: Virtuelle Speicherverwaltung Speicherschutzmechanismen durch Segmentation (über Deskriptoren) Pa
Original toplevel document
Grundprinzipien der Rechnerarchitekturs den Index Stapeladressierung Hier ist gar keine Adressangabe notwendig Somit sind die Instruktionen sehr kurz Die Stapeladressierung arbeitet mit der umgekehrten polnischen Notation (Postfix) <span>Kapitel 3 - Speicherschutz und Multitasking Um unberechtigte Zugriffe, Datenaufrufe oder Systemprozedurecalls zu vermeiden und Task-Isolation zu gewährleisten, ist ein ausgeklügeltes Speicherschutzsystem notwendig. Segmente zum schützen von Speicherbereichen Segmente sind logische Speicherbereiche variabler Länge (Pages sind normalerweise gleich groß und ergeben zusammengesetzt ein Segment). In einem Segment ist wiederum eine Aufteilung in Code-, Daten- und Speichersegment zu finden. Jedes Segment definiert ein Objekt, welches eindeutig über einen Deskriptor mit Basisadresse, Zugriffsrechten und Limit beschieben wird. Auf Basis dieser Segmente arbeitet die komplette Speicherverwaltung eines Rechners. Wie wird auf Segmente zugegriffen? Segmente werden über eine Deskriptortabelle indiziert. Die Tabellen enthalten Pointer auf die Speicherbereiche der jeweiligen Segmente. Was ist das besondere am segmentierten Adreßraum? Adressen auf Basis von Segmenten sind im unterschied zu linearen Adressen zweidimensional. Sie bestehen aus Segment und Offset. Berechnet werden sie durch einfache Addition von Segment und Offset. Vor der Addition ist das Segment um 4 Stellen nach links zu verschieben. 0002 : 000F berechnet sich also aus 0020 + 000F = 0001F Was sind die Nachteile des Realmodes? Begrenzung eines Segments auf maximal 64 KB, da Offsetadresse nur 16 Bit groß ist Es nur das erste MByte durch das Betriebssystem adressierbar kein Schutz des Speichers vor anderen Programmen Einträge aus der Interruptvektor-Tabelle sind leicht veränderbar nur ein Programm kann ausgeführt werden Was hat Multitasking mit Protected Mode zu tun? Multitasking kann nur durch Protected Mode arbeiten. Er ist sozusagen Grundlage für alle multitaskingfähigen Betriebssysteme. nsbesondere geht es um gegenseitigen Schutz der laufenden Tasks Taskwechselunterstützung durch das Betriebssystem Privilegierungsmechanismen Betriebssystemfunktionen zur Verwaltung von virtuellen Speicher Getrennte Stacks für Parameterübergabe Lösung des "Trojanischen Pferd" Problems Privilegebenen Im Protected Mode werden Anwendungen und Betriebssystem strikt getrennt. Es gibt vier Privilegstufen (null bis drei), welche über die Ausführung verschiedener Maschinensprachebefehle entscheiden. Befehle der Ebene Null sind z.B. das Laden der globalen Deskriptorentabelle oder des Maschinenstatuswortes. Aus welchen beiden Teilen besteht eine Virtuelle Adresse? Eine virtuelle Adresse beinhaltet den Segmentselektor, welcher auf einen Eintrag in der Deskriptortabelle zeigt. Das Segment-Offset zeigt auf die dazugehörige Adresse in dem selektierten Segment. Aus welchen drei Teilen setzt sich ein Segmentselektor zusammen? Aus dem Index, der den Eintrag in der Deskriptortabelle referenziert, dem Table Indicator, welcher über globalem oder lokalem Adressraum entscheidet und den Privelege Level. TI - Table Indicator 0 = GDT (Global Deskriptor Table für den globalen Adreßraum) 1 = LDT (Local Deskriptor Table für den lokalen Adreßraum) RPL Requestor's Privilege Level Privilegstufe des Segments, auf welches der Selektor verweist Was ist ein Deskriptor? Deskriptoren sind Abbildungen zwischen der virtuellen bzw. logischen Adresse (Segmentselektor:Offset) und der linearen Adresse (Basisadresse und Offset). Aus der linearen Adresse wird dann die physikalische Adresse berechnet. (bei i286 war die lineare Adresse noch gleich der physikalischen Adresse, da es noch keine Paging-Einheit gab) Was steht alles in so einem Eintrag in der Deskriptortabelle? Die "normalen" Deskriptoren, welche einen normalen Adressraum (Daten-, Code- oder Stacksegment) beschreiben, enthalten die Basisadresse des Segmentes im Speicher die Zugriffsrechte die Länge des Segmentes Eine andere Klasse von Deskriptoren sind System-Segment-Deskriptoren und zur Ablaufsteuerung notwendige Deskriptoren. Erstere definieren Einsprungpunkte in spezielle System-Unterroutinen oder Gates. Letztere sind Deskriptoren für Task-State-Segmente oder Local-Deskriptor-Tables. Aktiv sind aber immer nur eine globale, eine lokale Interrupt-Beschreibertabelle und eine Interrupt-Beschreibertabelle. Was ist ein Gate? Gates sind spezielle Eintritts-Deskriptoren in Segmente höherer Privilegstufe. (Interrupt- oder Trap-Gate-Deskriptoren) Worin unterscheiden sich GDT und LDT? Die Global Descriptor Table einhält Segmente des globalen Adressraums, welcher für alle Tasks zur Verfügung steht. Dagegen sind mit Local Descriptor Table allokierte Segmente nur von den Host-Tasks selbst adressierbar. (privater Adressraum) Lokale Deskriptortabellen sind Grundlage für die Task-Isolation und daher extrem wichtig für Sicherheit und Segmentschutz. Beschreiben Sie den Aufbau einer Globalen Deskriptortabelle ... ... Globale C/D2 Globale Code-/Daten-Deskriptoren Globale C/D1 Globale Code-/Daten-Deskriptoren ... ... System D2 Gates bzw. TSS-Deskriptoren System D1 Gates bzw. TSS-Deskriptoren ... ... ... ... LDT 2 Lokale Deskriptoren für individuellen Task LDT 1 Lokale Deskriptoren für individuellen Task ... ... ... ... IDT 2 Interrupt/Exeption Gates bzw. Deskriptoren IDT 1 Interrupt/Exeption Gates bzw. Deskriptoren GTD_alias ermöglicht dynamischen Zugriff auf die GDT 0-Selektor Zugriff auf 0-Selektor führt zu Exeption Was unterscheidet Real-Mode und Protected-Mode? Im Real-Mode gibt es keine Deskriptoren und somit ist auch kein Segmentschutz möglich. Die Basisadresse berechnet sich einfach aus dem Segment-Register, welches maximal 1 MByte adressieren kann, da es nur 20 Bit breit ist. Im Protected-Mode werden die Basisadressen mittels Deskriptoren bestimmt. Auf Grund dieser Unterschiede sind folgende Merkmale für den Protected-Mode signifikant: Virtuelle Speicherverwaltung Speicherschutzmechanismen durch Segmentation (über Deskriptoren) Paging möglich echtes Multitasking möglich I/O-Privilegierung und privilegierte Befehle Was ist Paging und wie funktioniert es? Paging wird ab i386 vom Prozessor unterstützt und ist nichts weiter als eine Einteilung des Speichers in gleich große Seiten. Vorteil des virtuellen Speichers, welcher durch Mapping oder Paging erst möglich ist, sind für Anwendungen theoretisch unendlich großen Arbeitsspeicher. Grund dafür ist, dass der Tertiärspeicher als Zwischenspeicher für schlafende oder temporär nicht notwendige Seiten ausgenutzt wird. Es gibt ausgeklügelte Seitenerstetzungsalgorithmen, welche das Austauschen von Seiten übernehmen. Ein weiteres Problem was beim Paging gelöst werden muss, ist die eventuell entstehende Inkonsistenz. D ieses Problem wird wie bekanntermaßen üblich durch Dirty-Bits in den Pages gelöst. Verwirrend ist anfangs der Zusammenhang von Segmentierung und Paging. Letztendlich laufen beide Technologien gleichzeitig auf einem modernen System und ergänzen sich gegenseitig. Paging ist hinter den Segmentierungsvorgang geschalten, um Transparenz zu gewährleisten. Die durch die Segmentierung berechnete bzw. übergebene lineare Adresse entspricht ohne Paging der physikalischen. Falls Paging aktiv ist, muss noch etwas mehr getan werden. Die Umsetzung von Linearer in Physikalischer Adresse hängt vom verwendeten Paging ab. Normalerweise wird über die ersten Bits die Page-Table referenziert und über die folgenden der Pagetable-Eintrag, aus dem die Basisadresse geholt wird. Der Offset wird normalerweise beibehalten. Beschreiben Sie was bei einem Page-Fault intern alles abläuft? Während Abarbeitung einer Befehlssequenz erfolgen mehrere Seitenzugriffe Es erfolgt ein Zugriff auf eine Seite. Prozessor prüft die Seite (ist sie im Speicher?). Seite gibt Page Not Present State zurück (d.h. Seite nicht im Speicher) CPU löst Page Fault Exception aus (Siehe System-Aufruf-Deskriptoren) Betriebssystem gibt in Auftrag die Seite von Platte zu holen Prozessor aktiviert Festplattenhardware und positioniert Leseköpfe Seite wird über DMA-Transfer von Disk-To-free Memory übertragen Betriebssystem aktualisiert Pagetable einschließlich des TLB (flush TLB) Betriebssystem startet den unterbrochenen Befehl neu Nennen Sie Vorteile und Nachteile des Pagings gegenüber Segmentation-Only! Performanceerhöhung eines Multitasking-Betriebssystems Verwaltung der Swap-Datei wird durch die Verwendung konstanter Speicherblöcke einfacher nur die 4-KByte werden eingelagert, die tatsächlich benötigt werden und nicht das gesamte Segment Nachteile: Ausführung verzögert sich, weil die Adresse erst dekodiert werden muß bei Zugriff auf eine Seite/Page evtl. erst Einlagerung dieser vom Sekundärspeicher notwendig (Present-Bit) Wie kann man die Adressdekodierung beim Paging umgehen? Durch Translation Lookaside Buffer. Ein TLB ist ein assoziativer Vierwege-Cache, welcher die 32 Page-Table-Einträge aufnimmt, auf die der Prozessor zuletzt zugegriffen hat (LRU-Strategie). Ein TLB Eintrag besteht aus drei logischen Blöcken: Datenblock mit Page-Attributen und physikalische Basisadresse einer Page Tagblock enthält die oberen 17 Bit einer linearen Adresse und Schutz-Bits LRU-Block (Least Recently Used) zeigt letzten Zugriff an Page- und Segmentschutz Zuerst wirkt der Segmentschutz und danach Pageschutz. Pageschutz ist nur 2-stufig. Die inneren drei Privilegebenen sind beim Paging als Supervisor-Code geschützt. Die äußere Ebene ist User-Code. Ein Zugriffsversuch einer User-Page auf eine Supervisor-Page löst eine Exception aus. Was unterscheidet kooperatives und preemtives Multitasking? Beim kooperativen Multitasking entscheiden die Tasks selbst über die Umschaltung der Prozessorleistung. (Naives und Gutgläubiges Verfahren, daß an die Vernunft aller Tasks und somit aller Programmierer glaubt : ) Preemptives Multitasking ist echtes Multitasking. Ein externer Timer steuert die Umschaltung der Tasks. Die Tasks können somit keinen Einfluss auf die Betriebsmittelumschaltung nehmen. Kapitel 4 - Speicherhierarchie und Caches Was bedeutet die Eigenschaft Lokalität? Aus programmtechnischer Sicht wiederholen sich oft Befehle und ganze Programmteile. Somit werden Daten
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itberechnet sich einfach aus dem Segment-Register, welches maximal 1 MByte adressieren kann, da es nur 20 Bit breit ist. Im Protected-Mode werden die Basisadressen mittels Deskriptoren bestimmt. <span>Auf Grund dieser Unterschiede sind folgende Merkmale für den Protected-Mode signifikant: Virtuelle Speicherverwaltung Speicherschutzmechanismen durch Segmentation (über Deskriptoren) Paging möglich echtes Multitasking möglich I/O-Privilegierung und privilegierte Befehle Was ist Paging und wie funktioniert es? Paging wird ab i386 vom Prozessor unterstützt und ist nichts weiter als eine Einteilung des Speichers in gleich große Seiten. Vorteil des virtuel
Original toplevel document
