Edited, memorised or added to reading queue
on 04-Sep-2019 (Wed)
Do you want BuboFlash to help you learning these things? Click here to log in or create user.
Flashcard 150890417
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itTransformations of time series that are commonly used include the power transformations: Y t = X t a , where a = ... 1/4, 1/3, 2, 3, 4, ....
Original toplevel document (pdf)
cannot see any pdfsFlashcard 1332009897228
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itA statistic is defined as a numerical quantity (such as the mean) calculated in a sample.
Original toplevel document
Subject 1. The Nature of StatisticsEstimates of these parameters taken from a sample are called statistics. Much of the field of statistics is devoted to drawing inferences from a sample concerning the value of a population parameter. <span>A statistic is defined as a numerical quantity (such as the mean) calculated in a sample. It has two different meanings. Most commonly, statistics refers to numerical data such as a company's earnings per share or average returns over the past five years. Statistics can also refer to the process of collecting, organizing, presenting, analyzing, and interpreting numerical data for the purpose of making decisions. Note that we will always know the exact composition of our sample, and by definition, we will always know the values within our sample. Ascertaining this information is the purpose of samples. Sample statistics will always be known, and can be used to estimate unknown population parameters. Hint: One way to easily remember these terms is to recall that "population" and "parameter" both start with a "p," and "sample" and "statisti
Flashcard 1332022742284
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itA parameter is a numerical quantity measuring some aspect of a population of scores.
Original toplevel document
Subject 1. The Nature of Statisticsve values associated with them, such as the average of all values in a sample and the average of all population values. Values from a population are called parameters, and values from a sample are called statistics. <span>A parameter is a numerical quantity measuring some aspect of a population of scores. The mean, for example, is a measure of central tendency. Greek letters are used to designate parameters. Parameters are rarely known and are usually estimated by statistics computed in samples. Populations can have many parameters, but investment analysts are usually only concerned with a few, such as the mean return or the standard deviation of returns. Estimates of these parameters taken from a sample are called statistics. Much of the field of statistics is devoted to drawing inferences from a sample concerning the value of a population parameter. A statistic is defined as a numerical quantity (such as the mean) calculated in a sample. It has two different meanings. Most commonly, statistics refers to
Flashcard 4344775576844
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itWhen you pass a tuple as the first argument in an assert statement, the assertion always evaluates as true and therefore never fails.
Original toplevel document
Assert Statements in Python – dbader.orgvaluate to true. I’ve been bitten by this myself in the past. I wrote a longer article about this specific issue you can check out by clicking here. Alternatively, here’s the executive summary: <span>When you pass a tuple as the first argument in an assert statement, the assertion always evaluates as true and therefore never fails. For example, this assertion will never fail: assert(1 == 2, 'This should fail') This has to do with non-empty tuples always being truthy in Python. If you pass a tuple to an assert stat
Flashcard 4344779509004
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itWhen you pass a tuple as the first argument in an assert statement, the assertion always evaluates as true and therefore never fails.
Original toplevel document
Assert Statements in Python – dbader.orgvaluate to true. I’ve been bitten by this myself in the past. I wrote a longer article about this specific issue you can check out by clicking here. Alternatively, here’s the executive summary: <span>When you pass a tuple as the first argument in an assert statement, the assertion always evaluates as true and therefore never fails. For example, this assertion will never fail: assert(1 == 2, 'This should fail') This has to do with non-empty tuples always being truthy in Python. If you pass a tuple to an assert stat
Article 4364208835852
Machine Learning
#has-images #learning #machine #statistics
Machine learning From Wikipedia, the free encyclopedia Jump to navigationJump to search For the journal, see Machine Learning (journal). "Statistical learning" redirects here. For statistical learning in linguistics, see statistical learning in language acquisition. Machine learning and data mining Problems[show] Supervised learning (classification • regression) [show] Clustering[show] Dimensionality reduction[show] Structured prediction[show] Anomaly detection[show] Artificial neural networks[show] Reinforcement learning[show] Theory[show] Machine-learning venues[show] Glossary of artificial intelligence[show] Related articles[show] v t e Machine learning (ML) is the scientific study of algorithms and statistical models that computer systems use to perform a specific task without using explicit instructions, rely
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Machine Learning
tection [show] Artificial neural networks [show] Reinforcement learning [show] Theory[show] Machine-learning venues[show] Glossary of artificial intelligence [show] Related articles[show] v t e <span>Machine learning (ML) is the scientific study of algorithms and statistical models that computer systems use to perform a specific task without using explicit instructions, relying on patterns and inference instead. It is seen as a subset of artificial intelligence . Machine learning algorithms build a mathematical model based on sample data, known as "training data ", in order to make predictions or decisions without being explicitly programmed to perform the task.[1] [2] :2 Machine learning algorithms are used in a wide variety of applications, such as email filtering and computer vision , where it is difficult or infeasible to develop a conventional algorithm for effectively performing the task. Machine learning is closely related to computational statistics , which focuses on making predictions using computers. The study of mathematical optimization delivers methods, theory and application domains to the field of machine learning. Data mining is a field of study within machine learning, and focuses on exploratory data analysis through unsupervised learning .[3] [4] In its application across business problems, machine learning is also referred to as predictive analytics . Contents 1Overview 1.1Machine learning tasks 2History and relationships to other fields 2.1Relation to data mining 2.2Relation to optimization 2.3Relation to statistics 3Theory 4Approac
Flashcard 4369499950348


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4369504931084


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4369509911820


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4369515416844


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4369520397580


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4369525378316


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4369530359052


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4369535339788


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4369540320524


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4369546611980


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4369551592716


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4369561029900


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4369569418508


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itMachine learning (ML) is the scientific study of algorithms and statistical models that computer systems use to perform a specific task without using explicit instructions, relying on patterns and inference instead. It is seen as a subset of artificial intelligence . Machine learning algorithms build a mathematical model based on sample data, known as "training data ", in order to make predictions
Original toplevel document
Machine Learningtection [show] Artificial neural networks [show] Reinforcement learning [show] Theory[show] Machine-learning venues[show] Glossary of artificial intelligence [show] Related articles[show] v t e <span>Machine learning (ML) is the scientific study of algorithms and statistical models that computer systems use to perform a specific task without using explicit instructions, relying on patterns and inference instead. It is seen as a subset of artificial intelligence . Machine learning algorithms build a mathematical model based on sample data, known as "training data ", in order to make predictions or decisions without being explicitly programmed to perform the task.[1] [2] :2 Machine learning algorithms are used in a wide variety of applications, such as email filtering and computer vision , where it is difficult or infeasible to develop a conventional algorithm for effectively performing the task. Machine learning is closely related to computational statistics , which focuses on making predictions using computers. The study of mathematical optimization delivers methods, theory and application domains to the field of machine learning. Data mining is a field of study within machine learning, and focuses on exploratory data analysis through unsupervised learning .[3] [4] In its application across business problems, machine learning is also referred to as predictive analytics . Contents 1Overview 1.1Machine learning tasks 2History and relationships to other fields 2.1Relation to data mining 2.2Relation to optimization 2.3Relation to statistics 3Theory 4Approac
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itional statistics , which focuses on making predictions using computers. The study of mathematical optimization delivers methods, theory and application domains to the field of machine learning. <span>Data mining is a field of study within machine learning, and focuses on exploratory data analysis through unsupervised learning .[3] [4] In its application across business problems, machine learning is also referred to as predictive analytics . <span>
Original toplevel document
Machine Learningtection [show] Artificial neural networks [show] Reinforcement learning [show] Theory[show] Machine-learning venues[show] Glossary of artificial intelligence [show] Related articles[show] v t e <span>Machine learning (ML) is the scientific study of algorithms and statistical models that computer systems use to perform a specific task without using explicit instructions, relying on patterns and inference instead. It is seen as a subset of artificial intelligence . Machine learning algorithms build a mathematical model based on sample data, known as "training data ", in order to make predictions or decisions without being explicitly programmed to perform the task.[1] [2] :2 Machine learning algorithms are used in a wide variety of applications, such as email filtering and computer vision , where it is difficult or infeasible to develop a conventional algorithm for effectively performing the task. Machine learning is closely related to computational statistics , which focuses on making predictions using computers. The study of mathematical optimization delivers methods, theory and application domains to the field of machine learning. Data mining is a field of study within machine learning, and focuses on exploratory data analysis through unsupervised learning .[3] [4] In its application across business problems, machine learning is also referred to as predictive analytics . Contents 1Overview 1.1Machine learning tasks 2History and relationships to other fields 2.1Relation to data mining 2.2Relation to optimization 2.3Relation to statistics 3Theory 4Approac

| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Augmenting Long-term Memory
l Nielsen | Y Combinator Research | July 2018 Related Resources Michael Nielsen on Twitter Michael Nielsen's project announcement mailing list cognitivemedium.com [imagelink] By Michael Nielsen <span>One day in the mid-1920s, a Moscow newspaper reporter named Solomon Shereshevsky entered the laboratory of the psychologist Alexander Luria. Shereshevsky's boss at the newspaper had noticed that Shereshevsky never needed to take any notes, but somehow still remembered all he was told, and had suggested he get his memory checked by an expert. Luria began testing Shereshevsky's memory. He began with simple tests, short strings of words and of numbers. Shereshevsky remembered these with ease, and so Luria gradually increased the length of the strings. But no matter how long they got, Shereshevsky could recite them back. Fascinated, Luria went on to study Shereshevsky's memory for the next 30 years. In a book summing up his research** Alexander Luria, “The Mind of a Mnemonist”, Harvard University Press (1968)., Luria reported that: [I]t appeared that there was no limit either to the capacity of S.'s memory or to the durability of the traces he retained. Experiments indicated that he had no difficulty reproducing any lengthy series of words whatever, even though these had originally been presented to him a week, a month, a year, or even many years earlier. In fact, some of these experiments designed to test his retention were performed (without his being given any warning) fifteen or sixteen years after the session in which he had originally recalled the words. Yet invariably they were successful. Such stories are fascinating. Memory is fundamental to our thinking, and the notion of having a perfect memory is seductive. At the same time, many people feel ambivalent about their ow
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Augmenting Long-term Memory
aimed at helping develop virtuoso skills with personal memory systems. But since writing such a guide wasn't my primary purpose, it may come across as a more-than-you-ever-wanted-to-know guide. <span>To conclude this introduction, a few words on what the essay won't cover. I will only briefly discuss visualization techniques such as memory palaces and the method of loci. And the essay won't describe the use of pharmaceuticals to improve memory, nor possible future brain-computer interfaces to augment memory. Those all need a separate treatment. But, as we shall see, there are already powerful ideas about personal memory systems based solely on the structuring and presentation of information. Part I: How to remember almost anyt
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Augmenting Long-term Memory
with the personal memory system Anki ** I've no affiliation at all with Anki. Other similar systems include Mnemosyne and SuperMemo . My limited use suggests Mnemosyne is very similar to Anki. <span>SuperMemo runs only on Windows, and I haven't had an opportunity to use it, though I have been influenced by essays on the SuperMemo website . I won't try to hide my enthusiasm for Anki behind a respectable facade of impartiality: it's a significant part of my life. Still, it has many limitations, and I'll mention some of them
Flashcard 4369613458700
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itMachine learning (ML) is the scientific study of algorithms and statistical models that computer systems use to perform a specific task without using explicit instructions, relying on patterns
Original toplevel document
Machine Learningtection [show] Artificial neural networks [show] Reinforcement learning [show] Theory[show] Machine-learning venues[show] Glossary of artificial intelligence [show] Related articles[show] v t e <span>Machine learning (ML) is the scientific study of algorithms and statistical models that computer systems use to perform a specific task without using explicit instructions, relying on patterns and inference instead. It is seen as a subset of artificial intelligence . Machine learning algorithms build a mathematical model based on sample data, known as "training data ", in order to make predictions or decisions without being explicitly programmed to perform the task.[1] [2] :2 Machine learning algorithms are used in a wide variety of applications, such as email filtering and computer vision , where it is difficult or infeasible to develop a conventional algorithm for effectively performing the task. Machine learning is closely related to computational statistics , which focuses on making predictions using computers. The study of mathematical optimization delivers methods, theory and application domains to the field of machine learning. Data mining is a field of study within machine learning, and focuses on exploratory data analysis through unsupervised learning .[3] [4] In its application across business problems, machine learning is also referred to as predictive analytics . Contents 1Overview 1.1Machine learning tasks 2History and relationships to other fields 2.1Relation to data mining 2.2Relation to optimization 2.3Relation to statistics 3Theory 4Approac
Flashcard 4369614507276
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itMachine learning (ML) is the scientific study of algorithms and statistical models that computer systems use to perform a specific task without using explicit instructions, relying on patterns and infer
Original toplevel document
Machine Learningtection [show] Artificial neural networks [show] Reinforcement learning [show] Theory[show] Machine-learning venues[show] Glossary of artificial intelligence [show] Related articles[show] v t e <span>Machine learning (ML) is the scientific study of algorithms and statistical models that computer systems use to perform a specific task without using explicit instructions, relying on patterns and inference instead. It is seen as a subset of artificial intelligence . Machine learning algorithms build a mathematical model based on sample data, known as "training data ", in order to make predictions or decisions without being explicitly programmed to perform the task.[1] [2] :2 Machine learning algorithms are used in a wide variety of applications, such as email filtering and computer vision , where it is difficult or infeasible to develop a conventional algorithm for effectively performing the task. Machine learning is closely related to computational statistics , which focuses on making predictions using computers. The study of mathematical optimization delivers methods, theory and application domains to the field of machine learning. Data mining is a field of study within machine learning, and focuses on exploratory data analysis through unsupervised learning .[3] [4] In its application across business problems, machine learning is also referred to as predictive analytics . Contents 1Overview 1.1Machine learning tasks 2History and relationships to other fields 2.1Relation to data mining 2.2Relation to optimization 2.3Relation to statistics 3Theory 4Approac
Flashcard 4369618963724
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itMachine learning is the scientific study of algorithms and statistical models that computer systems use to perform a specific task without using explicit instructions, relying on patterns and inference instead </s
Original toplevel document
Machine Learningtection [show] Artificial neural networks [show] Reinforcement learning [show] Theory[show] Machine-learning venues[show] Glossary of artificial intelligence [show] Related articles[show] v t e <span>Machine learning (ML) is the scientific study of algorithms and statistical models that computer systems use to perform a specific task without using explicit instructions, relying on patterns and inference instead. It is seen as a subset of artificial intelligence . Machine learning algorithms build a mathematical model based on sample data, known as "training data ", in order to make predictions or decisions without being explicitly programmed to perform the task.[1] [2] :2 Machine learning algorithms are used in a wide variety of applications, such as email filtering and computer vision , where it is difficult or infeasible to develop a conventional algorithm for effectively performing the task. Machine learning is closely related to computational statistics , which focuses on making predictions using computers. The study of mathematical optimization delivers methods, theory and application domains to the field of machine learning. Data mining is a field of study within machine learning, and focuses on exploratory data analysis through unsupervised learning .[3] [4] In its application across business problems, machine learning is also referred to as predictive analytics . Contents 1Overview 1.1Machine learning tasks 2History and relationships to other fields 2.1Relation to data mining 2.2Relation to optimization 2.3Relation to statistics 3Theory 4Approac
Flashcard 4369620274444
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itMachine learning is the scientific study of algorithms and statistical models that computer systems use to perform a specific task without using explicit instructions, relying on patterns and inference instead
Original toplevel document
Machine Learningtection [show] Artificial neural networks [show] Reinforcement learning [show] Theory[show] Machine-learning venues[show] Glossary of artificial intelligence [show] Related articles[show] v t e <span>Machine learning (ML) is the scientific study of algorithms and statistical models that computer systems use to perform a specific task without using explicit instructions, relying on patterns and inference instead. It is seen as a subset of artificial intelligence . Machine learning algorithms build a mathematical model based on sample data, known as "training data ", in order to make predictions or decisions without being explicitly programmed to perform the task.[1] [2] :2 Machine learning algorithms are used in a wide variety of applications, such as email filtering and computer vision , where it is difficult or infeasible to develop a conventional algorithm for effectively performing the task. Machine learning is closely related to computational statistics , which focuses on making predictions using computers. The study of mathematical optimization delivers methods, theory and application domains to the field of machine learning. Data mining is a field of study within machine learning, and focuses on exploratory data analysis through unsupervised learning .[3] [4] In its application across business problems, machine learning is also referred to as predictive analytics . Contents 1Overview 1.1Machine learning tasks 2History and relationships to other fields 2.1Relation to data mining 2.2Relation to optimization 2.3Relation to statistics 3Theory 4Approac
Flashcard 4369621847308
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itMachine learning is the scientific study of algorithms and statistical models that computer systems use to perform a specific task without using explicit instructions, relying on patterns and inference instead
Original toplevel document
Machine Learningtection [show] Artificial neural networks [show] Reinforcement learning [show] Theory[show] Machine-learning venues[show] Glossary of artificial intelligence [show] Related articles[show] v t e <span>Machine learning (ML) is the scientific study of algorithms and statistical models that computer systems use to perform a specific task without using explicit instructions, relying on patterns and inference instead. It is seen as a subset of artificial intelligence . Machine learning algorithms build a mathematical model based on sample data, known as "training data ", in order to make predictions or decisions without being explicitly programmed to perform the task.[1] [2] :2 Machine learning algorithms are used in a wide variety of applications, such as email filtering and computer vision , where it is difficult or infeasible to develop a conventional algorithm for effectively performing the task. Machine learning is closely related to computational statistics , which focuses on making predictions using computers. The study of mathematical optimization delivers methods, theory and application domains to the field of machine learning. Data mining is a field of study within machine learning, and focuses on exploratory data analysis through unsupervised learning .[3] [4] In its application across business problems, machine learning is also referred to as predictive analytics . Contents 1Overview 1.1Machine learning tasks 2History and relationships to other fields 2.1Relation to data mining 2.2Relation to optimization 2.3Relation to statistics 3Theory 4Approac
Flashcard 4369623420172
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itMachine learning is the scientific study of algorithms and statistical models that computer systems use to perform a specific task without using explicit instructions, relying on patterns and inference instead
Original toplevel document
Machine Learningtection [show] Artificial neural networks [show] Reinforcement learning [show] Theory[show] Machine-learning venues[show] Glossary of artificial intelligence [show] Related articles[show] v t e <span>Machine learning (ML) is the scientific study of algorithms and statistical models that computer systems use to perform a specific task without using explicit instructions, relying on patterns and inference instead. It is seen as a subset of artificial intelligence . Machine learning algorithms build a mathematical model based on sample data, known as "training data ", in order to make predictions or decisions without being explicitly programmed to perform the task.[1] [2] :2 Machine learning algorithms are used in a wide variety of applications, such as email filtering and computer vision , where it is difficult or infeasible to develop a conventional algorithm for effectively performing the task. Machine learning is closely related to computational statistics , which focuses on making predictions using computers. The study of mathematical optimization delivers methods, theory and application domains to the field of machine learning. Data mining is a field of study within machine learning, and focuses on exploratory data analysis through unsupervised learning .[3] [4] In its application across business problems, machine learning is also referred to as predictive analytics . Contents 1Overview 1.1Machine learning tasks 2History and relationships to other fields 2.1Relation to data mining 2.2Relation to optimization 2.3Relation to statistics 3Theory 4Approac
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Augmenting Long-term Memory
estimate that for an average card, I'll only need 4 to 7 minutes of total review time over the entire 20 years. Those estimates allow for occasional failed reviews, resetting the time interval. <span>That's a factor of more than 20 in savings over the more than 2 hours required with conventional flashcards. I therefore have two rules of thumb. First, if memorizing a fact seems worth 10 minutes of my time in the future, then I do it** I first saw an analysis along these lines in Gwern Branw
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Augmenting Long-term Memory
s. Those estimates allow for occasional failed reviews, resetting the time interval. That's a factor of more than 20 in savings over the more than 2 hours required with conventional flashcards. <span>I therefore have two rules of thumb. First, if memorizing a fact seems worth 10 minutes of my time in the future, then I do it** I first saw an analysis along these lines in Gwern Branwen's review of spaced repetition: Gwern Branwen, Spaced-Repetition . His numbers are slightly more optimistic than mine – he arrives at a 5-minute rule of thumb, rather than 10 minutes – but broadly consistent. Branwen's analysis is based, in turn, on an analysis in: Piotr Wozniak, Theoretical aspects of spaced repetition in learning .. Second, and superseding the first, if a fact seems striking then into Anki it goes, regardless of whether it seems worth 10 minutes of my future time or not. The reason for the exception is that many of the most important things we know are things we're not sure are going to be important, but which our intuitions tell us matter. This doesn't mean we should memorize everything. But it's worth cultivating taste in what to memorize. The single biggest change that Anki brings about is that it means memory is no longer a haphazard event, to be left to chance. Rather, it guarantees I will remember something, with mini
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Augmenting Long-term Memory
is a good basis on which to build deeper expertise. It's notable that I was reading the AlphaGo paper in support of a creative project of my own, namely, writing an article for Quanta Magazine. <span>This is important: I find Anki works much better when used in service to some personal creative project. It's tempting instead to use Anki to stockpile knowledge against some future day, to think “Oh, I should learn about the geography of Africa, or learn about World War II, or […]”. These
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Augmenting Long-term Memory
support of a creative project of my own, namely, writing an article for Quanta Magazine. This is important: I find Anki works much better when used in service to some personal creative project. <span>It's tempting instead to use Anki to stockpile knowledge against some future day, to think “Oh, I should learn about the geography of Africa, or learn about World War II, or […]”. These are goals which, for me, are intellectually appealing, but which I'm not emotionally invested in. I've tried this a bunch of times. It tends to generate cold and lifeless Anki questions, questions which I find hard to connect to upon later review, and where it's difficult to really, deeply internalize the answers. The problem is somehow in that initial idea I “should” learn about these things: intellectually, it seems like a good idea, but I've little emotional commitment. Study hard what interests you the most in the most undisciplined, irreverent and original manner possible. – Richard Feynman By contrast, when I'm reading in support of some creative pr
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Augmenting Long-term Memory
ort of some creative project, I ask much better Anki questions. I find it easier to connect to the questions and answers emotionally. I simply care more about them, and that makes a difference. <span>So while it's tempting to use Anki cards to study in preparation for some (possibly hypothetical) future use, it's better to find a way to use Anki as part of some creative project. Using Anki to do shallow reads of papers Most of my Anki-based reading is much shallower than my read of the AlphaGo paper. Rather than spending days on a paper, I'll typically spend 10
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Flashcard 4369709141260
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itData mining is a field of study within machine learning, and focuses on exploratory data analysis through unsupervised learning .
Original toplevel document
Machine Learningtection [show] Artificial neural networks [show] Reinforcement learning [show] Theory[show] Machine-learning venues[show] Glossary of artificial intelligence [show] Related articles[show] v t e <span>Machine learning (ML) is the scientific study of algorithms and statistical models that computer systems use to perform a specific task without using explicit instructions, relying on patterns and inference instead. It is seen as a subset of artificial intelligence . Machine learning algorithms build a mathematical model based on sample data, known as "training data ", in order to make predictions or decisions without being explicitly programmed to perform the task.[1] [2] :2 Machine learning algorithms are used in a wide variety of applications, such as email filtering and computer vision , where it is difficult or infeasible to develop a conventional algorithm for effectively performing the task. Machine learning is closely related to computational statistics , which focuses on making predictions using computers. The study of mathematical optimization delivers methods, theory and application domains to the field of machine learning. Data mining is a field of study within machine learning, and focuses on exploratory data analysis through unsupervised learning .[3] [4] In its application across business problems, machine learning is also referred to as predictive analytics . Contents 1Overview 1.1Machine learning tasks 2History and relationships to other fields 2.1Relation to data mining 2.2Relation to optimization 2.3Relation to statistics 3Theory 4Approac
Flashcard 4369710714124
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itData mining is a field of study within machine learning, and focuses on exploratory data analysis through unsupervised learning .
Original toplevel document
Machine Learningtection [show] Artificial neural networks [show] Reinforcement learning [show] Theory[show] Machine-learning venues[show] Glossary of artificial intelligence [show] Related articles[show] v t e <span>Machine learning (ML) is the scientific study of algorithms and statistical models that computer systems use to perform a specific task without using explicit instructions, relying on patterns and inference instead. It is seen as a subset of artificial intelligence . Machine learning algorithms build a mathematical model based on sample data, known as "training data ", in order to make predictions or decisions without being explicitly programmed to perform the task.[1] [2] :2 Machine learning algorithms are used in a wide variety of applications, such as email filtering and computer vision , where it is difficult or infeasible to develop a conventional algorithm for effectively performing the task. Machine learning is closely related to computational statistics , which focuses on making predictions using computers. The study of mathematical optimization delivers methods, theory and application domains to the field of machine learning. Data mining is a field of study within machine learning, and focuses on exploratory data analysis through unsupervised learning .[3] [4] In its application across business problems, machine learning is also referred to as predictive analytics . Contents 1Overview 1.1Machine learning tasks 2History and relationships to other fields 2.1Relation to data mining 2.2Relation to optimization 2.3Relation to statistics 3Theory 4Approac
Flashcard 4369712286988
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itData mining is a field of study within machine learning, and focuses on exploratory data analysis through unsupervised learning .
Original toplevel document