Grundprinzipien der Rechnerarchitekturs den Index Stapeladressierung Hier ist gar keine Adressangabe notwendig Somit sind die Instruktionen sehr kurz Die Stapeladressierung arbeitet mit der umgekehrten polnischen Notation (Postfix) <span>Kapitel 3 - Speicherschutz und Multitasking Um unberechtigte Zugriffe, Datenaufrufe oder Systemprozedurecalls zu vermeiden und Task-Isolation zu gewährleisten, ist ein ausgeklügeltes Speicherschutzsystem notwendig. Segmente zum schützen von Speicherbereichen Segmente sind logische Speicherbereiche variabler Länge (Pages sind normalerweise gleich groß und ergeben zusammengesetzt ein Segment). In einem Segment ist wiederum eine Aufteilung in Code-, Daten- und Speichersegment zu finden. Jedes Segment definiert ein Objekt, welches eindeutig über einen Deskriptor mit Basisadresse, Zugriffsrechten und Limit beschieben wird. Auf Basis dieser Segmente arbeitet die komplette Speicherverwaltung eines Rechners. Wie wird auf Segmente zugegriffen? Segmente werden über eine Deskriptortabelle indiziert. Die Tabellen enthalten Pointer auf die Speicherbereiche der jeweiligen Segmente. Was ist das besondere am segmentierten Adreßraum? Adressen auf Basis von Segmenten sind im unterschied zu linearen Adressen zweidimensional. Sie bestehen aus Segment und Offset. Berechnet werden sie durch einfache Addition von Segment und Offset. Vor der Addition ist das Segment um 4 Stellen nach links zu verschieben. 0002 : 000F berechnet sich also aus 0020 + 000F = 0001F Was sind die Nachteile des Realmodes? Begrenzung eines Segments auf maximal 64 KB, da Offsetadresse nur 16 Bit groß ist Es nur das erste MByte durch das Betriebssystem adressierbar kein Schutz des Speichers vor anderen Programmen Einträge aus der Interruptvektor-Tabelle sind leicht veränderbar nur ein Programm kann ausgeführt werden Was hat Multitasking mit Protected Mode zu tun? Multitasking kann nur durch Protected Mode arbeiten. Er ist sozusagen Grundlage für alle multitaskingfähigen Betriebssysteme. nsbesondere geht es um gegenseitigen Schutz der laufenden Tasks Taskwechselunterstützung durch das Betriebssystem Privilegierungsmechanismen Betriebssystemfunktionen zur Verwaltung von virtuellen Speicher Getrennte Stacks für Parameterübergabe Lösung des "Trojanischen Pferd" Problems Privilegebenen Im Protected Mode werden Anwendungen und Betriebssystem strikt getrennt. Es gibt vier Privilegstufen (null bis drei), welche über die Ausführung verschiedener Maschinensprachebefehle entscheiden. Befehle der Ebene Null sind z.B. das Laden der globalen Deskriptorentabelle oder des Maschinenstatuswortes. Aus welchen beiden Teilen besteht eine Virtuelle Adresse? Eine virtuelle Adresse beinhaltet den Segmentselektor, welcher auf einen Eintrag in der Deskriptortabelle zeigt. Das Segment-Offset zeigt auf die dazugehörige Adresse in dem selektierten Segment. Aus welchen drei Teilen setzt sich ein Segmentselektor zusammen? Aus dem Index, der den Eintrag in der Deskriptortabelle referenziert, dem Table Indicator, welcher über globalem oder lokalem Adressraum entscheidet und den Privelege Level. TI - Table Indicator 0 = GDT (Global Deskriptor Table für den globalen Adreßraum) 1 = LDT (Local Deskriptor Table für den lokalen Adreßraum) RPL Requestor's Privilege Level Privilegstufe des Segments, auf welches der Selektor verweist Was ist ein Deskriptor? Deskriptoren sind Abbildungen zwischen der virtuellen bzw. logischen Adresse (Segmentselektor:Offset) und der linearen Adresse (Basisadresse und Offset). Aus der linearen Adresse wird dann die physikalische Adresse berechnet. (bei i286 war die lineare Adresse noch gleich der physikalischen Adresse, da es noch keine Paging-Einheit gab) Was steht alles in so einem Eintrag in der Deskriptortabelle? Die "normalen" Deskriptoren, welche einen normalen Adressraum (Daten-, Code- oder Stacksegment) beschreiben, enthalten die Basisadresse des Segmentes im Speicher die Zugriffsrechte die Länge des Segmentes Eine andere Klasse von Deskriptoren sind System-Segment-Deskriptoren und zur Ablaufsteuerung notwendige Deskriptoren. Erstere definieren Einsprungpunkte in spezielle System-Unterroutinen oder Gates. Letztere sind Deskriptoren für Task-State-Segmente oder Local-Deskriptor-Tables. Aktiv sind aber immer nur eine globale, eine lokale Interrupt-Beschreibertabelle und eine Interrupt-Beschreibertabelle. Was ist ein Gate? Gates sind spezielle Eintritts-Deskriptoren in Segmente höherer Privilegstufe. (Interrupt- oder Trap-Gate-Deskriptoren) Worin unterscheiden sich GDT und LDT? Die Global Descriptor Table einhält Segmente des globalen Adressraums, welcher für alle Tasks zur Verfügung steht. Dagegen sind mit Local Descriptor Table allokierte Segmente nur von den Host-Tasks selbst adressierbar. (privater Adressraum) Lokale Deskriptortabellen sind Grundlage für die Task-Isolation und daher extrem wichtig für Sicherheit und Segmentschutz. Beschreiben Sie den Aufbau einer Globalen Deskriptortabelle ... ... Globale C/D2 Globale Code-/Daten-Deskriptoren Globale C/D1 Globale Code-/Daten-Deskriptoren ... ... System D2 Gates bzw. TSS-Deskriptoren System D1 Gates bzw. TSS-Deskriptoren ... ... ... ... LDT 2 Lokale Deskriptoren für individuellen Task LDT 1 Lokale Deskriptoren für individuellen Task ... ... ... ... IDT 2 Interrupt/Exeption Gates bzw. Deskriptoren IDT 1 Interrupt/Exeption Gates bzw. Deskriptoren GTD_alias ermöglicht dynamischen Zugriff auf die GDT 0-Selektor Zugriff auf 0-Selektor führt zu Exeption Was unterscheidet Real-Mode und Protected-Mode? Im Real-Mode gibt es keine Deskriptoren und somit ist auch kein Segmentschutz möglich. Die Basisadresse berechnet sich einfach aus dem Segment-Register, welches maximal 1 MByte adressieren kann, da es nur 20 Bit breit ist. Im Protected-Mode werden die Basisadressen mittels Deskriptoren bestimmt. Auf Grund dieser Unterschiede sind folgende Merkmale für den Protected-Mode signifikant: Virtuelle Speicherverwaltung Speicherschutzmechanismen durch Segmentation (über Deskriptoren) Paging möglich echtes Multitasking möglich I/O-Privilegierung und privilegierte Befehle Was ist Paging und wie funktioniert es? Paging wird ab i386 vom Prozessor unterstützt und ist nichts weiter als eine Einteilung des Speichers in gleich große Seiten. Vorteil des virtuellen Speichers, welcher durch Mapping oder Paging erst möglich ist, sind für Anwendungen theoretisch unendlich großen Arbeitsspeicher. Grund dafür ist, dass der Tertiärspeicher als Zwischenspeicher für schlafende oder temporär nicht notwendige Seiten ausgenutzt wird. Es gibt ausgeklügelte Seitenerstetzungsalgorithmen, welche das Austauschen von Seiten übernehmen. Ein weiteres Problem was beim Paging gelöst werden muss, ist die eventuell entstehende Inkonsistenz. D ieses Problem wird wie bekanntermaßen üblich durch Dirty-Bits in den Pages gelöst. Verwirrend ist anfangs der Zusammenhang von Segmentierung und Paging. Letztendlich laufen beide Technologien gleichzeitig auf einem modernen System und ergänzen sich gegenseitig. Paging ist hinter den Segmentierungsvorgang geschalten, um Transparenz zu gewährleisten. Die durch die Segmentierung berechnete bzw. übergebene lineare Adresse entspricht ohne Paging der physikalischen. Falls Paging aktiv ist, muss noch etwas mehr getan werden. Die Umsetzung von Linearer in Physikalischer Adresse hängt vom verwendeten Paging ab. Normalerweise wird über die ersten Bits die Page-Table referenziert und über die folgenden der Pagetable-Eintrag, aus dem die Basisadresse geholt wird. Der Offset wird normalerweise beibehalten. Beschreiben Sie was bei einem Page-Fault intern alles abläuft? Während Abarbeitung einer Befehlssequenz erfolgen mehrere Seitenzugriffe Es erfolgt ein Zugriff auf eine Seite. Prozessor prüft die Seite (ist sie im Speicher?). Seite gibt Page Not Present State zurück (d.h. Seite nicht im Speicher) CPU löst Page Fault Exception aus (Siehe System-Aufruf-Deskriptoren) Betriebssystem gibt in Auftrag die Seite von Platte zu holen Prozessor aktiviert Festplattenhardware und positioniert Leseköpfe Seite wird über DMA-Transfer von Disk-To-free Memory übertragen Betriebssystem aktualisiert Pagetable einschließlich des TLB (flush TLB) Betriebssystem startet den unterbrochenen Befehl neu Nennen Sie Vorteile und Nachteile des Pagings gegenüber Segmentation-Only! Performanceerhöhung eines Multitasking-Betriebssystems Verwaltung der Swap-Datei wird durch die Verwendung konstanter Speicherblöcke einfacher nur die 4-KByte werden eingelagert, die tatsächlich benötigt werden und nicht das gesamte Segment Nachteile: Ausführung verzögert sich, weil die Adresse erst dekodiert werden muß bei Zugriff auf eine Seite/Page evtl. erst Einlagerung dieser vom Sekundärspeicher notwendig (Present-Bit) Wie kann man die Adressdekodierung beim Paging umgehen? Durch Translation Lookaside Buffer. Ein TLB ist ein assoziativer Vierwege-Cache, welcher die 32 Page-Table-Einträge aufnimmt, auf die der Prozessor zuletzt zugegriffen hat (LRU-Strategie). Ein TLB Eintrag besteht aus drei logischen Blöcken: Datenblock mit Page-Attributen und physikalische Basisadresse einer Page Tagblock enthält die oberen 17 Bit einer linearen Adresse und Schutz-Bits LRU-Block (Least Recently Used) zeigt letzten Zugriff an Page- und Segmentschutz Zuerst wirkt der Segmentschutz und danach Pageschutz. Pageschutz ist nur 2-stufig. Die inneren drei Privilegebenen sind beim Paging als Supervisor-Code geschützt. Die äußere Ebene ist User-Code. Ein Zugriffsversuch einer User-Page auf eine Supervisor-Page löst eine Exception aus. Was unterscheidet kooperatives und preemtives Multitasking? Beim kooperativen Multitasking entscheiden die Tasks selbst über die Umschaltung der Prozessorleistung. (Naives und Gutgläubiges Verfahren, daß an die Vernunft aller Tasks und somit aller Programmierer glaubt : ) Preemptives Multitasking ist echtes Multitasking. Ein externer Timer steuert die Umschaltung der Tasks. Die Tasks können somit keinen Einfluss auf die Betriebsmittelumschaltung nehmen. Kapitel 4 - Speicherhierarchie und Caches Was bedeutet die Eigenschaft Lokalität? Aus programmtechnischer Sicht wiederholen sich oft Befehle und ganze Programmteile. Somit werden Daten
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itignifikant: Virtuelle Speicherverwaltung Speicherschutzmechanismen durch Segmentation (über Deskriptoren) Paging möglich echtes Multitasking möglich I/O-Privilegierung und privilegierte Befehle <span>Was ist Paging und wie funktioniert es? Paging wird ab i386 vom Prozessor unterstützt und ist nichts weiter als eine Einteilung des Speichers in gleich große Seiten. Vorteil des virtuellen Speichers, welcher durch Mapping oder Paging erst möglich ist, sind für Anwendungen theoretisch unendlich großen Arbeitsspeicher. Grund dafür ist, dass der Tertiärspeicher als Zwischenspeicher für schlafende oder temporär nicht notwendige Seiten ausgenutzt wird. Es gibt ausgeklügelte Seitenerstetzungsalgorithmen, welche das Austauschen von Seiten übernehmen. Ein weiteres Problem was beim Paging gelöst werden muss, ist die eventuell entstehende Inkonsistenz. D ieses Problem wird wie bekanntermaßen üblich durch Dirty-Bits in den Pages gelöst. Verwirrend ist anfangs der Zusammenhang von Segmentierung und Paging. Letztendlich laufen beide Technologien gleichzeitig auf einem modernen System und ergänzen sich gegenseitig. Paging ist hinter den Segmentierungsvorgang geschalten, um Transparenz zu gewährleisten. Die durch die Segmentierung berechnete bzw. übergebene lineare Adresse entspricht ohne Paging der physikalischen. Falls Paging aktiv ist, muss noch etwas mehr getan werden. Die Umsetzung von Linearer in Physikalischer Adresse hängt vom verwendeten Paging ab. Normalerweise wird über die ersten Bits die Page-Table referenziert und über die folgenden der Pagetable-Eintrag, aus dem die Basisadresse geholt wird. Der Offset wird normalerweise beibehalten. Beschreiben Sie was bei einem Page-Fault intern alles abläuft? Während Abarbeitung einer Befehlssequenz erfolgen mehrere Seitenzugriffe Es erfolgt ein Zugriff auf eine Seite. Prozessor