Machine Learningtection [show] Artificial neural networks [show] Reinforcement learning [show] Theory[show] Machine-learning venues[show] Glossary of artificial intelligence [show] Related articles[show] v t e <span>Machine learning (ML) is the scientific study of algorithms and statistical models that computer systems use to perform a specific task without using explicit instructions, relying on patterns and inference instead. It is seen as a subset of artificial intelligence . Machine learning algorithms build a mathematical model based on sample data, known as "training data ", in order to make predictions or decisions without being explicitly programmed to perform the task.[1] [2] :2 Machine learning algorithms are used in a wide variety of applications, such as email filtering and computer vision , where it is difficult or infeasible to develop a conventional algorithm for effectively performing the task. Machine learning is closely related to computational statistics , which focuses on making predictions using computers. The study of mathematical optimization delivers methods, theory and application domains to the field of machine learning. Data mining is a field of study within machine learning, and focuses on exploratory data analysis through unsupervised learning .[3] [4] In its application across business problems, machine learning is also referred to as predictive analytics . Contents 1Overview 1.1Machine learning tasks 2History and relationships to other fields 2.1Relation to data mining 2.2Relation to optimization 2.3Relation to statistics 3Theory 4Approac
Flashcard 4369713859852
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itData mining is a field of study within machine learning, and focuses on exploratory data analysis through unsupervised learning .
Original toplevel document
Machine Learningtection [show] Artificial neural networks [show] Reinforcement learning [show] Theory[show] Machine-learning venues[show] Glossary of artificial intelligence [show] Related articles[show] v t e <span>Machine learning (ML) is the scientific study of algorithms and statistical models that computer systems use to perform a specific task without using explicit instructions, relying on patterns and inference instead. It is seen as a subset of artificial intelligence . Machine learning algorithms build a mathematical model based on sample data, known as "training data ", in order to make predictions or decisions without being explicitly programmed to perform the task.[1] [2] :2 Machine learning algorithms are used in a wide variety of applications, such as email filtering and computer vision , where it is difficult or infeasible to develop a conventional algorithm for effectively performing the task. Machine learning is closely related to computational statistics , which focuses on making predictions using computers. The study of mathematical optimization delivers methods, theory and application domains to the field of machine learning. Data mining is a field of study within machine learning, and focuses on exploratory data analysis through unsupervised learning .[3] [4] In its application across business problems, machine learning is also referred to as predictive analytics . Contents 1Overview 1.1Machine learning tasks 2History and relationships to other fields 2.1Relation to data mining 2.2Relation to optimization 2.3Relation to statistics 3Theory 4Approac
Flashcard 4369715432716
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itData mining is a field of study within machine learning, and focuses on exploratory data analysis through unsupervised learning .
Original toplevel document
Machine Learningtection [show] Artificial neural networks [show] Reinforcement learning [show] Theory[show] Machine-learning venues[show] Glossary of artificial intelligence [show] Related articles[show] v t e <span>Machine learning (ML) is the scientific study of algorithms and statistical models that computer systems use to perform a specific task without using explicit instructions, relying on patterns and inference instead. It is seen as a subset of artificial intelligence . Machine learning algorithms build a mathematical model based on sample data, known as "training data ", in order to make predictions or decisions without being explicitly programmed to perform the task.[1] [2] :2 Machine learning algorithms are used in a wide variety of applications, such as email filtering and computer vision , where it is difficult or infeasible to develop a conventional algorithm for effectively performing the task. Machine learning is closely related to computational statistics , which focuses on making predictions using computers. The study of mathematical optimization delivers methods, theory and application domains to the field of machine learning. Data mining is a field of study within machine learning, and focuses on exploratory data analysis through unsupervised learning .[3] [4] In its application across business problems, machine learning is also referred to as predictive analytics . Contents 1Overview 1.1Machine learning tasks 2History and relationships to other fields 2.1Relation to data mining 2.2Relation to optimization 2.3Relation to statistics 3Theory 4Approac
Flashcard 4369718840588
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itSuperMemo runs only on Windows, and I haven't had an opportunity to use it, though I have been influenced by essays on the SuperMemo website .
Original toplevel document
Augmenting Long-term Memorywith the personal memory system Anki ** I've no affiliation at all with Anki. Other similar systems include Mnemosyne and SuperMemo . My limited use suggests Mnemosyne is very similar to Anki. <span>SuperMemo runs only on Windows, and I haven't had an opportunity to use it, though I have been influenced by essays on the SuperMemo website . I won't try to hide my enthusiasm for Anki behind a respectable facade of impartiality: it's a significant part of my life. Still, it has many limitations, and I'll mention some of them
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Flashcard 4369723559180
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itIt is tempting to use Anki cards to study for a hypothetical future use but it's better to use Anki as part of a real world active creative project.
Original toplevel document
Augmenting Long-term Memoryort of some creative project, I ask much better Anki questions. I find it easier to connect to the questions and answers emotionally. I simply care more about them, and that makes a difference. <span>So while it's tempting to use Anki cards to study in preparation for some (possibly hypothetical) future use, it's better to find a way to use Anki as part of some creative project. Using Anki to do shallow reads of papers Most of my Anki-based reading is much shallower than my read of the AlphaGo paper. Rather than spending days on a paper, I'll typically spend 10
Flashcard 4369725132044
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itIt is tempting to use Anki cards to study for a hypothetical future use but it's better to use Anki as part of a real world active creative project.
Original toplevel document
Augmenting Long-term Memoryort of some creative project, I ask much better Anki questions. I find it easier to connect to the questions and answers emotionally. I simply care more about them, and that makes a difference. <span>So while it's tempting to use Anki cards to study in preparation for some (possibly hypothetical) future use, it's better to find a way to use Anki as part of some creative project. Using Anki to do shallow reads of papers Most of my Anki-based reading is much shallower than my read of the AlphaGo paper. Rather than spending days on a paper, I'll typically spend 10
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Augmenting Long-term Memory
ally learning the Unix command line. I'd only ever learned the most basic commands. Learning the command line is a superpower for people who program, so it seemed highly desirable to know well. <span>So, for fun, I wondered if it might be possible to use Anki to essentially completely memorize a (short) book about the Unix command line. It was! I chose O'Reilly Media's “Macintosh Terminal Pocket Guide”, by Daniel Barrett. I don't mean I literally memorized the entire text of the book** I later did an experiment with Charles Dickens' “A Tale of Two Cities”, seeing if it might actually be possible to memorize the entire text. After a few weeks I concluded that it would be possible, but would not be worth the time. So I deleted all the cards. An interesting thing has occurred post-deletion: the first few sentences of the book have gradually decayed in my memory, and I now have no more than fragments. I occasionally wonder what the impact would be of memorizing a good book in its entirety; I wouldn't be surprised if it greatly influenced my own language and writing.. But I did memorize much of the conceptual knowledge in the book, as well as the names, syntax, and options for most of the commands in the book. The exceptions were things I had no frame of reference to imagine using. But I did memorize most things I could imagine using. In the end I covered perhaps 60 to 70 percent of the book, skipping or skimming pieces that didn't seem relevant to me. Still, my knowledge of the command line increased enormously. Choosing this rather ludicrous, albeit extremely useful, goal gave me a great deal of confidence in Anki. It was exciting, making it obvious that Anki would make it easy to learn things
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Augmenting Long-term Memory
gine using. In the end I covered perhaps 60 to 70 percent of the book, skipping or skimming pieces that didn't seem relevant to me. Still, my knowledge of the command line increased enormously. <span>Choosing this rather ludicrous, albeit extremely useful, goal gave me a great deal of confidence in Anki. It was exciting, making it obvious that Anki would make it easy to learn things that would formerly have been quite tedious and difficult for me to learn. This confidence, in turn, made it much easier to build an Anki habit. At the same time, the project also helped me learn the Anki interface, and got me to experiment with different ways of posing questions. That is, it helped me build the skills necessary to use Anki well. Using Anki to thoroughly read a research paper in an unfamiliar field I find Anki a great help when reading research papers, particularly in fields outside my expertise. As an example o
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Augmenting Long-term Memory
e time, the project also helped me learn the Anki interface, and got me to experiment with different ways of posing questions. That is, it helped me build the skills necessary to use Anki well. <span>Using Anki to thoroughly read a research paper in an unfamiliar field I find Anki a great help when reading research papers, particularly in fields outside my expertise. As an example of how this can work, I'll describe my experience reading a 2016 paper** David Silver, Aja Huang, Chris J. Maddison, Arthur Guez et al, Mastering the game of Go with deep neural networks and tree search , Nature (2016). describing AlphaGo, the computer system from Google DeepMind that beat some of the world's strongest players of the game Go. After the match where AlphaGo beat Lee Sedol, one of the strongest human Go players in history, I suggested to Quanta Magazine that I write an article about the system** Michael Nielsen, Is AlphaGo Really Such a Big Deal? , Quanta (2016).. AlphaGo was a hot media topic at the time, and the most common angle in stories was human interest, viewing AlphaGo as part of a long-standing human-versus-machine narrative, with a few technical details filled in, mostly as color. I wanted to take a different angle. Through the 1990s and first decade of the 2000s, I believed human-or-better general artificial intelligence was far, far away. The reason was that over that time researchers made only slow progress building systems to do intuitive pattern matching, of the kind that underlies human sight and hearing, as well as in playing games such as Go. Despite enormous effort by AI researchers, many pattern-matching feats which humans find effortless remained impossible for machines. While we made only very slow progress on this set of problems for a long time, around 2011 progress began to speed up, driven by advances in deep neural networks. For instance, machine vision systems rapidly went from being terrible to being comparable to human beings for certain limited tasks. By the time AlphaGo was released, it was no longer correct to say we had no idea how to build computer systems to do intuitive pattern matching. While we hadn't yet nailed the problem, we were making rapid progress. AlphaGo was a big part of that story, and I wanted my article to explore this notion of building computer systems to capture human intuition. While I was excited, writing such an article was going to be difficult. It was going to require a deeper understanding of the technical details of AlphaGo than a typical journalistic article. Fortunately, I knew a fair amount about neural networks – I'd written a book about them** Michael A. Nielsen, "Neural Networks and Deep Learning" , Determination Press (2015).. But I knew nothing about the game of Go, or about many of the ideas used by AlphaGo, based on a field known as reinforcement learning. I was going to need to learn this material from scratch, and to write a good article I was going to need to really understand the underlying technical material. Here's how I went about it. I began with the AlphaGo paper itself. I began reading it quickly, almost skimming. I wasn't looking for a comprehensive understanding. Rather, I was doing two things. One, I was trying to simply identify the most important ideas in the paper. What were the names of the key techniques I'd need to learn about? Second, there was a kind of hoovering process, looking for basic facts that I could understand easily, and that would obviously benefit me. Things like basic terminology, the rules of Go, and so on. Here's a few examples of the kind of question I entered into Anki at this stage: “What's the size of a Go board?”; “Who plays first in Go?”; “How many human game positions did AlphaGo learn from?”; “Where did AlphaGo get its training data?”; “What were the names of the two main types of neural network AlphaGo used?” As you can see, these are all elementary questions. They're the kind of thing that are very easily picked up during an initial pass over the paper, with occasional digressions to search Google and Wikipedia, and so on. Furthermore, while these facts were easy to pick up in isolation, they also seemed likely to be useful in building a deeper understanding of other material in the paper. I made several rapid passes over the paper in this way, each time getting deeper and deeper. At this stage I wasn't trying to obtain anything like a complete understanding of AlphaGo. Rather, I was trying to build up my background understanding. At all times, if something wasn't easy to understand, I didn't worry about it, I just keep going. But as I made repeat passes, the range of things that were easy to understand grew and grew. I found myself adding questions about the types of features used as inputs to AlphaGo's neural networks, basic facts about the structure of the networks, and so on. After five or six such passes over the paper, I went back and attempted a thorough read. This time the purpose was to understand AlphaGo in detail. By now I understood much of the background context, and it was relatively easy to do a thorough read, certainly far easier than coming into the paper cold. Don't get me wrong: it was still challenging. But it was far easier than it would have been otherwise. After doing one thorough pass over the AlphaGo paper, I made a second thorough pass, in a similar vein. Yet more fell into place. By this time, I understood the AlphaGo system reasonably well. Many of the questions I was putting into Anki were high level, sometimes on the verge of original research directions. I certainly understood AlphaGo well enough that I was confident I could write the sections of my article dealing with it. (In practice, my article ranged over several systems, not just AlphaGo, and I had to learn about those as well, using a similar process, though I didn't go as deep.) I continued to add questions as I wrote my article, ending up adding several hundred questions in total. But by this point the hardest work had been done. Of course, instead of using Anki I could have taken conventional notes, using a similar process to build up an understanding of the paper. But using Anki gave me confidence I would retain much of the understanding over the long term. A year or so later DeepMind released papers describing followup systems, known as AlphaGo Zero and AlphaZero** For AlphaGo Zero, see: David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou et al, Mastering the game of Go without human knowledge , Nature (2017). For AlphaZero, see: David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou et al, Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm (2017).. Despite the fact that I'd thought little about AlphaGo or reinforcement learning in the intervening time, I found I could read those followup papers with ease. While I didn't attempt to understand those papers as thoroughly as the initial AlphaGo paper, I found I could get a pretty good understanding of the papers in less than an hour. I'd retained much of my earlier understanding! By contrast, had I used conventional note-taking in my original reading of the AlphaGo paper, my understanding would have more rapidly evaporated, and it would have taken longer to read the later papers. And so using Anki in this way gives confidence you will retain understanding over the long term. This confidence, in turn, makes the initial act of understanding more pleasurable, since you believe you're learning something for the long haul, not something you'll forget in a day or a week. OK, but what does one do with it? … [N]ow that I have all this power – a mechanical golem that will never forget and never let me forget whatever I chose to – what do I choose to remember? – Gwern Branwen This entire process took a few days of my time, spread over a few weeks. That's a lot of work. However, the payoff was that I got a pretty good basic grounding in modern deep reinforcement learning. This is an immensely important field, of great use in robotics, and many researchers believe it will play an important role in achieving general artificial intelligence. With a few days work I'd gone from knowing nothing about deep reinforcement learning to a durable understanding of a key paper in the field, a paper that made use of many techniques that were used across the entire field. Of course, I was still a long way from being an expert. There were many important details about AlphaGo I hadn't understood, and I would have had to do far more work to build my own system in the area. But this foundational kind of understanding is a good basis on which to build deeper expertise. It's notable that I was reading the AlphaGo paper in support of a creative project of my own, namely, writing an article for Quanta Magazine. This is important: I find Anki works much b
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Augmenting Long-term Memory
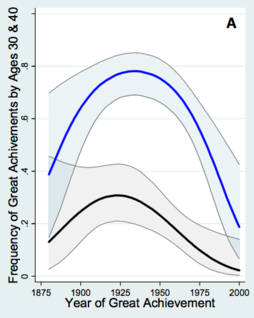
difference. So while it's tempting to use Anki cards to study in preparation for some (possibly hypothetical) future use, it's better to find a way to use Anki as part of some creative project. <span>Using Anki to do shallow reads of papers Most of my Anki-based reading is much shallower than my read of the AlphaGo paper. Rather than spending days on a paper, I'll typically spend 10 to 60 minutes, sometimes longer for very good papers. Here's a few notes on some patterns I've found useful in shallow reading. As mentioned above, I'm usually doing such reading as part of the background research for some project. I will find a new article (or set of articles), and typically spend a few minutes assessing it. Does the article seem likely to contain substantial insight or provocation relevant to my project – new questions, new ideas, new methods, new results? If so, I'll have a read. This doesn't mean reading every word in the paper. Rather, I'll add to Anki questions about the core claims, core questions, and core ideas of the paper. It's particularly helpful to extract Anki questions from the abstract, introduction, conclusion, figures, and figure captions. Typically I will extract anywhere from 5 to 20 Anki questions from the paper. It's usually a bad idea to extract fewer than 5 questions – doing so tends to leave the paper as a kind of isolated orphan in my memory. Later I find it difficult to feel much connection to those questions. Put another way: if a paper is so uninteresting that it's not possible to add 5 good questions about it, it's usually better to add no questions at all. One failure mode of this process is if you Ankify** I.e., enter into Anki. Also useful are forms such as Ankification etc. misleading work. Many papers contain wrong or misleading statements, and if you commit such items to memory, you're actively making yourself stupider. How to avoid Ankifying misleading work? As an example, let me describe how I Ankified a paper I recently read, by the economists Benjamin Jones and Bruce Weinberg** Benjamin F. Jones and Bruce A. Weinberg, Age Dynamics in Scientific Creativity , Proceedings of the National Academy of Sciences (2011).. The paper studies the ages at which scientists make their greatest discoveries. I should say at the outset: I have no reason to think this paper is misleading! But it's also worth being cautious. As an example of that caution, one of the questions I added to Anki was: “What does Jones 2011 claim is the average age at which physics Nobelists made their prizewinning discovery, over 1980-2011?” (Answer: 48). Another variant question was: “Which paper claimed that physics Nobelists made their prizewinning discovery at average age 48, over the period 1980-2011?” (Answer: Jones 2011). And so on. Such questions qualify the underlying claim: we now know it was a claim made in Jones 2011, and that we're relying on the quality of Jones and Weinberg's data analysis. In fact, I haven't examined that analysis carefully enough to regard it as a fact that the average age of those Nobelists is 48. But it is certainly a fact that their paper claimed it was 48. Those are different things, and the latter is better to Ankify. If I'm particularly concerned about the quality of the analysis, I may add one or more questions about what makes such work difficult, e.g.: “What's one challenge in determining the age of Nobel winners at the time of their discovery, as discussed in Jones 2011?” Good answers include: the difficulty of figuring out which paper contained the Nobel-winning work; the fact that publication of papers is sometimes delayed by years; that sometimes work is spread over multiple papers; and so on. Thinking about such challenges reminds me that if Jones and Weinberg were sloppy, or simply made an understandable mistake, their numbers might be off. Now, it so happens that for this particular paper, I'm not too worried about such issues. And so I didn't Ankify any such question. But it's worth being careful in framing questions so you're not misleading yourself. Another useful pattern while reading papers is Ankifying figures. For instance, here's a graph from Jones 2011 showing the probability a physicist made their prizewinning discovery by a
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Augmenting Long-term Memory