Original toplevel document
Grundprinzipien der Rechnerarchitekturs den Index Stapeladressierung Hier ist gar keine Adressangabe notwendig Somit sind die Instruktionen sehr kurz Die Stapeladressierung arbeitet mit der umgekehrten polnischen Notation (Postfix) <span>Kapitel 3 - Speicherschutz und Multitasking Um unberechtigte Zugriffe, Datenaufrufe oder Systemprozedurecalls zu vermeiden und Task-Isolation zu gewährleisten, ist ein ausgeklügeltes Speicherschutzsystem notwendig. Segmente zum schützen von Speicherbereichen Segmente sind logische Speicherbereiche variabler Länge (Pages sind normalerweise gleich groß und ergeben zusammengesetzt ein Segment). In einem Segment ist wiederum eine Aufteilung in Code-, Daten- und Speichersegment zu finden. Jedes Segment definiert ein Objekt, welches eindeutig über einen Deskriptor mit Basisadresse, Zugriffsrechten und Limit beschieben wird. Auf Basis dieser Segmente arbeitet die komplette Speicherverwaltung eines Rechners. Wie wird auf Segmente zugegriffen? Segmente werden über eine Deskriptortabelle indiziert. Die Tabellen enthalten Pointer auf die Speicherbereiche der jeweiligen Segmente. Was ist das besondere am segmentierten Adreßraum? Adressen auf Basis von Segmenten sind im unterschied zu linearen Adressen zweidimensional. Sie bestehen aus Segment und Offset. Berechnet werden sie durch einfache Addition von Segment und Offset. Vor der Addition ist das Segment um 4 Stellen nach links zu verschieben. 0002 : 000F berechnet sich also aus 0020 + 000F = 0001F Was sind die Nachteile des Realmodes? Begrenzung eines Segments auf maximal 64 KB, da Offsetadresse nur 16 Bit groß ist Es nur das erste MByte durch das Betriebssystem adressierbar kein Schutz des Speichers vor anderen Programmen Einträge aus der Interruptvektor-Tabelle sind leicht veränderbar nur ein Programm kann ausgeführt werden Was hat Multitasking mit Protected Mode zu tun? Multitasking kann nur durch Protected Mode arbeiten. Er ist sozusagen Grundlage für alle multitaskingfähigen Betriebssysteme. nsbesondere geht es um gegenseitigen Schutz der laufenden Tasks Taskwechselunterstützung durch das Betriebssystem Privilegierungsmechanismen Betriebssystemfunktionen zur Verwaltung von virtuellen Speicher Getrennte Stacks für Parameterübergabe Lösung des "Trojanischen Pferd" Problems Privilegebenen Im Protected Mode werden Anwendungen und Betriebssystem strikt getrennt. Es gibt vier Privilegstufen (null bis drei), welche über die Ausführung verschiedener Maschinensprachebefehle entscheiden. Befehle der Ebene Null sind z.B. das Laden der globalen Deskriptorentabelle oder des Maschinenstatuswortes. Aus welchen beiden Teilen besteht eine Virtuelle Adresse? Eine virtuelle Adresse beinhaltet den Segmentselektor, welcher auf einen Eintrag in der Deskriptortabelle zeigt. Das Segment-Offset zeigt auf die dazugehörige Adresse in dem selektierten Segment. Aus welchen drei Teilen setzt sich ein Segmentselektor zusammen? Aus dem Index, der den Eintrag in der Deskriptortabelle referenziert, dem Table Indicator, welcher über globalem oder lokalem Adressraum entscheidet und den Privelege Level. TI - Table Indicator 0 = GDT (Global Deskriptor Table für den globalen Adreßraum) 1 = LDT (Local Deskriptor Table für den lokalen Adreßraum) RPL Requestor's Privilege Level Privilegstufe des Segments, auf welches der Selektor verweist Was ist ein Deskriptor? Deskriptoren sind Abbildungen zwischen der virtuellen bzw. logischen Adresse (Segmentselektor:Offset) und der linearen Adresse (Basisadresse und Offset). Aus der linearen Adresse wird dann die physikalische Adresse berechnet. (bei i286 war die lineare Adresse noch gleich der physikalischen Adresse, da es noch keine Paging-Einheit gab) Was steht alles in so einem Eintrag in der Deskriptortabelle? Die "normalen" Deskriptoren, welche einen normalen Adressraum (Daten-, Code- oder Stacksegment) beschreiben, enthalten die Basisadresse des Segmentes im Speicher die Zugriffsrechte die Länge des Segmentes Eine andere Klasse von Deskriptoren sind System-Segment-Deskriptoren und zur Ablaufsteuerung notwendige Deskriptoren. Erstere definieren Einsprungpunkte in spezielle System-Unterroutinen oder Gates. Letztere sind Deskriptoren für Task-State-Segmente oder Local-Deskriptor-Tables. Aktiv sind aber immer nur eine globale, eine lokale Interrupt-Beschreibertabelle und eine Interrupt-Beschreibertabelle. Was ist ein Gate? Gates sind spezielle Eintritts-Deskriptoren in Segmente höherer Privilegstufe. (Interrupt- oder Trap-Gate-Deskriptoren) Worin unterscheiden sich GDT und LDT? Die Global Descriptor Table einhält Segmente des globalen Adressraums, welcher für alle Tasks zur Verfügung steht. Dagegen sind mit Local Descriptor Table allokierte Segmente nur von den Host-Tasks selbst adressierbar. (privater Adressraum) Lokale Deskriptortabellen sind Grundlage für die Task-Isolation und daher extrem wichtig für Sicherheit und Segmentschutz. Beschreiben Sie den Aufbau einer Globalen Deskriptortabelle ... ... Globale C/D2 Globale Code-/Daten-Deskriptoren Globale C/D1 Globale Code-/Daten-Deskriptoren ... ... System D2 Gates bzw. TSS-Deskriptoren System D1 Gates bzw. TSS-Deskriptoren ... ... ... ... LDT 2 Lokale Deskriptoren für individuellen Task LDT 1 Lokale Deskriptoren für individuellen Task ... ... ... ... IDT 2 Interrupt/Exeption Gates bzw. Deskriptoren IDT 1 Interrupt/Exeption Gates bzw. Deskriptoren GTD_alias ermöglicht dynamischen Zugriff auf die GDT 0-Selektor Zugriff auf 0-Selektor führt zu Exeption Was unterscheidet Real-Mode und Protected-Mode? Im Real-Mode gibt es keine Deskriptoren und somit ist auch kein Segmentschutz möglich. Die Basisadresse berechnet sich einfach aus dem Segment-Register, welches maximal 1 MByte adressieren kann, da es nur 20 Bit breit ist. Im Protected-Mode werden die Basisadressen mittels Deskriptoren bestimmt. Auf Grund dieser Unterschiede sind folgende Merkmale für den Protected-Mode signifikant: Virtuelle Speicherverwaltung Speicherschutzmechanismen durch Segmentation (über Deskriptoren) Paging möglich echtes Multitasking möglich I/O-Privilegierung und privilegierte Befehle Was ist Paging und wie funktioniert es? Paging wird ab i386 vom Prozessor unterstützt und ist nichts weiter als eine Einteilung des Speichers in gleich große Seiten. Vorteil des virtuellen Speichers, welcher durch Mapping oder Paging erst möglich ist, sind für Anwendungen theoretisch unendlich großen Arbeitsspeicher. Grund dafür ist, dass der Tertiärspeicher als Zwischenspeicher für schlafende oder temporär nicht notwendige Seiten ausgenutzt wird. Es gibt ausgeklügelte Seitenerstetzungsalgorithmen, welche das Austauschen von Seiten übernehmen. Ein weiteres Problem was beim Paging gelöst werden muss, ist die eventuell entstehende Inkonsistenz. D ieses Problem wird wie bekanntermaßen üblich durch Dirty-Bits in den Pages gelöst. Verwirrend ist anfangs der Zusammenhang von Segmentierung und Paging. Letztendlich laufen beide Technologien gleichzeitig auf einem modernen System und ergänzen sich gegenseitig. Paging ist hinter den Segmentierungsvorgang geschalten, um Transparenz zu gewährleisten. Die durch die Segmentierung berechnete bzw. übergebene lineare Adresse entspricht ohne Paging der physikalischen. Falls Paging aktiv ist, muss noch etwas mehr getan werden. Die Umsetzung von Linearer in Physikalischer Adresse hängt vom verwendeten Paging ab. Normalerweise wird über die ersten Bits die Page-Table referenziert und über die folgenden der Pagetable-Eintrag, aus dem die Basisadresse geholt wird. Der Offset wird normalerweise beibehalten. Beschreiben Sie was bei einem Page-Fault intern alles abläuft? Während Abarbeitung einer Befehlssequenz erfolgen mehrere Seitenzugriffe Es erfolgt ein Zugriff auf eine Seite. Prozessor prüft die Seite (ist sie im Speicher?). Seite gibt Page Not Present State zurück (d.h. Seite nicht im Speicher) CPU löst Page Fault Exception aus (Siehe System-Aufruf-Deskriptoren) Betriebssystem gibt in Auftrag die Seite von Platte zu holen Prozessor aktiviert Festplattenhardware und positioniert Leseköpfe Seite wird über DMA-Transfer von Disk-To-free Memory übertragen Betriebssystem aktualisiert Pagetable einschließlich des TLB (flush TLB) Betriebssystem startet den unterbrochenen Befehl neu Nennen Sie Vorteile und Nachteile des Pagings gegenüber Segmentation-Only! Performanceerhöhung eines Multitasking-Betriebssystems Verwaltung der Swap-Datei wird durch die Verwendung konstanter Speicherblöcke einfacher nur die 4-KByte werden eingelagert, die tatsächlich benötigt werden und nicht das gesamte Segment Nachteile: Ausführung verzögert sich, weil die Adresse erst dekodiert werden muß bei Zugriff auf eine Seite/Page evtl. erst Einlagerung dieser vom Sekundärspeicher notwendig (Present-Bit) Wie kann man die Adressdekodierung beim Paging umgehen? Durch Translation Lookaside Buffer. Ein TLB ist ein assoziativer Vierwege-Cache, welcher die 32 Page-Table-Einträge aufnimmt, auf die der Prozessor zuletzt zugegriffen hat (LRU-Strategie). Ein TLB Eintrag besteht aus drei logischen Blöcken: Datenblock mit Page-Attributen und physikalische Basisadresse einer Page Tagblock enthält die oberen 17 Bit einer linearen Adresse und Schutz-Bits LRU-Block (Least Recently Used) zeigt letzten Zugriff an Page- und Segmentschutz Zuerst wirkt der Segmentschutz und danach Pageschutz. Pageschutz ist nur 2-stufig. Die inneren drei Privilegebenen sind beim Paging als Supervisor-Code geschützt. Die äußere Ebene ist User-Code. Ein Zugriffsversuch einer User-Page auf eine Supervisor-Page löst eine Exception aus. Was unterscheidet kooperatives und preemtives Multitasking? Beim kooperativen Multitasking entscheiden die Tasks selbst über die Umschaltung der Prozessorleistung. (Naives und Gutgläubiges Verfahren, daß an die Vernunft aller Tasks und somit aller Programmierer glaubt : ) Preemptives Multitasking ist echtes Multitasking. Ein externer Timer steuert die Umschaltung der Tasks. Die Tasks können somit keinen Einfluss auf die Betriebsmittelumschaltung nehmen. Kapitel 4 - Speicherhierarchie und Caches Was bedeutet die Eigenschaft Lokalität? Aus programmtechnischer Sicht wiederholen sich oft Befehle und ganze Programmteile. Somit werden Daten
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itormalerweise wird über die ersten Bits die Page-Table referenziert und über die folgenden der Pagetable-Eintrag, aus dem die Basisadresse geholt wird. Der Offset wird normalerweise beibehalten. <span>Beschreiben Sie was bei einem Page-Fault intern alles abläuft? Während Abarbeitung einer Befehlssequenz erfolgen mehrere Seitenzugriffe Es erfolgt ein Zugriff auf eine Seite. Prozessor prüft die Seite (ist sie im Speicher?). Seite gibt Page Not Present State zurück (d.h. Seite nicht im Speicher) CPU löst Page Fault Exception aus (Siehe System-Aufruf-Deskriptoren) Betriebssystem gibt in Auftrag die Seite von Platte zu holen Prozessor aktiviert Festplattenhardware und positioniert Leseköpfe Seite wird über DMA-Transfer von Disk-To-free Memory übertragen Betriebssystem aktualisiert Pagetable einschließlich des TLB (flush TLB) Betriebssystem startet den unterbrochenen Befehl neu Nennen Sie Vorteile und Nachteile des Pagings gegenüber Segmentation-Only! Performanceerhöhung eines Multitasking-Betriebssystems Verwaltung der Swap-Datei wird durch die Verwendung kon
Original toplevel document
Grundprinzipien der Rechnerarchitekturs den Index Stapeladressierung Hier ist gar keine Adressangabe notwendig Somit sind die Instruktionen sehr kurz Die Stapeladressierung arbeitet mit der umgekehrten polnischen Notation (Postfix) <span>Kapitel 3 - Speicherschutz und Multitasking Um unberechtigte Zugriffe, Datenaufrufe oder Systemprozedurecalls zu vermeiden und Task-Isolation zu gewährleisten, ist ein ausgeklügeltes Speicherschutzsystem notwendig. Segmente zum schützen von Speicherbereichen Segmente sind logische Speicherbereiche variabler Länge (Pages sind normalerweise gleich groß und ergeben zusammengesetzt ein Segment). In einem Segment ist wiederum eine Aufteilung in Code-, Daten- und Speichersegment zu finden. Jedes Segment definiert ein Objekt, welches eindeutig über einen Deskriptor mit Basisadresse, Zugriffsrechten und Limit beschieben wird. Auf Basis dieser Segmente arbeitet die komplette Speicherverwaltung eines Rechners. Wie wird auf Segmente zugegriffen? Segmente werden über eine Deskriptortabelle indiziert. Die Tabellen enthalten Pointer auf die Speicherbereiche der jeweiligen Segmente. Was ist das besondere am segmentierten Adreßraum? Adressen auf Basis von Segmenten sind im unterschied zu linearen Adressen zweidimensional. Sie bestehen aus Segment und Offset. Berechnet werden sie durch einfache Addition von Segment und Offset. Vor der Addition ist das Segment um 4 Stellen nach links zu verschieben. 0002 : 000F berechnet sich also aus 0020 + 000F = 0001F Was sind die Nachteile des Realmodes? Begrenzung eines Segments auf maximal 64 KB, da Offsetadresse nur 16 Bit groß ist Es nur das erste MByte durch das Betriebssystem adressierbar kein Schutz des Speichers vor anderen Programmen Einträge aus der Interruptvektor-Tabelle sind leicht veränderbar nur ein Programm kann ausgeführt werden Was hat Multitasking mit Protected Mode zu tun? Multitasking kann nur durch Protected Mode arbeiten. Er ist sozusagen Grundlage für alle multitaskingfähigen Betriebssysteme. nsbesondere geht es um gegenseitigen Schutz der laufenden Tasks Taskwechselunterstützung durch das Betriebssystem Privilegierungsmechanismen Betriebssystemfunktionen zur Verwaltung von virtuellen Speicher Getrennte Stacks für Parameterübergabe Lösung des "Trojanischen Pferd" Problems Privilegebenen Im Protected Mode werden Anwendungen und Betriebssystem strikt getrennt. Es gibt vier Privilegstufen (null bis drei), welche über die Ausführung verschiedener Maschinensprachebefehle entscheiden. Befehle der Ebene Null sind z.B. das Laden der globalen Deskriptorentabelle oder des Maschinenstatuswortes. Aus welchen beiden Teilen besteht eine Virtuelle Adresse? Eine virtuelle Adresse beinhaltet den Segmentselektor, welcher auf einen Eintrag in der Deskriptortabelle zeigt. Das Segment-Offset zeigt auf die dazugehörige Adresse in dem selektierten Segment. Aus welchen drei Teilen setzt sich ein Segmentselektor zusammen? Aus dem Index, der den Eintrag in der Deskriptortabelle referenziert, dem Table Indicator, welcher über globalem oder lokalem Adressraum entscheidet und den Privelege Level. TI - Table Indicator 0 = GDT (Global Deskriptor Table für den globalen Adreßraum) 1 = LDT (Local Deskriptor Table für den lokalen Adreßraum) RPL Requestor's Privilege Level Privilegstufe des Segments, auf welches der Selektor verweist Was ist ein Deskriptor? Deskriptoren sind Abbildungen zwischen der virtuellen bzw. logischen Adresse (Segmentselektor:Offset) und der linearen Adresse (Basisadresse und Offset). Aus der linearen Adresse wird dann die physikalische Adresse berechnet. (bei i286 war die lineare Adresse noch gleich der physikalischen Adresse, da es noch keine Paging-Einheit gab) Was steht alles in so einem Eintrag in der Deskriptortabelle? Die "normalen" Deskriptoren, welche einen normalen Adressraum (Daten-, Code- oder Stacksegment) beschreiben, enthalten die Basisadresse des Segmentes im Speicher die Zugriffsrechte die Länge des Segmentes Eine andere Klasse von Deskriptoren sind System-Segment-Deskriptoren und zur Ablaufsteuerung notwendige Deskriptoren. Erstere definieren Einsprungpunkte in spezielle System-Unterroutinen oder Gates. Letztere sind Deskriptoren für Task-State-Segmente oder Local-Deskriptor-Tables. Aktiv sind aber immer nur eine globale, eine lokale Interrupt-Beschreibertabelle und eine Interrupt-Beschreibertabelle. Was ist ein Gate? Gates sind spezielle Eintritts-Deskriptoren in Segmente höherer Privilegstufe. (Interrupt- oder Trap-Gate-Deskriptoren) Worin unterscheiden sich GDT und LDT? Die Global Descriptor Table einhält Segmente des globalen Adressraums, welcher für alle Tasks zur Verfügung steht. Dagegen sind mit Local Descriptor Table allokierte Segmente nur von den Host-Tasks selbst adressierbar. (privater Adressraum) Lokale Deskriptortabellen sind Grundlage für die Task-Isolation und daher extrem wichtig für Sicherheit und Segmentschutz. Beschreiben Sie den Aufbau einer Globalen Deskriptortabelle ... ... Globale C/D2 Globale Code-/Daten-Deskriptoren Globale C/D1 Globale Code-/Daten-Deskriptoren ... ... System D2 Gates bzw. TSS-Deskriptoren System D1 Gates bzw. TSS-Deskriptoren ... ... ... ... LDT 2 Lokale Deskriptoren für individuellen Task LDT 1 Lokale Deskriptoren für individuellen Task ... ... ... ... IDT 2 Interrupt/Exeption Gates bzw. Deskriptoren IDT 1 Interrupt/Exeption Gates bzw. Deskriptoren GTD_alias ermöglicht dynamischen Zugriff auf die GDT 0-Selektor Zugriff auf 0-Selektor führt zu Exeption Was unterscheidet Real-Mode und Protected-Mode? Im Real-Mode gibt es keine Deskriptoren und somit ist auch kein Segmentschutz möglich. Die Basisadresse berechnet sich einfach aus dem Segment-Register, welches maximal 1 MByte adressieren kann, da es nur 20 Bit breit ist. Im Protected-Mode werden die Basisadressen mittels Deskriptoren bestimmt. Auf Grund dieser Unterschiede sind folgende Merkmale für den Protected-Mode signifikant: Virtuelle Speicherverwaltung Speicherschutzmechanismen durch Segmentation (über Deskriptoren) Paging möglich echtes Multitasking möglich I/O-Privilegierung und privilegierte Befehle Was ist Paging und wie funktioniert es? Paging wird ab i386 vom Prozessor unterstützt und ist nichts weiter als eine Einteilung des Speichers in gleich große Seiten. Vorteil des virtuellen Speichers, welcher durch Mapping oder Paging erst möglich ist, sind für Anwendungen theoretisch unendlich großen Arbeitsspeicher. Grund dafür ist, dass der Tertiärspeicher als Zwischenspeicher für schlafende oder temporär nicht notwendige Seiten ausgenutzt wird. Es gibt ausgeklügelte Seitenerstetzungsalgorithmen, welche das Austauschen von Seiten übernehmen. Ein weiteres Problem was beim Paging gelöst werden muss, ist die eventuell entstehende Inkonsistenz. D ieses Problem wird wie bekanntermaßen üblich durch Dirty-Bits in den Pages gelöst. Verwirrend ist anfangs der Zusammenhang von Segmentierung und Paging. Letztendlich laufen beide Technologien gleichzeitig auf einem modernen System und ergänzen sich gegenseitig. Paging ist hinter den Segmentierungsvorgang geschalten, um Transparenz zu gewährleisten. Die durch die Segmentierung berechnete bzw. übergebene lineare Adresse entspricht ohne Paging der physikalischen. Falls Paging aktiv ist, muss noch etwas mehr getan werden. Die Umsetzung von Linearer in Physikalischer Adresse hängt vom verwendeten Paging ab. Normalerweise wird über die ersten Bits die Page-Table referenziert und über die folgenden der Pagetable-Eintrag, aus dem die Basisadresse geholt wird. Der Offset wird normalerweise beibehalten. Beschreiben Sie was bei einem Page-Fault intern alles abläuft? Während Abarbeitung einer Befehlssequenz erfolgen mehrere Seitenzugriffe Es erfolgt ein Zugriff auf eine Seite. Prozessor prüft die Seite (ist sie im Speicher?). Seite gibt Page Not Present State zurück (d.h. Seite nicht im Speicher) CPU löst Page Fault Exception aus (Siehe System-Aufruf-Deskriptoren) Betriebssystem gibt in Auftrag die Seite von Platte zu holen Prozessor aktiviert Festplattenhardware und positioniert Leseköpfe Seite wird über DMA-Transfer von Disk-To-free Memory übertragen Betriebssystem aktualisiert Pagetable einschließlich des TLB (flush TLB) Betriebssystem startet den unterbrochenen Befehl neu Nennen Sie Vorteile und Nachteile des Pagings gegenüber Segmentation-Only! Performanceerhöhung eines Multitasking-Betriebssystems Verwaltung der Swap-Datei wird durch die Verwendung konstanter Speicherblöcke einfacher nur die 4-KByte werden eingelagert, die tatsächlich benötigt werden und nicht das gesamte Segment Nachteile: Ausführung verzögert sich, weil die Adresse erst dekodiert werden muß bei Zugriff auf eine Seite/Page evtl. erst Einlagerung dieser vom Sekundärspeicher notwendig (Present-Bit) Wie kann man die Adressdekodierung beim Paging umgehen? Durch Translation Lookaside Buffer. Ein TLB ist ein assoziativer Vierwege-Cache, welcher die 32 Page-Table-Einträge aufnimmt, auf die der Prozessor zuletzt zugegriffen hat (LRU-Strategie). Ein TLB Eintrag besteht aus drei logischen Blöcken: Datenblock mit Page-Attributen und physikalische Basisadresse einer Page Tagblock enthält die oberen 17 Bit einer linearen Adresse und Schutz-Bits LRU-Block (Least Recently Used) zeigt letzten Zugriff an Page- und Segmentschutz Zuerst wirkt der Segmentschutz und danach Pageschutz. Pageschutz ist nur 2-stufig. Die inneren drei Privilegebenen sind beim Paging als Supervisor-Code geschützt. Die äußere Ebene ist User-Code. Ein Zugriffsversuch einer User-Page auf eine Supervisor-Page löst eine Exception aus. Was unterscheidet kooperatives und preemtives Multitasking? Beim kooperativen Multitasking entscheiden die Tasks selbst über die Umschaltung der Prozessorleistung. (Naives und Gutgläubiges Verfahren, daß an die Vernunft aller Tasks und somit aller Programmierer glaubt : ) Preemptives Multitasking ist echtes Multitasking. Ein externer Timer steuert die Umschaltung der Tasks. Die Tasks können somit keinen Einfluss auf die Betriebsmittelumschaltung nehmen. Kapitel 4 - Speicherhierarchie und Caches Was bedeutet die Eigenschaft Lokalität? Aus programmtechnischer Sicht wiederholen sich oft Befehle und ganze Programmteile. Somit werden Daten