for this particular paper, I'm not too worried about such issues. And so I didn't Ankify any such question. But it's worth being careful in framing questions so you're not misleading yourself. <span>Another useful pattern while reading papers is Ankifying figures. For instance, here's a graph from Jones 2011 showing the probability a physicist made their prizewinning discovery by age 40 (blue line) and by age 30 (black line): I have an Anki question which simply says: “Visualize the graph Jones 2011 made of the probability curves for physicists making their prizewinning discoveries by age 30 and 40”. The answer is the image shown above, and I count myself as successful if my mental image is roughly along those lines. I could deepen my engagement with the graph by adding questions such as: “In Jones 2011's graph of physics prizewinning discoveries, what is the peak probability of great achievement by age 40 [i.e., the highest point in the blue line in the graph above]?” (Answer: about 0.8.) Indeed, one could easily add dozens of interesting questions about this graph. I haven't done that, because of the time commitment associated to such questions. But I do find the broad shape of the graph fascinating, and it's also useful to know the graph exists, and where to consult it if I want more details. I said above that I typically spend 10 to 60 minutes Ankifying a paper, with the duration depending on my judgment of the value I'm getting from the paper. However, if I'm learning a gr
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itknown as reinforcement learning. I was going to need to learn this material from scratch, and to write a good article I was going to need to really understand the underlying technical material. <span>Here's how I went about it. I began with the AlphaGo paper itself. I began reading it quickly, almost skimming. I wasn't looking for a comprehensive understanding. Rather, I was doing two things. One, I was trying to simply identify the most important ideas in the paper. What were the names of the key techniques I'd need to learn about? Second, there was a kind of hoovering process, looking for basic facts that I could understand easily, and that would obviously benefit me. Things like basic terminology, the rules of Go, and so on. Here's a few examples of the kind of question I entered into Anki at this stage: “What's the size of a Go board?”; “Who plays first in Go?”; “How many human game positions did AlphaGo learn from?”; “Where did AlphaGo get its training data?”; “What were the names of the two main types of neural network AlphaGo used?” As you can see, these are all elementary questions. They're the kind of thing that are very easily picked up during an initial pass over the paper, with occasional digressions to search Google and Wikipedia, and so on. Furthermore, while these facts were easy to pick up in isolation, they also seemed likely to be useful in building a deeper understanding of other material in the paper. I made several rapid passes over the paper in this way, each time getting deeper and deeper. At this stage I wasn't trying to obtain anything like a complete understanding of AlphaGo. Rather, I was trying to build up my background understanding. At all times, if something wasn't easy to understand, I didn't worry about it, I just keep going. But as I made repeat passes, the range of things that were easy to understand grew and grew. I found myself adding questions about the types of features used as inputs to AlphaGo's neural networks, basic facts about the structure of the networks, and so on. After five or six such passes over the paper, I went back and attempted a thorough read. This time the purpose was to understand AlphaGo in detail. By now I understood much of the backg
Original toplevel document
Augmenting Long-term Memorye time, the project also helped me learn the Anki interface, and got me to experiment with different ways of posing questions. That is, it helped me build the skills necessary to use Anki well. <span>Using Anki to thoroughly read a research paper in an unfamiliar field I find Anki a great help when reading research papers, particularly in fields outside my expertise. As an example of how this can work, I'll describe my experience reading a 2016 paper** David Silver, Aja Huang, Chris J. Maddison, Arthur Guez et al, Mastering the game of Go with deep neural networks and tree search , Nature (2016). describing AlphaGo, the computer system from Google DeepMind that beat some of the world's strongest players of the game Go. After the match where AlphaGo beat Lee Sedol, one of the strongest human Go players in history, I suggested to Quanta Magazine that I write an article about the system** Michael Nielsen, Is AlphaGo Really Such a Big Deal? , Quanta (2016).. AlphaGo was a hot media topic at the time, and the most common angle in stories was human interest, viewing AlphaGo as part of a long-standing human-versus-machine narrative, with a few technical details filled in, mostly as color. I wanted to take a different angle. Through the 1990s and first decade of the 2000s, I believed human-or-better general artificial intelligence was far, far away. The reason was that over that time researchers made only slow progress building systems to do intuitive pattern matching, of the kind that underlies human sight and hearing, as well as in playing games such as Go. Despite enormous effort by AI researchers, many pattern-matching feats which humans find effortless remained impossible for machines. While we made only very slow progress on this set of problems for a long time, around 2011 progress began to speed up, driven by advances in deep neural networks. For instance, machine vision systems rapidly went from being terrible to being comparable to human beings for certain limited tasks. By the time AlphaGo was released, it was no longer correct to say we had no idea how to build computer systems to do intuitive pattern matching. While we hadn't yet nailed the problem, we were making rapid progress. AlphaGo was a big part of that story, and I wanted my article to explore this notion of building computer systems to capture human intuition. While I was excited, writing such an article was going to be difficult. It was going to require a deeper understanding of the technical details of AlphaGo than a typical journalistic article. Fortunately, I knew a fair amount about neural networks – I'd written a book about them** Michael A. Nielsen, "Neural Networks and Deep Learning" , Determination Press (2015).. But I knew nothing about the game of Go, or about many of the ideas used by AlphaGo, based on a field known as reinforcement learning. I was going to need to learn this material from scratch, and to write a good article I was going to need to really understand the underlying technical material. Here's how I went about it. I began with the AlphaGo paper itself. I began reading it quickly, almost skimming. I wasn't looking for a comprehensive understanding. Rather, I was doing two things. One, I was trying to simply identify the most important ideas in the paper. What were the names of the key techniques I'd need to learn about? Second, there was a kind of hoovering process, looking for basic facts that I could understand easily, and that would obviously benefit me. Things like basic terminology, the rules of Go, and so on. Here's a few examples of the kind of question I entered into Anki at this stage: “What's the size of a Go board?”; “Who plays first in Go?”; “How many human game positions did AlphaGo learn from?”; “Where did AlphaGo get its training data?”; “What were the names of the two main types of neural network AlphaGo used?” As you can see, these are all elementary questions. They're the kind of thing that are very easily picked up during an initial pass over the paper, with occasional digressions to search Google and Wikipedia, and so on. Furthermore, while these facts were easy to pick up in isolation, they also seemed likely to be useful in building a deeper understanding of other material in the paper. I made several rapid passes over the paper in this way, each time getting deeper and deeper. At this stage I wasn't trying to obtain anything like a complete understanding of AlphaGo. Rather, I was trying to build up my background understanding. At all times, if something wasn't easy to understand, I didn't worry about it, I just keep going. But as I made repeat passes, the range of things that were easy to understand grew and grew. I found myself adding questions about the types of features used as inputs to AlphaGo's neural networks, basic facts about the structure of the networks, and so on. After five or six such passes over the paper, I went back and attempted a thorough read. This time the purpose was to understand AlphaGo in detail. By now I understood much of the background context, and it was relatively easy to do a thorough read, certainly far easier than coming into the paper cold. Don't get me wrong: it was still challenging. But it was far easier than it would have been otherwise. After doing one thorough pass over the AlphaGo paper, I made a second thorough pass, in a similar vein. Yet more fell into place. By this time, I understood the AlphaGo system reasonably well. Many of the questions I was putting into Anki were high level, sometimes on the verge of original research directions. I certainly understood AlphaGo well enough that I was confident I could write the sections of my article dealing with it. (In practice, my article ranged over several systems, not just AlphaGo, and I had to learn about those as well, using a similar process, though I didn't go as deep.) I continued to add questions as I wrote my article, ending up adding several hundred questions in total. But by this point the hardest work had been done. Of course, instead of using Anki I could have taken conventional notes, using a similar process to build up an understanding of the paper. But using Anki gave me confidence I would retain much of the understanding over the long term. A year or so later DeepMind released papers describing followup systems, known as AlphaGo Zero and AlphaZero** For AlphaGo Zero, see: David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou et al, Mastering the game of Go without human knowledge , Nature (2017). For AlphaZero, see: David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou et al, Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm (2017).. Despite the fact that I'd thought little about AlphaGo or reinforcement learning in the intervening time, I found I could read those followup papers with ease. While I didn't attempt to understand those papers as thoroughly as the initial AlphaGo paper, I found I could get a pretty good understanding of the papers in less than an hour. I'd retained much of my earlier understanding! By contrast, had I used conventional note-taking in my original reading of the AlphaGo paper, my understanding would have more rapidly evaporated, and it would have taken longer to read the later papers. And so using Anki in this way gives confidence you will retain understanding over the long term. This confidence, in turn, makes the initial act of understanding more pleasurable, since you believe you're learning something for the long haul, not something you'll forget in a day or a week. OK, but what does one do with it? … [N]ow that I have all this power – a mechanical golem that will never forget and never let me forget whatever I chose to – what do I choose to remember? – Gwern Branwen This entire process took a few days of my time, spread over a few weeks. That's a lot of work. However, the payoff was that I got a pretty good basic grounding in modern deep reinforcement learning. This is an immensely important field, of great use in robotics, and many researchers believe it will play an important role in achieving general artificial intelligence. With a few days work I'd gone from knowing nothing about deep reinforcement learning to a durable understanding of a key paper in the field, a paper that made use of many techniques that were used across the entire field. Of course, I was still a long way from being an expert. There were many important details about AlphaGo I hadn't understood, and I would have had to do far more work to build my own system in the area. But this foundational kind of understanding is a good basis on which to build deeper expertise. It's notable that I was reading the AlphaGo paper in support of a creative project of my own, namely, writing an article for Quanta Magazine. This is important: I find Anki works much b
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itto understand grew and grew. I found myself adding questions about the types of features used as inputs to AlphaGo's neural networks, basic facts about the structure of the networks, and so on. <span>After five or six such passes over the paper, I went back and attempted a thorough read. This time the purpose was to understand AlphaGo in detail. By now I understood much of the background context, and it was relatively easy to do a thorough read, certainly far easier than coming into the paper cold. Don't get me wrong: it was still challenging. But it was far easier than it would have been otherwise. After doing one thorough pass over the AlphaGo paper, I made a second thorough pass, in a similar vein. Yet more fell into place. By this time, I understood the AlphaGo system reasonably well. Many of the questions I was putting into Anki were high level, sometimes on the verge of original research directions. I certainly understood AlphaGo well enough that I was confident I could write the sections of my article dealing with it. (In practice, my article ranged over several systems, not just AlphaGo, and I had to learn about those as well, using a similar process, though I didn't go as deep.) I continued to add questions as I wrote my article, ending up adding several hundred questions in total. But by this point the hardest work had been done. Of course, instead of using Anki I could have taken conventional notes, using a similar process to build up an understanding of the paper. But using Anki gave me confidence I would reta
Original toplevel document
Augmenting Long-term Memorye time, the project also helped me learn the Anki interface, and got me to experiment with different ways of posing questions. That is, it helped me build the skills necessary to use Anki well. <span>Using Anki to thoroughly read a research paper in an unfamiliar field I find Anki a great help when reading research papers, particularly in fields outside my expertise. As an example of how this can work, I'll describe my experience reading a 2016 paper** David Silver, Aja Huang, Chris J. Maddison, Arthur Guez et al, Mastering the game of Go with deep neural networks and tree search , Nature (2016). describing AlphaGo, the computer system from Google DeepMind that beat some of the world's strongest players of the game Go. After the match where AlphaGo beat Lee Sedol, one of the strongest human Go players in history, I suggested to Quanta Magazine that I write an article about the system** Michael Nielsen, Is AlphaGo Really Such a Big Deal? , Quanta (2016).. AlphaGo was a hot media topic at the time, and the most common angle in stories was human interest, viewing AlphaGo as part of a long-standing human-versus-machine narrative, with a few technical details filled in, mostly as color. I wanted to take a different angle. Through the 1990s and first decade of the 2000s, I believed human-or-better general artificial intelligence was far, far away. The reason was that over that time researchers made only slow progress building systems to do intuitive pattern matching, of the kind that underlies human sight and hearing, as well as in playing games such as Go. Despite enormous effort by AI researchers, many pattern-matching feats which humans find effortless remained impossible for machines. While we made only very slow progress on this set of problems for a long time, around 2011 progress began to speed up, driven by advances in deep neural networks. For instance, machine vision systems rapidly went from being terrible to being comparable to human beings for certain limited tasks. By the time AlphaGo was released, it was no longer correct to say we had no idea how to build computer systems to do intuitive pattern matching. While we hadn't yet nailed the problem, we were making rapid progress. AlphaGo was a big part of that story, and I wanted my article to explore this notion of building computer systems to capture human intuition. While I was excited, writing such an article was going to be difficult. It was going to require a deeper understanding of the technical details of AlphaGo than a typical journalistic article. Fortunately, I knew a fair amount about neural networks – I'd written a book about them** Michael A. Nielsen, "Neural Networks and Deep Learning" , Determination Press (2015).. But I knew nothing about the game of Go, or about many of the ideas used by AlphaGo, based on a field known as reinforcement learning. I was going to need to learn this material from scratch, and to write a good article I was going to need to really understand the underlying technical material. Here's how I went about it. I began with the AlphaGo paper itself. I began reading it quickly, almost skimming. I wasn't looking for a comprehensive understanding. Rather, I was doing two things. One, I was trying to simply identify the most important ideas in the paper. What were the names of the key techniques I'd need to learn about? Second, there was a kind of hoovering process, looking for basic facts that I could understand easily, and that would obviously benefit me. Things like basic terminology, the rules of Go, and so on. Here's a few examples of the kind of question I entered into Anki at this stage: “What's the size of a Go board?”; “Who plays first in Go?”; “How many human game positions did AlphaGo learn from?”; “Where did AlphaGo get its training data?”; “What were the names of the two main types of neural network AlphaGo used?” As you can see, these are all elementary questions. They're the kind of thing that are very easily picked up during an initial pass over the paper, with occasional digressions to search Google and Wikipedia, and so on. Furthermore, while these facts were easy to pick up in isolation, they also seemed likely to be useful in building a deeper understanding of other material in the paper. I made several rapid passes over the paper in this way, each time getting deeper and deeper. At this stage I wasn't trying to obtain anything like a complete understanding of AlphaGo. Rather, I was trying to build up my background understanding. At all times, if something wasn't easy to understand, I didn't worry about it, I just keep going. But as I made repeat passes, the range of things that were easy to understand grew and grew. I found myself adding questions about the types of features used as inputs to AlphaGo's neural networks, basic facts about the structure of the networks, and so on. After five or six such passes over the paper, I went back and attempted a thorough read. This time the purpose was to understand AlphaGo in detail. By now I understood much of the background context, and it was relatively easy to do a thorough read, certainly far easier than coming into the paper cold. Don't get me wrong: it was still challenging. But it was far easier than it would have been otherwise. After doing one thorough pass over the AlphaGo paper, I made a second thorough pass, in a similar vein. Yet more fell into place. By this time, I understood the AlphaGo system reasonably well. Many of the questions I was putting into Anki were high level, sometimes on the verge of original research directions. I certainly understood AlphaGo well enough that I was confident I could write the sections of my article dealing with it. (In practice, my article ranged over several systems, not just AlphaGo, and I had to learn about those as well, using a similar process, though I didn't go as deep.) I continued to add questions as I wrote my article, ending up adding several hundred questions in total. But by this point the hardest work had been done. Of course, instead of using Anki I could have taken conventional notes, using a similar process to build up an understanding of the paper. But using Anki gave me confidence I would retain much of the understanding over the long term. A year or so later DeepMind released papers describing followup systems, known as AlphaGo Zero and AlphaZero** For AlphaGo Zero, see: David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou et al, Mastering the game of Go without human knowledge , Nature (2017). For AlphaZero, see: David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou et al, Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm (2017).. Despite the fact that I'd thought little about AlphaGo or reinforcement learning in the intervening time, I found I could read those followup papers with ease. While I didn't attempt to understand those papers as thoroughly as the initial AlphaGo paper, I found I could get a pretty good understanding of the papers in less than an hour. I'd retained much of my earlier understanding! By contrast, had I used conventional note-taking in my original reading of the AlphaGo paper, my understanding would have more rapidly evaporated, and it would have taken longer to read the later papers. And so using Anki in this way gives confidence you will retain understanding over the long term. This confidence, in turn, makes the initial act of understanding more pleasurable, since you believe you're learning something for the long haul, not something you'll forget in a day or a week. OK, but what does one do with it? … [N]ow that I have all this power – a mechanical golem that will never forget and never let me forget whatever I chose to – what do I choose to remember? – Gwern Branwen This entire process took a few days of my time, spread over a few weeks. That's a lot of work. However, the payoff was that I got a pretty good basic grounding in modern deep reinforcement learning. This is an immensely important field, of great use in robotics, and many researchers believe it will play an important role in achieving general artificial intelligence. With a few days work I'd gone from knowing nothing about deep reinforcement learning to a durable understanding of a key paper in the field, a paper that made use of many techniques that were used across the entire field. Of course, I was still a long way from being an expert. There were many important details about AlphaGo I hadn't understood, and I would have had to do far more work to build my own system in the area. But this foundational kind of understanding is a good basis on which to build deeper expertise. It's notable that I was reading the AlphaGo paper in support of a creative project of my own, namely, writing an article for Quanta Magazine. This is important: I find Anki works much b
Flashcard 4369913351436
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itThe conventional Euclidean norm is not appropriate because, as discussed in Section 9.2, some states are more important than ot he rs because they occur more frequently or because we are more interested in them ( S ect i on 9.11)
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itUsing Anki to thoroughly read a research paper in an unfamiliar field I find Anki a great help when reading research papers, particularly in fields outside my expertise. As an example of how this can work, I'll describe my experience reading a 2016 paper** David Silver, Aja Huang, Chris J. Maddison, Arthur Guez et al, Mastering the game of Go with deep neural networks and tree search , Nature (2016). describing AlphaGo, the computer system from Google DeepMind that beat some of the world's strongest players of the game Go. After the match where AlphaGo beat Lee Sedol,