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itpfe Seite wird über DMA-Transfer von Disk-To-free Memory übertragen Betriebssystem aktualisiert Pagetable einschließlich des TLB (flush TLB) Betriebssystem startet den unterbrochenen Befehl neu <span>Nennen Sie Vorteile und Nachteile des Pagings gegenüber Segmentation-Only! Performanceerhöhung eines Multitasking-Betriebssystems Verwaltung der Swap-Datei wird durch die Verwendung konstanter Speicherblöcke einfacher nur die 4-KByte werden eingelagert, die tatsächlich benötigt werden und nicht das gesamte Segment Nachteile: Ausführung verzögert sich, weil die Adresse erst dekodiert werden muß bei Zugriff auf eine Seite/Page evtl. erst Einlagerung dieser vom Sekundärspeicher notwendig (Present-Bit) Wie kann man die Adressdekodierung beim Paging umgehen? Durch Translation Lookaside Buffer. Ein TLB ist ein assoziativer Vierwege-Cache, welcher die 32 Page-Table-Einträge aufnimmt, auf
Original toplevel document
Grundprinzipien der Rechnerarchitekturs den Index Stapeladressierung Hier ist gar keine Adressangabe notwendig Somit sind die Instruktionen sehr kurz Die Stapeladressierung arbeitet mit der umgekehrten polnischen Notation (Postfix) <span>Kapitel 3 - Speicherschutz und Multitasking Um unberechtigte Zugriffe, Datenaufrufe oder Systemprozedurecalls zu vermeiden und Task-Isolation zu gewährleisten, ist ein ausgeklügeltes Speicherschutzsystem notwendig. Segmente zum schützen von Speicherbereichen Segmente sind logische Speicherbereiche variabler Länge (Pages sind normalerweise gleich groß und ergeben zusammengesetzt ein Segment). In einem Segment ist wiederum eine Aufteilung in Code-, Daten- und Speichersegment zu finden. Jedes Segment definiert ein Objekt, welches eindeutig über einen Deskriptor mit Basisadresse, Zugriffsrechten und Limit beschieben wird. Auf Basis dieser Segmente arbeitet die komplette Speicherverwaltung eines Rechners. Wie wird auf Segmente zugegriffen? Segmente werden über eine Deskriptortabelle indiziert. Die Tabellen enthalten Pointer auf die Speicherbereiche der jeweiligen Segmente. Was ist das besondere am segmentierten Adreßraum? Adressen auf Basis von Segmenten sind im unterschied zu linearen Adressen zweidimensional. Sie bestehen aus Segment und Offset. Berechnet werden sie durch einfache Addition von Segment und Offset. Vor der Addition ist das Segment um 4 Stellen nach links zu verschieben. 0002 : 000F berechnet sich also aus 0020 + 000F = 0001F Was sind die Nachteile des Realmodes? Begrenzung eines Segments auf maximal 64 KB, da Offsetadresse nur 16 Bit groß ist Es nur das erste MByte durch das Betriebssystem adressierbar kein Schutz des Speichers vor anderen Programmen Einträge aus der Interruptvektor-Tabelle sind leicht veränderbar nur ein Programm kann ausgeführt werden Was hat Multitasking mit Protected Mode zu tun? Multitasking kann nur durch Protected Mode arbeiten. Er ist sozusagen Grundlage für alle multitaskingfähigen Betriebssysteme. nsbesondere geht es um gegenseitigen Schutz der laufenden Tasks Taskwechselunterstützung durch das Betriebssystem Privilegierungsmechanismen Betriebssystemfunktionen zur Verwaltung von virtuellen Speicher Getrennte Stacks für Parameterübergabe Lösung des "Trojanischen Pferd" Problems Privilegebenen Im Protected Mode werden Anwendungen und Betriebssystem strikt getrennt. Es gibt vier Privilegstufen (null bis drei), welche über die Ausführung verschiedener Maschinensprachebefehle entscheiden. Befehle der Ebene Null sind z.B. das Laden der globalen Deskriptorentabelle oder des Maschinenstatuswortes. Aus welchen beiden Teilen besteht eine Virtuelle Adresse? Eine virtuelle Adresse beinhaltet den Segmentselektor, welcher auf einen Eintrag in der Deskriptortabelle zeigt. Das Segment-Offset zeigt auf die dazugehörige Adresse in dem selektierten Segment. Aus welchen drei Teilen setzt sich ein Segmentselektor zusammen? Aus dem Index, der den Eintrag in der Deskriptortabelle referenziert, dem Table Indicator, welcher über globalem oder lokalem Adressraum entscheidet und den Privelege Level. TI - Table Indicator 0 = GDT (Global Deskriptor Table für den globalen Adreßraum) 1 = LDT (Local Deskriptor Table für den lokalen Adreßraum) RPL Requestor's Privilege Level Privilegstufe des Segments, auf welches der Selektor verweist Was ist ein Deskriptor? Deskriptoren sind Abbildungen zwischen der virtuellen bzw. logischen Adresse (Segmentselektor:Offset) und der linearen Adresse (Basisadresse und Offset). Aus der linearen Adresse wird dann die physikalische Adresse berechnet. (bei i286 war die lineare Adresse noch gleich der physikalischen Adresse, da es noch keine Paging-Einheit gab) Was steht alles in so einem Eintrag in der Deskriptortabelle? Die "normalen" Deskriptoren, welche einen normalen Adressraum (Daten-, Code- oder Stacksegment) beschreiben, enthalten die Basisadresse des Segmentes im Speicher die Zugriffsrechte die Länge des Segmentes Eine andere Klasse von Deskriptoren sind System-Segment-Deskriptoren und zur Ablaufsteuerung notwendige Deskriptoren. Erstere definieren Einsprungpunkte in spezielle System-Unterroutinen oder Gates. Letztere sind Deskriptoren für Task-State-Segmente oder Local-Deskriptor-Tables. Aktiv sind aber immer nur eine globale, eine lokale Interrupt-Beschreibertabelle und eine Interrupt-Beschreibertabelle. Was ist ein Gate? Gates sind spezielle Eintritts-Deskriptoren in Segmente höherer Privilegstufe. (Interrupt- oder Trap-Gate-Deskriptoren) Worin unterscheiden sich GDT und LDT? Die Global Descriptor Table einhält Segmente des globalen Adressraums, welcher für alle Tasks zur Verfügung steht. Dagegen sind mit Local Descriptor Table allokierte Segmente nur von den Host-Tasks selbst adressierbar. (privater Adressraum) Lokale Deskriptortabellen sind Grundlage für die Task-Isolation und daher extrem wichtig für Sicherheit und Segmentschutz. Beschreiben Sie den Aufbau einer Globalen Deskriptortabelle ... ... Globale C/D2 Globale Code-/Daten-Deskriptoren Globale C/D1 Globale Code-/Daten-Deskriptoren ... ... System D2 Gates bzw. TSS-Deskriptoren System D1 Gates bzw. TSS-Deskriptoren ... ... ... ... LDT 2 Lokale Deskriptoren für individuellen Task LDT 1 Lokale Deskriptoren für individuellen Task ... ... ... ... IDT 2 Interrupt/Exeption Gates bzw. Deskriptoren IDT 1 Interrupt/Exeption Gates bzw. Deskriptoren GTD_alias ermöglicht dynamischen Zugriff auf die GDT 0-Selektor Zugriff auf 0-Selektor führt zu Exeption Was unterscheidet Real-Mode und Protected-Mode? Im Real-Mode gibt es keine Deskriptoren und somit ist auch kein Segmentschutz möglich. Die Basisadresse berechnet sich einfach aus dem Segment-Register, welches maximal 1 MByte adressieren kann, da es nur 20 Bit breit ist. Im Protected-Mode werden die Basisadressen mittels Deskriptoren bestimmt. Auf Grund dieser Unterschiede sind folgende Merkmale für den Protected-Mode signifikant: Virtuelle Speicherverwaltung Speicherschutzmechanismen durch Segmentation (über Deskriptoren) Paging möglich echtes Multitasking möglich I/O-Privilegierung und privilegierte Befehle Was ist Paging und wie funktioniert es? Paging wird ab i386 vom Prozessor unterstützt und ist nichts weiter als eine Einteilung des Speichers in gleich große Seiten. Vorteil des virtuellen Speichers, welcher durch Mapping oder Paging erst möglich ist, sind für Anwendungen theoretisch unendlich großen Arbeitsspeicher. Grund dafür ist, dass der Tertiärspeicher als Zwischenspeicher für schlafende oder temporär nicht notwendige Seiten ausgenutzt wird. Es gibt ausgeklügelte Seitenerstetzungsalgorithmen, welche das Austauschen von Seiten übernehmen. Ein weiteres Problem was beim Paging gelöst werden muss, ist die eventuell entstehende Inkonsistenz. D ieses Problem wird wie bekanntermaßen üblich durch Dirty-Bits in den Pages gelöst. Verwirrend ist anfangs der Zusammenhang von Segmentierung und Paging. Letztendlich laufen beide Technologien gleichzeitig auf einem modernen System und ergänzen sich gegenseitig. Paging ist hinter den Segmentierungsvorgang geschalten, um Transparenz zu gewährleisten. Die durch die Segmentierung berechnete bzw. übergebene lineare Adresse entspricht ohne Paging der physikalischen. Falls Paging aktiv ist, muss noch etwas mehr getan werden. Die Umsetzung von Linearer in Physikalischer Adresse hängt vom verwendeten Paging ab. Normalerweise wird über die ersten Bits die Page-Table referenziert und über die folgenden der Pagetable-Eintrag, aus dem die Basisadresse geholt wird. Der Offset wird normalerweise beibehalten. Beschreiben Sie was bei einem Page-Fault intern alles abläuft? Während Abarbeitung einer Befehlssequenz erfolgen mehrere Seitenzugriffe Es erfolgt ein Zugriff auf eine Seite. Prozessor prüft die Seite (ist sie im Speicher?). Seite gibt Page Not Present State zurück (d.h. Seite nicht im Speicher) CPU löst Page Fault Exception aus (Siehe System-Aufruf-Deskriptoren) Betriebssystem gibt in Auftrag die Seite von Platte zu holen Prozessor aktiviert Festplattenhardware und positioniert Leseköpfe Seite wird über DMA-Transfer von Disk-To-free Memory übertragen Betriebssystem aktualisiert Pagetable einschließlich des TLB (flush TLB) Betriebssystem startet den unterbrochenen Befehl neu Nennen Sie Vorteile und Nachteile des Pagings gegenüber Segmentation-Only! Performanceerhöhung eines Multitasking-Betriebssystems Verwaltung der Swap-Datei wird durch die Verwendung konstanter Speicherblöcke einfacher nur die 4-KByte werden eingelagert, die tatsächlich benötigt werden und nicht das gesamte Segment Nachteile: Ausführung verzögert sich, weil die Adresse erst dekodiert werden muß bei Zugriff auf eine Seite/Page evtl. erst Einlagerung dieser vom Sekundärspeicher notwendig (Present-Bit) Wie kann man die Adressdekodierung beim Paging umgehen? Durch Translation Lookaside Buffer. Ein TLB ist ein assoziativer Vierwege-Cache, welcher die 32 Page-Table-Einträge aufnimmt, auf die der Prozessor zuletzt zugegriffen hat (LRU-Strategie). Ein TLB Eintrag besteht aus drei logischen Blöcken: Datenblock mit Page-Attributen und physikalische Basisadresse einer Page Tagblock enthält die oberen 17 Bit einer linearen Adresse und Schutz-Bits LRU-Block (Least Recently Used) zeigt letzten Zugriff an Page- und Segmentschutz Zuerst wirkt der Segmentschutz und danach Pageschutz. Pageschutz ist nur 2-stufig. Die inneren drei Privilegebenen sind beim Paging als Supervisor-Code geschützt. Die äußere Ebene ist User-Code. Ein Zugriffsversuch einer User-Page auf eine Supervisor-Page löst eine Exception aus. Was unterscheidet kooperatives und preemtives Multitasking? Beim kooperativen Multitasking entscheiden die Tasks selbst über die Umschaltung der Prozessorleistung. (Naives und Gutgläubiges Verfahren, daß an die Vernunft aller Tasks und somit aller Programmierer glaubt : ) Preemptives Multitasking ist echtes Multitasking. Ein externer Timer steuert die Umschaltung der Tasks. Die Tasks können somit keinen Einfluss auf die Betriebsmittelumschaltung nehmen. Kapitel 4 - Speicherhierarchie und Caches Was bedeutet die Eigenschaft Lokalität? Aus programmtechnischer Sicht wiederholen sich oft Befehle und ganze Programmteile. Somit werden Daten
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itgment Nachteile: Ausführung verzögert sich, weil die Adresse erst dekodiert werden muß bei Zugriff auf eine Seite/Page evtl. erst Einlagerung dieser vom Sekundärspeicher notwendig (Present-Bit) <span>Wie kann man die Adressdekodierung beim Paging umgehen? Durch Translation Lookaside Buffer. Ein TLB ist ein assoziativer Vierwege-Cache, welcher die 32 Page-Table-Einträge aufnimmt, auf die der Prozessor zuletzt zugegriffen hat (LRU-Strategie). Ein TLB Eintrag besteht aus drei logischen Blöcken: Datenblock mit Page-Attributen und physikalische Basisadresse einer Page Tagblock enthält die oberen 17 Bit einer linearen Adresse und Schutz-Bits LRU-Block (Least Recently Used) zeigt letzten Zugriff an Page- und Segmentschutz Zuerst wirkt der Segmentschutz und danach Pageschutz. Pageschutz ist nur 2-stufig. Die inneren drei Privilegebenen sind beim Paging als Supervisor-Code geschützt
Original toplevel document
Grundprinzipien der Rechnerarchitekturs den Index Stapeladressierung Hier ist gar keine Adressangabe notwendig Somit sind die Instruktionen sehr kurz Die Stapeladressierung arbeitet mit der umgekehrten polnischen Notation (Postfix) <span>Kapitel 3 - Speicherschutz und Multitasking Um unberechtigte Zugriffe, Datenaufrufe oder Systemprozedurecalls zu vermeiden und Task-Isolation zu gewährleisten, ist ein ausgeklügeltes Speicherschutzsystem notwendig. Segmente zum schützen von Speicherbereichen Segmente sind logische Speicherbereiche variabler Länge (Pages sind normalerweise gleich groß und ergeben zusammengesetzt ein Segment). In einem Segment ist wiederum eine Aufteilung in Code-, Daten- und Speichersegment zu finden. Jedes Segment definiert ein Objekt, welches eindeutig über einen Deskriptor mit Basisadresse, Zugriffsrechten und Limit beschieben wird. Auf Basis dieser Segmente arbeitet die komplette Speicherverwaltung eines Rechners. Wie wird auf Segmente zugegriffen? Segmente werden über eine Deskriptortabelle indiziert. Die Tabellen enthalten Pointer auf die Speicherbereiche der jeweiligen Segmente. Was ist das besondere am segmentierten Adreßraum? Adressen auf Basis von Segmenten sind im unterschied zu linearen Adressen zweidimensional. Sie bestehen aus Segment und Offset. Berechnet werden sie durch einfache Addition von Segment und Offset. Vor der Addition ist das Segment um 4 Stellen nach links zu verschieben. 0002 : 000F berechnet sich also aus 0020 + 000F = 0001F Was sind die Nachteile des Realmodes? Begrenzung eines Segments auf maximal 64 KB, da Offsetadresse nur 16 Bit groß ist Es nur das erste MByte durch das Betriebssystem adressierbar kein Schutz des Speichers vor anderen Programmen Einträge aus der Interruptvektor-Tabelle sind leicht veränderbar nur ein Programm kann ausgeführt werden Was hat Multitasking mit Protected Mode zu tun? Multitasking kann nur durch Protected Mode arbeiten. Er ist sozusagen Grundlage für alle multitaskingfähigen Betriebssysteme. nsbesondere geht es um gegenseitigen Schutz der laufenden Tasks Taskwechselunterstützung durch das Betriebssystem Privilegierungsmechanismen Betriebssystemfunktionen zur Verwaltung von virtuellen Speicher Getrennte Stacks für Parameterübergabe Lösung des "Trojanischen Pferd" Problems Privilegebenen Im Protected Mode werden Anwendungen und Betriebssystem strikt getrennt. Es gibt vier Privilegstufen (null bis drei), welche über die Ausführung verschiedener Maschinensprachebefehle entscheiden. Befehle der Ebene Null sind z.B. das Laden der globalen Deskriptorentabelle oder des Maschinenstatuswortes. Aus welchen beiden Teilen besteht eine Virtuelle Adresse? Eine virtuelle Adresse beinhaltet den Segmentselektor, welcher auf einen Eintrag in der Deskriptortabelle zeigt. Das Segment-Offset zeigt auf die dazugehörige Adresse in dem selektierten Segment. Aus welchen drei Teilen setzt sich ein Segmentselektor zusammen? Aus dem Index, der den Eintrag in der Deskriptortabelle referenziert, dem Table Indicator, welcher über globalem oder lokalem Adressraum entscheidet und den Privelege Level. TI - Table Indicator 0 = GDT (Global Deskriptor Table für den globalen Adreßraum) 1 = LDT (Local Deskriptor Table für den lokalen Adreßraum) RPL Requestor's Privilege Level Privilegstufe des Segments, auf welches der Selektor verweist Was ist ein Deskriptor? Deskriptoren sind Abbildungen zwischen der virtuellen bzw. logischen Adresse (Segmentselektor:Offset) und der linearen Adresse (Basisadresse und Offset). Aus der linearen Adresse wird dann die physikalische Adresse berechnet. (bei i286 war die lineare Adresse noch gleich der physikalischen Adresse, da es noch keine Paging-Einheit gab) Was steht alles in so einem Eintrag in der Deskriptortabelle? Die "normalen" Deskriptoren, welche einen normalen Adressraum (Daten-, Code- oder Stacksegment) beschreiben, enthalten die Basisadresse des Segmentes im Speicher die Zugriffsrechte die Länge des Segmentes Eine andere Klasse von Deskriptoren sind System-Segment-Deskriptoren und zur Ablaufsteuerung notwendige Deskriptoren. Erstere definieren Einsprungpunkte in spezielle System-Unterroutinen oder Gates. Letztere sind Deskriptoren für Task-State-Segmente oder Local-Deskriptor-Tables. Aktiv sind aber immer nur eine globale, eine lokale Interrupt-Beschreibertabelle und eine Interrupt-Beschreibertabelle. Was ist ein Gate? Gates sind spezielle Eintritts-Deskriptoren in Segmente höherer Privilegstufe. (Interrupt- oder Trap-Gate-Deskriptoren) Worin unterscheiden sich GDT und LDT? Die Global Descriptor Table einhält Segmente des globalen Adressraums, welcher für alle Tasks zur Verfügung steht. Dagegen sind mit Local Descriptor Table allokierte Segmente nur von den Host-Tasks selbst adressierbar. (privater Adressraum) Lokale Deskriptortabellen sind Grundlage für die Task-Isolation und daher extrem wichtig für Sicherheit und Segmentschutz. Beschreiben Sie den Aufbau einer Globalen Deskriptortabelle ... ... Globale C/D2 Globale Code-/Daten-Deskriptoren Globale C/D1 Globale Code-/Daten-Deskriptoren ... ... System D2 Gates bzw. TSS-Deskriptoren System D1 Gates bzw. TSS-Deskriptoren ... ... ... ... LDT 2 Lokale Deskriptoren für individuellen Task LDT 1 Lokale Deskriptoren für individuellen Task ... ... ... ... IDT 2 Interrupt/Exeption Gates bzw. Deskriptoren IDT 1 Interrupt/Exeption Gates bzw. Deskriptoren GTD_alias ermöglicht dynamischen Zugriff auf die GDT 0-Selektor Zugriff auf 0-Selektor führt zu Exeption Was unterscheidet Real-Mode und Protected-Mode? Im Real-Mode gibt es keine Deskriptoren und somit ist auch kein Segmentschutz möglich. Die Basisadresse berechnet sich einfach aus dem Segment-Register, welches maximal 1 MByte adressieren kann, da es nur 20 Bit breit ist. Im Protected-Mode werden die Basisadressen mittels Deskriptoren bestimmt. Auf Grund dieser Unterschiede sind folgende Merkmale für den Protected-Mode signifikant: Virtuelle Speicherverwaltung Speicherschutzmechanismen durch Segmentation (über Deskriptoren) Paging möglich echtes Multitasking möglich I/O-Privilegierung und privilegierte Befehle Was ist Paging und wie funktioniert es? Paging wird ab i386 vom Prozessor unterstützt und ist nichts weiter als eine Einteilung des Speichers in gleich große Seiten. Vorteil des virtuellen Speichers, welcher durch Mapping oder Paging erst möglich ist, sind für Anwendungen theoretisch unendlich großen Arbeitsspeicher. Grund dafür ist, dass der Tertiärspeicher als Zwischenspeicher für schlafende oder temporär nicht notwendige Seiten ausgenutzt wird. Es gibt ausgeklügelte Seitenerstetzungsalgorithmen, welche das Austauschen von Seiten übernehmen. Ein weiteres Problem was beim Paging gelöst werden muss, ist die eventuell entstehende Inkonsistenz. D ieses Problem wird wie bekanntermaßen üblich durch Dirty-Bits in den Pages gelöst. Verwirrend ist anfangs der Zusammenhang von Segmentierung und Paging. Letztendlich laufen beide Technologien gleichzeitig auf einem modernen System und ergänzen sich gegenseitig. Paging ist hinter den Segmentierungsvorgang geschalten, um Transparenz zu gewährleisten. Die durch die Segmentierung berechnete bzw. übergebene lineare Adresse entspricht ohne Paging der physikalischen. Falls Paging aktiv ist, muss noch etwas mehr getan werden. Die Umsetzung von Linearer in Physikalischer Adresse hängt vom verwendeten Paging ab. Normalerweise wird über die ersten Bits die Page-Table referenziert und über die folgenden der Pagetable-Eintrag, aus dem die Basisadresse geholt wird. Der Offset wird normalerweise beibehalten. Beschreiben Sie was bei einem Page-Fault intern alles abläuft? Während Abarbeitung einer Befehlssequenz erfolgen mehrere Seitenzugriffe Es erfolgt ein Zugriff auf eine Seite. Prozessor prüft die Seite (ist sie im Speicher?). Seite gibt Page Not Present State zurück (d.h. Seite nicht im Speicher) CPU löst Page Fault Exception aus (Siehe System-Aufruf-Deskriptoren) Betriebssystem gibt in Auftrag die Seite von Platte zu holen Prozessor aktiviert Festplattenhardware und positioniert Leseköpfe Seite wird über DMA-Transfer von Disk-To-free Memory übertragen Betriebssystem aktualisiert Pagetable einschließlich des TLB (flush TLB) Betriebssystem startet den unterbrochenen Befehl neu Nennen Sie Vorteile und Nachteile des Pagings gegenüber Segmentation-Only! Performanceerhöhung eines Multitasking-Betriebssystems Verwaltung der Swap-Datei wird durch die Verwendung konstanter Speicherblöcke einfacher nur die 4-KByte werden eingelagert, die tatsächlich benötigt werden und nicht das gesamte Segment Nachteile: Ausführung verzögert sich, weil die Adresse erst dekodiert werden muß bei Zugriff auf eine Seite/Page evtl. erst Einlagerung dieser vom Sekundärspeicher notwendig (Present-Bit) Wie kann man die Adressdekodierung beim Paging umgehen? Durch Translation Lookaside Buffer. Ein TLB ist ein assoziativer Vierwege-Cache, welcher die 32 Page-Table-Einträge aufnimmt, auf die der Prozessor zuletzt zugegriffen hat (LRU-Strategie). Ein TLB Eintrag besteht aus drei logischen Blöcken: Datenblock mit Page-Attributen und physikalische Basisadresse einer Page Tagblock enthält die oberen 17 Bit einer linearen Adresse und Schutz-Bits LRU-Block (Least Recently Used) zeigt letzten Zugriff an Page- und Segmentschutz Zuerst wirkt der Segmentschutz und danach Pageschutz. Pageschutz ist nur 2-stufig. Die inneren drei Privilegebenen sind beim Paging als Supervisor-Code geschützt. Die äußere Ebene ist User-Code. Ein Zugriffsversuch einer User-Page auf eine Supervisor-Page löst eine Exception aus. Was unterscheidet kooperatives und preemtives Multitasking? Beim kooperativen Multitasking entscheiden die Tasks selbst über die Umschaltung der Prozessorleistung. (Naives und Gutgläubiges Verfahren, daß an die Vernunft aller Tasks und somit aller Programmierer glaubt : ) Preemptives Multitasking ist echtes Multitasking. Ein externer Timer steuert die Umschaltung der Tasks. Die Tasks können somit keinen Einfluss auf die Betriebsmittelumschaltung nehmen. Kapitel 4 - Speicherhierarchie und Caches Was bedeutet die Eigenschaft Lokalität? Aus programmtechnischer Sicht wiederholen sich oft Befehle und ganze Programmteile. Somit werden Daten