Original toplevel document
Augmenting Long-term Memorye time, the project also helped me learn the Anki interface, and got me to experiment with different ways of posing questions. That is, it helped me build the skills necessary to use Anki well. <span>Using Anki to thoroughly read a research paper in an unfamiliar field I find Anki a great help when reading research papers, particularly in fields outside my expertise. As an example of how this can work, I'll describe my experience reading a 2016 paper** David Silver, Aja Huang, Chris J. Maddison, Arthur Guez et al, Mastering the game of Go with deep neural networks and tree search , Nature (2016). describing AlphaGo, the computer system from Google DeepMind that beat some of the world's strongest players of the game Go. After the match where AlphaGo beat Lee Sedol, one of the strongest human Go players in history, I suggested to Quanta Magazine that I write an article about the system** Michael Nielsen, Is AlphaGo Really Such a Big Deal? , Quanta (2016).. AlphaGo was a hot media topic at the time, and the most common angle in stories was human interest, viewing AlphaGo as part of a long-standing human-versus-machine narrative, with a few technical details filled in, mostly as color. I wanted to take a different angle. Through the 1990s and first decade of the 2000s, I believed human-or-better general artificial intelligence was far, far away. The reason was that over that time researchers made only slow progress building systems to do intuitive pattern matching, of the kind that underlies human sight and hearing, as well as in playing games such as Go. Despite enormous effort by AI researchers, many pattern-matching feats which humans find effortless remained impossible for machines. While we made only very slow progress on this set of problems for a long time, around 2011 progress began to speed up, driven by advances in deep neural networks. For instance, machine vision systems rapidly went from being terrible to being comparable to human beings for certain limited tasks. By the time AlphaGo was released, it was no longer correct to say we had no idea how to build computer systems to do intuitive pattern matching. While we hadn't yet nailed the problem, we were making rapid progress. AlphaGo was a big part of that story, and I wanted my article to explore this notion of building computer systems to capture human intuition. While I was excited, writing such an article was going to be difficult. It was going to require a deeper understanding of the technical details of AlphaGo than a typical journalistic article. Fortunately, I knew a fair amount about neural networks – I'd written a book about them** Michael A. Nielsen, "Neural Networks and Deep Learning" , Determination Press (2015).. But I knew nothing about the game of Go, or about many of the ideas used by AlphaGo, based on a field known as reinforcement learning. I was going to need to learn this material from scratch, and to write a good article I was going to need to really understand the underlying technical material. Here's how I went about it. I began with the AlphaGo paper itself. I began reading it quickly, almost skimming. I wasn't looking for a comprehensive understanding. Rather, I was doing two things. One, I was trying to simply identify the most important ideas in the paper. What were the names of the key techniques I'd need to learn about? Second, there was a kind of hoovering process, looking for basic facts that I could understand easily, and that would obviously benefit me. Things like basic terminology, the rules of Go, and so on. Here's a few examples of the kind of question I entered into Anki at this stage: “What's the size of a Go board?”; “Who plays first in Go?”; “How many human game positions did AlphaGo learn from?”; “Where did AlphaGo get its training data?”; “What were the names of the two main types of neural network AlphaGo used?” As you can see, these are all elementary questions. They're the kind of thing that are very easily picked up during an initial pass over the paper, with occasional digressions to search Google and Wikipedia, and so on. Furthermore, while these facts were easy to pick up in isolation, they also seemed likely to be useful in building a deeper understanding of other material in the paper. I made several rapid passes over the paper in this way, each time getting deeper and deeper. At this stage I wasn't trying to obtain anything like a complete understanding of AlphaGo. Rather, I was trying to build up my background understanding. At all times, if something wasn't easy to understand, I didn't worry about it, I just keep going. But as I made repeat passes, the range of things that were easy to understand grew and grew. I found myself adding questions about the types of features used as inputs to AlphaGo's neural networks, basic facts about the structure of the networks, and so on. After five or six such passes over the paper, I went back and attempted a thorough read. This time the purpose was to understand AlphaGo in detail. By now I understood much of the background context, and it was relatively easy to do a thorough read, certainly far easier than coming into the paper cold. Don't get me wrong: it was still challenging. But it was far easier than it would have been otherwise. After doing one thorough pass over the AlphaGo paper, I made a second thorough pass, in a similar vein. Yet more fell into place. By this time, I understood the AlphaGo system reasonably well. Many of the questions I was putting into Anki were high level, sometimes on the verge of original research directions. I certainly understood AlphaGo well enough that I was confident I could write the sections of my article dealing with it. (In practice, my article ranged over several systems, not just AlphaGo, and I had to learn about those as well, using a similar process, though I didn't go as deep.) I continued to add questions as I wrote my article, ending up adding several hundred questions in total. But by this point the hardest work had been done. Of course, instead of using Anki I could have taken conventional notes, using a similar process to build up an understanding of the paper. But using Anki gave me confidence I would retain much of the understanding over the long term. A year or so later DeepMind released papers describing followup systems, known as AlphaGo Zero and AlphaZero** For AlphaGo Zero, see: David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou et al, Mastering the game of Go without human knowledge , Nature (2017). For AlphaZero, see: David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou et al, Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm (2017).. Despite the fact that I'd thought little about AlphaGo or reinforcement learning in the intervening time, I found I could read those followup papers with ease. While I didn't attempt to understand those papers as thoroughly as the initial AlphaGo paper, I found I could get a pretty good understanding of the papers in less than an hour. I'd retained much of my earlier understanding! By contrast, had I used conventional note-taking in my original reading of the AlphaGo paper, my understanding would have more rapidly evaporated, and it would have taken longer to read the later papers. And so using Anki in this way gives confidence you will retain understanding over the long term. This confidence, in turn, makes the initial act of understanding more pleasurable, since you believe you're learning something for the long haul, not something you'll forget in a day or a week. OK, but what does one do with it? … [N]ow that I have all this power – a mechanical golem that will never forget and never let me forget whatever I chose to – what do I choose to remember? – Gwern Branwen This entire process took a few days of my time, spread over a few weeks. That's a lot of work. However, the payoff was that I got a pretty good basic grounding in modern deep reinforcement learning. This is an immensely important field, of great use in robotics, and many researchers believe it will play an important role in achieving general artificial intelligence. With a few days work I'd gone from knowing nothing about deep reinforcement learning to a durable understanding of a key paper in the field, a paper that made use of many techniques that were used across the entire field. Of course, I was still a long way from being an expert. There were many important details about AlphaGo I hadn't understood, and I would have had to do far more work to build my own system in the area. But this foundational kind of understanding is a good basis on which to build deeper expertise. It's notable that I was reading the AlphaGo paper in support of a creative project of my own, namely, writing an article for Quanta Magazine. This is important: I find Anki works much b
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itover that time researchers made only slow progress building systems to do intuitive pattern matching, of the kind that underlies human sight and hearing, as well as in playing games such as Go. <span>Despite enormous effort by AI researchers, many pattern-matching feats which humans find effortless remained impossible for machines. While we made only very slow progress on this set of problems for a long time, around 2011 progress began to speed up, driven by advances in deep neural networks. For instance, machine
Original toplevel document
Augmenting Long-term Memorye time, the project also helped me learn the Anki interface, and got me to experiment with different ways of posing questions. That is, it helped me build the skills necessary to use Anki well. <span>Using Anki to thoroughly read a research paper in an unfamiliar field I find Anki a great help when reading research papers, particularly in fields outside my expertise. As an example of how this can work, I'll describe my experience reading a 2016 paper** David Silver, Aja Huang, Chris J. Maddison, Arthur Guez et al, Mastering the game of Go with deep neural networks and tree search , Nature (2016). describing AlphaGo, the computer system from Google DeepMind that beat some of the world's strongest players of the game Go. After the match where AlphaGo beat Lee Sedol, one of the strongest human Go players in history, I suggested to Quanta Magazine that I write an article about the system** Michael Nielsen, Is AlphaGo Really Such a Big Deal? , Quanta (2016).. AlphaGo was a hot media topic at the time, and the most common angle in stories was human interest, viewing AlphaGo as part of a long-standing human-versus-machine narrative, with a few technical details filled in, mostly as color. I wanted to take a different angle. Through the 1990s and first decade of the 2000s, I believed human-or-better general artificial intelligence was far, far away. The reason was that over that time researchers made only slow progress building systems to do intuitive pattern matching, of the kind that underlies human sight and hearing, as well as in playing games such as Go. Despite enormous effort by AI researchers, many pattern-matching feats which humans find effortless remained impossible for machines. While we made only very slow progress on this set of problems for a long time, around 2011 progress began to speed up, driven by advances in deep neural networks. For instance, machine vision systems rapidly went from being terrible to being comparable to human beings for certain limited tasks. By the time AlphaGo was released, it was no longer correct to say we had no idea how to build computer systems to do intuitive pattern matching. While we hadn't yet nailed the problem, we were making rapid progress. AlphaGo was a big part of that story, and I wanted my article to explore this notion of building computer systems to capture human intuition. While I was excited, writing such an article was going to be difficult. It was going to require a deeper understanding of the technical details of AlphaGo than a typical journalistic article. Fortunately, I knew a fair amount about neural networks – I'd written a book about them** Michael A. Nielsen, "Neural Networks and Deep Learning" , Determination Press (2015).. But I knew nothing about the game of Go, or about many of the ideas used by AlphaGo, based on a field known as reinforcement learning. I was going to need to learn this material from scratch, and to write a good article I was going to need to really understand the underlying technical material. Here's how I went about it. I began with the AlphaGo paper itself. I began reading it quickly, almost skimming. I wasn't looking for a comprehensive understanding. Rather, I was doing two things. One, I was trying to simply identify the most important ideas in the paper. What were the names of the key techniques I'd need to learn about? Second, there was a kind of hoovering process, looking for basic facts that I could understand easily, and that would obviously benefit me. Things like basic terminology, the rules of Go, and so on. Here's a few examples of the kind of question I entered into Anki at this stage: “What's the size of a Go board?”; “Who plays first in Go?”; “How many human game positions did AlphaGo learn from?”; “Where did AlphaGo get its training data?”; “What were the names of the two main types of neural network AlphaGo used?” As you can see, these are all elementary questions. They're the kind of thing that are very easily picked up during an initial pass over the paper, with occasional digressions to search Google and Wikipedia, and so on. Furthermore, while these facts were easy to pick up in isolation, they also seemed likely to be useful in building a deeper understanding of other material in the paper. I made several rapid passes over the paper in this way, each time getting deeper and deeper. At this stage I wasn't trying to obtain anything like a complete understanding of AlphaGo. Rather, I was trying to build up my background understanding. At all times, if something wasn't easy to understand, I didn't worry about it, I just keep going. But as I made repeat passes, the range of things that were easy to understand grew and grew. I found myself adding questions about the types of features used as inputs to AlphaGo's neural networks, basic facts about the structure of the networks, and so on. After five or six such passes over the paper, I went back and attempted a thorough read. This time the purpose was to understand AlphaGo in detail. By now I understood much of the background context, and it was relatively easy to do a thorough read, certainly far easier than coming into the paper cold. Don't get me wrong: it was still challenging. But it was far easier than it would have been otherwise. After doing one thorough pass over the AlphaGo paper, I made a second thorough pass, in a similar vein. Yet more fell into place. By this time, I understood the AlphaGo system reasonably well. Many of the questions I was putting into Anki were high level, sometimes on the verge of original research directions. I certainly understood AlphaGo well enough that I was confident I could write the sections of my article dealing with it. (In practice, my article ranged over several systems, not just AlphaGo, and I had to learn about those as well, using a similar process, though I didn't go as deep.) I continued to add questions as I wrote my article, ending up adding several hundred questions in total. But by this point the hardest work had been done. Of course, instead of using Anki I could have taken conventional notes, using a similar process to build up an understanding of the paper. But using Anki gave me confidence I would retain much of the understanding over the long term. A year or so later DeepMind released papers describing followup systems, known as AlphaGo Zero and AlphaZero** For AlphaGo Zero, see: David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou et al, Mastering the game of Go without human knowledge , Nature (2017). For AlphaZero, see: David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou et al, Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm (2017).. Despite the fact that I'd thought little about AlphaGo or reinforcement learning in the intervening time, I found I could read those followup papers with ease. While I didn't attempt to understand those papers as thoroughly as the initial AlphaGo paper, I found I could get a pretty good understanding of the papers in less than an hour. I'd retained much of my earlier understanding! By contrast, had I used conventional note-taking in my original reading of the AlphaGo paper, my understanding would have more rapidly evaporated, and it would have taken longer to read the later papers. And so using Anki in this way gives confidence you will retain understanding over the long term. This confidence, in turn, makes the initial act of understanding more pleasurable, since you believe you're learning something for the long haul, not something you'll forget in a day or a week. OK, but what does one do with it? … [N]ow that I have all this power – a mechanical golem that will never forget and never let me forget whatever I chose to – what do I choose to remember? – Gwern Branwen This entire process took a few days of my time, spread over a few weeks. That's a lot of work. However, the payoff was that I got a pretty good basic grounding in modern deep reinforcement learning. This is an immensely important field, of great use in robotics, and many researchers believe it will play an important role in achieving general artificial intelligence. With a few days work I'd gone from knowing nothing about deep reinforcement learning to a durable understanding of a key paper in the field, a paper that made use of many techniques that were used across the entire field. Of course, I was still a long way from being an expert. There were many important details about AlphaGo I hadn't understood, and I would have had to do far more work to build my own system in the area. But this foundational kind of understanding is a good basis on which to build deeper expertise. It's notable that I was reading the AlphaGo paper in support of a creative project of my own, namely, writing an article for Quanta Magazine. This is important: I find Anki works much b
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itfort by AI researchers, many pattern-matching feats which humans find effortless remained impossible for machines. While we made only very slow progress on this set of problems for a long time, <span>around 2011 progress began to speed up, driven by advances in deep neural networks. For instance, machine vision systems rapidly went from being terrible to being comparable to human beings for certain limited tasks. By the time AlphaGo was released, it was no longer
Original toplevel document
Augmenting Long-term Memorye time, the project also helped me learn the Anki interface, and got me to experiment with different ways of posing questions. That is, it helped me build the skills necessary to use Anki well. <span>Using Anki to thoroughly read a research paper in an unfamiliar field I find Anki a great help when reading research papers, particularly in fields outside my expertise. As an example of how this can work, I'll describe my experience reading a 2016 paper** David Silver, Aja Huang, Chris J. Maddison, Arthur Guez et al, Mastering the game of Go with deep neural networks and tree search , Nature (2016). describing AlphaGo, the computer system from Google DeepMind that beat some of the world's strongest players of the game Go. After the match where AlphaGo beat Lee Sedol, one of the strongest human Go players in history, I suggested to Quanta Magazine that I write an article about the system** Michael Nielsen, Is AlphaGo Really Such a Big Deal? , Quanta (2016).. AlphaGo was a hot media topic at the time, and the most common angle in stories was human interest, viewing AlphaGo as part of a long-standing human-versus-machine narrative, with a few technical details filled in, mostly as color. I wanted to take a different angle. Through the 1990s and first decade of the 2000s, I believed human-or-better general artificial intelligence was far, far away. The reason was that over that time researchers made only slow progress building systems to do intuitive pattern matching, of the kind that underlies human sight and hearing, as well as in playing games such as Go. Despite enormous effort by AI researchers, many pattern-matching feats which humans find effortless remained impossible for machines. While we made only very slow progress on this set of problems for a long time, around 2011 progress began to speed up, driven by advances in deep neural networks. For instance, machine vision systems rapidly went from being terrible to being comparable to human beings for certain limited tasks. By the time AlphaGo was released, it was no longer correct to say we had no idea how to build computer systems to do intuitive pattern matching. While we hadn't yet nailed the problem, we were making rapid progress. AlphaGo was a big part of that story, and I wanted my article to explore this notion of building computer systems to capture human intuition. While I was excited, writing such an article was going to be difficult. It was going to require a deeper understanding of the technical details of AlphaGo than a typical journalistic article. Fortunately, I knew a fair amount about neural networks – I'd written a book about them** Michael A. Nielsen, "Neural Networks and Deep Learning" , Determination Press (2015).. But I knew nothing about the game of Go, or about many of the ideas used by AlphaGo, based on a field known as reinforcement learning. I was going to need to learn this material from scratch, and to write a good article I was going to need to really understand the underlying technical material. Here's how I went about it. I began with the AlphaGo paper itself. I began reading it quickly, almost skimming. I wasn't looking for a comprehensive understanding. Rather, I was doing two things. One, I was trying to simply identify the most important ideas in the paper. What were the names of the key techniques I'd need to learn about? Second, there was a kind of hoovering process, looking for basic facts that I could understand easily, and that would obviously benefit me. Things like basic terminology, the rules of Go, and so on. Here's a few examples of the kind of question I entered into Anki at this stage: “What's the size of a Go board?”; “Who plays first in Go?”; “How many human game positions did AlphaGo learn from?”; “Where did AlphaGo get its training data?”; “What were the names of the two main types of neural network AlphaGo used?” As you can see, these are all elementary questions. They're the kind of thing that are very easily picked up during an initial pass over the paper, with occasional digressions to search Google and Wikipedia, and so on. Furthermore, while these facts were easy to pick up in isolation, they also seemed likely to be useful in building a deeper understanding of other material in the paper. I made several rapid passes over the paper in this way, each time getting deeper and deeper. At this stage I wasn't trying to obtain anything like a complete understanding of AlphaGo. Rather, I was trying to build up my background understanding. At all times, if something wasn't easy to understand, I didn't worry about it, I just keep going. But as I made repeat passes, the range of things that were easy to understand grew and grew. I found myself adding questions about the types of