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itmit Page-Attributen und physikalische Basisadresse einer Page Tagblock enthält die oberen 17 Bit einer linearen Adresse und Schutz-Bits LRU-Block (Least Recently Used) zeigt letzten Zugriff an <span>Page- und Segmentschutz Zuerst wirkt der Segmentschutz und danach Pageschutz. Pageschutz ist nur 2-stufig. Die inneren drei Privilegebenen sind beim Paging als Supervisor-Code geschützt. Die äußere Ebene ist User-Code. Ein Zugriffsversuch einer User-Page auf eine Supervisor-Page löst eine Exception aus. Was unterscheidet kooperatives und preemtives Multitasking? Beim kooperativen Multitasking entscheiden die Tasks selbst über die Umschaltung der Prozessorleistung. (Naives und Gutgläubi
Original toplevel document
Grundprinzipien der Rechnerarchitekturs den Index Stapeladressierung Hier ist gar keine Adressangabe notwendig Somit sind die Instruktionen sehr kurz Die Stapeladressierung arbeitet mit der umgekehrten polnischen Notation (Postfix) <span>Kapitel 3 - Speicherschutz und Multitasking Um unberechtigte Zugriffe, Datenaufrufe oder Systemprozedurecalls zu vermeiden und Task-Isolation zu gewährleisten, ist ein ausgeklügeltes Speicherschutzsystem notwendig. Segmente zum schützen von Speicherbereichen Segmente sind logische Speicherbereiche variabler Länge (Pages sind normalerweise gleich groß und ergeben zusammengesetzt ein Segment). In einem Segment ist wiederum eine Aufteilung in Code-, Daten- und Speichersegment zu finden. Jedes Segment definiert ein Objekt, welches eindeutig über einen Deskriptor mit Basisadresse, Zugriffsrechten und Limit beschieben wird. Auf Basis dieser Segmente arbeitet die komplette Speicherverwaltung eines Rechners. Wie wird auf Segmente zugegriffen? Segmente werden über eine Deskriptortabelle indiziert. Die Tabellen enthalten Pointer auf die Speicherbereiche der jeweiligen Segmente. Was ist das besondere am segmentierten Adreßraum? Adressen auf Basis von Segmenten sind im unterschied zu linearen Adressen zweidimensional. Sie bestehen aus Segment und Offset. Berechnet werden sie durch einfache Addition von Segment und Offset. Vor der Addition ist das Segment um 4 Stellen nach links zu verschieben. 0002 : 000F berechnet sich also aus 0020 + 000F = 0001F Was sind die Nachteile des Realmodes? Begrenzung eines Segments auf maximal 64 KB, da Offsetadresse nur 16 Bit groß ist Es nur das erste MByte durch das Betriebssystem adressierbar kein Schutz des Speichers vor anderen Programmen Einträge aus der Interruptvektor-Tabelle sind leicht veränderbar nur ein Programm kann ausgeführt werden Was hat Multitasking mit Protected Mode zu tun? Multitasking kann nur durch Protected Mode arbeiten. Er ist sozusagen Grundlage für alle multitaskingfähigen Betriebssysteme. nsbesondere geht es um gegenseitigen Schutz der laufenden Tasks Taskwechselunterstützung durch das Betriebssystem Privilegierungsmechanismen Betriebssystemfunktionen zur Verwaltung von virtuellen Speicher Getrennte Stacks für Parameterübergabe Lösung des "Trojanischen Pferd" Problems Privilegebenen Im Protected Mode werden Anwendungen und Betriebssystem strikt getrennt. Es gibt vier Privilegstufen (null bis drei), welche über die Ausführung verschiedener Maschinensprachebefehle entscheiden. Befehle der Ebene Null sind z.B. das Laden der globalen Deskriptorentabelle oder des Maschinenstatuswortes. Aus welchen beiden Teilen besteht eine Virtuelle Adresse? Eine virtuelle Adresse beinhaltet den Segmentselektor, welcher auf einen Eintrag in der Deskriptortabelle zeigt. Das Segment-Offset zeigt auf die dazugehörige Adresse in dem selektierten Segment. Aus welchen drei Teilen setzt sich ein Segmentselektor zusammen? Aus dem Index, der den Eintrag in der Deskriptortabelle referenziert, dem Table Indicator, welcher über globalem oder lokalem Adressraum entscheidet und den Privelege Level. TI - Table Indicator 0 = GDT (Global Deskriptor Table für den globalen Adreßraum) 1 = LDT (Local Deskriptor Table für den lokalen Adreßraum) RPL Requestor's Privilege Level Privilegstufe des Segments, auf welches der Selektor verweist Was ist ein Deskriptor? Deskriptoren sind Abbildungen zwischen der virtuellen bzw. logischen Adresse (Segmentselektor:Offset) und der linearen Adresse (Basisadresse und Offset). Aus der linearen Adresse wird dann die physikalische Adresse berechnet. (bei i286 war die lineare Adresse noch gleich der physikalischen Adresse, da es noch keine Paging-Einheit gab) Was steht alles in so einem Eintrag in der Deskriptortabelle? Die "normalen" Deskriptoren, welche einen normalen Adressraum (Daten-, Code- oder Stacksegment) beschreiben, enthalten die Basisadresse des Segmentes im Speicher die Zugriffsrechte die Länge des Segmentes Eine andere Klasse von Deskriptoren sind System-Segment-Deskriptoren und zur Ablaufsteuerung notwendige Deskriptoren. Erstere definieren Einsprungpunkte in spezielle System-Unterroutinen oder Gates. Letztere sind Deskriptoren für Task-State-Segmente oder Local-Deskriptor-Tables. Aktiv sind aber immer nur eine globale, eine lokale Interrupt-Beschreibertabelle und eine Interrupt-Beschreibertabelle. Was ist ein Gate? Gates sind spezielle Eintritts-Deskriptoren in Segmente höherer Privilegstufe. (Interrupt- oder Trap-Gate-Deskriptoren) Worin unterscheiden sich GDT und LDT? Die Global Descriptor Table einhält Segmente des globalen Adressraums, welcher für alle Tasks zur Verfügung steht. Dagegen sind mit Local Descriptor Table allokierte Segmente nur von den Host-Tasks selbst adressierbar. (privater Adressraum) Lokale Deskriptortabellen sind Grundlage für die Task-Isolation und daher extrem wichtig für Sicherheit und Segmentschutz. Beschreiben Sie den Aufbau einer Globalen Deskriptortabelle ... ... Globale C/D2 Globale Code-/Daten-Deskriptoren Globale C/D1 Globale Code-/Daten-Deskriptoren ... ... System D2 Gates bzw. TSS-Deskriptoren System D1 Gates bzw. TSS-Deskriptoren ... ... ... ... LDT 2 Lokale Deskriptoren für individuellen Task LDT 1 Lokale Deskriptoren für individuellen Task ... ... ... ... IDT 2 Interrupt/Exeption Gates bzw. Deskriptoren IDT 1 Interrupt/Exeption Gates bzw. Deskriptoren GTD_alias ermöglicht dynamischen Zugriff auf die GDT 0-Selektor Zugriff auf 0-Selektor führt zu Exeption Was unterscheidet Real-Mode und Protected-Mode? Im Real-Mode gibt es keine Deskriptoren und somit ist auch kein Segmentschutz möglich. Die Basisadresse berechnet sich einfach aus dem Segment-Register, welches maximal 1 MByte adressieren kann, da es nur 20 Bit breit ist. Im Protected-Mode werden die Basisadressen mittels Deskriptoren bestimmt. Auf Grund dieser Unterschiede sind folgende Merkmale für den Protected-Mode signifikant: Virtuelle Speicherverwaltung Speicherschutzmechanismen durch Segmentation (über Deskriptoren) Paging möglich echtes Multitasking möglich I/O-Privilegierung und privilegierte Befehle Was ist Paging und wie funktioniert es? Paging wird ab i386 vom Prozessor unterstützt und ist nichts weiter als eine Einteilung des Speichers in gleich große Seiten. Vorteil des virtuellen Speichers, welcher durch Mapping oder Paging erst möglich ist, sind für Anwendungen theoretisch unendlich großen Arbeitsspeicher. Grund dafür ist, dass der Tertiärspeicher als Zwischenspeicher für schlafende oder temporär nicht notwendige Seiten ausgenutzt wird. Es gibt ausgeklügelte Seitenerstetzungsalgorithmen, welche das Austauschen von Seiten übernehmen. Ein weiteres Problem was beim Paging gelöst werden muss, ist die eventuell entstehende Inkonsistenz. D ieses Problem wird wie bekanntermaßen üblich durch Dirty-Bits in den Pages gelöst. Verwirrend ist anfangs der Zusammenhang von Segmentierung und Paging. Letztendlich laufen beide Technologien gleichzeitig auf einem modernen System und ergänzen sich gegenseitig. Paging ist hinter den Segmentierungsvorgang geschalten, um Transparenz zu gewährleisten. Die durch die Segmentierung berechnete bzw. übergebene lineare Adresse entspricht ohne Paging der physikalischen. Falls Paging aktiv ist, muss noch etwas mehr getan werden. Die Umsetzung von Linearer in Physikalischer Adresse hängt vom verwendeten Paging ab. Normalerweise wird über die ersten Bits die Page-Table referenziert und über die folgenden der Pagetable-Eintrag, aus dem die Basisadresse geholt wird. Der Offset wird normalerweise beibehalten. Beschreiben Sie was bei einem Page-Fault intern alles abläuft? Während Abarbeitung einer Befehlssequenz erfolgen mehrere Seitenzugriffe Es erfolgt ein Zugriff auf eine Seite. Prozessor prüft die Seite (ist sie im Speicher?). Seite gibt Page Not Present State zurück (d.h. Seite nicht im Speicher) CPU löst Page Fault Exception aus (Siehe System-Aufruf-Deskriptoren) Betriebssystem gibt in Auftrag die Seite von Platte zu holen Prozessor aktiviert Festplattenhardware und positioniert Leseköpfe Seite wird über DMA-Transfer von Disk-To-free Memory übertragen Betriebssystem aktualisiert Pagetable einschließlich des TLB (flush TLB) Betriebssystem startet den unterbrochenen Befehl neu Nennen Sie Vorteile und Nachteile des Pagings gegenüber Segmentation-Only! Performanceerhöhung eines Multitasking-Betriebssystems Verwaltung der Swap-Datei wird durch die Verwendung konstanter Speicherblöcke einfacher nur die 4-KByte werden eingelagert, die tatsächlich benötigt werden und nicht das gesamte Segment Nachteile: Ausführung verzögert sich, weil die Adresse erst dekodiert werden muß bei Zugriff auf eine Seite/Page evtl. erst Einlagerung dieser vom Sekundärspeicher notwendig (Present-Bit) Wie kann man die Adressdekodierung beim Paging umgehen? Durch Translation Lookaside Buffer. Ein TLB ist ein assoziativer Vierwege-Cache, welcher die 32 Page-Table-Einträge aufnimmt, auf die der Prozessor zuletzt zugegriffen hat (LRU-Strategie). Ein TLB Eintrag besteht aus drei logischen Blöcken: Datenblock mit Page-Attributen und physikalische Basisadresse einer Page Tagblock enthält die oberen 17 Bit einer linearen Adresse und Schutz-Bits LRU-Block (Least Recently Used) zeigt letzten Zugriff an Page- und Segmentschutz Zuerst wirkt der Segmentschutz und danach Pageschutz. Pageschutz ist nur 2-stufig. Die inneren drei Privilegebenen sind beim Paging als Supervisor-Code geschützt. Die äußere Ebene ist User-Code. Ein Zugriffsversuch einer User-Page auf eine Supervisor-Page löst eine Exception aus. Was unterscheidet kooperatives und preemtives Multitasking? Beim kooperativen Multitasking entscheiden die Tasks selbst über die Umschaltung der Prozessorleistung. (Naives und Gutgläubiges Verfahren, daß an die Vernunft aller Tasks und somit aller Programmierer glaubt : ) Preemptives Multitasking ist echtes Multitasking. Ein externer Timer steuert die Umschaltung der Tasks. Die Tasks können somit keinen Einfluss auf die Betriebsmittelumschaltung nehmen. Kapitel 4 - Speicherhierarchie und Caches Was bedeutet die Eigenschaft Lokalität? Aus programmtechnischer Sicht wiederholen sich oft Befehle und ganze Programmteile. Somit werden Daten
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itinneren drei Privilegebenen sind beim Paging als Supervisor-Code geschützt. Die äußere Ebene ist User-Code. Ein Zugriffsversuch einer User-Page auf eine Supervisor-Page löst eine Exception aus. <span>Was unterscheidet kooperatives und preemtives Multitasking? Beim kooperativen Multitasking entscheiden die Tasks selbst über die Umschaltung der Prozessorleistung. (Naives und Gutgläubiges Verfahren, daß an die Vernunft aller Tasks und somit aller Programmierer glaubt : ) Preemptives Multitasking ist echtes Multitasking. Ein externer Timer steuert die Umschaltung der Tasks. Die Tasks können somit keinen Einfluss auf die Betriebsmittelumschaltung nehmen. <span>
Original toplevel document
Grundprinzipien der Rechnerarchitekturs den Index Stapeladressierung Hier ist gar keine Adressangabe notwendig Somit sind die Instruktionen sehr kurz Die Stapeladressierung arbeitet mit der umgekehrten polnischen Notation (Postfix) <span>Kapitel 3 - Speicherschutz und Multitasking Um unberechtigte Zugriffe, Datenaufrufe oder Systemprozedurecalls zu vermeiden und Task-Isolation zu gewährleisten, ist ein ausgeklügeltes Speicherschutzsystem notwendig. Segmente zum schützen von Speicherbereichen Segmente sind logische Speicherbereiche variabler Länge (Pages sind normalerweise gleich groß und ergeben zusammengesetzt ein Segment). In einem Segment ist wiederum eine Aufteilung in Code-, Daten- und Speichersegment zu finden. Jedes Segment definiert ein Objekt, welches eindeutig über einen Deskriptor mit Basisadresse, Zugriffsrechten und Limit beschieben wird. Auf Basis dieser Segmente arbeitet die komplette Speicherverwaltung eines Rechners. Wie wird auf Segmente zugegriffen? Segmente werden über eine Deskriptortabelle indiziert. Die Tabellen enthalten Pointer auf die Speicherbereiche der jeweiligen Segmente. Was ist das besondere am segmentierten Adreßraum? Adressen auf Basis von Segmenten sind im unterschied zu linearen Adressen zweidimensional. Sie bestehen aus Segment und Offset. Berechnet werden sie durch einfache Addition von Segment und Offset. Vor der Addition ist das Segment um 4 Stellen nach links zu verschieben. 0002 : 000F berechnet sich also aus 0020 + 000F = 0001F Was sind die Nachteile des Realmodes? Begrenzung eines Segments auf maximal 64 KB, da Offsetadresse nur 16 Bit groß ist Es nur das erste MByte durch das Betriebssystem adressierbar kein Schutz des Speichers vor anderen Programmen Einträge aus der Interruptvektor-Tabelle sind leicht veränderbar nur ein Programm kann ausgeführt werden Was hat Multitasking mit Protected Mode zu tun? Multitasking kann nur durch Protected Mode arbeiten. Er ist sozusagen Grundlage für alle multitaskingfähigen Betriebssysteme. nsbesondere geht es um gegenseitigen Schutz der laufenden Tasks Taskwechselunterstützung durch das Betriebssystem Privilegierungsmechanismen Betriebssystemfunktionen zur Verwaltung von virtuellen Speicher Getrennte Stacks für Parameterübergabe Lösung des "Trojanischen Pferd" Problems Privilegebenen Im Protected Mode werden Anwendungen und Betriebssystem strikt getrennt. Es gibt vier Privilegstufen (null bis drei), welche über die Ausführung verschiedener Maschinensprachebefehle entscheiden. Befehle der Ebene Null sind z.B. das Laden der globalen Deskriptorentabelle oder des Maschinenstatuswortes. Aus welchen beiden Teilen besteht eine Virtuelle Adresse? Eine virtuelle Adresse beinhaltet den Segmentselektor, welcher auf einen Eintrag in der Deskriptortabelle zeigt. Das Segment-Offset zeigt auf die dazugehörige Adresse in dem selektierten Segment. Aus welchen drei Teilen setzt sich ein Segmentselektor zusammen? Aus dem Index, der den Eintrag in der Deskriptortabelle referenziert, dem Table Indicator, welcher über globalem oder lokalem Adressraum entscheidet und den Privelege Level. TI - Table Indicator 0 = GDT (Global Deskriptor Table für den globalen Adreßraum) 1 = LDT (Local Deskriptor Table für den lokalen Adreßraum) RPL Requestor's Privilege Level Privilegstufe des Segments, auf welches der Selektor verweist Was ist ein Deskriptor? Deskriptoren sind Abbildungen zwischen der virtuellen bzw. logischen Adresse (Segmentselektor:Offset) und der linearen Adresse (Basisadresse und Offset). Aus der linearen Adresse wird dann die physikalische Adresse berechnet. (bei i286 war die lineare Adresse noch gleich der physikalischen Adresse, da es noch keine Paging-Einheit gab) Was steht alles in so einem Eintrag in der Deskriptortabelle? Die "normalen" Deskriptoren, welche einen normalen Adressraum (Daten-, Code- oder Stacksegment) beschreiben, enthalten die Basisadresse des Segmentes im Speicher die Zugriffsrechte die Länge des Segmentes Eine andere Klasse von Deskriptoren sind System-Segment-Deskriptoren und zur Ablaufsteuerung notwendige Deskriptoren. Erstere definieren Einsprungpunkte in spezielle System-Unterroutinen oder Gates. Letztere sind Deskriptoren für Task-State-Segmente oder Local-Deskriptor-Tables. Aktiv sind aber immer nur eine globale, eine lokale Interrupt-Beschreibertabelle und eine Interrupt-Beschreibertabelle. Was ist ein Gate? Gates sind spezielle Eintritts-Deskriptoren in Segmente höherer Privilegstufe. (Interrupt- oder Trap-Gate-Deskriptoren) Worin unterscheiden sich GDT und LDT? Die Global Descriptor Table einhält Segmente des globalen Adressraums, welcher für alle Tasks zur Verfügung steht. Dagegen sind mit Local Descriptor Table allokierte Segmente nur von den Host-Tasks selbst adressierbar. (privater Adressraum) Lokale Deskriptortabellen sind Grundlage für die Task-Isolation und daher extrem wichtig für Sicherheit und Segmentschutz. Beschreiben Sie den Aufbau einer Globalen Deskriptortabelle ... ... Globale C/D2 Globale Code-/Daten-Deskriptoren Globale C/D1 Globale Code-/Daten-Deskriptoren ... ... System D2 Gates bzw. TSS-Deskriptoren System D1 Gates bzw. TSS-Deskriptoren ... ... ... ... LDT 2 Lokale Deskriptoren für individuellen Task LDT 1 Lokale Deskriptoren für individuellen Task ... ... ... ... IDT 2 Interrupt/Exeption Gates bzw. Deskriptoren IDT 1 Interrupt/Exeption Gates bzw. Deskriptoren GTD_alias ermöglicht dynamischen Zugriff auf die GDT 0-Selektor Zugriff auf 0-Selektor führt zu Exeption Was unterscheidet Real-Mode und Protected-Mode? Im Real-Mode gibt es keine Deskriptoren und somit ist auch kein Segmentschutz möglich. Die Basisadresse berechnet sich einfach aus dem Segment-Register, welches maximal 1 MByte adressieren kann, da es nur 20 Bit breit ist. Im Protected-Mode werden die Basisadressen mittels Deskriptoren bestimmt. Auf Grund dieser Unterschiede sind folgende Merkmale für den Protected-Mode signifikant: Virtuelle Speicherverwaltung Speicherschutzmechanismen durch Segmentation (über Deskriptoren) Paging möglich echtes Multitasking möglich I/O-Privilegierung und privilegierte Befehle Was ist Paging und wie funktioniert es? Paging wird ab i386 vom Prozessor unterstützt und ist nichts weiter als eine Einteilung des Speichers in gleich große Seiten. Vorteil des virtuellen Speichers, welcher durch Mapping oder Paging erst möglich ist, sind für Anwendungen theoretisch unendlich großen Arbeitsspeicher. Grund dafür ist, dass der Tertiärspeicher als Zwischenspeicher für schlafende oder temporär nicht notwendige Seiten ausgenutzt wird. Es gibt ausgeklügelte Seitenerstetzungsalgorithmen, welche das Austauschen von Seiten übernehmen. Ein weiteres Problem was beim Paging gelöst werden muss, ist die eventuell entstehende Inkonsistenz. D ieses Problem wird wie bekanntermaßen üblich durch Dirty-Bits in den Pages gelöst. Verwirrend ist anfangs der Zusammenhang von Segmentierung und Paging. Letztendlich laufen beide Technologien gleichzeitig auf einem modernen System und ergänzen sich gegenseitig. Paging ist hinter den Segmentierungsvorgang geschalten, um Transparenz zu gewährleisten. Die durch die Segmentierung berechnete bzw. übergebene lineare Adresse entspricht ohne Paging der physikalischen. Falls Paging aktiv ist, muss noch etwas mehr getan werden. Die Umsetzung von Linearer in Physikalischer Adresse hängt vom verwendeten Paging ab. Normalerweise wird über die ersten Bits die Page-Table referenziert und über die folgenden der Pagetable-Eintrag, aus dem die Basisadresse geholt wird. Der Offset wird normalerweise beibehalten. Beschreiben Sie was bei einem Page-Fault intern alles abläuft? Während Abarbeitung einer Befehlssequenz erfolgen mehrere Seitenzugriffe Es erfolgt ein Zugriff auf eine Seite. Prozessor prüft die Seite (ist sie im Speicher?). Seite gibt Page Not Present State zurück (d.h. Seite nicht im Speicher) CPU löst Page Fault Exception aus (Siehe System-Aufruf-Deskriptoren) Betriebssystem gibt in Auftrag die Seite von Platte zu holen Prozessor aktiviert Festplattenhardware und positioniert Leseköpfe Seite wird über DMA-Transfer von Disk-To-free Memory übertragen Betriebssystem aktualisiert Pagetable einschließlich des TLB (flush TLB) Betriebssystem startet den unterbrochenen Befehl neu Nennen Sie Vorteile und Nachteile des Pagings gegenüber Segmentation-Only! Performanceerhöhung eines Multitasking-Betriebssystems Verwaltung der Swap-Datei wird durch die Verwendung konstanter Speicherblöcke einfacher nur die 4-KByte werden eingelagert, die tatsächlich benötigt werden und nicht das gesamte Segment Nachteile: Ausführung verzögert sich, weil die Adresse erst dekodiert werden muß bei Zugriff auf eine Seite/Page evtl. erst Einlagerung dieser vom Sekundärspeicher notwendig (Present-Bit) Wie kann man die Adressdekodierung beim Paging umgehen? Durch Translation Lookaside Buffer. Ein TLB ist ein assoziativer Vierwege-Cache, welcher die 32 Page-Table-Einträge aufnimmt, auf die der Prozessor zuletzt zugegriffen hat (LRU-Strategie). Ein TLB Eintrag besteht aus drei logischen Blöcken: Datenblock mit Page-Attributen und physikalische Basisadresse einer Page Tagblock enthält die oberen 17 Bit einer linearen Adresse und Schutz-Bits LRU-Block (Least Recently Used) zeigt letzten Zugriff an Page- und Segmentschutz Zuerst wirkt der Segmentschutz und danach Pageschutz. Pageschutz ist nur 2-stufig. Die inneren drei Privilegebenen sind beim Paging als Supervisor-Code geschützt. Die äußere Ebene ist User-Code. Ein Zugriffsversuch einer User-Page auf eine Supervisor-Page löst eine Exception aus. Was unterscheidet kooperatives und preemtives Multitasking? Beim kooperativen Multitasking entscheiden die Tasks selbst über die Umschaltung der Prozessorleistung. (Naives und Gutgläubiges Verfahren, daß an die Vernunft aller Tasks und somit aller Programmierer glaubt : ) Preemptives Multitasking ist echtes Multitasking. Ein externer Timer steuert die Umschaltung der Tasks. Die Tasks können somit keinen Einfluss auf die Betriebsmittelumschaltung nehmen. Kapitel 4 - Speicherhierarchie und Caches Was bedeutet die Eigenschaft Lokalität? Aus programmtechnischer Sicht wiederholen sich oft Befehle und ganze Programmteile. Somit werden Daten