features used as inputs to AlphaGo's neural networks, basic facts about the structure of the networks, and so on. After five or six such passes over the paper, I went back and attempted a thorough read. This time the purpose was to understand AlphaGo in detail. By now I understood much of the background context, and it was relatively easy to do a thorough read, certainly far easier than coming into the paper cold. Don't get me wrong: it was still challenging. But it was far easier than it would have been otherwise. After doing one thorough pass over the AlphaGo paper, I made a second thorough pass, in a similar vein. Yet more fell into place. By this time, I understood the AlphaGo system reasonably well. Many of the questions I was putting into Anki were high level, sometimes on the verge of original research directions. I certainly understood AlphaGo well enough that I was confident I could write the sections of my article dealing with it. (In practice, my article ranged over several systems, not just AlphaGo, and I had to learn about those as well, using a similar process, though I didn't go as deep.) I continued to add questions as I wrote my article, ending up adding several hundred questions in total. But by this point the hardest work had been done. Of course, instead of using Anki I could have taken conventional notes, using a similar process to build up an understanding of the paper. But using Anki gave me confidence I would retain much of the understanding over the long term. A year or so later DeepMind released papers describing followup systems, known as AlphaGo Zero and AlphaZero** For AlphaGo Zero, see: David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou et al, Mastering the game of Go without human knowledge , Nature (2017). For AlphaZero, see: David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou et al, Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm (2017).. Despite the fact that I'd thought little about AlphaGo or reinforcement learning in the intervening time, I found I could read those followup papers with ease. While I didn't attempt to understand those papers as thoroughly as the initial AlphaGo paper, I found I could get a pretty good understanding of the papers in less than an hour. I'd retained much of my earlier understanding! By contrast, had I used conventional note-taking in my original reading of the AlphaGo paper, my understanding would have more rapidly evaporated, and it would have taken longer to read the later papers. And so using Anki in this way gives confidence you will retain understanding over the long term. This confidence, in turn, makes the initial act of understanding more pleasurable, since you believe you're learning something for the long haul, not something you'll forget in a day or a week. OK, but what does one do with it? … [N]ow that I have all this power – a mechanical golem that will never forget and never let me forget whatever I chose to – what do I choose to remember? – Gwern Branwen This entire process took a few days of my time, spread over a few weeks. That's a lot of work. However, the payoff was that I got a pretty good basic grounding in modern deep reinforcement learning. This is an immensely important field, of great use in robotics, and many researchers believe it will play an important role in achieving general artificial intelligence. With a few days work I'd gone from knowing nothing about deep reinforcement learning to a durable understanding of a key paper in the field, a paper that made use of many techniques that were used across the entire field. Of course, I was still a long way from being an expert. There were many important details about AlphaGo I hadn't understood, and I would have had to do far more work to build my own system in the area. But this foundational kind of understanding is a good basis on which to build deeper expertise. It's notable that I was reading the AlphaGo paper in support of a creative project of my own, namely, writing an article for Quanta Magazine. This is important: I find Anki works much b
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itgan to speed up, driven by advances in deep neural networks. For instance, machine vision systems rapidly went from being terrible to being comparable to human beings for certain limited tasks. <span>By the time AlphaGo was released, it was no longer correct to say we had no idea how to build computer systems to do intuitive pattern matching. While we hadn't yet nailed the problem, we were making rapid progress. AlphaGo was a big part of that story, and I wanted my article to explore this notion of building computer systems
Original toplevel document
Augmenting Long-term Memorye time, the project also helped me learn the Anki interface, and got me to experiment with different ways of posing questions. That is, it helped me build the skills necessary to use Anki well. <span>Using Anki to thoroughly read a research paper in an unfamiliar field I find Anki a great help when reading research papers, particularly in fields outside my expertise. As an example of how this can work, I'll describe my experience reading a 2016 paper** David Silver, Aja Huang, Chris J. Maddison, Arthur Guez et al, Mastering the game of Go with deep neural networks and tree search , Nature (2016). describing AlphaGo, the computer system from Google DeepMind that beat some of the world's strongest players of the game Go. After the match where AlphaGo beat Lee Sedol, one of the strongest human Go players in history, I suggested to Quanta Magazine that I write an article about the system** Michael Nielsen, Is AlphaGo Really Such a Big Deal? , Quanta (2016).. AlphaGo was a hot media topic at the time, and the most common angle in stories was human interest, viewing AlphaGo as part of a long-standing human-versus-machine narrative, with a few technical details filled in, mostly as color. I wanted to take a different angle. Through the 1990s and first decade of the 2000s, I believed human-or-better general artificial intelligence was far, far away. The reason was that over that time researchers made only slow progress building systems to do intuitive pattern matching, of the kind that underlies human sight and hearing, as well as in playing games such as Go. Despite enormous effort by AI researchers, many pattern-matching feats which humans find effortless remained impossible for machines. While we made only very slow progress on this set of problems for a long time, around 2011 progress began to speed up, driven by advances in deep neural networks. For instance, machine vision systems rapidly went from being terrible to being comparable to human beings for certain limited tasks. By the time AlphaGo was released, it was no longer correct to say we had no idea how to build computer systems to do intuitive pattern matching. While we hadn't yet nailed the problem, we were making rapid progress. AlphaGo was a big part of that story, and I wanted my article to explore this notion of building computer systems to capture human intuition. While I was excited, writing such an article was going to be difficult. It was going to require a deeper understanding of the technical details of AlphaGo than a typical journalistic article. Fortunately, I knew a fair amount about neural networks – I'd written a book about them** Michael A. Nielsen, "Neural Networks and Deep Learning" , Determination Press (2015).. But I knew nothing about the game of Go, or about many of the ideas used by AlphaGo, based on a field known as reinforcement learning. I was going to need to learn this material from scratch, and to write a good article I was going to need to really understand the underlying technical material. Here's how I went about it. I began with the AlphaGo paper itself. I began reading it quickly, almost skimming. I wasn't looking for a comprehensive understanding. Rather, I was doing two things. One, I was trying to simply identify the most important ideas in the paper. What were the names of the key techniques I'd need to learn about? Second, there was a kind of hoovering process, looking for basic facts that I could understand easily, and that would obviously benefit me. Things like basic terminology, the rules of Go, and so on. Here's a few examples of the kind of question I entered into Anki at this stage: “What's the size of a Go board?”; “Who plays first in Go?”; “How many human game positions did AlphaGo learn from?”; “Where did AlphaGo get its training data?”; “What were the names of the two main types of neural network AlphaGo used?” As you can see, these are all elementary questions. They're the kind of thing that are very easily picked up during an initial pass over the paper, with occasional digressions to search Google and Wikipedia, and so on. Furthermore, while these facts were easy to pick up in isolation, they also seemed likely to be useful in building a deeper understanding of other material in the paper. I made several rapid passes over the paper in this way, each time getting deeper and deeper. At this stage I wasn't trying to obtain anything like a complete understanding of AlphaGo. Rather, I was trying to build up my background understanding. At all times, if something wasn't easy to understand, I didn't worry about it, I just keep going. But as I made repeat passes, the range of things that were easy to understand grew and grew. I found myself adding questions about the types of features used as inputs to AlphaGo's neural networks, basic facts about the structure of the networks, and so on. After five or six such passes over the paper, I went back and attempted a thorough read. This time the purpose was to understand AlphaGo in detail. By now I understood much of the background context, and it was relatively easy to do a thorough read, certainly far easier than coming into the paper cold. Don't get me wrong: it was still challenging. But it was far easier than it would have been otherwise. After doing one thorough pass over the AlphaGo paper, I made a second thorough pass, in a similar vein. Yet more fell into place. By this time, I understood the AlphaGo system reasonably well. Many of the questions I was putting into Anki were high level, sometimes on the verge of original research directions. I certainly understood AlphaGo well enough that I was confident I could write the sections of my article dealing with it. (In practice, my article ranged over several systems, not just AlphaGo, and I had to learn about those as well, using a similar process, though I didn't go as deep.) I continued to add questions as I wrote my article, ending up adding several hundred questions in total. But by this point the hardest work had been done. Of course, instead of using Anki I could have taken conventional notes, using a similar process to build up an understanding of the paper. But using Anki gave me confidence I would retain much of the understanding over the long term. A year or so later DeepMind released papers describing followup systems, known as AlphaGo Zero and AlphaZero** For AlphaGo Zero, see: David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou et al, Mastering the game of Go without human knowledge , Nature (2017). For AlphaZero, see: David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou et al, Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm (2017).. Despite the fact that I'd thought little about AlphaGo or reinforcement learning in the intervening time, I found I could read those followup papers with ease. While I didn't attempt to understand those papers as thoroughly as the initial AlphaGo paper, I found I could get a pretty good understanding of the papers in less than an hour. I'd retained much of my earlier understanding! By contrast, had I used conventional note-taking in my original reading of the AlphaGo paper, my understanding would have more rapidly evaporated, and it would have taken longer to read the later papers. And so using Anki in this way gives confidence you will retain understanding over the long term. This confidence, in turn, makes the initial act of understanding more pleasurable, since you believe you're learning something for the long haul, not something you'll forget in a day or a week. OK, but what does one do with it? … [N]ow that I have all this power – a mechanical golem that will never forget and never let me forget whatever I chose to – what do I choose to remember? – Gwern Branwen This entire process took a few days of my time, spread over a few weeks. That's a lot of work. However, the payoff was that I got a pretty good basic grounding in modern deep reinforcement learning. This is an immensely important field, of great use in robotics, and many researchers believe it will play an important role in achieving general artificial intelligence. With a few days work I'd gone from knowing nothing about deep reinforcement learning to a durable understanding of a key paper in the field, a paper that made use of many techniques that were used across the entire field. Of course, I was still a long way from being an expert. There were many important details about AlphaGo I hadn't understood, and I would have had to do far more work to build my own system in the area. But this foundational kind of understanding is a good basis on which to build deeper expertise. It's notable that I was reading the AlphaGo paper in support of a creative project of my own, namely, writing an article for Quanta Magazine. This is important: I find Anki works much b
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open ity this point the hardest work had been done. Of course, instead of using Anki I could have taken conventional notes, using a similar process to build up an understanding of the paper. But using <span>Anki gave me confidence I would retain much of the understanding over the long term. A year or so later DeepMind released papers describing followup systems, known as AlphaGo Zero and AlphaZero** For AlphaGo Zero, see: David Silver, Julian Schrittwieser, Karen Simonyan,
Original toplevel document
Augmenting Long-term Memorye time, the project also helped me learn the Anki interface, and got me to experiment with different ways of posing questions. That is, it helped me build the skills necessary to use Anki well. <span>Using Anki to thoroughly read a research paper in an unfamiliar field I find Anki a great help when reading research papers, particularly in fields outside my expertise. As an example of how this can work, I'll describe my experience reading a 2016 paper** David Silver, Aja Huang, Chris J. Maddison, Arthur Guez et al, Mastering the game of Go with deep neural networks and tree search , Nature (2016). describing AlphaGo, the computer system from Google DeepMind that beat some of the world's strongest players of the game Go. After the match where AlphaGo beat Lee Sedol, one of the strongest human Go players in history, I suggested to Quanta Magazine that I write an article about the system** Michael Nielsen, Is AlphaGo Really Such a Big Deal? , Quanta (2016).. AlphaGo was a hot media topic at the time, and the most common angle in stories was human interest, viewing AlphaGo as part of a long-standing human-versus-machine narrative, with a few technical details filled in, mostly as color. I wanted to take a different angle. Through the 1990s and first decade of the 2000s, I believed human-or-better general artificial intelligence was far, far away. The reason was that over that time researchers made only slow progress building systems to do intuitive pattern matching, of the kind that underlies human sight and hearing, as well as in playing games such as Go. Despite enormous effort by AI researchers, many pattern-matching feats which humans find effortless remained impossible for machines. While we made only very slow progress on this set of problems for a long time, around 2011 progress began to speed up, driven by advances in deep neural networks. For instance, machine vision systems rapidly went from being terrible to being comparable to human beings for certain limited tasks. By the time AlphaGo was released, it was no longer correct to say we had no idea how to build computer systems to do intuitive pattern matching. While we hadn't yet nailed the problem, we were making rapid progress. AlphaGo was a big part of that story, and I wanted my article to explore this notion of building computer systems to capture human intuition. While I was excited, writing such an article was going to be difficult. It was going to require a deeper understanding of the technical details of AlphaGo than a typical journalistic article. Fortunately, I knew a fair amount about neural networks – I'd written a book about them** Michael A. Nielsen, "Neural Networks and Deep Learning" , Determination Press (2015).. But I knew nothing about the game of Go, or about many of the ideas used by AlphaGo, based on a field known as reinforcement learning. I was going to need to learn this material from scratch, and to write a good article I was going to need to really understand the underlying technical material. Here's how I went about it. I began with the AlphaGo paper itself. I began reading it quickly, almost skimming. I wasn't looking for a comprehensive understanding. Rather, I was doing two things. One, I was trying to simply identify the most important ideas in the paper. What were the names of the key techniques I'd need to learn about? Second, there was a kind of hoovering process, looking for basic facts that I could understand easily, and that would obviously benefit me. Things like basic terminology, the rules of Go, and so on. Here's a few examples of the kind of question I entered into Anki at this stage: “What's the size of a Go board?”; “Who plays first in Go?”; “How many human game positions did AlphaGo learn from?”; “Where did AlphaGo get its training data?”; “What were the names of the two main types of neural network AlphaGo used?” As you can see, these are all elementary questions. They're the kind of thing that are very easily picked up during an initial pass over the paper, with occasional digressions to search Google and Wikipedia, and so on. Furthermore, while these facts were easy to pick up in isolation, they also seemed likely to be useful in building a deeper understanding of other material in the paper. I made several rapid passes over the paper in this way, each time getting deeper and deeper. At this stage I wasn't trying to obtain anything like a complete understanding of AlphaGo. Rather, I was trying to build up my background understanding. At all times, if something wasn't easy to understand, I didn't worry about it, I just keep going. But as I made repeat passes, the range of things that were easy to understand grew and grew. I found myself adding questions about the types of features used as inputs to AlphaGo's neural networks, basic facts about the structure of the networks, and so on. After five or six such passes over the paper, I went back and attempted a thorough read. This time the purpose was to understand AlphaGo in detail. By now I understood much of the background context, and it was relatively easy to do a thorough read, certainly far easier than coming into the paper cold. Don't get me wrong: it was still challenging. But it was far easier than it would have been otherwise. After doing one thorough pass over the AlphaGo paper, I made a second thorough pass, in a similar vein. Yet more fell into place. By this time, I understood the AlphaGo system reasonably well. Many of the questions I was putting into Anki were high level, sometimes on the verge of original research directions. I certainly understood AlphaGo well enough that I was confident I could write the sections of my article dealing with it. (In practice, my article ranged over several systems, not just AlphaGo, and I had to learn about those as well, using a similar process, though I didn't go as deep.) I continued to add questions as I wrote my article, ending up adding several hundred questions in total. But by this point the hardest work had been done. Of course, instead of using Anki I could have taken conventional notes, using a similar process to build up an understanding of the paper. But using Anki gave me confidence I would retain much of the understanding over the long term. A year or so later DeepMind released papers describing followup systems, known as AlphaGo Zero and AlphaZero** For AlphaGo Zero, see: David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou et al, Mastering the game of Go without human knowledge , Nature (2017). For AlphaZero, see: David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou et al, Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm (2017).. Despite the fact that I'd thought little about AlphaGo or reinforcement learning in the intervening time, I found I could read those followup papers with ease. While I didn't attempt to understand those papers as thoroughly as the initial AlphaGo paper, I found I could get a pretty good understanding of the papers in less than an hour. I'd retained much of my earlier understanding! By contrast, had I used conventional note-taking in my original reading of the AlphaGo paper, my understanding would have more rapidly evaporated, and it would have taken longer to read the later papers. And so using Anki in this way gives confidence you will retain understanding over the long term. This confidence, in turn, makes the initial act of understanding more pleasurable, since you believe you're learning something for the long haul, not something you'll forget in a day or a week. OK, but what does one do with it? … [N]ow that I have all this power – a mechanical golem that will never forget and never let me forget whatever I chose to – what do I choose to remember? – Gwern Branwen This entire process took a few days of my time, spread over a few weeks. That's a lot of work. However, the payoff was that I got a pretty good basic grounding in modern deep reinforcement learning. This is an immensely important field, of great use in robotics, and many researchers believe it will play an important role in achieving general artificial intelligence. With a few days work I'd gone from knowing nothing about deep reinforcement learning to a durable understanding of a key paper in the field, a paper that made use of many techniques that were used across the entire field. Of course, I was still a long way from being an expert. There were many important details about AlphaGo I hadn't understood, and I would have had to do far more work to build my own system in the area. But this foundational kind of understanding is a good basis on which to build deeper expertise. It's notable that I was reading the AlphaGo paper in support of a creative project of my own, namely, writing an article for Quanta Magazine. This is important: I find Anki works much b
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itI used conventional note-taking in my original reading of the AlphaGo paper, my understanding would have more rapidly evaporated, and it would have taken longer to read the later papers. And so <span>using Anki in this way gives confidence you will retain understanding over the long term. This confidence, in turn, makes the initial act of understanding more pleasurable, since you believe you're learning something for the long haul, not something you'll forget in a day or a week. OK, but what does one do with it? … [N]ow that I have all this power – a
Original toplevel document
Augmenting Long-term Memorye time, the project also helped me learn the Anki interface, and got me to experiment with different ways of posing questions. That is, it helped me build the skills necessary to use Anki well. <span>Using Anki to thoroughly read a research paper in an unfamiliar field I find Anki a great help when reading research papers, particularly in fields outside my expertise. As an example of how this can work, I'll describe my experience reading a 2016 paper** David Silver, Aja Huang, Chris J. Maddison, Arthur Guez et al, Mastering the game of Go with deep neural networks and tree search , Nature (2016). describing AlphaGo, the computer system from Google DeepMind that beat some of the world's strongest players of the game Go. After the match where AlphaGo beat Lee Sedol, one of the strongest human Go players in history, I suggested to Quanta Magazine that I write an article about the system** Michael Nielsen, Is AlphaGo Really Such a Big Deal? , Quanta (2016).. AlphaGo was a hot media topic at the time, and the most common angle in stories was human interest, viewing AlphaGo as part of a long-standing human-versus-machine narrative, with a few technical details filled in, mostly as color. I wanted to take a different angle. Through the 1990s and first decade of the 2000s, I believed human-or-better general artificial intelligence was far, far away. The reason was that over that time researchers made only slow progress building systems to do intuitive pattern matching, of the kind that underlies human sight and hearing, as well as in playing games such as Go. Despite enormous effort by AI researchers, many pattern-matching feats which humans find effortless remained impossible for machines. While we made only very slow progress on this set of problems for a long time, around 2011 progress began to speed up, driven by advances in deep neural networks. For instance, machine vision systems rapidly went from being terrible to being comparable to human beings for certain limited tasks. By the time AlphaGo was released, it was no longer correct to say we had no idea how to build computer systems to do intuitive pattern matching. While we hadn't yet nailed the problem, we were making rapid progress. AlphaGo was a big part of that story, and I wanted my article to explore this notion of building computer systems to capture human intuition. While I was excited, writing such an article was going to be difficult. It was going to require a deeper understanding of the technical details of AlphaGo than a typical journalistic article. Fortunately, I knew a fair amount about neural networks – I'd written a book about them** Michael A. Nielsen, "Neural Networks and Deep Learning" , Determination Press (2015).. But I knew nothing about the game of Go, or about many of the ideas used by AlphaGo, based on a field known as reinforcement learning. I was going to need to learn this material from scratch, and to write a good article I was going to need to really understand the underlying technical material. Here's how I went about it. I began with the AlphaGo paper itself. I began reading it quickly, almost skimming. I wasn't looking for a comprehensive understanding. Rather, I was doing two things. One, I was trying to simply identify the most important ideas in the paper. What were the names of the key techniques I'd need to learn about? Second, there was a kind of hoovering process, looking for basic facts that I could understand easily, and that would obviously benefit me. Things like basic terminology, the rules of Go, and so on. Here's a few examples of the kind of question I entered into Anki at this stage: “What's the size of a Go board?”; “Who plays first in Go?”; “How many human game positions did AlphaGo learn from?”; “Where did AlphaGo get its training data?”; “What were the names of the two main types of neural network AlphaGo used?” As you can see, these are all elementary questions. They're the kind of thing that are very easily picked up during an initial pass over the paper, with occasional digressions to search Google and Wikipedia, and so on. Furthermore, while these facts were easy to pick up in isolation, they also seemed likely to be useful in building a deeper understanding of other material in the paper. I made several rapid passes over the paper in this way, each time getting deeper and deeper. At this stage I wasn't trying to obtain anything like a complete understanding of AlphaGo. Rather, I was trying to build up my background understanding. At all times, if something wasn't easy to understand, I didn't worry about it, I just keep going. But as I made repeat passes, the range of things that were easy to understand grew and grew. I found myself adding questions about the types of features used as inputs to AlphaGo's neural networks, basic facts about the structure of the networks, and so on. After five or six such passes over the paper, I went back and attempted a thorough read. This time the purpose was to understand AlphaGo in detail. By now I understood much of the background context, and it was relatively easy to do a thorough read, certainly far easier than coming into the paper cold. Don't get me wrong: it was still challenging. But it was far easier than it would have been otherwise. After doing one thorough pass over the AlphaGo paper, I made a second thorough pass, in a similar vein. Yet more fell into place. By this time, I understood the AlphaGo system reasonably well. Many of the questions I was putting into Anki were high level, sometimes on the verge of original research directions. I certainly understood AlphaGo well enough that I was confident I could write the sections of my article dealing with it. (In practice, my article ranged over several systems, not just AlphaGo, and I had to learn about those as well, using a similar process, though I didn't go as deep.) I continued to add questions as I wrote my article, ending up adding several hundred questions in total. But by this point the hardest work had been done. Of course, instead of using Anki I could have taken conventional notes, using a similar process to build up an understanding of the paper. But using Anki gave me confidence I would retain much of the understanding over the long term. A year or so later DeepMind released papers describing followup systems, known as AlphaGo Zero and AlphaZero** For AlphaGo Zero, see: David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou et al, Mastering the game of Go without human knowledge , Nature (2017). For AlphaZero, see: David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou et al, Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm (2017).. Despite the fact that I'd thought little about AlphaGo or reinforcement learning in the intervening time, I found I could read those followup papers with ease. While I didn't attempt to understand those papers as thoroughly as the initial AlphaGo paper, I found I could get a pretty good understanding of the papers in less than an hour. I'd retained much of my earlier understanding! By contrast, had I used conventional note-taking in my original reading of the AlphaGo paper, my understanding would have more rapidly evaporated, and it would have taken longer to read the later papers. And so using Anki in this way gives confidence you will retain understanding over the long term. This confidence, in turn, makes the initial act of understanding more pleasurable, since you believe you're learning something for the long haul, not something you'll forget in a day or a week. OK, but what does one do with it? … [N]ow that I have all this power – a mechanical golem that will never forget and never let me forget whatever I chose to – what do I choose to remember? – Gwern Branwen This entire process took a few days of my time, spread over a few weeks. That's a lot of work. However, the payoff was that I got a pretty good basic grounding in modern deep reinforcement learning. This is an immensely important field, of great use in robotics, and many researchers believe it will play an important role in achieving general artificial intelligence. With a few days work I'd gone from knowing nothing about deep reinforcement learning to a durable understanding of a key paper in the field, a paper that made use of many techniques that were used across the entire field. Of course, I was still a long way from being an expert. There were many important details about AlphaGo I hadn't understood, and I would have had to do far more work to build my own system in the area. But this foundational kind of understanding is a good basis on which to build deeper expertise. It's notable that I was reading the AlphaGo paper in support of a creative project of my own, namely, writing an article for Quanta Magazine. This is important: I find Anki works much b
| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itwas still a long way from being an expert. There were many important details about AlphaGo I hadn't understood, and I would have had to do far more work to build my own system in the area. But <span>this foundational kind of understanding is a good basis on which to build deeper expertise. <span>
Original toplevel document
Augmenting Long-term Memorye time, the project also helped me learn the Anki interface, and got me to experiment with different ways of posing questions. That is, it helped me build the skills necessary to use Anki well. <span>Using Anki to thoroughly read a research paper in an unfamiliar field I find Anki a great help when reading research papers, particularly in fields outside my expertise. As an example of how this can work, I'll describe my experience reading a 2016 paper** David Silver, Aja Huang, Chris J. Maddison, Arthur Guez et al, Mastering the game of Go with deep neural networks and tree search , Nature (2016). describing AlphaGo, the computer system from Google DeepMind that beat some of the world's strongest players of the game Go. After the match where AlphaGo beat Lee Sedol, one of the strongest human Go players in history, I suggested to Quanta Magazine that I write an article about the system** Michael Nielsen, Is AlphaGo Really Such a Big Deal? , Quanta (2016).. AlphaGo was a hot media topic at the time, and the most common angle in stories was human interest, viewing AlphaGo as part of a long-standing human-versus-machine narrative, with a few technical details filled in, mostly as color. I wanted to take a different angle. Through the 1990s and first decade of the 2000s, I believed human-or-better general artificial intelligence was far, far away. The reason was that over that time researchers made only slow progress building systems to do intuitive pattern matching, of the kind that underlies human sight and hearing, as well as in playing games such as Go. Despite enormous effort by AI researchers, many pattern-matching feats which humans find effortless remained impossible for machines. While we made only very slow progress on this set of problems for a long time, around 2011 progress began to speed up, driven by advances in deep neural networks. For instance, machine vision systems rapidly went from being terrible to being comparable to human beings for certain limited tasks. By the time AlphaGo was released, it was no longer correct to say we had no idea how to build computer systems to do intuitive pattern matching. While we hadn't yet nailed the problem, we were making rapid progress. AlphaGo was a big part of that story, and I wanted my article to explore this notion of building computer systems to capture human intuition. While I was excited, writing such an article was going to be difficult. It was going to require a deeper understanding of the technical details of AlphaGo than a typical journalistic article. Fortunately, I knew a fair amount about neural networks – I'd written a book about them** Michael A. Nielsen, "Neural Networks and Deep Learning" , Determination Press (2015).. But I knew nothing about the game of Go, or about many of the ideas used by AlphaGo, based on a field known as reinforcement learning. I was going to need to learn this material from scratch, and to write a good article I was going to need to really understand the underlying technical material. Here's how I went about it. I began with the AlphaGo paper itself. I began reading it quickly, almost skimming. I wasn't looking for a comprehensive understanding. Rather, I was doing two things. One, I was trying to simply identify the most important ideas in the paper. What were the names of the key techniques I'd need to learn about? Second, there was a kind of hoovering process, looking for basic facts that I could understand easily, and that would obviously benefit me. Things like basic terminology, the rules of Go, and so on. Here's a few examples of the kind of question I entered into Anki at this stage: “What's the size of a Go board?”; “Who plays first in Go?”; “How many human game positions did AlphaGo learn from?”; “Where did AlphaGo get its training data?”; “What were the names of the two main types of neural network AlphaGo used?” As you can see, these are all elementary questions. They're the kind of thing that are very easily picked up during an initial pass over the paper, with occasional digressions to search Google and Wikipedia, and so on. Furthermore, while these facts were easy to pick up in isolation, they also seemed likely to be useful in building a deeper understanding of other material in the paper. I made several rapid passes over the paper in this way, each time getting deeper and deeper. At this stage I wasn't trying to obtain anything like a complete understanding of AlphaGo. Rather, I was trying to build up my background understanding. At all times, if something wasn't easy to understand, I didn't worry about it, I just keep going. But as I made repeat passes, the range of things that were easy to understand grew and grew. I found myself adding questions about the types of features used as inputs to AlphaGo's neural networks, basic facts about the structure of the networks, and so on. After five or six such passes over the paper, I went back and attempted a thorough read. This time the purpose was to understand AlphaGo in detail. By now I understood much of the background context, and it was relatively easy to do a thorough read, certainly far easier than coming into the paper cold. Don't get me wrong: it was still challenging. But it was far easier than it would have been otherwise. After doing one thorough pass over the AlphaGo paper, I made a second thorough pass, in a similar vein. Yet more fell into place. By this time, I understood the AlphaGo system reasonably well. Many of the questions I was putting into Anki were high level, sometimes on the verge of original research directions. I certainly understood AlphaGo well enough that I was confident I could write the sections of my article dealing with it. (In practice, my article ranged over several systems, not just AlphaGo, and I had to learn about those as well, using a similar process, though I didn't go as deep.) I continued to add questions as I wrote my article, ending up adding several hundred questions in total. But by this point the hardest work had been done. Of course, instead of using Anki I could have taken conventional notes, using a similar process to build up an understanding of the paper. But using Anki gave me confidence I would retain much of the understanding over the long term. A year or so later DeepMind released papers describing followup systems, known as AlphaGo Zero and AlphaZero** For AlphaGo Zero, see: David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou et al, Mastering the game of Go without human knowledge , Nature (2017). For AlphaZero, see: David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou et al, Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm (2017).. Despite the fact that I'd thought little about AlphaGo or reinforcement learning in the intervening time, I found I could read those followup papers with ease. While I didn't attempt to understand those papers as thoroughly as the initial AlphaGo paper, I found I could get a pretty good understanding of the papers in less than an hour. I'd retained much of my earlier understanding! By contrast, had I used conventional note-taking in my original reading of the AlphaGo paper, my understanding would have more rapidly evaporated, and it would have taken longer to read the later papers. And so using Anki in this way gives confidence you will retain understanding over the long term. This confidence, in turn, makes the initial act of understanding more pleasurable, since you believe you're learning something for the long haul, not something you'll forget in a day or a week. OK, but what does one do with it? … [N]ow that I have all this power – a mechanical golem that will never forget and never let me forget whatever I chose to – what do I choose to remember? – Gwern Branwen This entire process took a few days of my time, spread over a few weeks. That's a lot of work. However, the payoff was that I got a pretty good basic grounding in modern deep reinforcement learning. This is an immensely important field, of great use in robotics, and many researchers believe it will play an important role in achieving general artificial intelligence. With a few days work I'd gone from knowing nothing about deep reinforcement learning to a durable understanding of a key paper in the field, a paper that made use of many techniques that were used across the entire field. Of course, I was still a long way from being an expert. There were many important details about AlphaGo I hadn't understood, and I would have had to do far more work to build my own system in the area. But this foundational kind of understanding is a good basis on which to build deeper expertise. It's notable that I was reading the AlphaGo paper in support of a creative project of my own, namely, writing an article for Quanta Magazine. This is important: I find Anki works much b
Flashcard 4370012966156
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itThe home- run hitters try to “force” a diagnosis, and give only one most likely diagnosis. They are either very, very correct, and look very smart, or else they strike out and miss the diagnosis comp
Original toplevel document (pdf)
cannot see any pdfsFlashcard 4370014539020
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itThe home- run hitters try to “force” a diagnosis, and give only one most likely diagnosis. They are either very, very correct, and look very smart, or else they strike out and miss the diagnosis completely.
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itSebaceous carcinoma (21.5): oil red-O stain positive (need frozen section). Sometimes Bowenoid changes (oil red-O negative carcinoma) in the epidermis coexist with sebaceous carcinoma in the dermis. EMA positivity is useful if frozen section not available Merkel cell tumor (26.7): small cell tumor (1.130) is almost always present also in the dermis, in addition to the epidermotropic cells. Sometimes Bowen’s disease can coexist, or the sm
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open itzen section). Sometimes Bowenoid changes (oil red-O negative carcinoma) in the epidermis coexist with sebaceous carcinoma in the dermis. EMA positivity is useful if frozen section not available <span>Merkel cell tumor (26.7): small cell tumor (1.130) is almost always present also in the dermis, in addition to the epidermotropic cells. Sometimes Bowen’s disease can coexist, or the small cells enter the epidermis. Merkel cell carcinoma cells are usually positive for CK20 (perinuclear dot pattern) and neuron-specific enolase Clear cell acanthoma (18.6): discrete clone of pale keratinocytes in a psoriasiform epidermis, positive for glycogen and keratin Hidroacanthoma simplex (23.10): this is an eccrine porom
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open its. Sometimes Bowen’s disease can coexist, or the small cells enter the epidermis. Merkel cell carcinoma cells are usually positive for CK20 (perinuclear dot pattern) and neuron-specific enolase <span>Clear cell acanthoma (18.6): discrete clone of pale keratinocytes in a psoriasiform epidermis, positive for glycogen and keratin Hidroacanthoma simplex (23.10): this is an eccrine poroma with Borst–Jadassohn features, and sweat ducts are present Pagetoid dyskeratosis 164 (1.27) Epidermotropic adnexal carcinoma (2
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
Parent (intermediate) annotation
Open ite for CK20 (perinuclear dot pattern) and neuron-specific enolase Clear cell acanthoma (18.6): discrete clone of pale keratinocytes in a psoriasiform epidermis, positive for glycogen and keratin <span>Hidroacanthoma simplex (23.10): this is an eccrine poroma with Borst–Jadassohn features, and sweat ducts are present Pagetoid dyskeratosis 164 (1.27) Epidermotropic adnexal carcinoma (23.13): rare Epidermotropic metastatic carcinoma or melanoma: very rare. Usually carcinoma or melanoma cells within th
Original toplevel document (pdf)
cannot see any pdfs| status | not read | reprioritisations | ||
|---|---|---|---|---|
| last reprioritisation on | suggested re-reading day | |||
| started reading on | finished reading on |
After finishing a programming language course, how do I get real dirty with coding real-world-like apps? - Quora
ly language, I still do not know where to start on a project. How do I approach it and figure out wha... Rajesh Upadhayaya, Web developer, Program digger, technology lover Answered Mar 14, 2018 <span>This is what i do… I’ve learnt a new programming language and now I want my skill in action. I pick up a project which I wrote in another language and started creating a new project with this new skill. But sometime I don’t want to waste my time and re-writing the same project. So I pick up a online challenge and show my skills. But we don’t get these challenges daily, then in that case I solve earlier challenges question and show how I strong I became in programming….. Ah na… I don’t want to solve older challenge. I need real life challenge, so I go thru the old the ideas I had in past and put them in action. Create a new app or website and updated my git hub repository. Oh sit.. I never got any such idea so I log into stack overflow and solve other peoples problems. In short there are various way you can get your hands dirty. 125 views · View 3 Upvoters pxrVaoVmbTERoDQzSstnFzeNdJMqEe cbjLyKYGSA lNcDXHZpduDdcXmoPkVejLDckDuNCxcfSkKYdUXGkEoneJ What are the biggest tracker networks and what can I do about them?
Flashcard 4370028956940
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itMerkel cell carcinoma cells are usually positive for CK20 (perinuclear dot pattern) and neuron-specific enolase
Original toplevel document (pdf)
cannot see any pdfsFlashcard 4370030529804
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itMerkel cell carcinoma cells are usually positive for CK20 (perinuclear dot pattern) and neuron-specific enolase
Original toplevel document (pdf)
cannot see any pdfsFlashcard 4370032102668
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itMerkel cell carcinoma cells are usually positive for CK20 (perinuclear dot pattern) and neuron-specific enolase
Original toplevel document (pdf)
cannot see any pdfsFlashcard 4370033675532
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itMerkel cell carcinoma cells are usually positive for CK20 (perinuclear dot pattern) and neuron-specific enolase
Original toplevel document (pdf)
cannot see any pdfsFlashcard 4370039442700
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370042326284


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370047307020


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370052287756


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370059103500


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370064084236


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370069851404


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370074832140


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370079812876

| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370084793612


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370089774348


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370094755084


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370099735820


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370104716556


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370109697292


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370114678028


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370119658764


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370124639500


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370129620236


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370134600972


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370139581708
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370140892428


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370147708172


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370152688908


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370157669644


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370162650380


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370167631116


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370172611852


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370177592588


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370182573324


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370187554060


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370192534796


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370197515532


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370202496268


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370207477004


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370212457740


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370217438476


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370222419212


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370227399948


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370232380684


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370237361420


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370242342156


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370249157900


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370254138636


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370259119372


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370265935116


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370270915852


| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370275896588
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Flashcard 4370286382348
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itHidroacanthoma simplex: this is an eccrine poroma with Borst–Jadassohn features, and sweat ducts are present
Original toplevel document (pdf)
cannot see any pdfsFlashcard 4370287955212
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itHidroacanthoma simplex: this is an eccrine poroma with Borst–Jadassohn features, and sweat ducts are present
Original toplevel document (pdf)
cannot see any pdfsFlashcard 4370290576652
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Parent (intermediate) annotation
Open itHidroacanthoma simplex: this is an eccrine poroma with Borst–Jadassohn phenomenon, and sweat ducts are present
Original toplevel document (pdf)
cannot see any pdfsFlashcard 4370298965260
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Unknown title
late Strategy 1.1 Terminologies If you are not familiar with strategy pipeline, please take a look at this video https://broadcast.amazon.com/videos/46919 (from 0:00 till 15:00). Terminologies: <span>context a shared object, which can contains states, across all processors of strategy pipeline sources anything that is retrieved by calling dependency services and is used for generating and/o
late Strategy 1.1 Terminologies If you are not familiar with strategy pipeline, please take a look at this video https://broadcast.amazon.com/videos/46919 (from 0:00 till 15:00). Terminologies: <span>context a shared object, which can contains states, across all processors of strategy pipeline sources anything that is retrieved by calling dependency services and is used for generating and/o
Flashcard 4370302373132
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Unknown title
ook at this video https://broadcast.amazon.com/videos/46919 (from 0:00 till 15:00). Terminologies: context a shared object, which can contains states, across all processors of strategy pipeline <span>sources anything that is retrieved by calling dependency services and is used for generating and/or post processing/filter candidates (recommendations) candidates recommendations that are retur
ook at this video https://broadcast.amazon.com/videos/46919 (from 0:00 till 15:00). Terminologies: context a shared object, which can contains states, across all processors of strategy pipeline <span>sources anything that is retrieved by calling dependency services and is used for generating and/or post processing/filter candidates (recommendations) candidates recommendations that are retur
Flashcard 4370305781004
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Unknown title
cross all processors of strategy pipeline sources anything that is retrieved by calling dependency services and is used for generating and/or post processing/filter candidates (recommendations) <span>candidates recommendations that are returned to client. widgets a container for list of recommendations and additional metadata (title, reftag, etc.) A brief description of the stages in the pipel
cross all processors of strategy pipeline sources anything that is retrieved by calling dependency services and is used for generating and/or post processing/filter candidates (recommendations) <span>candidates recommendations that are returned to client. widgets a container for list of recommendations and additional metadata (title, reftag, etc.) A brief description of the stages in the pipel
Flashcard 4370308664588
| status | not learned | measured difficulty | 37% [default] | last interval [days] | |||
|---|---|---|---|---|---|---|---|
| repetition number in this series | 0 | memorised on | scheduled repetition | ||||
| scheduled repetition interval | last repetition or drill |
Unknown title
ng that is retrieved by calling dependency services and is used for generating and/or post processing/filter candidates (recommendations) candidates recommendations that are returned to client. <span>widgets a container for list of recommendations and additional metadata (title, reftag, etc.) A brief description of the stages in the pipeline (in the order of being executed) contextProcessor
ng that is retrieved by calling dependency services and is used for generating and/or post processing/filter candidates (recommendations) candidates recommendations that are returned to client. <span>widgets a container for list of recommendations and additional metadata (title, reftag, etc.) A brief description of the stages in the pipeline (in the order of being executed) contextProcessor